1. 딥러닝 개발환경
1) 텐서플로(Tensorflow)
- 딥러닝 모델을 만들 수 있게 도와주는 프로그래밍 라이브러리
- 텐서 : 데이터
2) 케라스(keras)
- 딥러닝 만들 때 사용하는 라이브러리
- 텐서플로를 이용하기 쉽게 만들어줌 ➡️ 케라스를 이용하려면 텐서플로가 먼저 import되어 있어야 함
- 딥러닝 모델 : 하드웨어 + 하드웨어를 구동하기 위한 라이브러리 + 인공지능을 만들 수 있는 소프트웨어
- 하드웨어 : GPU, CPU
- 하드웨어를 다루는 라이브러리 : CUDA...
- 심층 신경망을 만드는 도구 : 텐서플로, 테아노, CNTK
- 위 라이브러리를 쉽게 이용할 수 있게 해줌 : 케라스
2. 숫자 인식 인공지능 만들기
CNN 이용
- MNIST 데이터셋 이용 : 0~9 숫자에 대한 손글씨 제공
1) 개발환경 만들기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import mnist
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential: 순차적인 신경망 구성할 때 사용하는 함수는 케라스의 모델(model) 도구 중 Sequential(시퀀셜) 모델from tensorflow.keras.layers import Dense, Activation: 레이어 도구 불러오기
- Activation : 활성화 함수
- Dense : 전결합층(fully-connected layer) ➡️ 각 레이어의 뉴런 개수 설정 가능
- 전결합층 : 입력층, 은닉층, 출력층 같이 각각의 층들이 바로 앞의 층과 서로 연결되어 있는 것
from tensorflow.keras.utils import to_categorical: 유틸 도구 중 to_categorical() 함수 불러오기
- to_categorical() : 원핫 인코딩 가능
- 원핫 인코딩(one-hot incoding) : 하나의 값만 1로 나타내고 나머지는 0으로 표시
ex) mnist를 원핫 인코딩으로 표시할 경우 벡터로 나타남
-> 0을 나타내는 벡터 : [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
-> 9를 나타내는 벡터 : [0, 0, 0, 0, 0, 0, 0, 0, 0, 1]from tensorflow.keras.datasets import mnist: 케라스 데이터셋 중 mnist 불러오기
2) 데이터셋 불러오기
- 훈련(train), 검증(test) 데이터 각각 필요함
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print('x_train_shape', x_train.shape)
print('y_train_shape', y_train.shape)
print('x_test_shape', x_test.shape)
print('y_test_shape', y_test.shape)
(x_train, y_train), (x_test, y_test) = mnist.load_data()- load_data() : 데이터셋을 불러오라는 의미
- mnist 데이터셋 구조 : 모두 넘파이로 만들어져 있음
| 훈련데이터 | 훈련데이터 레이블 | 검증데이터 | 검증데이터 레이블 |
|---|---|---|---|
| x_train | y_train | x_test | y_test |
| 각 손글씨 그림들 | 그림에 대한 숫자의 의미 | 각 손글씨 그림들 | 그림에 대한 숫자의 의미 |
print('x_train_shape', x_train.shape):- x_train.shape : 훈련 데이터는 6만개가 있으며, 각 데이터는 가로 28, 세로 28개의 데이터로 구성되어 있음.
