1. 모델 설계하기
* 폐암 수술 환자 생존률 예측
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
import tensorflow as tf
from pandas import read_csv
np.random.seed(3)
tf.random.set_seed(3)
target = 'https://raw.githubusercontent.com/gilbutITbook/006958/master/deeplearning/dataset/ThoraricSurgery.csv'
dataframe = read_csv(target, engine='python').values
X = dataframe[:,0:17]
Y = dataframe[:,17]
model = Sequential()
model.add(Dense(30, input_dim=17, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'])
model.fit(X,Y,epochs=100,batch_size=10)1. 모델 정의
- 모듈 임포트
model = Sequential(): 모델 생성model.add(Dense()): 모델 내부 계층 구성model.compile(): 모델 컴파일(컴퓨터가 인식가능하게 컴파일)model.fit(): 모델 실행(학습)- 교차엔트로피 : 가중치 수정을 위한 오차 측정
2. 입력층, 은닉층, 출력층
model = Sequential()
model.add(Dense(30, input_dim=17, activation='relu'))
model.add(Dense(1, activation='sigmoid')) # 2개의 층으로 구성됨- 딥러닝 구조를 설정하고 층을 설정하는 부분
Sequential(): 입력층, 은닉층, 출력층을 순차적으로 구성할 수 있는 모델 객체model.add(): model을 추가하고 add를 통해 라인을 추가하면 새로운 층 구성됨- 지금까지 만들어진 2개의 층은 각각 은닉층과 출력층
- 출력층 : 맨 마지막 층
Dense(): 가중합과 활성화 함수 동작을 담당하는 계층(노드) ➡️ 입력층, 은닉층, 출력층과 같이 신경망 모델의 각 계층의 기능을 수행하는 클래스- units : 첫 번째 파라미터, 해당 층의 노드 개수
Dense(30): 해당 층에 30개의 노드를 만들겠다
- input_dim : 입력 데이터에서 몇개의 값을 가져올지 결정 ➡️ 입력층을 따로 적어주지 않고 해당 층이 은닉층+입력층 역할도 같이 함
Dense(30, input_dim=17): 데이터에서 17개의 값을 받아 은닉층의 30개의 노드로 보냄
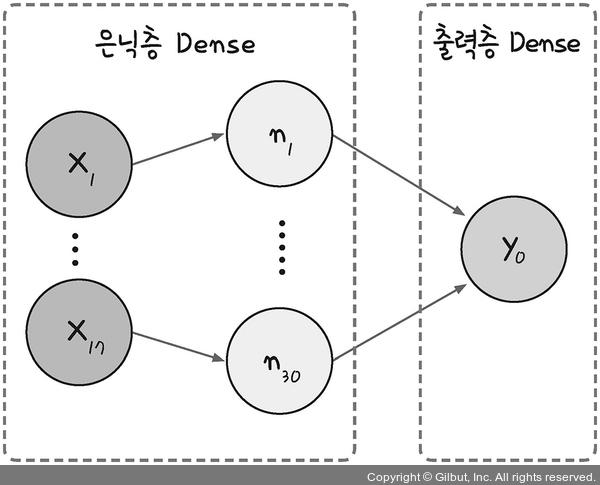
- 첫번째 Dense = 입력층 + 은닉층
- 두번째 Dense = 출력층
➡️ 은닉층의 각 노드는 17개의 입력값에서 임의의 가중치를 가지고 각 노드로 전송되어 활성화 함수를 만남. 활성화 함수를 거친 결과값이 출력층으로 전송됨.
activation: 활성화 함수model.add(Dense(1, activation='sigmoid')): 출력층의 결과는 1개이므로 노드 개수 1.
- units : 첫 번째 파라미터, 해당 층의 노드 개수
3. 모델 컴파일
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'])- 구축한 모델이 학습(훈련)과정을 실행할 수 있도록 환경 설정
loss='mean_squared_error': 오차함수 지정(평균제곱오차 : 수렴하기까지 속도가 많이 걸림) ➡️ 교차 엔트로피 계열 함수optimizer='adam': 최적화방법, W는 각 층별의 가중치w의 집합
