5. 전이학습(transfer learning)
- 딥러닝 : 스스로 중요한 속성을 추출해 학습하므로 방대한 데이터 필요함
- 데이터가 불충분할 경우, 전이학습을 통해 예측율을 높일 수 있음
✔️ 수만 장에 달하는 기존의 이미지에서 학습한 정보를 가져와 내 프로젝트에 활용하는 것
* 치매환자 뇌 예측하기 with CNN
1) 데이터셋
- 지도학습(supervised learning) : 정답(클래스)를 주고 학습하여 다음 정답 예측
- ex) 폐암 수술 환자의 생존율 예측, 피마 인디언의 당뇨병 예측, CNN을 이용한 MNIST 분류 등
- 비지도 학습(unsupervised learning) : 정답을 주지 않고 데이터의 특성을 찾아냄
- ex) GAN, 오토인코더 등
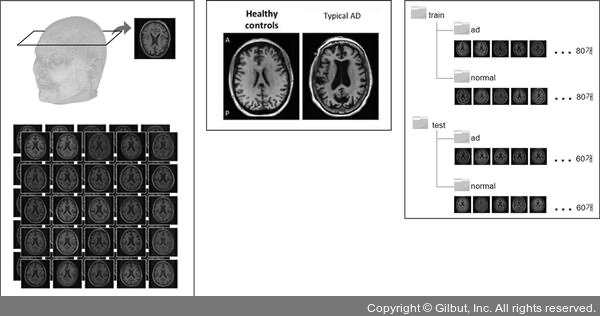
- MRI 단면 이미지 습득 / 2. 일반인인지 치매인지 유형 감별* /3. 일반인 혹은 치매 클래스로 분류
- ex) GAN, 오토인코더 등
- 이미지 분류 기법인 CNN을 통해 진행 : 지도학습
- 데이터 : 280개 뇌 단면 사진
- train : 160
- test : 120
- 치매환자(ad 폴더에 있음) : 140
- 일반인(normal 폴더에 있음) : 140
- ImageDataGenerator() : 데이터의 수를 늘림 ➡️ 주어진 데이터를 이용해 변형된 이미지를 만들어 학습셋에 포함시킴
train_datagen = ImageDataGenerator( rescale=1./255, horizontal_flip=True, width_shift_range=0.1, height_shift_range=0.1, rotation_range=5, shear_range=0.7, zoom_range=1.2, vertical_flip=True, fill_mode='nearest')
- 이미지 생성옵션
- rescale : 주어진 이미지의 크기 변경
- 1./255 : 원본영상이 0~255의 RGB값을 가졌기 때문에 255로 나눠서 0~1사이의 값으로 변경
- horizontal_flip/vertical_flip : 주어진 이미지를 수평/수직으로 뒤집음
- zoom_range : 정해진 범위 내 축소 및 확대
- width_shift_range, height_shift_range : 정해진 범위 안에서 그림을 수평, 수직으로 랜덤하게 평행 이동
- rotation_range : 정해진 각도만큼 이미지 회전
- shear_range : 좌표 하나 고정시키고 다른 몇 개의 좌표를 이동시키는 반환
- fill_mode : 이미지를 축소, 회전, 이동 시 생기는 빈 공간을 어떻게 채울지 결정
- nearest : 가장 비슷한 색으로 채워짐
➡️ 인자 전체 적용 시 불필요한 데이터가 생성될 수 있음

✔️ 데이터 부풀리기 : 학습셋에서만 적용
- 테스트셋에서는 실제 정보 유지 : 과적합 방지
- 데이터 정규화만 해줌.
test_datagen = ImageDataGenerator(rescale=1./255)
- 데이터 정규화만 해줌.
