1.1. 인공지능, 머신러닝, 딥러닝

1️⃣ 인공지능
- 인간의 지능을 모방하여 사람이 하는 일은 컴퓨터(기계)가 할 수 있도록 하는 기술
- 구현 방법 : 머신러닝, 딥러닝 ➡️ 학습 모델을 제공하여 데이터를 뷴류할 수 있는 기술
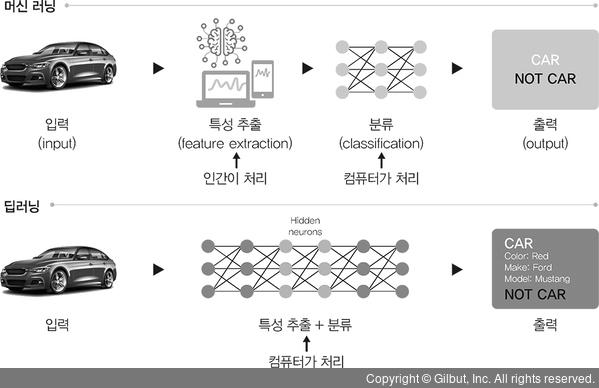
2️⃣ 머신러닝
- 주어진 데이터를 인간이 먼저 전처리
- 범용적인 목적을 위해 제작되었기 때문에 데이터 특징 스스로 추출 불가능
- 학습과정 : 각 데이터(이미지) 특성을 컴퓨터(기계)에 인식시키고 학습시켜 문제 해결
3️⃣ 딥러닝
- 인간의 전처리 단계 생략
- 대량의 데이터를 신경망에 적용해 스스로 답을 찾아냄
✅ 딥러닝 vs 머신러닝
| 머신러닝 | 딥러닝 | |
|---|---|---|
| 동작 원리 | 입력데이터에 알고리즘 적용해 예측 수행 | 정보를 전달하는 신경망을 사용해 데이터 특징 및 관계 해석 |
| 재사용 | 입력데이터를 분석하기 위해 다양한 알고리즘 사용 / 동일한 유형의 데이터 분석을 위한 재사용 불가능 | 구현된 알고리즘을 동일한 유형의 데이터로 분석하는데 재사용 가능 |
| 데이터 | 일반적으로 수천 개의 데이터 필요 | 수백만개 이상의 데이터 필요 |
| 훈련시간 | 단시간 | 장시간 |
| 결과 | 점수, 분류 등 숫자값 | 출력은 점수, 텍스트, 소리 등 어느것이든 가능함. |
1.2. 머신러닝
- 컴퓨터 스스로 대용량 데이터에서 지식이나 패턴을 찾아 학습하고 예측을 수행함
- 컴퓨터가 학습할 수 있게 하는 알고리즘과 기술을 개발하는 분야
1) 학습과정
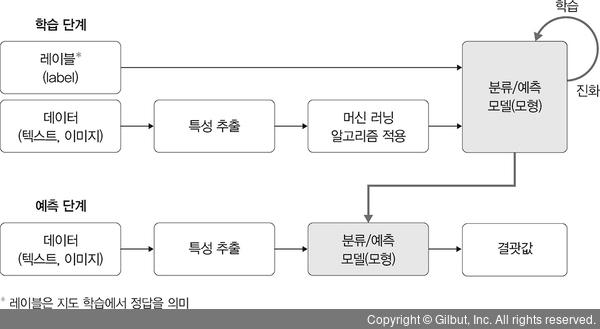
1️⃣ 학습 단계(learning)
- 학습 데이터를 대상으로 머신러닝 알고리즘을 적용하여 학습시키고 해당 학습 결과를 모형으로 생성
2️⃣ 예측 단계(prediction)
- 학습 단계에서 생성된 모형에 새로운 데이터를 적용하여 결과 예측
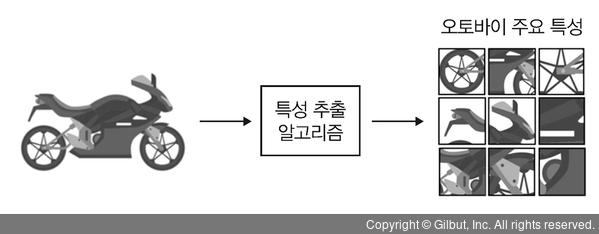
✔️ 특성 추출