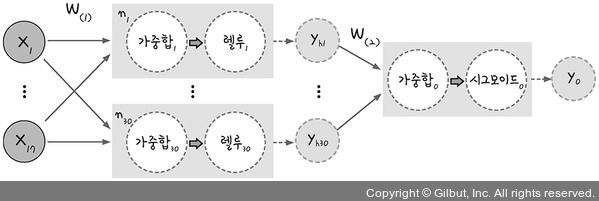
metrics=['accuracy']: 모델이 컴파일될 때 모델 수행 결과를 나타나게 함- accuarcy : 정확도를 측정하기 위해 사용되는 샘플 테스트 데이터를 학습과정에서 제외 ➡️ 과적합 문제 방지(overfitting, 특정 데이터에서는 잘 동작하나 그 외 데이터에서는 잘 작동하지 않음)
* 대표적인 오차 함수
- 평균제곱계열
- 1️⃣ mean_squared_error(평균 제곱 오차) : mean(square(yt - yo)
- yt: 실제값, yo : 예측값
- 2️⃣ mean_absolute_error(평균 절대 오차) : mean(abs(yt - yo)
- 실제값과 예측값 간 차이의 절대값 평균
- 3️⃣ mean_absolute_percentage_error(평균 절대 백분율 오차) : mean(abs(yt-yo)/abs(yt))
- 절대값 오차를 절댓값으로 나눈 후 평균
- 4️⃣ mean_squared_logarithmic_error(평균 제곱 로그 오차) : mean(square((log(yo)+1) - log(yt)+1)))
- 실제 값과 예측 값에 로그를 적용한 값의 차이를 제곱한 값의 평균
- 교차 엔트로피 계열
- 1️⃣ categorical_crossentropy(범주형 교차 엔트로피) : 일반형 분류
- 2️⃣ binary_crossentropy(이항 교차 엔트로피) : 두 개의 클래스 중에서 예측
4. 모델 실행
model.fit(X,Y,epochs=100,batch_size=10)- 데이터를 사용하여 모델을 학습시킴
데이터 형태
- 데이터 : 470개의 환자에게서 17개의 정보 정리
- 정보 = 속성
- 생존여부 = 클래스
- 각 환자의 정보 = 샘플
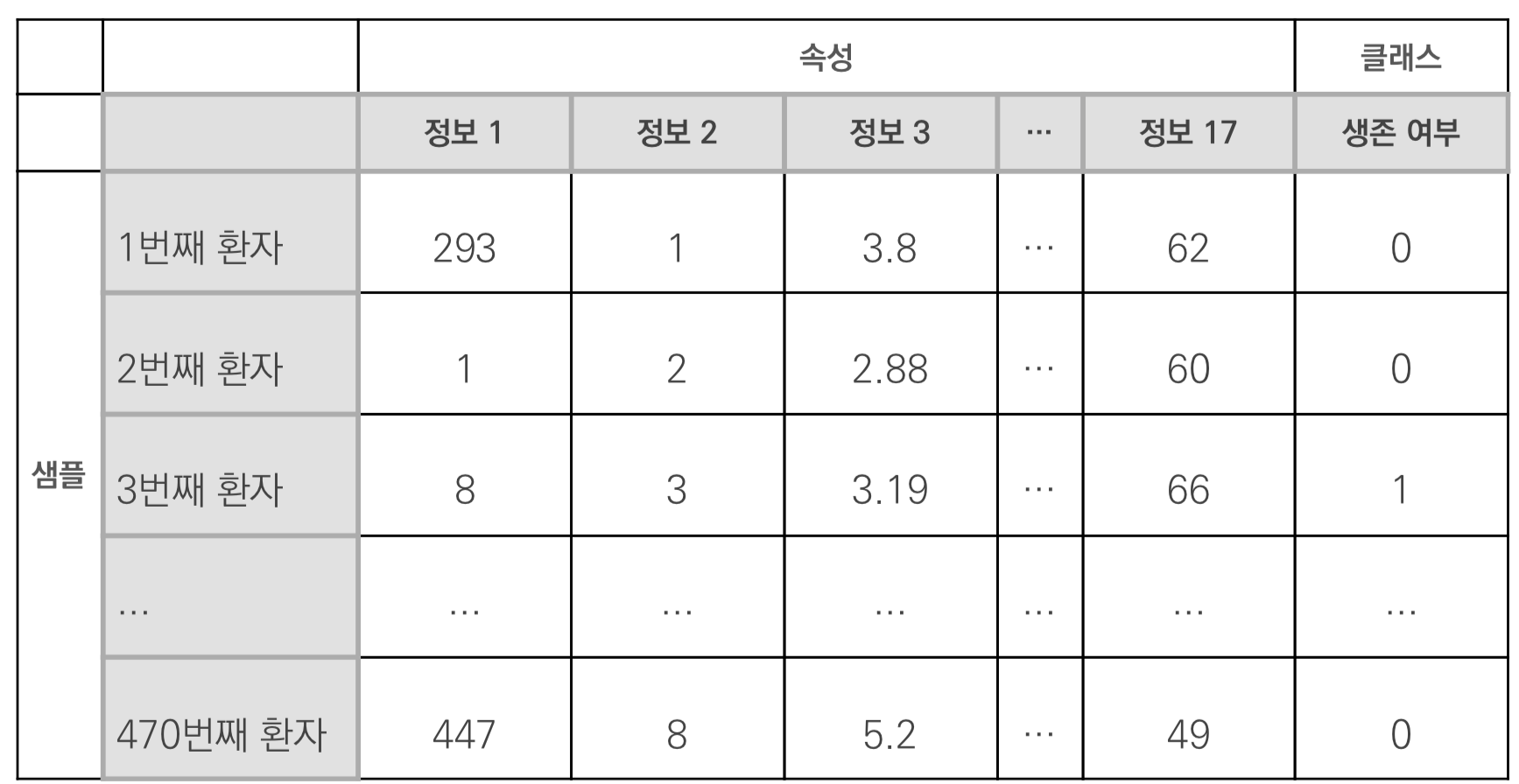
- epochs(에포크) : 모든 샘플에 대해 한 번 실행됨
- epochs = 100 : 모든 샘플에 대해 100번 실행 반복
- batch_size : 샘플을 한 번에 몇개씩 처리할지 결정
-batch_size = 10 : 470개의 샘플을 10개씩 나눠서 처리 ➡️ 너무 크면 학습속도 느려짐. 너무 작으면 각 실행값의 편차가 생겨 결괏값이 불안정해짐
2. 데이터 다루기
* 피마 인디언 당뇨병 예측
1. 데이터 분석
- 딥러닝 구동에 앞서 항상 데이터 내용과 구조를 잘 파악할 필요 있음
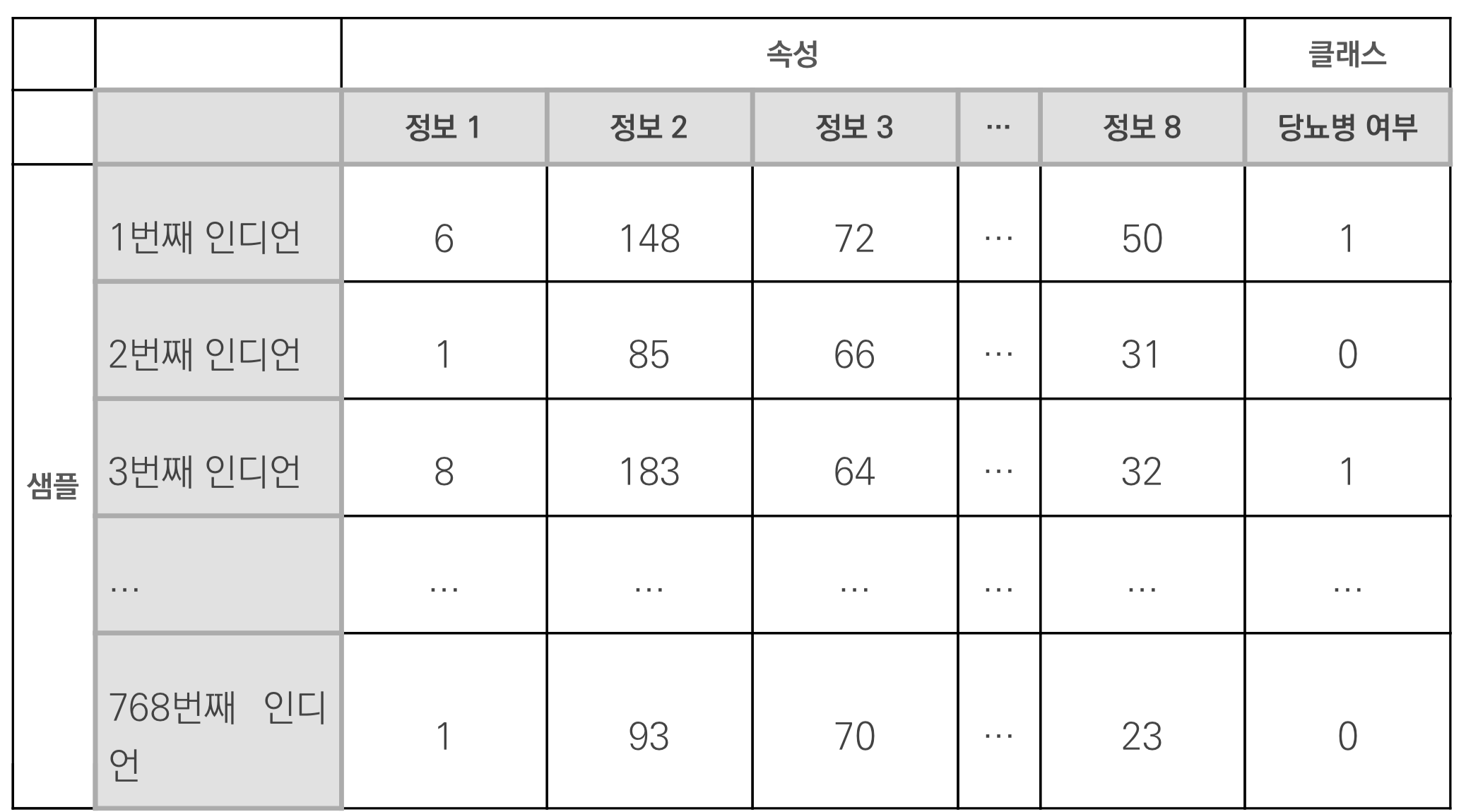
- 샘플 수 : 768
- 속성 : 8
- 정보 1(pregnant) : 과거 임신 횟수
- 정보 2(plasma) : 포도당 부하 검사 2시간 후 공복 혈당 농도
- 정보 3(pressure) : 확장기 혈압
- 정보 4(thickness) : 삼두근 피부 주름 두께
- 정보 5(insulin) : 혈청 인슐린
- 정보 6(BMI) : 체질량 지수
- 정보 7(pedigree): 당뇨병 가족력
- 정보 8(age) : 나이
- 클래스 : 당뇨 1, 당뇨 아님 0
2. 데이터 조사 with pandas
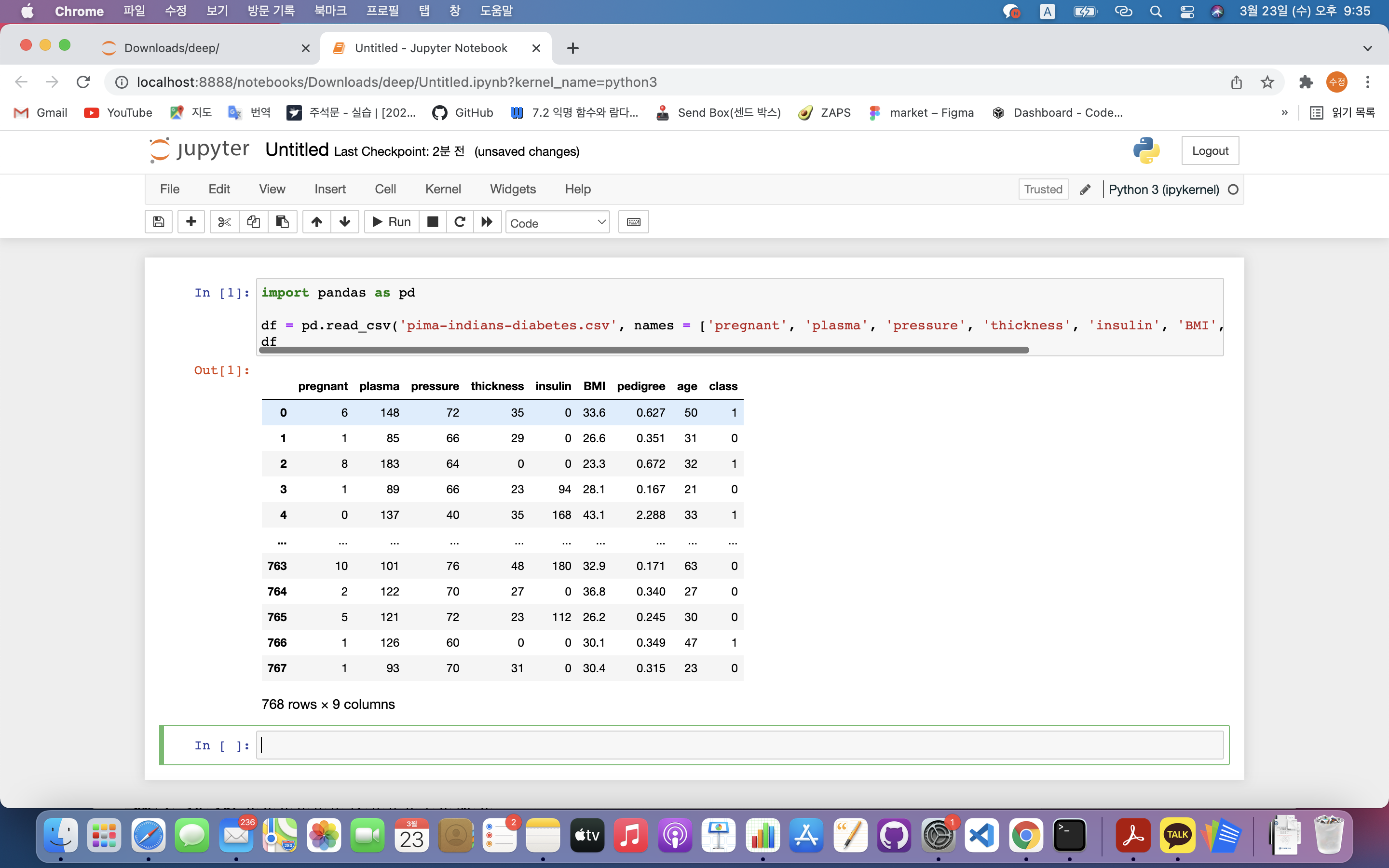
import pandas as pd
df = pd.read_csv('pima-indians-diabetes.csv', names = ['pregnant', 'plasma', 'pressure', 'thickness', 'insulin', 'BMI', 'pedigree', 'age', 'class'])
df.head(5)
df.info()
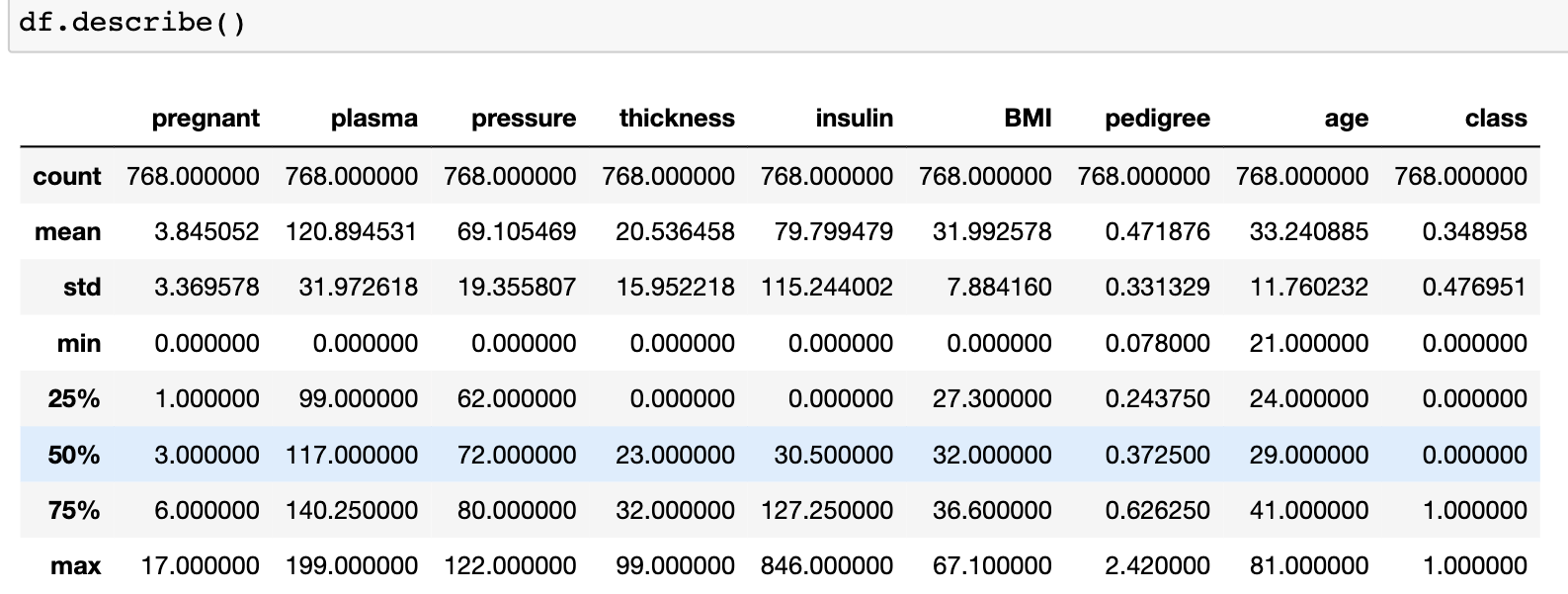
df.describe()