- flow_from_directory(): 폴더에 저장된 데이터 불러옴
- 실제 데이터의 위치와 이미지를 불러옴
train_generactor = train_datagen.flow_from_directory( './trian', target_size = (150,150), batch_size = 5, class_mode = 'binary' ) test_generactor = test_datagen.flow_from_directory( './test', target_size = (150,150), batch_size = 5, class_mode = 'binary' )
2) 컴파일
model.fit_generator(
train_generator, #학습 모델
steps_per_epochs=100, # 이미지 생성기에서 추출할 샘플 이미지
epochs=20,
validation_data = test_generator, validation_steps=4)- 실행 함수 : fit_generator()
3) 전체 코드
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, Dropout, Flatten, Dense, Conv2D, MaxPooling2D
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import optimizers, initializers, regularizers, metrics
np.random.seed(3)
tf.random.set_seed(3)
train_datagen = ImageDataGenerator(rescale = 1./255,
horizontal_flip=True, #수평 대칭 이미지를 50% 확률로 만들어 추가함
width_shift_range=0.1, #전체 크기의 10% 범위에서 좌우로 이동
height_shift_range=0.1,# 전체크기의 10% 범위에서 위아래로 이동
fill_mode='nearest')
train_generator = train_datagen.flow_from_directory('./train',
target_size=(150,150),
batch_size=5,
class_mode='binary')
test_datagen = ImageDataGenerator(rescale = 1./255)
test_generator = test_datagen.flow_from_directory('./test',