- 데이터별 특징 찾기를 토대로 데이터를 벡터로 변환하는 과정
- 사람이 인지하는 데이터 ➡️ 컴퓨터가 인지할 수 있는 데이터 형태로 변경 필요
- 컴퓨터가 입력받은 데이터를 분석하여 일정한 패턴이나 규칙을 찾아내기 위함
✅ 머신러닝의 구성 요소
1) 데이터
- 머신러닝이 학습모델을 만드는데 사용
- 실제 데이터 특징이 잘 반영되고 편향되지 않은 훈련 데이터 확보 필요
- 훈련 데이터셋, 검증 데이터셋으로 분리하여 훈련을 위해 사용
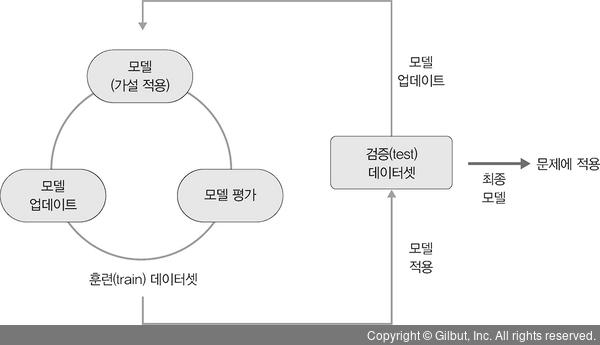
2) 모델 = 가설
- 머신러닝의 학습 단계에서 얻은 최종 결과물
- ex) 입력 데이터의 패턴은 A와 같다
- 절차
- 1️⃣ 모델(가설) 선택
- 2️⃣ 모델 학습 및 평가
- 3️⃣ 평가 바탕 모델 업데이트
2) 머신러닝 학습 알고리즘
1️⃣ 지도학습
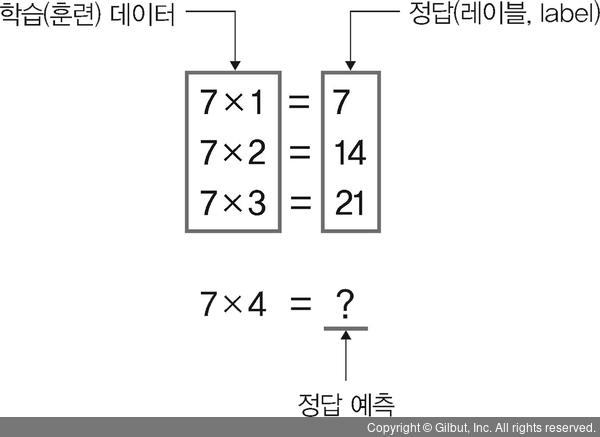
- 정답이 무엇인지 컴퓨터에 알려 주고 학습시키는 방법
2️⃣ 비지도학습
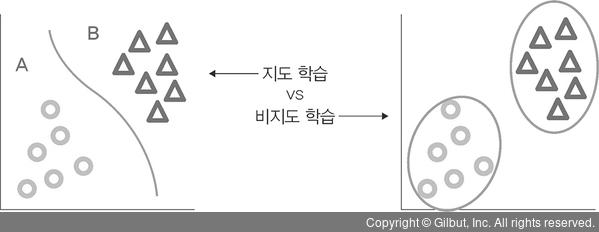
- 정답을 알려주지 않고 특징이 비슷한 데이터를 클러스터링(범주화)하여 예측하는 학습방법
3️⃣ 강화학습
- 분류할 수 있는 데이터가 있는 것도 아니고 데이터가 있다해도 정답이 없음
- 자신의 행동에 대한 보상을 받으며 학습 진행
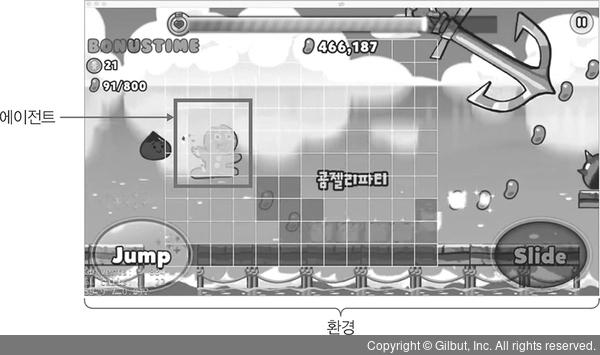
- 에이전트 : 쿠기(게이머)
- 환경(Environment) : 게임 환경
- 액션(action) : 에이전트가 변화하는 환경에 따라 다른 행동을 취함
- 보상 : 동전, 젤리 등 취득하여 보상을 얻음
➡️ 보상이 커지는 행동은 자주 하도록 하고, 줄어드는 행동은 덜 하도록 하여 학습을 진행
✅ 지도학습 vs 비지도학습 vs 강화학습
🟡 지도학습(Supervised Learning)
- 분류(classification)
- K-최근접 이웃(K-Nearnest Neighbor, KNN)