df.pd.read_csv(): csv 데이터 불러오기.df.head(5): 데이터의 첫 다섯 줄 불러오기df.info(): 데이터의 전반적인 정보 추출
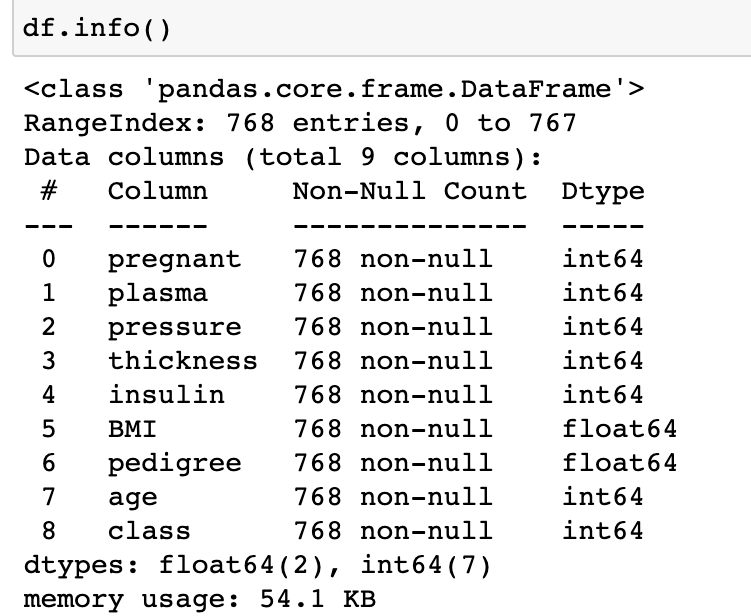
- 데이터가 항목별로 빠짐없이 다 들어가있음
df.describe(): 정보별 특징 ➡️ 정보별 샘플 수(count), 평균(mean), 표준편차(std), 최솟값(min), 백분위 수로 25%, 50%, 75%에 해당하는 값 그리고 최댓값(max)이 정리
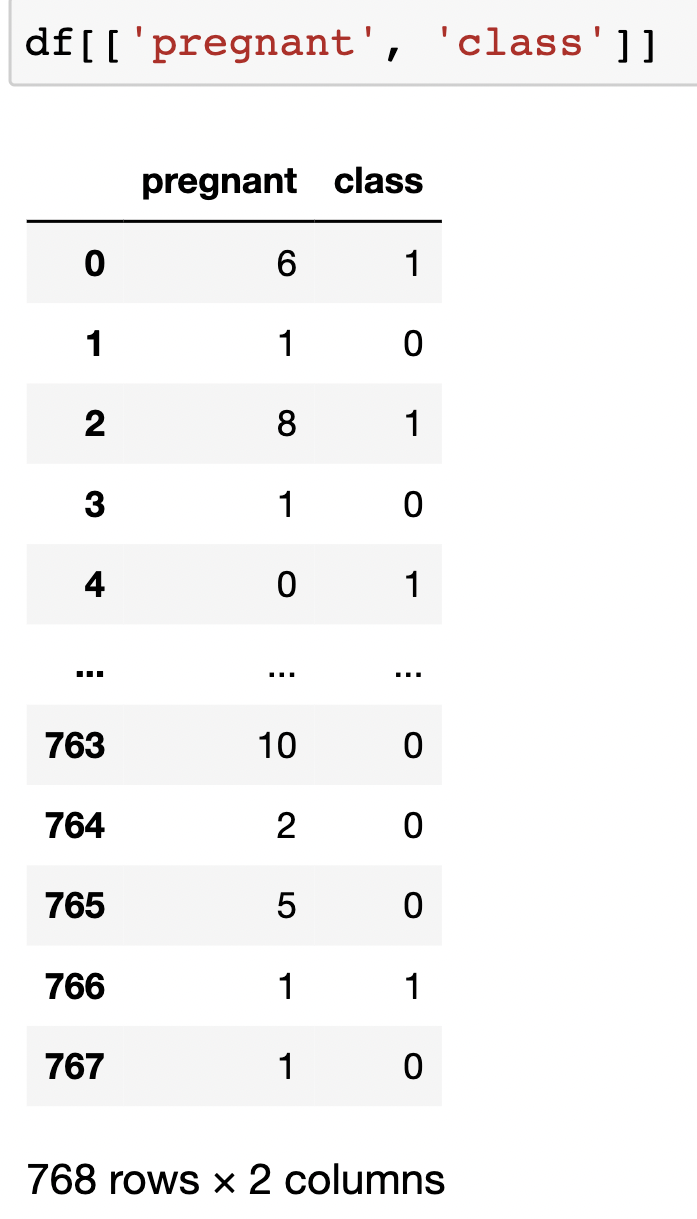
df[['pregnant', 'class']]: 데이터 일부 컬럼만 추출
3. 데이터 가공
- 목적 : 당뇨병 발병 제공 ➡️ 모든 정보는 당뇨병 발병과 무슨 관계인지에 초점을 맞춰야함
df[['pregnant', 'class']].groupby(['pregnant'], as_index=False).mean().sort_values(by='pregnant', ascending=True)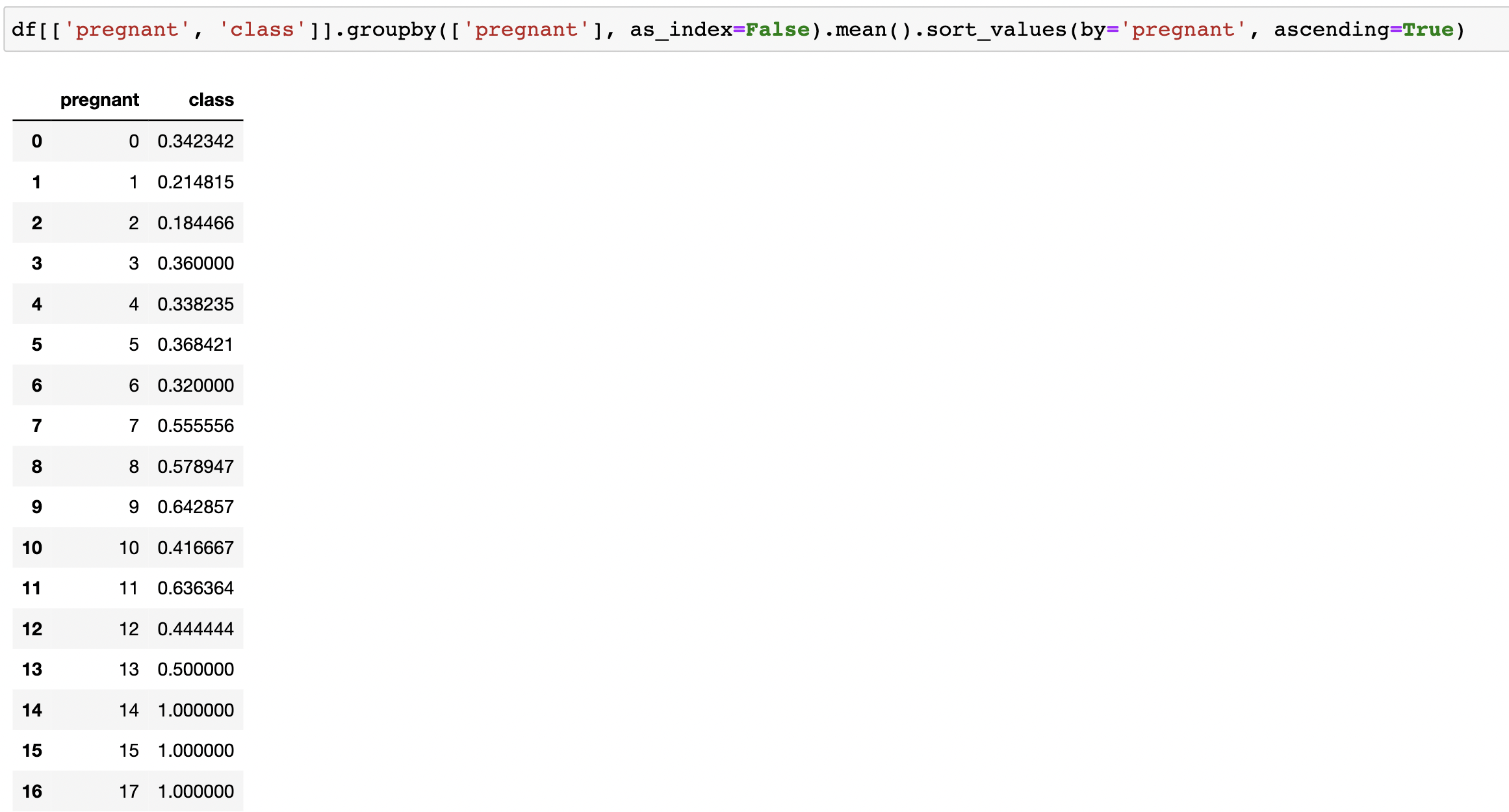
- 임신 횟수 당 당뇨병 발병률
- groupby() : pregnant를 기준으로 하는 새 그룹 생성
- as_index=False : pregnant 옆에 새로운 인덱스 만들어줌
- mean() : 평균구함
- sort_values(by='pregnant', ascending=True) : pregnant 컬럼을 오름차순으로 정렬
4. 그래프 그리기 with matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize = (12,12))
sns.heatmap(df.corr(), linewidths=0.1, vmax=0.5, cmap=plt.cm.gist_heat, linecolor='white', annot=True)
plt.show()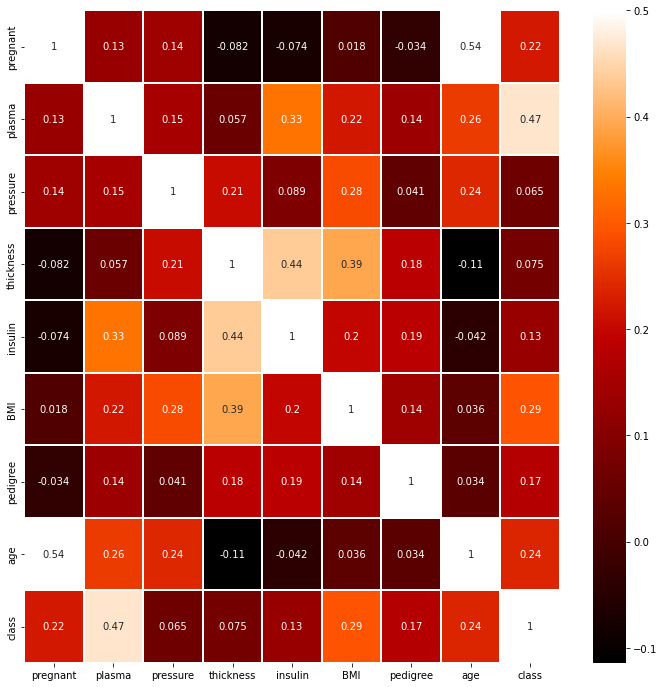
➡️ class 항목은 pregnant ~ age까지의 상관도를 숫자로 나타냄 : plasma가 가장 연관성이 높음을 확인 가능
plt.figure(figsize = (12,12)): 그래프 크기 결정sns.heatmap(): 두 항목씩 짝 지은 후 각각 어떤 패턴으로 변화하는지 관찰하는 함수 ➡️ 전혀 다른 패턴으로 변화 시 0, 서로 비슷한 패턴으로 변화 시 1로 가까워짐
grid = sns.FacetGrid(df, col='class')
grid.map(plt.hist, 'plasma', bins=10)
plt.show()➡️ 가장 연관성이 높은 plasma와 class 항목의 관계도만 따로 그래프로 표현
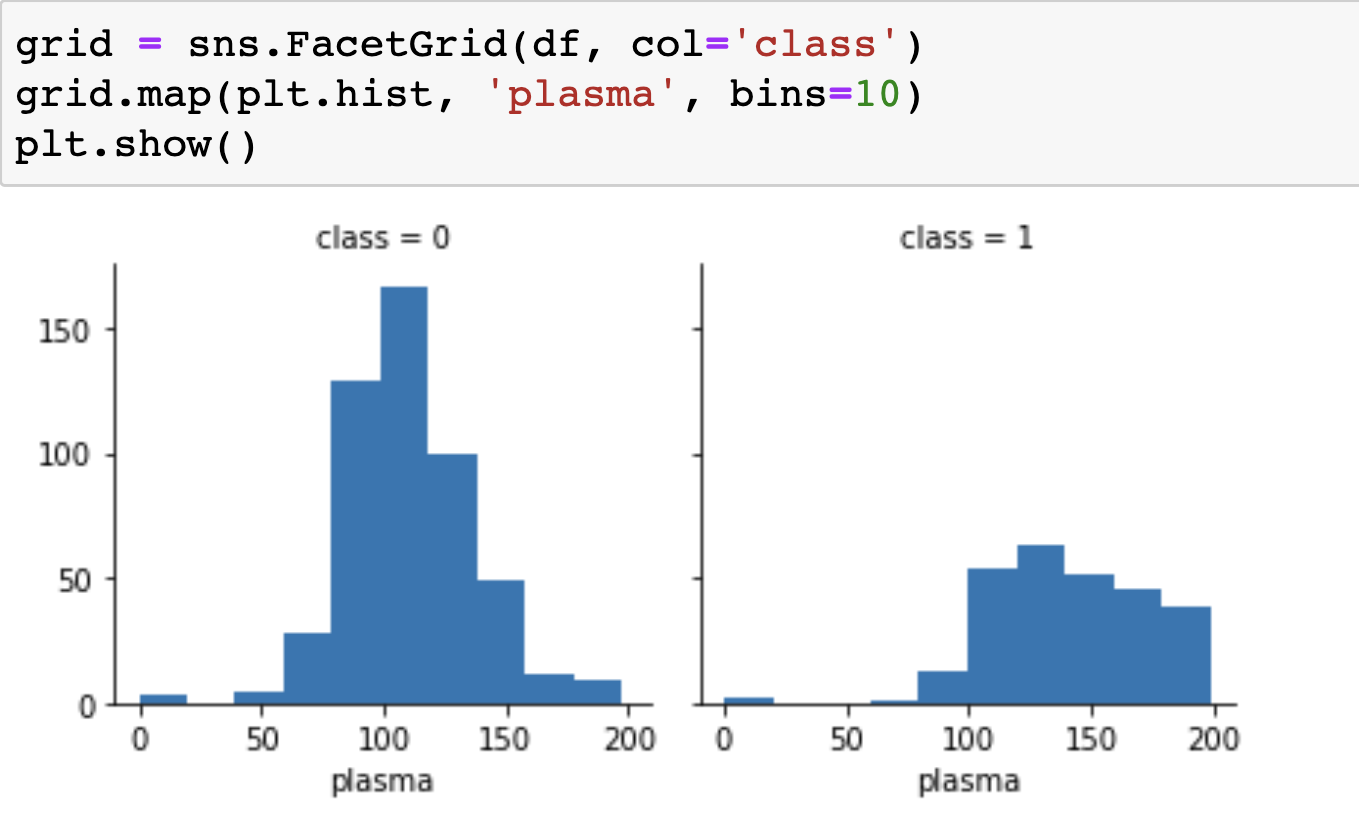
- 당뇨 환자(class=1)은 plasma 수치가 150 이상인 경우가 많음
5. 피마 인디언 당뇨병 예측 실행
seed 설정
np.random.seed(seed) tf.random.set_seed(seed)
- random() : 컴퓨터 내 내장된 랜덤 테이블 중 하나를 표로 보여줌
- seed : 랜덤 테이블 어떤 것을 불러올 것인지 결정 ➡️ seed값이 같으면 똑같은 랜덤 값 출력
✔️ 일정한 결과값을 얻기 위해서는 넘파이 seed값과 텐서플로 seed값 모두 설정해야 함
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
import tensorflow as tf
np.random.seed(3)
tf.random.set_seed(3)
dataset = np.loadtxt('pima-indians-diabetes.csv', delimiter=",")