target_size=(150,150),
batch_size=5,
class_mode='binary')
#CNN 모델
model = Sequential()
model.add(Conv2D(32, (3,3), input_shape=(150,150,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(32, (3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(2))
model.add(Activation('sigmoid'))
model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizers.Adam(learning_rate=0.0002), metrics=['accuracy'])
model.fit_generator(train_generator, steps_per_epoch=100, epochs=20,
validation_data = test_generator,
validation_steps=10)
acc= history.history['accuracy']
val_acc= history.history['val_accuracy']
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, acc, marker='.', c="red", label='Trainset_acc')
plt.plot(x_len, val_acc, marker='.', c="lightcoral", label='Testset_acc')
plt.plot(x_len, y_vloss, marker='.', c="cornflowerblue", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss/acc')
plt.show()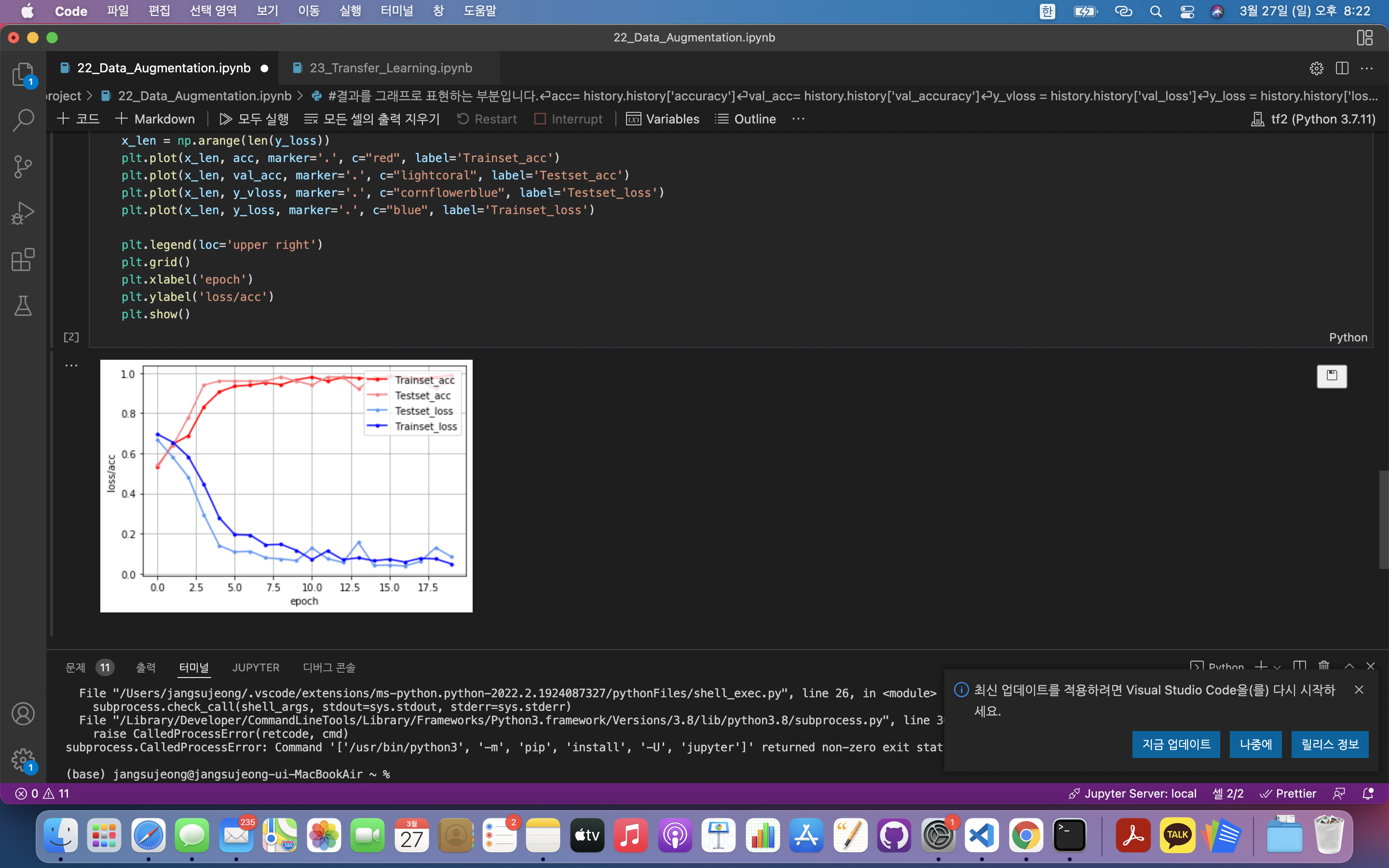
* 치매환자 뇌 예측하기 with 전이학습
- 전이학습 : 기존의 학습 결과를 가져와서 유사한 프로젝트에 사용하는 방법
1) 데이터셋
- 이미지넷 : 1,000가지 종류로 나뉜 120만 개가 넘는 이미지를 놓고 어떤 물체인지를 맞히는 ‘이미지넷 이미지 인식 대회(ILSVRC)’에 사용되는 데이터셋
➡️ 방대한 양의 데이터셋에서 추출한 정보를 가져와 예측율 극대화✔️ 이미지넷 학습 정보 이용 목적 : '형태'를 구분하는 기본적인 학습이 되어 있음.