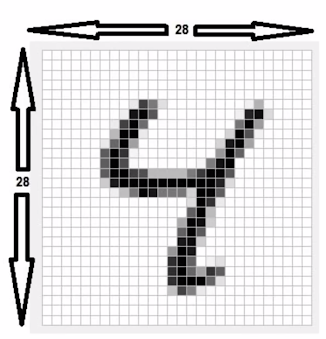
print('y_train_shape', y_train.shape): 60000개의 정답(레이블)으로 구성되어 있음 ➡️ 1차원 배열
3) mnist 데이터셋에서 X의 형태 바꾸기
- 28 X 28 형태의 2차원 배열을 인공지능 모델에 넣으려면 형태를 바꿔야함 ➡️ 1 X 784형태의 1차원 배열로 변경

X_train = x_train.reshape(60000, 784)
X_test = x_test.reshape(10000, 784)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
print("X Training matrix shape", X_train.shape)
print("X Testing matrix shape", X_test.shape)
X_train = x_train.reshape(60000, 784): (60000, 28, 28) → (60000, 784)로 데이터의 형태가 바꿈X_train = X_train.astype('float32'): X_train의 값은 정수인데 정규화를 위해 실수 형태로 형변환X_train /= 255: 마찬가지로 정규화를 위해 값들을 0~1사이의 값으로 변경해줘야 함.- 0 : 검정색
- 1 ~ 254 : 회색
- 255 : 흰색
print("X Training matrix shape", X_train.shape): 1차원 배열로 변경된 것 확인
4) mnist 데이터셋에서 Y의 형태 바꾸기
- 수치형 데이터를 범주형 데이터로 변경됨 ➡️ 성능 올릴 수 있음
- 인공지능은 3이 2와 4사이의 숫자라는 관계를 알 필요 없음
- 단순히 2와 3을 잘 구분하기만 하면 됨