X = dataset[:, 0:8]
Y = dataset[:, 8]
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X,Y,epochs=200,batch_size=10)
print("\n Accuracy: %.4f" % (model.evaluate(X, Y)[1]))
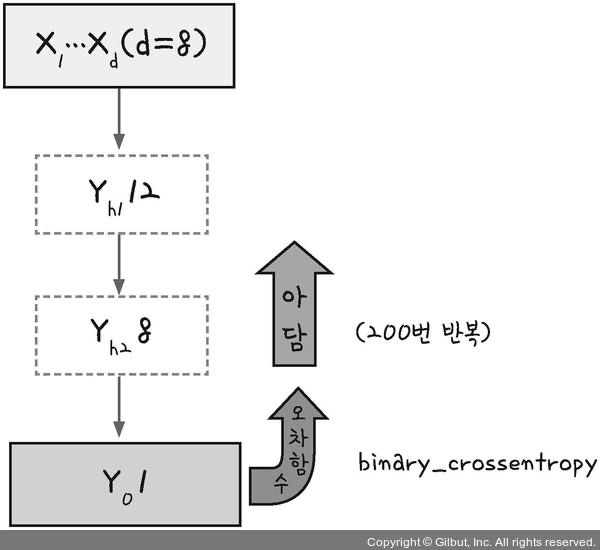
- 입력층 + 은닉층1
- 출력수 : 12
- 특성값 : 8
- 활성화 함수 : relu
- 은닉층2
- 출력수 : 8
- 활성화 함수 : relu
- 출력층
- 출력수 : 1
- 활성화 함수 : sigmoid
3. 다중 분류 문제 해결
* 아이리스 품종 예측
1. 다중분류 문제
- 다중분류 : 여러 개의 답 중 하나 고르는 분류
- 이진분류(이항분류)와는 다르게 활성화 함수를 softmax로 사용
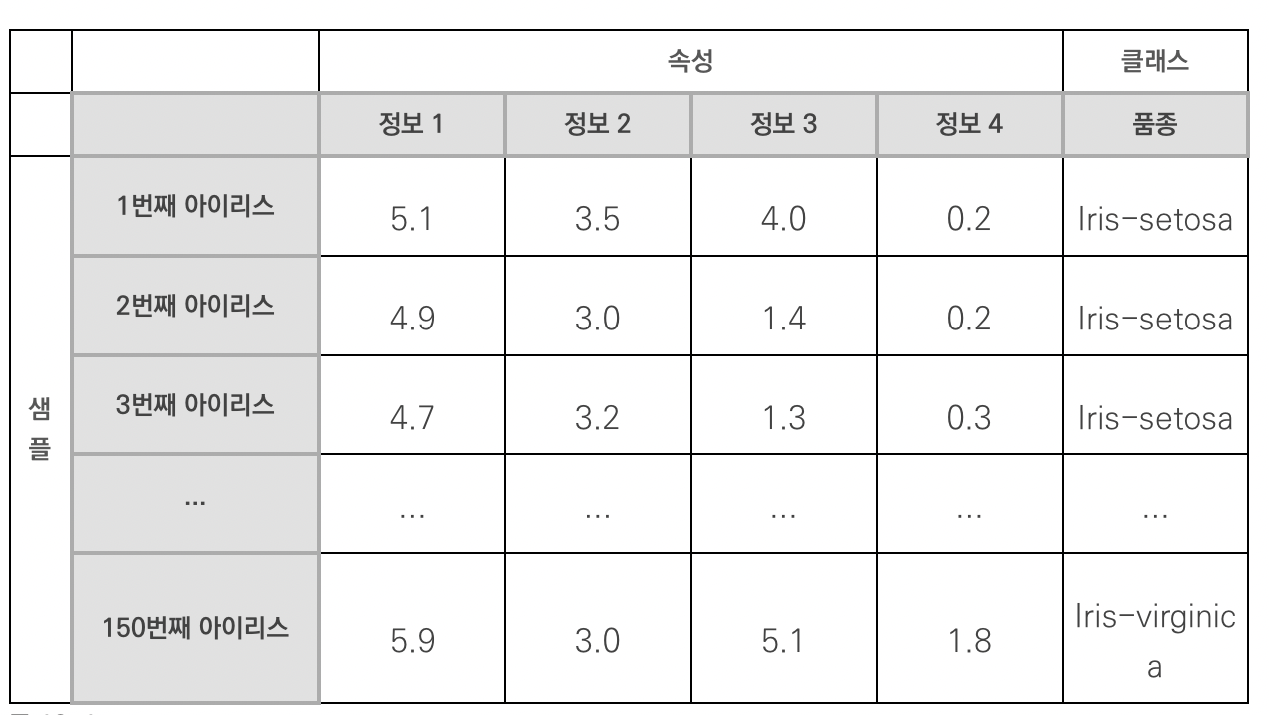
- 샘플 수 : 150
- 속성 : 4
- 정보 1 : 꽃받침 길이 (sepal length, 단위: cm)
- 정보 2 : 꽃받침 너비 (sepal width, 단위: cm)
- 정보 3 : 꽃잎 길이 (petal length, 단위: cm)
- 정보 4 : 꽃잎 너비 (petal width, 단위: cm)
- 클래스 : Iris-setosa, Iris-versicolor, Iris-virginica
2. 상관도 그래프
import pandas as pd
df = pd.read_csv('iris.csv')
df.head()
import seaborn as sns
import matplotlib.pyplot as plt
sns.pairplot(df, hue='Species')
plt.show()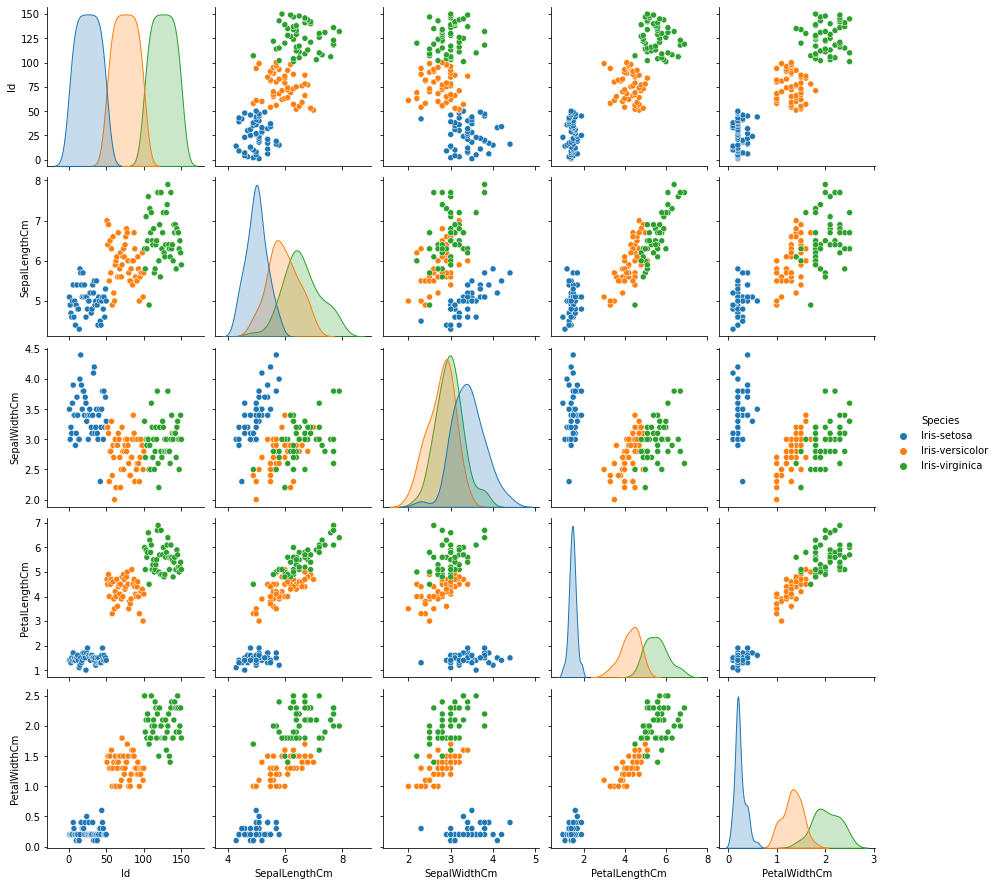
- pairplot() : 데이터 전체를 한번에 보기
- 속성별 연관도 확인 가능
3. 원-핫 인코딩
- 아이리스 품종 예측
dataset = df.values
X = dataset[:, :4].astype(float)
Y_obj = dataset[:, 4]- X : 숫자 데이터
- Y : 문자데이터
from sklearn.preprocessing import LabelEncoder
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)LabelEncoder(): 문자열을 숫자로 바꿔주려면 클래스 이름을 숫자 형태로 바꿔주면 됨- array(['Iris-setosa', 'Iris-versicolor','Iris-virginica']) ➡️ array([1,2,3])로 변경됨
‼️ 활성화 함수는 0,1로만 이뤄져있음!
- array(['Iris-setosa', 'Iris-versicolor','Iris-virginica']) ➡️ array([1,2,3])로 변경됨
from tensorflow.keras import utils
import tensorflow as tf
Y_encoded = tf.keras.utils.to_categorical(Y)to_categorical(Y): 여러 개의 Y값을 0과 1로만 이루어진 형태로 변경해줌(원핫인코딩)- array([1,2,3]) ➡️ array([[1., 0., 0.], [0., 1., 0.],[ 0., 0., 1.]])로 변경됨
4. softmax
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(16, input_dim=4, activation='relu'))