- 서포트 벡터 머신(Support Vector Machine, SVM)
- 결정트리(decision tree)
- 로지스틱 회귀(Logistic regression)
- 회귀(regression)
- 선형회귀(Linear regression)
🟢 비지도학습(Unsupervised Learning)
- 군집(clustering)
- K-평균 군집화(K-mean clustering)
- 밀도 기반 군집 분석(DBSCAN)
- 차원축소(dimensionality reduction)
- 주성분 분석(Principal Component Analysis, PCA)
🔵 강화학습(Reinforcement Learning)
- 마르코프 결정과정(Markov Decision Process, MDP)
1.3. 딥러닝
- 인간의 신경망 원리를 모방한 심층 신경망 이론 기반으로 고안된 머신러닝 방법의 일종
- 인간의 신경망 원리를 모방한 심층 신경망
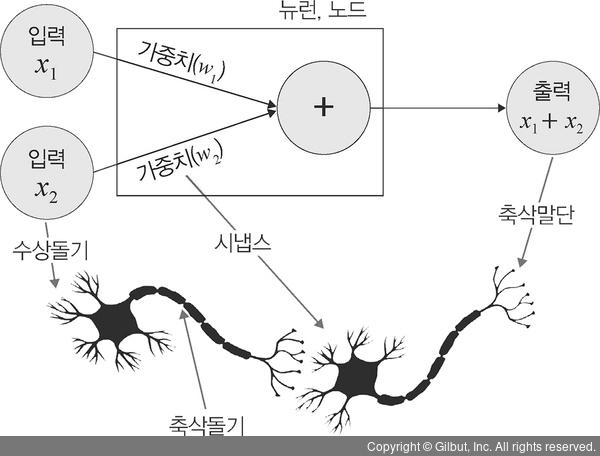
- 수상돌기 : 주변이나 다른 뉴런에서 자극을 받아들이고 이 자극들을 전기적 신호 형태로 세포체와 축삭돌기로 보냄
- 시냅스 : 신경세포들이 이루는 연결부위로, 한 뉴런의 축삭돌기와 다음 뉴런의 수상돌기가 만나는 부분
- 축살돌기 : 다른 뉴런(수상돌기)에 신호를 전달하는 기능을 하는 뉴런의 한 부분으로, 뉴런에서 뻗어있는 돌기 중 가장 길며, 단 한개만 있음
- 축삭말단 : 전달된 전기신호를 받아 신경 전달 물질을 시냅스 틈새로 분비
- 인간의 신경망 원리를 모방한 심층 신경망
1) 딥러닝 학습 과정
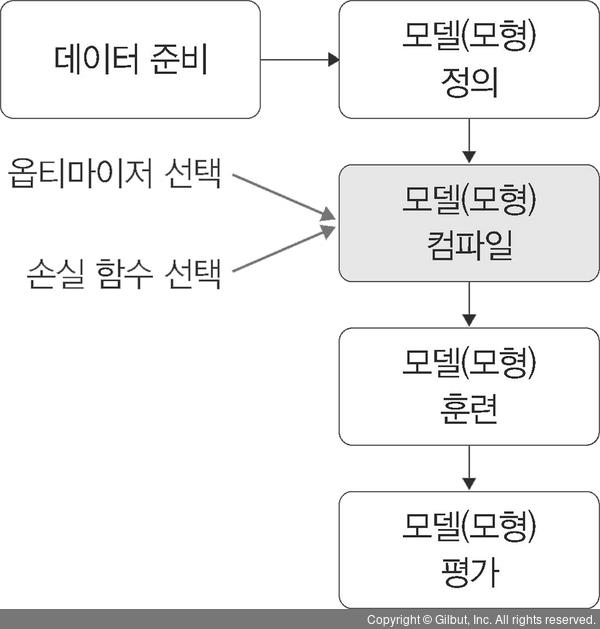
1️⃣ 데이터 준비
- 텐서플로우, 케라스에서 제공하는 데이터 사용 : 이미 전처리가 된 데이터
- 공개된 데이터 사용(kaggle)
2️⃣ 모델(모형) 정의
- 신경망 생성
- 은닉층 개수가 많으면 성능도 좋아짐 ➡️ 과적합 발생 가능성 ⬆️
- 은닉층 개수에 따른 성능과 과적합은 서로 상충관계
✅ 과적합