- 그러므로 숫자의 의미보다는 0은 첫 번째, 1은 두번째 레이블임을 알려주면 됨
Y_train = to_categorical(y_train, 10)
Y_test = to_categorical(y_test, 10)
print("Y Training matrix shape", Y_train.shape)
print("Y Testing matrix shape", Y_test.shape)
Y_train = to_categorical(y_train, 10): 원핫 인코딩- to_categorical(변경전 데이터, 원핫 인코딩할 숫자의 개수(몇개로 구분할지 정함)) : 수치형 데이터 ➡️ 범주형 데이터

- to_categorical(변경전 데이터, 원핫 인코딩할 숫자의 개수(몇개로 구분할지 정함)) : 수치형 데이터 ➡️ 범주형 데이터
print("Y Training matrix shape", Y_train.shape): 행이 10개로 추가되었음
5) 인공지능 모델 만들기
- 4개의 층으로 구성
- 1층 : 입력층
- 2, 3층 : 은닉층
- 4층 : 출력층
model = Sequential()
model.add(Dense(512, input_shape=(784,)))
model.add(Activation('relu'))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dense(10))
model.add(Activation('softmax'))
model.summary()model = Sequential(): 딥러닝에 사용할 모델을 시퀀셜 모델로 설정model.add(Dense(512, input_shape=(784,))): 모델의 층 추가- Dense(은닉층의 노드 수, 입력하는 데이터 형태) : 층의 형태 결정