model.add(Dense(3, activation='softmax'))- 최종 출력값이 3개이므로 출력층 노드 수 3개로 수정하였음
- 소프트맥스 함수 원리
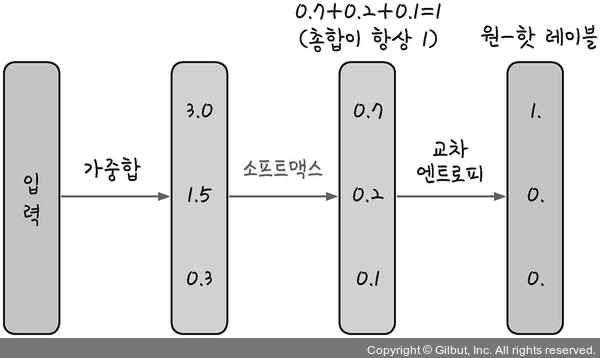
- 총합이 1인 형태로 바꾸어서 계산해주는 함수
- 합계를 1로 바꾸면 큰 값이 더 두드러지게 나타나고 작은 값은 더 작아짐
- 교차 엔트로피를 지나 [1, 0, 0], 즉, 하나만 1이고 나머지는 0인 원-핫 인코딩 값으로 변하게 됨
- 소프트맥스 함수 원리
5. 아이리스 품종 예측
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.preprocessing import LabelEncoder
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
# seed 값 설정
np.random.seed(3)
tf.random.set_seed(3)
# 데이터 입력
df = pd.read_csv('iris.csv')
# 데이터 분류
dataset = df.values
X = dataset[:,:-1].astype(float)
Y_obj = dataset[:,-1]
print(X)
# 문자열을 숫자로 변환
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)
Y_encoded = tf.keras.utils.to_categorical(Y)
print(Y_encoded)
# 모델의 설정
model = Sequential()
model.add(Dense(16, input_dim=5, activation='relu'))
model.add(Dense(3, activation='softmax'))
# 모델 컴파일
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델 실행
model.fit(X, Y_encoded, epochs=50, batch_size=1)
# 결과 출력
print('\n Accuracy: %.4f' % (model.evaluate(X, Y_encoded)[1]))- 전체 샘플이 50번 반복되게 하고 한 번에 입력되는 값은 1개
4. 과적합 피하기
* 초음파 광물 예측하기
1) 데이터의 확인과 실행
import pandas as pd
df = pd.read_csv('sonar.csv', header=None)
df.info()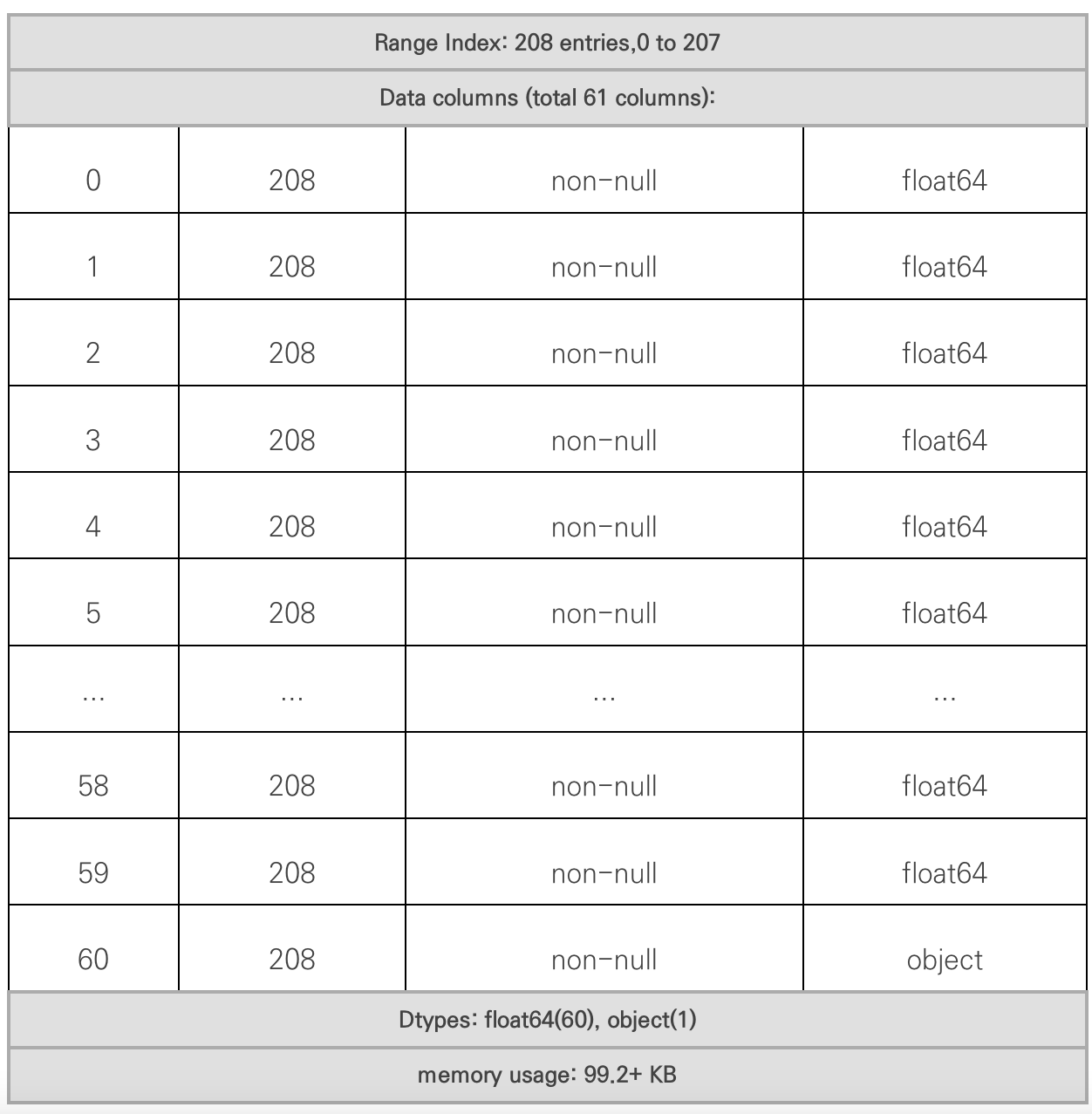
- index = 총 샘플 수 = 208개
- 컬럼 : 61개
- 속성 : 60(float형)
- 클래스 : 1(객체형) ➡️ 데이터 형 변환 필요
from keras.models import Sequential
from keras.layers.core import Dense
from sklearn.preprocessing import LabelEncoder
import pandas as pd
import numpy as np
import tensorflow as tf
np.random.seed(3)
tf.random.set_seed(3)
df = pd.read_csv('sonar.csv', header=None)
dataset = df.values
X = dataset[:, :60]
Y_obj = dataset[:, 60]
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'])
model.fit(X, Y, epochs=200, batch_size=5)
print("\n Accuracy: %.4f" % (model.evaluate(X, Y)[1]))
➡️ 정확도 : 100% 나옴 why???