- 훈련 데이터를 과하게 학습하여 훈련 데이터에 대한 오차는 감소하나, 새로운 데이터에 대한 오차는 커짐
3️⃣ 모델 컴파일
- 활성화 함수, 손실 함수, 옵티마이저 선택 : 과적합을 피할 수 있는 것들로 선택
- 연속형 훈련 데이터셋 : 평균제곱오차(Mean Squared Error, MSE)
- 이진분류(binary classification) : 크로스 엔트로피(cross-entropy)
✅ 활성화 함수
- 입력 신호가 일정 기준 이상이면 출력 신호로 변환
- ex) 시그모이드, 하이퍼볼릭 탄젠트, 렐루 등
✅ 손실 함수
- 모델의 출력값과 사용자가 원하는 출력값(레이블)의 차이 = 오차를 구하는 함수
- ex) MSE, cross-entropy-error
✅ 옵티마이저
- 손실 함수 기반으로 네트워크 업데이트 방법 결정
- 아담(Adam), 알엠에스프롭(RMSProp)
4️⃣ 모델(모형) 훈련
- 훈련 단계 : 한 번에 처리할 데이터양 지정
- 한 번에 처리해야할 데이터 양이 많음 : 학습속도⬇️, 메모리 용량 부족
- 따라서 에포크 선택 중요
- 값의 변화를 시각적으로 표현하여 눈으로 확인하면서 파라미터와 하이퍼파라미터에 대한 최적의 값을 찾아야 함
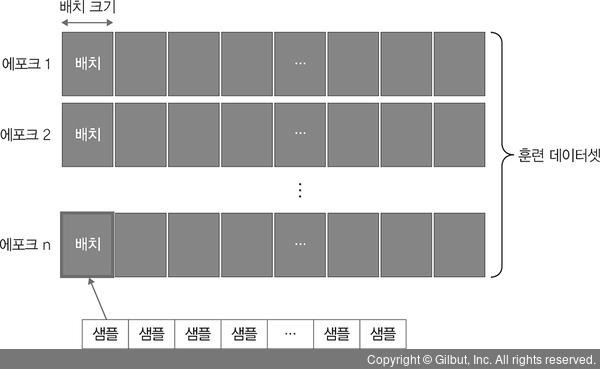
✅ 에포크
- 전체 훈련 데이터셋에서 일정한 묶음으로 나누어 처리할 수 있는 배치와 훈련의 횟수
- ex) 훈련 데이터 셋 1000개, 배치 크기 = 20
- 샘플 단위 20개마다 모델 가중치 1번 업데이트 ➡️ 50번의 가중치 업데이트
- 에포크 : 10, 배치크기 : 20 ➡️ 가중치 업데이트 50번 ✖️ 10번(에포크)
➡️ 각 데이터 샘플 총 10번씩 사용하므로 가중치는 총 500번 업데이트
- ex) 훈련 데이터 셋 1000개, 배치 크기 = 20
✅ 파라미터
- 모델 내부에서 결정되는 변수
✅ 하이퍼 파라미터
- 튜닝 / 최적화애햐 하는 변수로 사람들이 선험적 지식으로 설정해야 하는 변수
5️⃣ 모델(모형) 예측
- 검증 데이터셋을 생성한 모델(모형)에 적용해 실제로 예측 진행