model.add(Activation('relu')): 다음 층으로 값 전달할 때 사용할 활성화 함수model.add(Dense(256)): 노드가 256개로 구성된 은닉층 생성, 데이터 형태 필요 없음model.add(Dense(10)): 마지막 층은 10개 노드로 구성 ➡️ 최종 결과값은 10개의 숫자 중 하나임model.add(Activation('softmax')): 각 노드에서 전달되는 값의 총합이 1이 되도록 하기 위함model.summary(): 모델의 구성을 볼 수 있는 함수
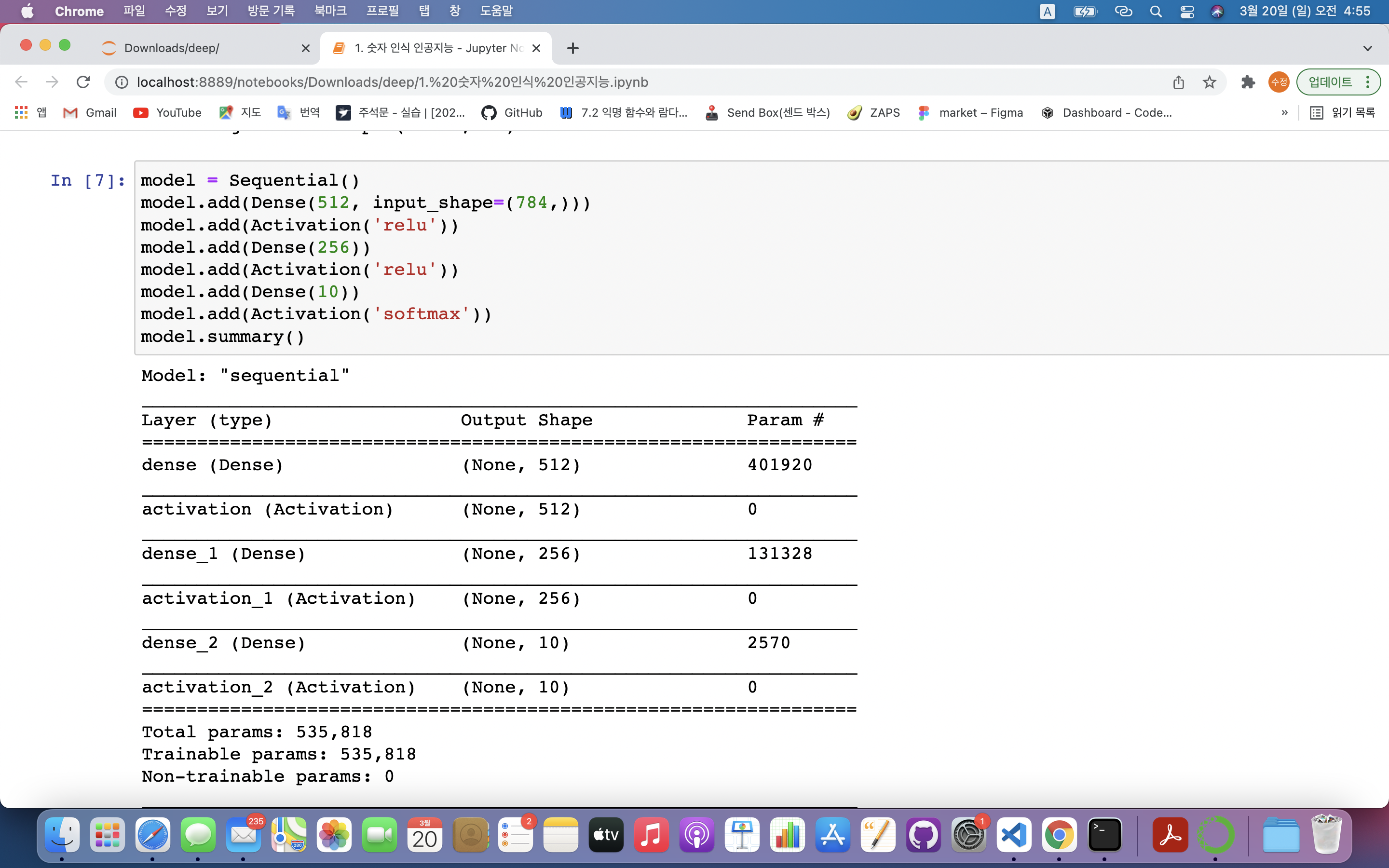
- 결과 분석
- Model: "sequential" ➡️ 시퀀셜 모델로 구성
- Layer : 레이어 부분을 나타냄
- Output Shape : 레이어의 모습
- Param # : 각 노드와 편향을 연결하는 가중치의 수
ex1) 첫번째 레이어 : 512개의 노드, 401,920(784×512+512)개의 파라미터
➡️ 편향 : 512개(=은닉층의 개수와 같음)
➡️ 가중치 : 784개의 입력층 x 512개의 은닉층
ex2) 두번째 레이어 : 256개의 노드, 131,328(512×256+256)개의 파라미터
➡️ 편향 : 256개(=은닉층의 개수와 같음)
➡️ 가중치 : 512개의 입력층 x 256개의 은닉층
ex3) 세번째 레이어 : 10개의 노드, 2,570(256×10+10)개의 파라미터
➡️ 편향 : 10개(=결과값)
➡️ 가중치 : 256개의 입력층 x 10개의 은닉층
6) 모델 학습
- 모델 실행 과정 : 데이터를 사용하여 심층 신경망을 딥러닝 기법으로 학습 ➡️ 신경망이 예측한 결과와 정답을 비교 후 오차가 있으면 재학습
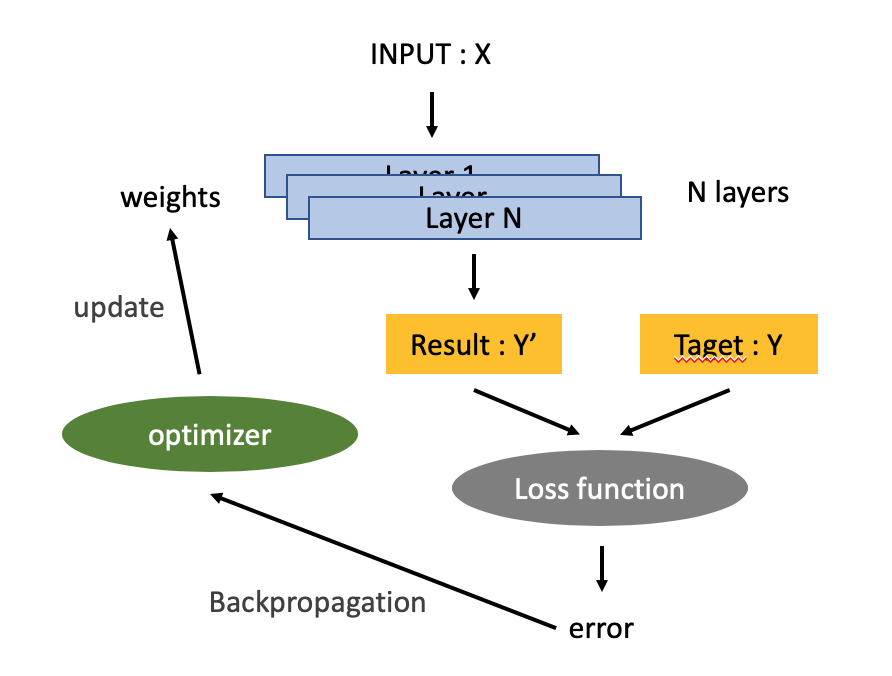