2) 과적합
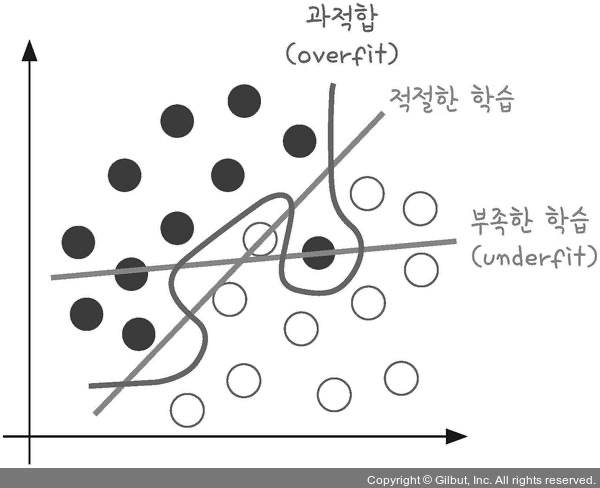
- 과적합(overfitting)
- 모델이 학습 데이터셋 안에서는 일정 수준 이상의 예측 정확도를 보이지만, 새로운 데이터에 적용하면 잘 맞지 않음
- 새로운 데이터에 적용하면 해당 선을 이용해서 정확히 두 그룹으로 나누지 못함
- 너무 층이 많거나 변수가 복잡해서 발생 / 테스트셋과 학습셋이 중복될 때 발생하기도 함
과적합 피하기 1️⃣ 학습셋과 테스트셋
- 학습데이터셋과 테스트데이터셋을 완전히 구분한 다음 학습과 동시에 테스트 병행하는 방법
- 모델 : 학습데이터로 학습을 진행 후 학습 결과 저장
- 모델은 다른 셋에 적용할 경우 학습 단계에서 각인된 그대로 동작함
➡️ 테스트셋으로 정확도를 측정해 학습률 확인- 이후 좋은 모델이 만들어졌다면 실생활에 대입
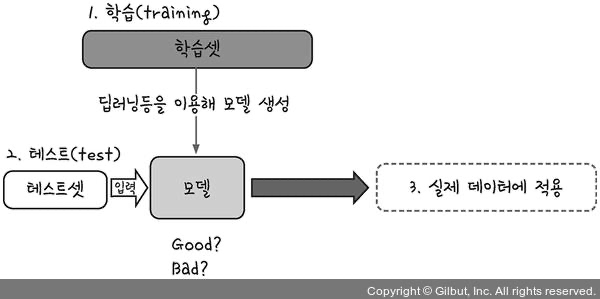
- 그렇다면 이전 코드에서는 어떻게 정확도 측정이 가능했던 걸까?
- 데이터에 있는 모든 샘플을 학습데이터로 이용했음
- 학습에 사용된 샘플을 테스트에 쓸 수 없으므로, 학습단계에서 테스트할 샘플을 자동적으로 뺌 ➡️ 테스트 샘플을 이용해 정확도 측정함
- 빠른 시간에 모델 성능을 파악하고 수정이 가능하게 함
- 학습셋만 가지고 평가할 경우
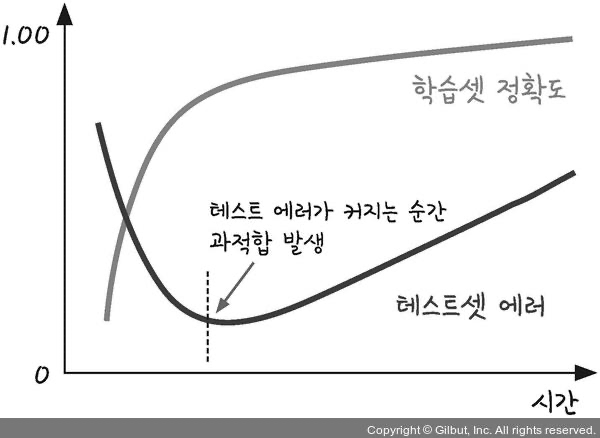
- 층을 더하거나 에포크 값을 높여 실행 횟수를 높이면 정확도 올라감
- 학습이 깊어져 학습셋 내부의 성공률은 높아져도 테스트셋에는 효과 없음 ➡️ 과적합
- 학습을 진행해도 테스트 결과가 좋아지지 않는 지점에서 학습 중단
- 학습셋만 가지고 평가할 경우
- 머신러닝 목표 : 과거의 데이터를 토대로 새로운 데이터를 예측함 ➡️ 새로운 데이터에 사용할 모델을 만들어야함
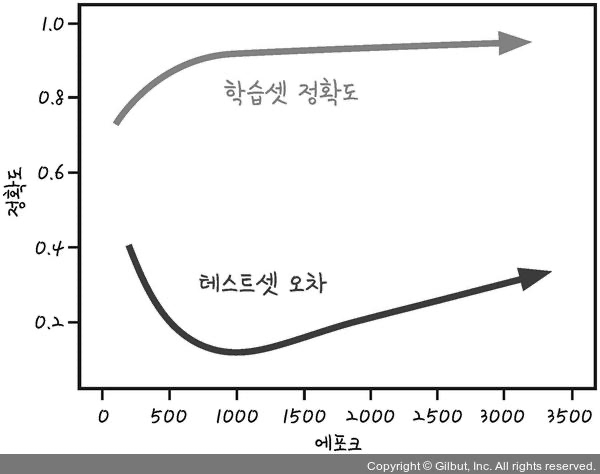
ex) 학습셋과 테스트셋 정확도 측정
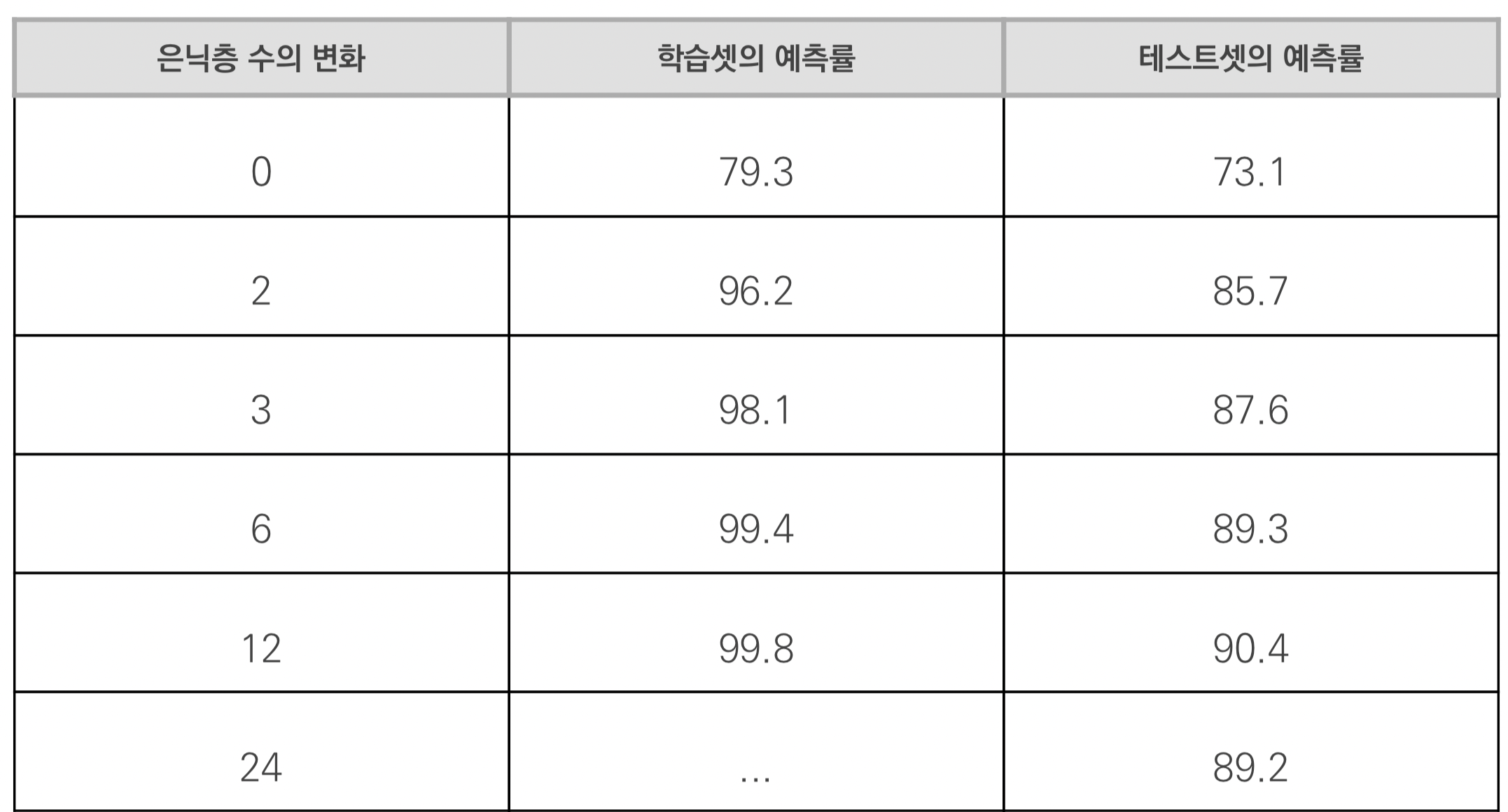
- 은닉층 수(Number of Hidden Units) 증가도에 따른 학습셋의 예측률(Average Performance on Training Sets)과 테스트셋의 예측률(Average Performance on Testing Sets)의 변화
- 24개의 은닉층에서 학습셋 예측률이 100퍼센트지만 테스트셋 예측률은 오히려 감소함
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=3)
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, Y_train, epochs=130, batch_size=5)
model.evaluate(X_test, Y_test)[1]X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=3): 테스트 셋의 비율은 전체 데이터의 30%
+)모델 저장과 재사용하기
from keras.models import Sequential, load_model
model.save('my_model.h5')#모델 컴퓨터에 저장
del model #모델 삭제
model = load_model('my_model.h5') #모델 불러오기
print("\n Test Accuracy: %.4f" % (model.evaluate(X_test, Y_test)[1]))
과적합 피하기 2️⃣ k겹 교차 검증(k-fold cross validation)
- 데이터셋을 여러개로 나누어 하나씩 테스트셋으로 사용하고 나머지를 모두 합하여 학습셋으로 사용하는 방법
- 데이터를 100% 테스트셋으로 사용 가능함
ex) 5겹 교차 검증(5-fold cross validation)
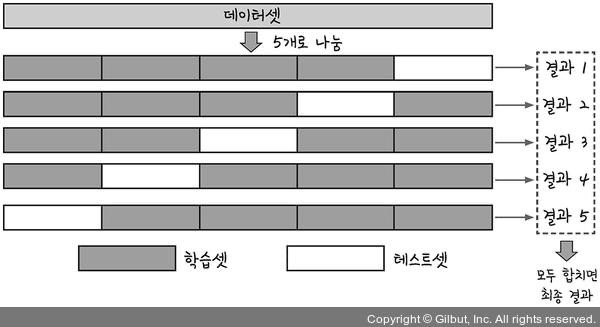
- StratifiedKFold() 함수 : 데이터를 원하는 만큼 쪼개 학습셋과 테스트셋으로 사용하게 되는 함수
from keras.models import Sequential
from keras.layers.core import Dense
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedKFold
import numpy
import pandas as pd
import tensorflow as tf
seed = 0
numpy.random.seed(seed)
tf.random.set_seed(seed)
df = pd.read_csv('sonar.csv', header=None)
dataset = df.values
X = dataset[:,0:60]