ex) 딥러닝 : 어떤 픽셀의 조합이 '선', 어떤 형태의 그룹이 '면'인지 하나씩 파악하는 등 기본적인 학습을 하는데만도 많은 시간이 걸림.
🔆 전이학습 : 방대한 대용량 데이터를 이용해 학습한 가중치 정보를 가져와 내 모델에 적용 후 사용 가능 - 전이학습 방법
- 1️⃣ 대규모 데이터셋에서 학습된 기존의 네트워크 불러옴
- 2️⃣ CNN 모델 앞에 해당 네트워크를 세움
- 3️⃣ 뒤쪽 레이어에서 나의 프로젝트와 연결
- 4️⃣ 두 네트워크가 잘 맞춰지도록 미세조정(Fine tuning)
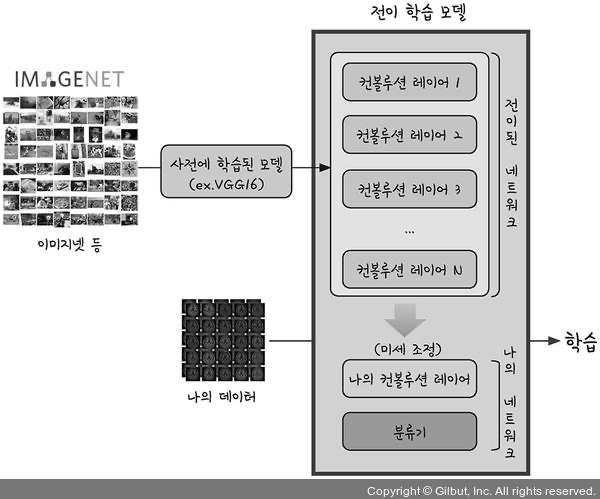
- VGGNet : 이미지넷 데이터셋 중 미리 학습된 모델
- 옥스포드대학의 연구팀 VGG에 의해 개발된 모델로 2014년 이미지넷 이미지 인식 대회에서 2위를 차지한 모델
transfer_model = VGG16(weights='imagenet', include_top=False, input_shape=(150,150,3))
transfer_model.trianable = False
transfer_model.summary()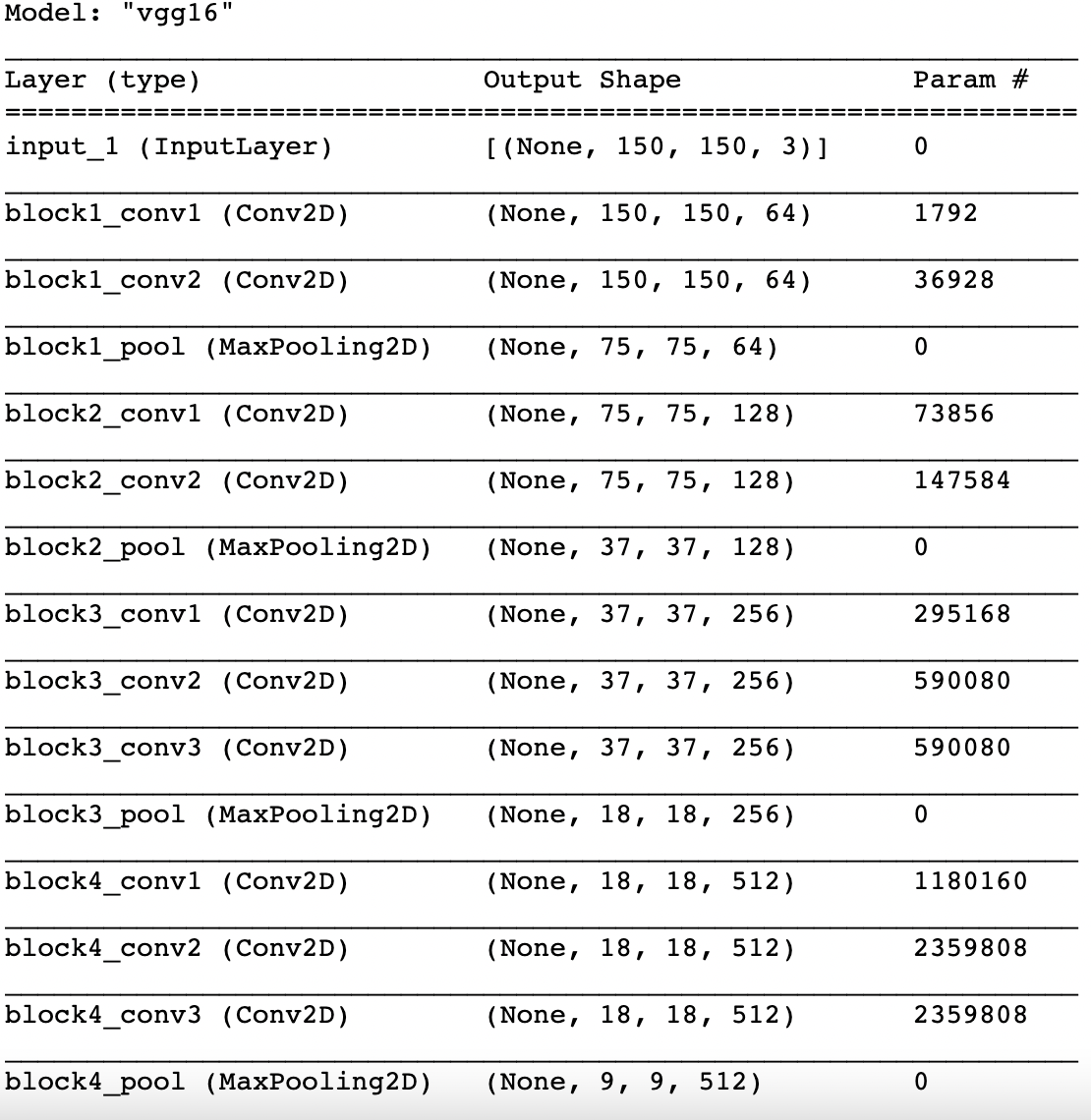

2) 로컬 네트워크 생성
finetune_model = models.Sequential()
finetune_model.add(transfer_model)
finetune_model.add(Flatten())
finetune_model.add(Dense(64, activation='relu'))
finetune_model.add(Dense(2, activation='softmax'))
finetune_model.summary()
- transfer_model을 불러온 후, 최종 예측하는 층 추가

train_datagen = ImageDataGenerator(rescale = 1./255,
horizontal_flip=True, #수평 대칭 이미지를 50% 확률로 만들어 추가함
width_shift_range=0.1, #전체 크기의 10% 범위에서 좌우로 이동
height_shift_range=0.1,# 전체크기의 10% 범위에서 위아래로 이동
fill_mode='nearest')
train_generator = train_datagen.flow_from_directory('./train',
target_size=(150,150),
batch_size=5,
class_mode='binary')