- 오차를 줄이기 위해 경사하강법 사용
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, Y_train, batch_size=128, epochs=10, verbose=1)model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']): compile()함수 = 심층신경망 학습시키는 방법 지정- loss : 오차값 계산 방법 ➡️ categorical_crossentropy(다중 분류)
- optimizer : 오차 줄이는 방법 ➡️ adam
(🟡 옵티마이저 : 경사하강법 알고리즘을 어떻게 활용할지 정함) - metrics : 학습결과 확인방법 ➡️ accuracy(정확도)
✔️정확도 : 실제 6만개의 데이터와 레이블값 비교해 정답 비율을 알려줌
model.fit(X_train, Y_train, batch_size=128, epochs=10, verbose=1): 실제 모델 학습- 데이터 : X_train, Y_train
- batch_size : 인공지능 모델이 한 번에 학습하는 데이터 수 ➡️ 한번에 128개 데이터 학습
- epochs : 모든 데이터를 1번 학습시킴 ➡️ 모든 데이터를 10번 반복 학습시킴
- verbose : fit함수의 결과값 출력
| verbose값 | 의미 |
|---|---|
| 0 | 아무런 표시도 하지 않음 |
| 1 | 에포크별 진행상황 알려줌 |
| 2 | 에포크별 학습결과를 알려줌 |
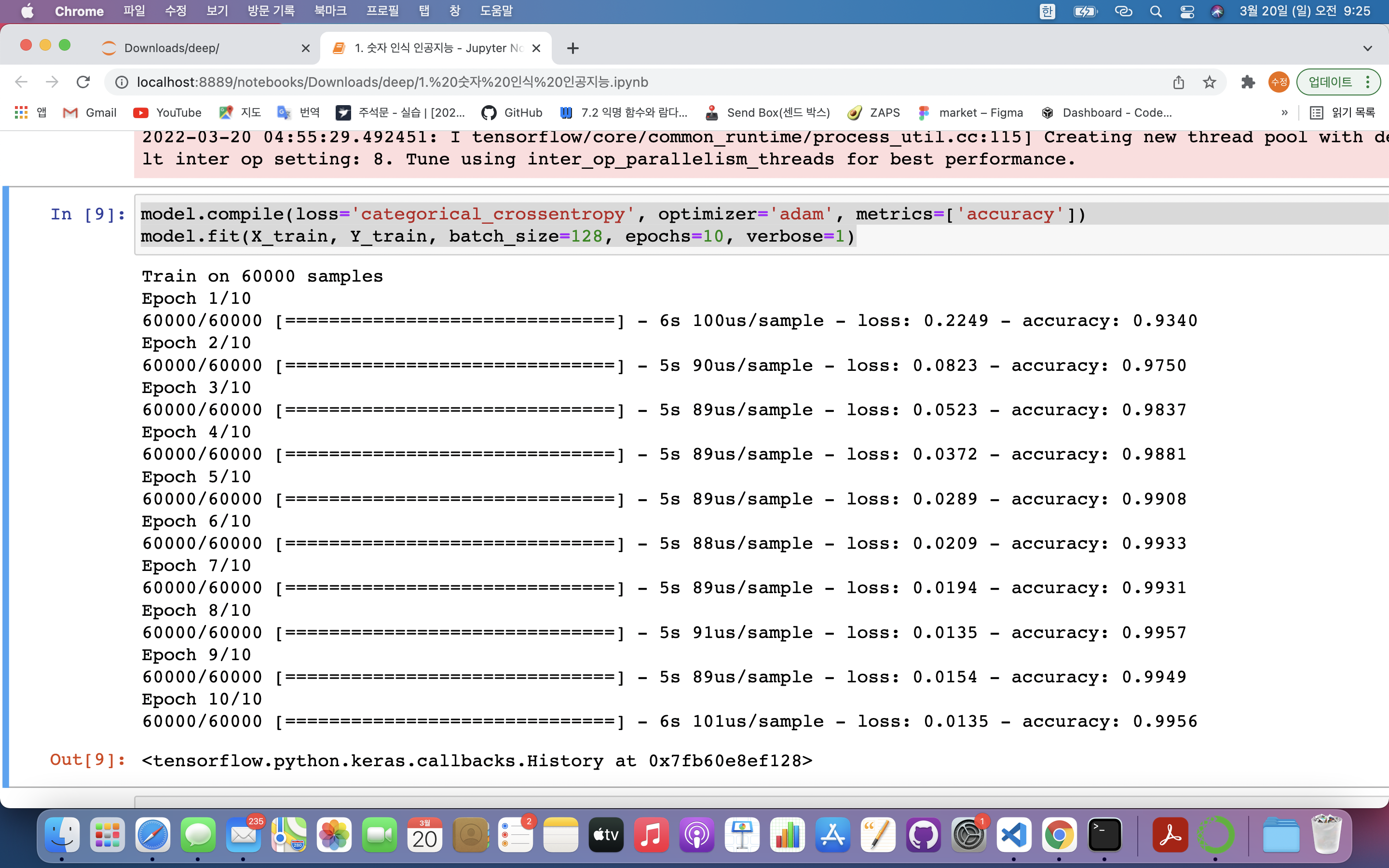
- 첫 번째 에포크에서 마지막 에포크로 갈 수록 오차값은 줄어들고 정확도는 올라감
7) 모델 성능 평가
- 검증 데이터를 얼마나 잘 맞추는가?