Y_obj = dataset[:,60]
e = LabelEncoder()
e.fit(Y_obj)
Y = e.transform(Y_obj)
n = 10
skf = StratifiedKFold(n_splits=n, shuffle=True, random_state=seed)
accuracy = []
# 빈 accuracy 배열
accuracy = []
# 모델의 설정, 컴파일, 실행
for train, test in skf.split(X, Y):
model = Sequential()
model.add(Dense(24, input_dim=60, activation='relu'))
model.add(Dense(10, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy'])
model.fit(X[train], Y[train], epochs=100, batch_size=5)
k_accuracy = "%.4f" % (model.evaluate(X[test], Y[test])[1])
accuracy.append(k_accuracy)
print("\n %.f fold accuracy:" % n, accuracy)
# 10 fold accuracy: ['0.7143', '0.9048', '0.7619', '0.9048', '0.8095', '0.8571', '0.8571', '0.8571', '0.9500', '0.8500']- 10겹 교차 검증 수행
- skf에는 데이터가 10개 셋으로 나눠짐
5. 베스트 모델 만들기
* 와인 종류 예측
1) 데이터 확인과 실행
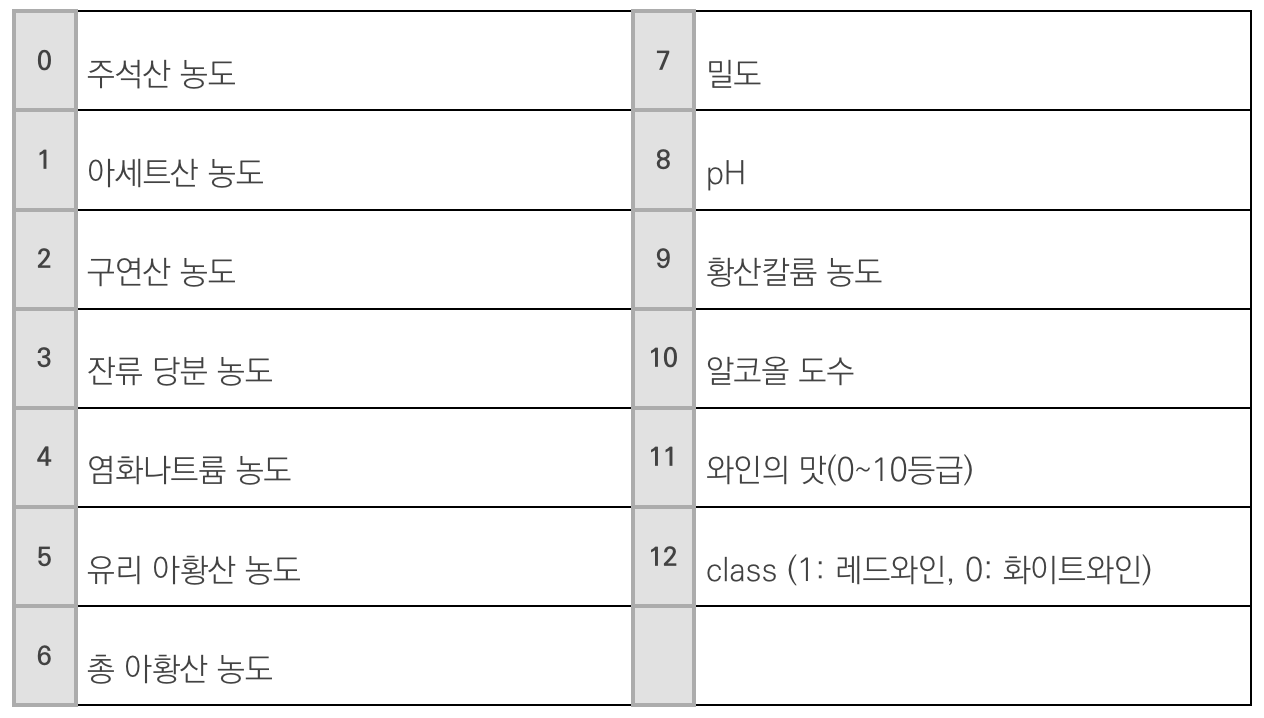
- sample() : 원본 데이터에서 정해진 비율만큼 랜덤으로 뽑아오는 함수
- frac=1 : 원본 데이터의 100% 불러온다
- frac=0.5 : 원본 데이터의 50%만 랜덤으로 불러옴
import numpy as np
import pandas as pd
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.model_selection import train_test_split
seed = 1234
df = pd.read_csv('../data/wine.csv', header=None)
df = df.sample(frac=1)
df_values = df.values
X = df_values[:, :-1].astype(float)
Y = df_values[:, -1]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=seed)
model = Sequential()
model.add(Dense(30, input_dim=12, activation='relu'))
model.add(Dense(12, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, Y_train, epochs=200, batch_size=10)
result = model.evaluate(X_test, Y_test, verbose=0)
print(result)
#[0.06677131354808807, 0.9753845930099487]- 4개의 은닉층 : 각각 30, 12, 8, 1개의 노드 주기
- 이항 분류 문제 : 오차함수는 binary_crossentropy, 최적화 함수는 adam
- 전체 샘플이 200회 반복
- 한 번에 입력되는 입력값이 200개가 되게끔 해서 종합
2) 모델 업데이트
- save() : 모델 저장
- load_model() : 모델 재사용
- 에포크별 정확도 함께 기록
import os.path
folderpath = '../data/model/' # 모델 저장하는 폴더
if not os.path.exists(folderpath): # 위 폴더가 존재하지 않는다면
os.mkdir(folderpath) # 해당 폴더를 만듦
from tensorflow.keras.callbacks import ModelCheckpoint
modelname="{epoch:02d}-{val_loss:.4f}.hdf5" #에포크 횟수와 테스트 오차값을 이용해 파일 이름 생성하기
modelpath = folderpath + modelname
checkpointer = ModelCheckpoint(
filepath=modelpath,
monitor='val_loss',
verbose=1,
save_best_only=True)
model.fit(X, Y, validation_split=0.2, epochs=200, batch_size=200, verbose=0, callbacks=[checkpointer])- checkpointer : 모니터할 값 지정