- 예측력이 낮을 경우 : 파라미터 튜닝, 신경망 자체 재설계
✅ 심층신경망(deep neural network)
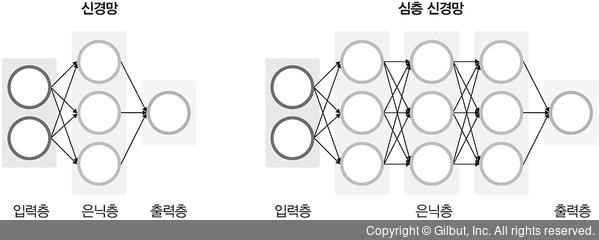
- 머신러닝과의 차별점
- 은닉층이 2개 이상인 신경망
- 데이터셋의 어떤 특성들이 중요한지 스스로에게 가르쳐 줄 수 있음
✅ 역전파
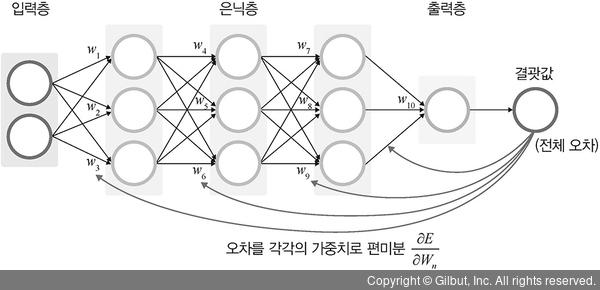
- 가중치값 업데이트(미분)
- 오차를 가중치로 미분함
2) 딥러닝 학습 알고리즘
1️⃣ 지도학습
☝🏻 합성곱 신경망(Convolutional Neural Network, CNN)
- 이미지 / 비디오상 객체를 식별하는 컴퓨터 비전 기술에서 가장 많이 사용
✔️목적에 따른 이미지 분류
- 이미지 분류
- 이미지를 알고리즘에 입력하여 어떤 클래스 레이블에 속하는지 알려줌
- 유사 데이터끼리 분류가 가능해짐
- 이미지 인식
- 사진을 분석해 그 안의 사물의 종류를 인식함
- ex)의료 이미징 : 질병 식별 / 산업 검사, 로봇 비전 등

- 이미지 분할
- 영상에서 사물이나 배경 등 객체 간 영역을 픽셀 단위로 구분
- ex) X-ray, CT, MRI 등 의료 영상에서 분할된 이미지정보를 활용해 질병 진단 등에 활용
- 이미지 분류
✌🏻 순환신경망(Recurrent Neural Network, RNN)
- 시계열 데이터 분류 시 사용됨
- ex) 주식 데이터 : 시간에 따른 데이터 변화
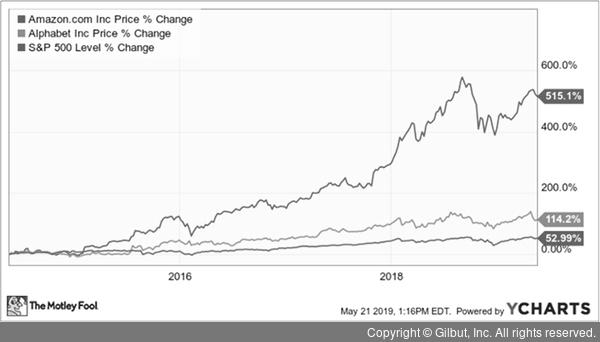
- ex) 주식 데이터 : 시간에 따른 데이터 변화
- ✅ LSTM(Long Short-Term Memory)
- RNN의 역전파 과정에서 기울기 소멸 문제 발생 해결
- 게이트 3개 추가
- 망각게이트 : 과거 정보를 잊기 위한 게이트
- 입력게이트 : 현재 정보를 기억하기 위한 게이트
- 출력게이트 : 최종 결과를 위한 게이트
2️⃣ 비지도학습
☝🏻 워드임베딩(Word Embedding)
- 자연어를 컴퓨터가 이해하고 효율적으로 처리하게 하기 위해 자연어 변환 필요함