score = model.evaluate(X_test, Y_test)
print('Test score:', score[0])
print('Test accuracy:', score[1])score = model.evaluate(X_test, Y_test): 모델의 정확도를 평가할 수 있는 기능 제공- 첫 번째 파라미터 : 테스트할 데이터
- 두 번째 파라미터 : 테스트 데이터의 정답
- evaluate() 결과 반환
1️⃣ loss(오차값) : 0~1 사이의 값으로, 0이면 오차 없음. 1이면 오차가 큼 ➡️ score[0]에 저장됨
2️⃣ accuracy(정확도) : 모델이 예측한 값과 정답의 일치여부로 0~1사이의 값. 1에 가까울 수록 정확도가 높음. ➡️ score[1]에 저장됨
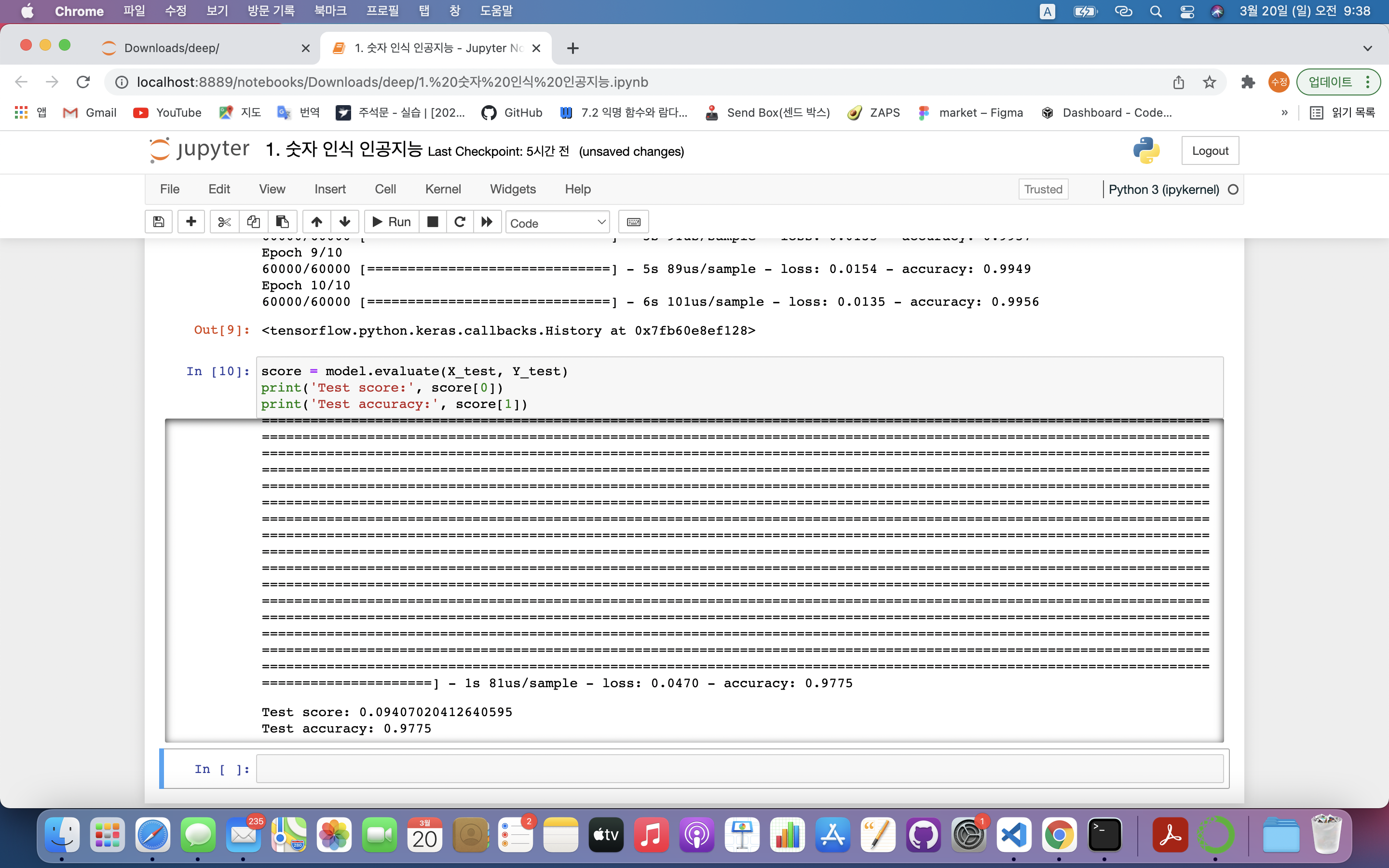
8) 모델 학습 결과
- 인공지능이 잘 구분한 데이터와 그렇지 못한 데이터 확인
predicted_classes = np.argmax(model.predict(X_test), axis=1)
correct_indices = np.nonzero(predicted_classes == y_test)[0]
incorrect_indices = np.nonzero(predicted_classes != y_test)[0]
predicted_classes = np.argmax(model.predict(X_test), axis=1)
- 결과를 예측 : predict()
- ⬆️X_test의 예측값 = 10000개
- 각 입력데이터에 따라 인공지능이 어떤 값을 예상하는지 보여줌
- softmax로 출력하였기 때문에 각 값의 예상치는 0~1 사이의 실수로 구성
- np.argmax() : 여러 데이터 중 가장 큰 값 선택