- ModelCheckpoint : model.fit() 사용해 학습을 하는 동안 일정한 주기로 모델의 상태를 저장하는 콜백
- 테스트 오차 : 케라스 내부에서 'val_loss'에 저장됨
- acc : 학습 정확도
- val_loss : 테스트셋 정확도
- loss : 학습셋 정확도
- verbose : 해당 함수의 진행 사항 출력 여부
- 1 : 출력
- 0 : 미출력
- save_best_only : 모델이 앞서 저장한 모델보다 나아졌을 경우에만 저장
- 학습할 때마다 checkpointer 값을 받아 지정된 곳에 모델 저장
- 에포크가 진행되면서 모든 값이 저장되는 것이 아니라 테스트 오차를 실행한 결괏값이 향상되었을 때만 저장됨
3) 그래프로 확인
epoch_loop = 2000
batch_cnt = 300
history = model.fit(X, Y, validation_split=0.33, epochs=epoch_loop, batch_size=batch_cnt)- 에포크를 얼마나 지정해야 할지 결정(과적합 문제)
- validation_split=0.33 : 불러온 샘플 중 33%는 테스트셋
import numpy as np
import matplotlib.pyplot as plt
x_len = np.arange(epoch_loop)
plt.plot(x_len, history.history['val_loss']) # 테스트셋으로 실험 결과의 오차값 저장
plt.plot(x_len, history.history['accuracy']) # 학습셋으로 측정한 정확도 값 저장
plt.show()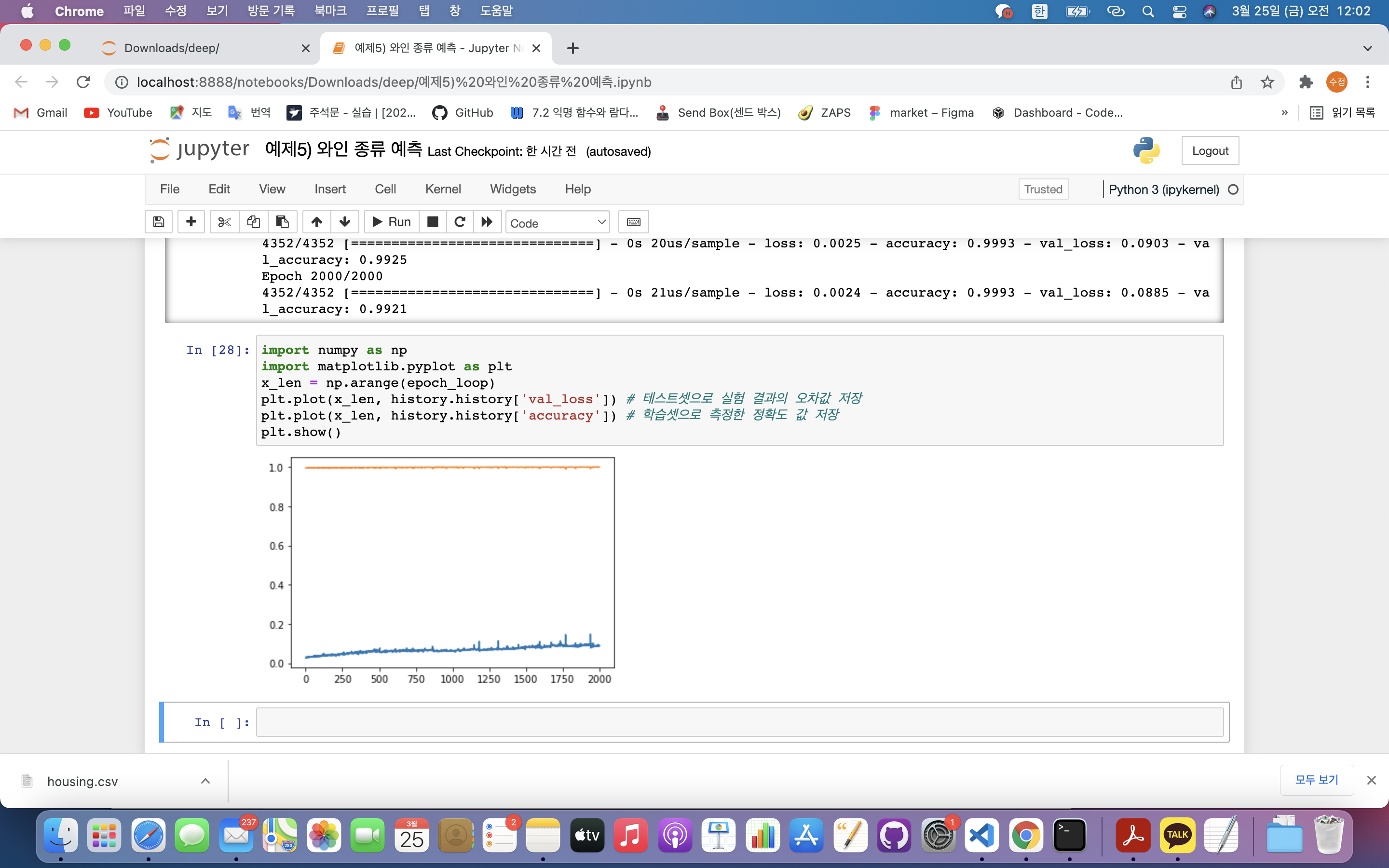
- 학습이 진행될수록 테스트셋 과적합 발생
4) 학습 자동중단
from tensorflow.keras.callbacks import EarlyStopping
es_callback = EarlyStopping(monitor='val_loss', patience=100)
history = model.fit(X, Y, validation_split=0.2, epochs=200, batch_size=200, verbose=0,
callbacks=[checkpointer, es_callback])- EarlyStopping() : 학습이 진행되어도 테스트셋 오차가 줄어들지 않으면 학습을 중단
- monitor : 모니터할 값
- patience : 테스트 오차가 좋아지지 않아도 몇 번까지 기다릴지 설정
- 모델 업데이트 함수와 학습 자동 중단 함수 동시에 사용
6. 선형 회귀 적용하기
* 보스턴 집값 예측
1) 데이터 확인하기
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
import numpy
import pandas as pd
import tensorflow as tf
df = pd.read_csv('housing.csv', delim_whitespace=True, header=None)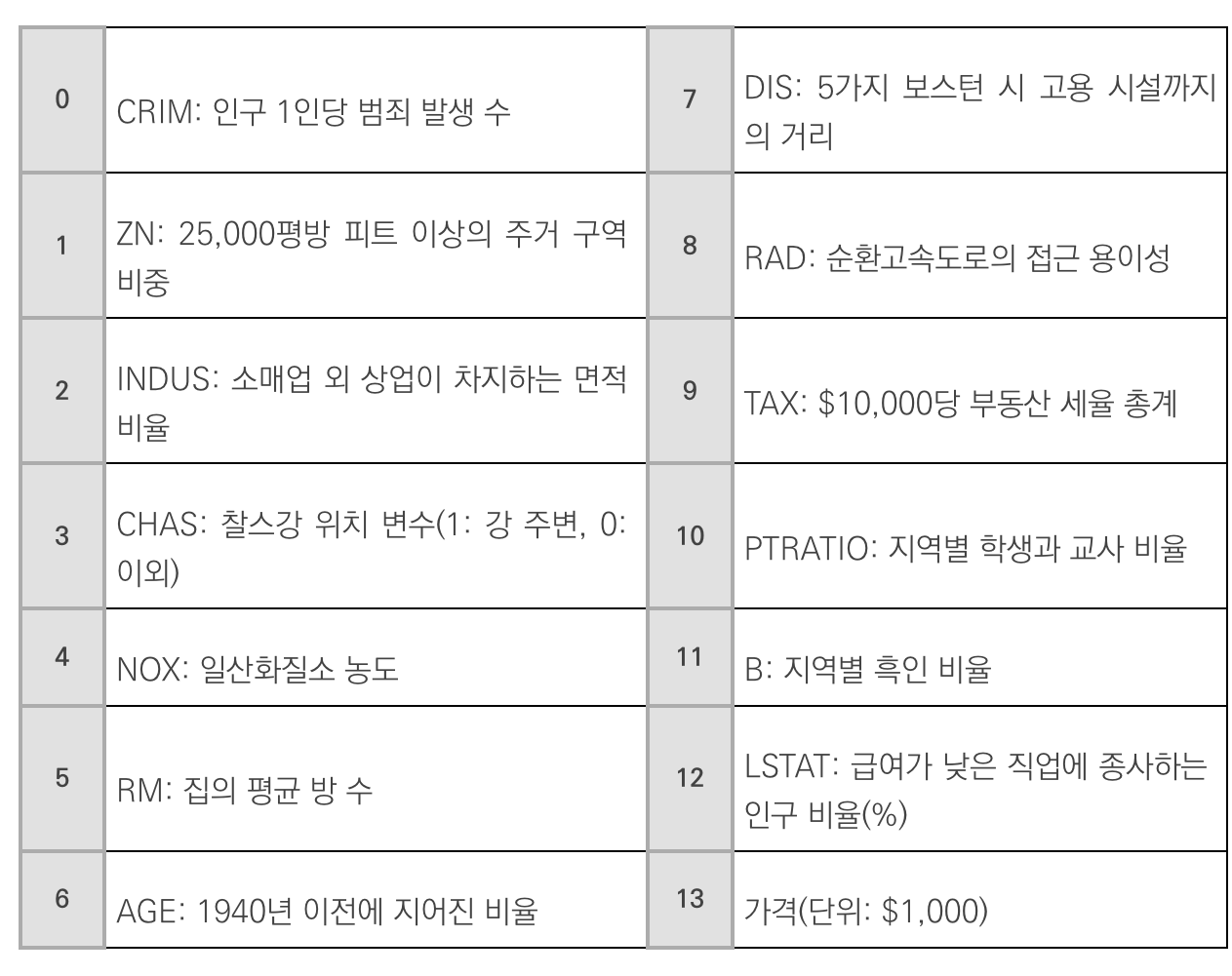
2) 선형회귀 실행
seed = 0
numpy.random.seed(seed)
tf.random.set_seed(3)
dataset = df.values
X = dataset[:,0:13]
Y = dataset[:,13]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=seed)
model = Sequential()
model.add(Dense(30, input_dim=13, activation='relu'))
model.add(Dense(6, activation='relu'))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(X_train, Y_train, epochs=200, batch_size=10)
Y_pred = model.predict(X_test).flatten()
for i in range(10):
label = Y_test[i]
pred = Y_pred[i]
print("실제가격: {:.3f}, 예상가격: {:.3f}".format(label, pred))- 선형 회귀 데이터에는 마지막에 0,1을 판단할 필요 없기 때문에 활성화 함수 지정할 필요없음
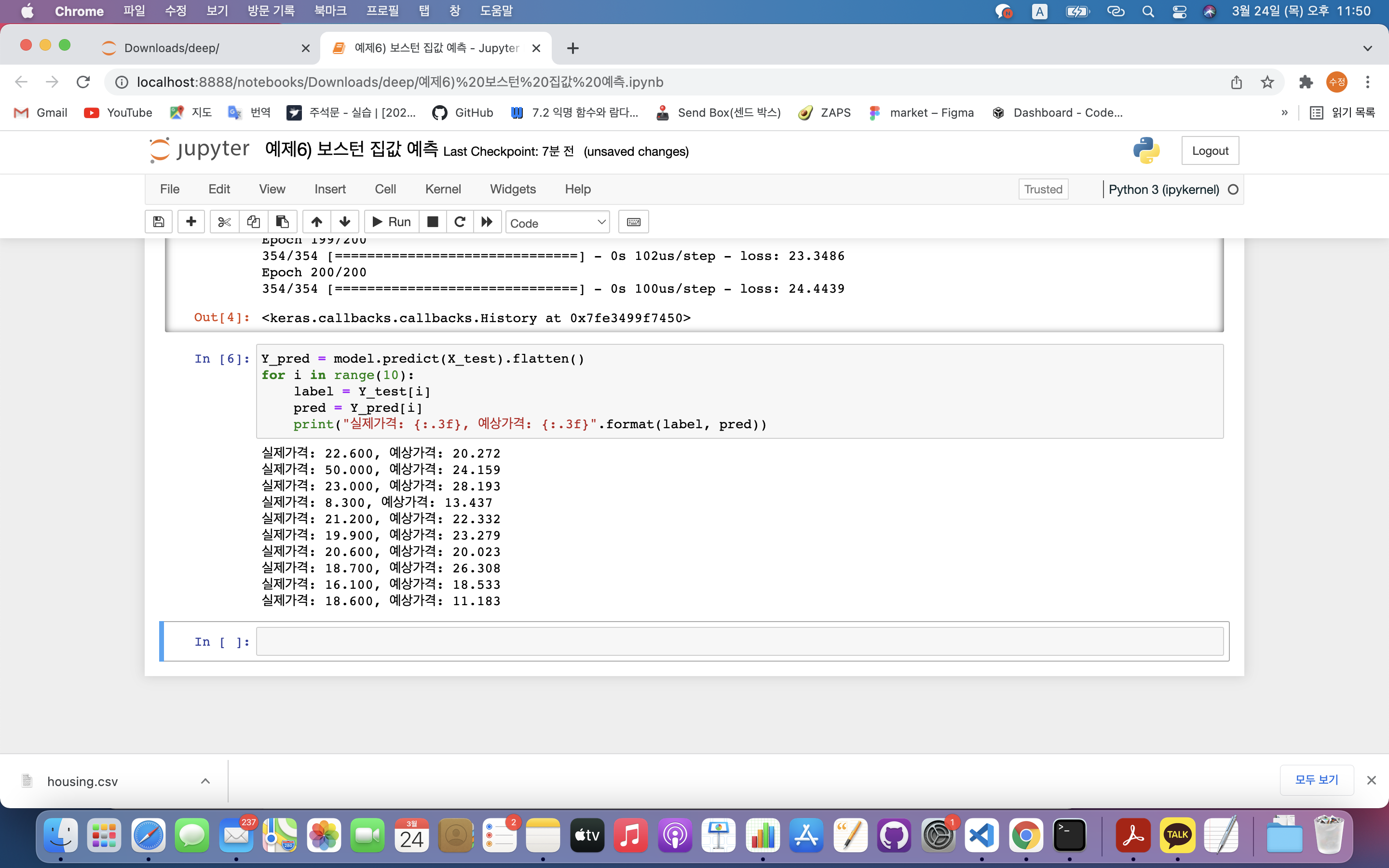
- 실제값과 예측값 비교
- flatten() : 데이터 배열을 무조건 1차원으로 변경

hello world!