- 단어를 벡터로 표현
- 워드투벡터(Word2Vec), 글로브(GloVe) 사용
- 자연어 처리 분야의 일종
- 번역, 음성 인식 등 서비스에서 사용됨

- 번역, 음성 인식 등 서비스에서 사용됨
- 워드 임베딩을 활용해 만든 워드 클라우드
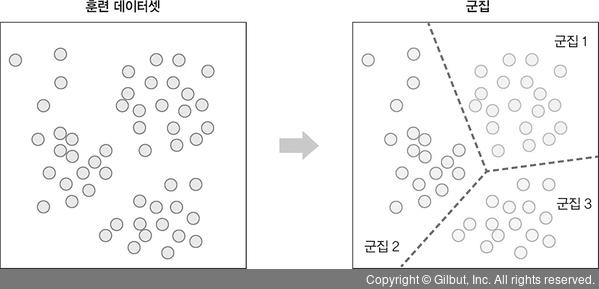
✌🏻 군집
- 아무런 정보가 없는 상태에서 데이터를 분류함
- 목표
- 한 클러스터 안의 데이터는 매우 비슷하게 구성
- 다른 클러스터 데이터와 구분되게 나눔
🤟🏻 전이학습(transfer learning)
- 사전에 학습이 완료된 모델(사전학습모델)을 가지고 우리가 원하는 학습에 미세 조정 기법을 사용해 학습시킴
- 필요 요소
- 사전에 학습이 완료된 모델
- 학습이 완료된 모델을 활용할 수 있는 접근법
- ✅ 사전학습모델
- 풀고자 하는 문제와 비슷하면서 많은 데이터로 이미 학습되어 있는 모델
ex) VGG, 인셉션(Inception), MobileNet
- 풀고자 하는 문제와 비슷하면서 많은 데이터로 이미 학습되어 있는 모델
✅ 지도학습 vs 비지도학습 vs 전이학습 vs 강화학습
🟡 지도학습(Supervised Learning)
- 이미지 분류
- CNN
- AlexNet
- ResNet
- 시계열데이터분석
- RNN
- LSTM
🟢 비지도학습(Unsupervised Learning)
- 군집(clustering)
- 가우시안 혼합 모델(Gaussian Mixture Model, GMM)
- 자기 조직화 지도(Self-Organizing Map, SOM)
- 차원축소(dimensionality reduction)
- 오토인코더(AutoEncoder)
- 주성분 분석(PCA)
🔵 강화학습(Reinforcement Learning)
- 마르코프 결정과정(Markov Decision Process, MDP)
🟠 전이학습(transfer learning)
- 사전학습모델
- 엘모(ELMo)
- 전이학습
- 버트(BERT)
- MoblieNetV2

hello world!