- axis=0 : 각 열(세로⬇️)에서 가장 큰 수
- axis=1 : 각 행(가로➡️)에서 가장 큰 수

correct_indices = np.nonzero(predicted_classes == y_test)[0]: 인공지능이 잘 예측한 숫자 찾기
- predicted_classes == y_test : 논리 연산자 이용하여 예측값과 레이블이 같은지 확인 ➡️ 같을 경우 1이 나옴
- np.nonzero(조건) : 조건에 부합하는 요소들의 인덱스를 리턴함
➡️0이 아닌 값의 정확한 위치를 찾아줌
ex) 1번째, 2번째, 5번째 등등 위치가 변수에 저장됨
➡️[0]의 의미 : 마스크임. 마스크 씌우지 않는 경우 배열형태로 반환이 되지 않음
incorrect_indices = np.nonzero(predicted_classes != y_test)[0]: 잘못 예측한 숫자 찾기
- predicted_classes != y_test : 논리 연산자 이용하여 예측값과 레이블이 다른지 확인 ➡️ 다를 경우 1이 나옴
- 각 결과는 1차원 배열로 저장됨
9) 시각화하기
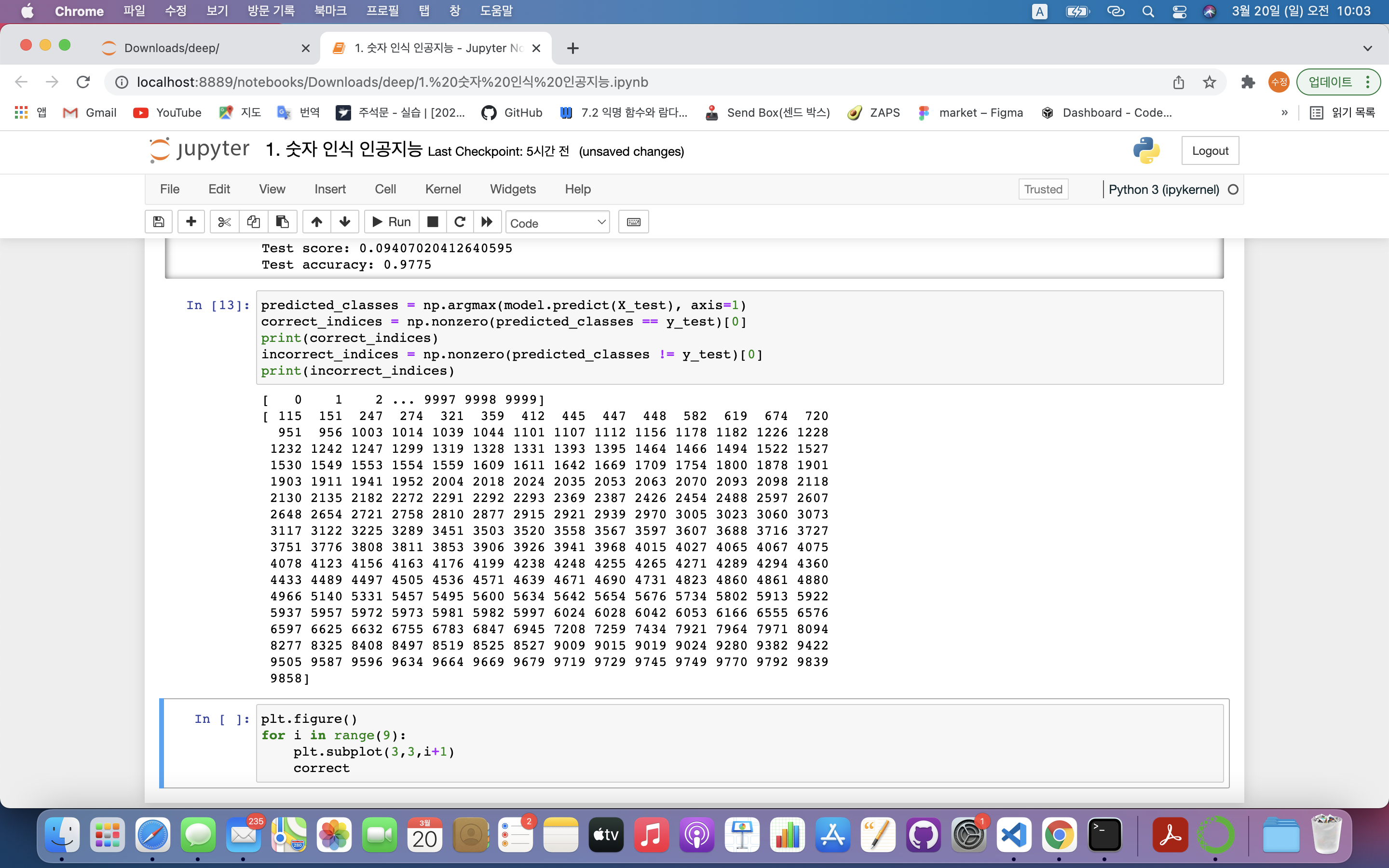
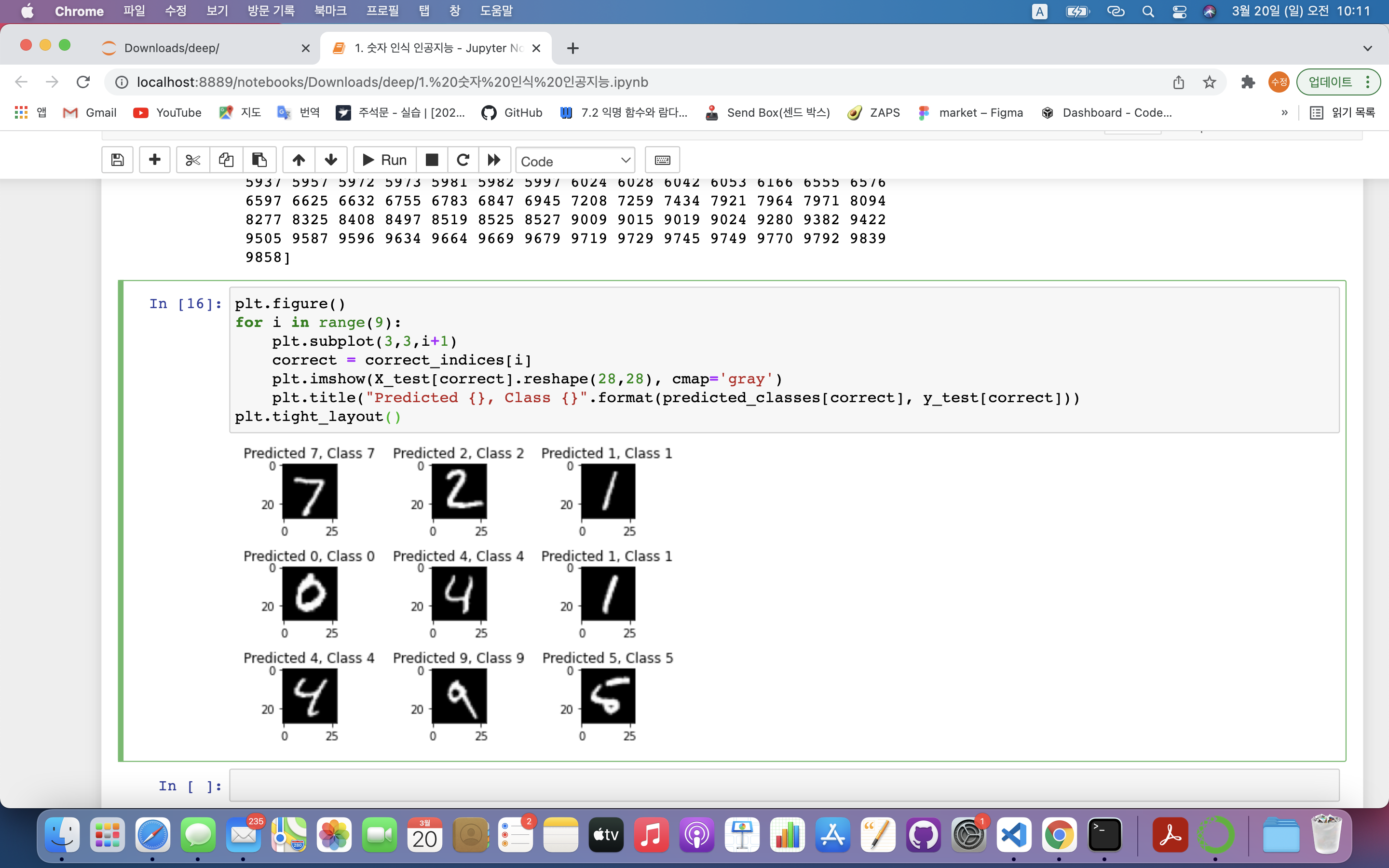
1> 잘 예측한 값 시각화
plt.figure()
for i in range(9):
plt.subplot(3,3,i+1)
correct = correct_indices[i]
plt.imshow(X_test[correct].reshape(28,28), cmap='gray')
plt.title("Predicted {}, Class {}".format(predicted_classes[correct], y_test[correct]))
plt.tight_layout()