test_datagen = ImageDataGenerator(rescale = 1./255)
test_generator = test_datagen.flow_from_directory('./test',
target_size=(150,150),
batch_size=5,
class_mode='binary')
transfer_model = VGG16(weights='imagenet', include_top=False, input_shape=(150,150,3))
transfer_model.trianable = False
finetune_model = models.Sequential()
finetune_model.add(transfer_model)
finetune_model.add(Flatten())
finetune_model.add(Dense(64, activation='relu'))
finetune_model.add(Dense(2, activation='softmax'))
finetune_model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizers.Adam(learning_rate=0.0002), metrics=['accuracy'])
history = finetune_model.fit_generator(train_generator, steps_per_epoch=100, epochs=20,
validation_data = test_generator,
validation_steps=10)
acc= history.history['accuracy']
val_acc= history.history['val_accuracy']
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
x_len = np.arange(len(y_loss))
plt.plot(x_len, acc, marker='.', c="red", label='Trainset_acc')
plt.plot(x_len, val_acc, marker='.', c="lightcoral", label='Testset_acc')
plt.plot(x_len, y_vloss, marker='.', c="cornflowerblue", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss/acc')
plt.show()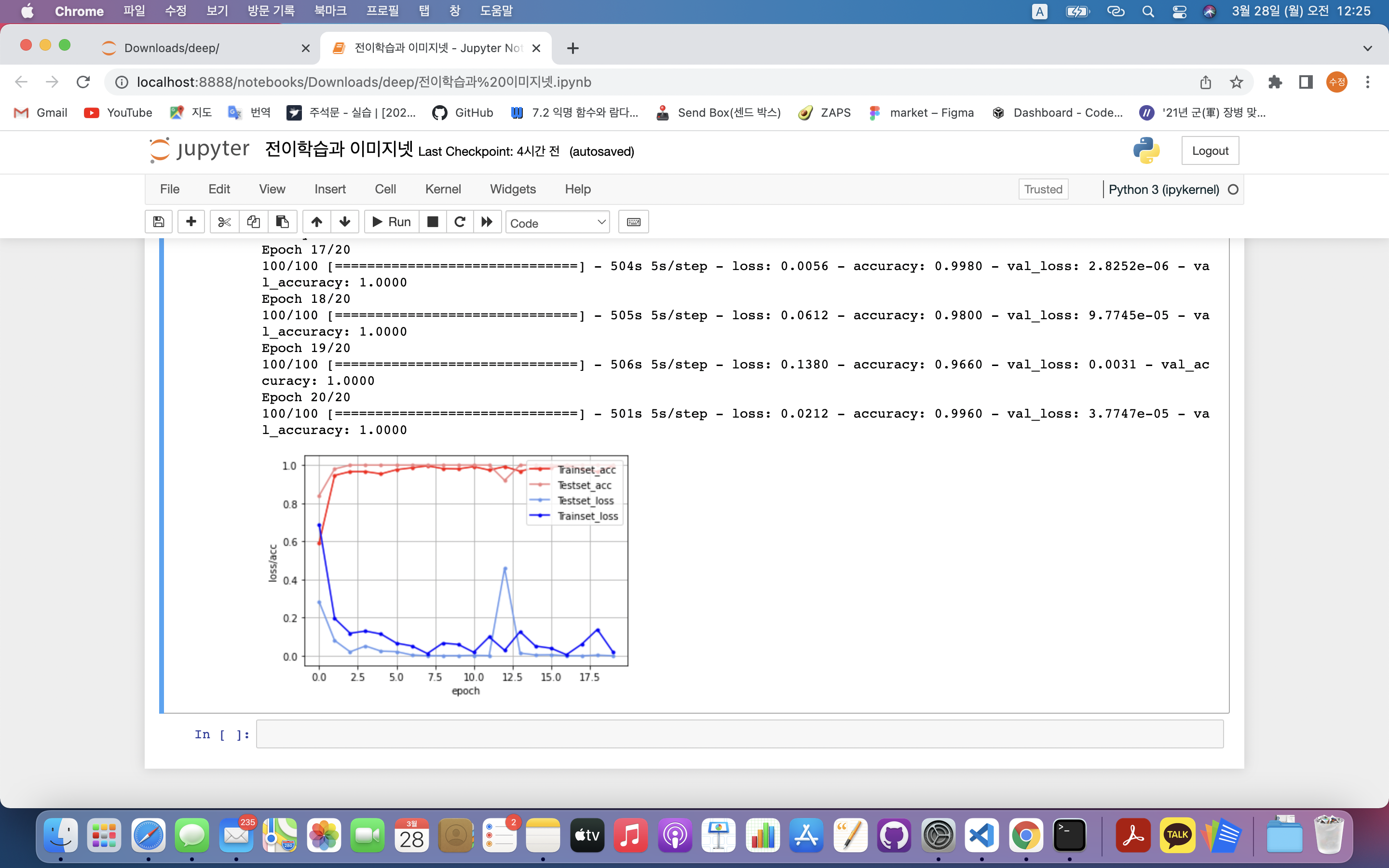

hello world!