plt.figure(): matplotlib 그래프를 그리겠다는 선언for i in range(9):: 9개의 그림만 그림plt.subplot(3,3,i+1): 그림 위치 지정
- 1️⃣ 첫 번째 인자 : 그림의 가로 개수
- 2️⃣ 두 번째 인자 : 그림의 세로 개수
- 3️⃣ 세 번째 인자 : 순서
➡️ 3 X 3 그림을 그릴 것이며 루프를 반복해나가면서 순차적으로 그림 삽입correct = correct_indices[i]: correct_indices에 저장된 정답이 9개 저장plt.imshow(X_test[correct].reshape(28,28), cmap='gray'): 어떤 이미지를 보여줄지 결정
- X_test[correct] : X_test에서 정답인 값 가져옴
- reshape(28,28) : X_test의 데이터값은 1차원 배열로 되어있으므로 2차원 배열로 reshape해줌
- cmap='gray' : 그림을 회색조로 표현
plt.title("Predicted {}, Class {}".format(predicted_classes[correct], y_test[correct])): 그림의 설명을 넣어줌plt.tight_layout(): 화면에 그림을 보여줌
2> 잘못 예측한 값 시각화
plt.figure()
for i in range(9):
plt.subplot(3,3,i+1)
incorrect = incorrect_indices[i]
plt.imshow(X_test[incorrect].reshape(28,28), cmap='gray')
plt.title("Predicted {}, Class {}".format(predicted_classes[incorrect], y_test[incorrect]))
plt.tight_layout()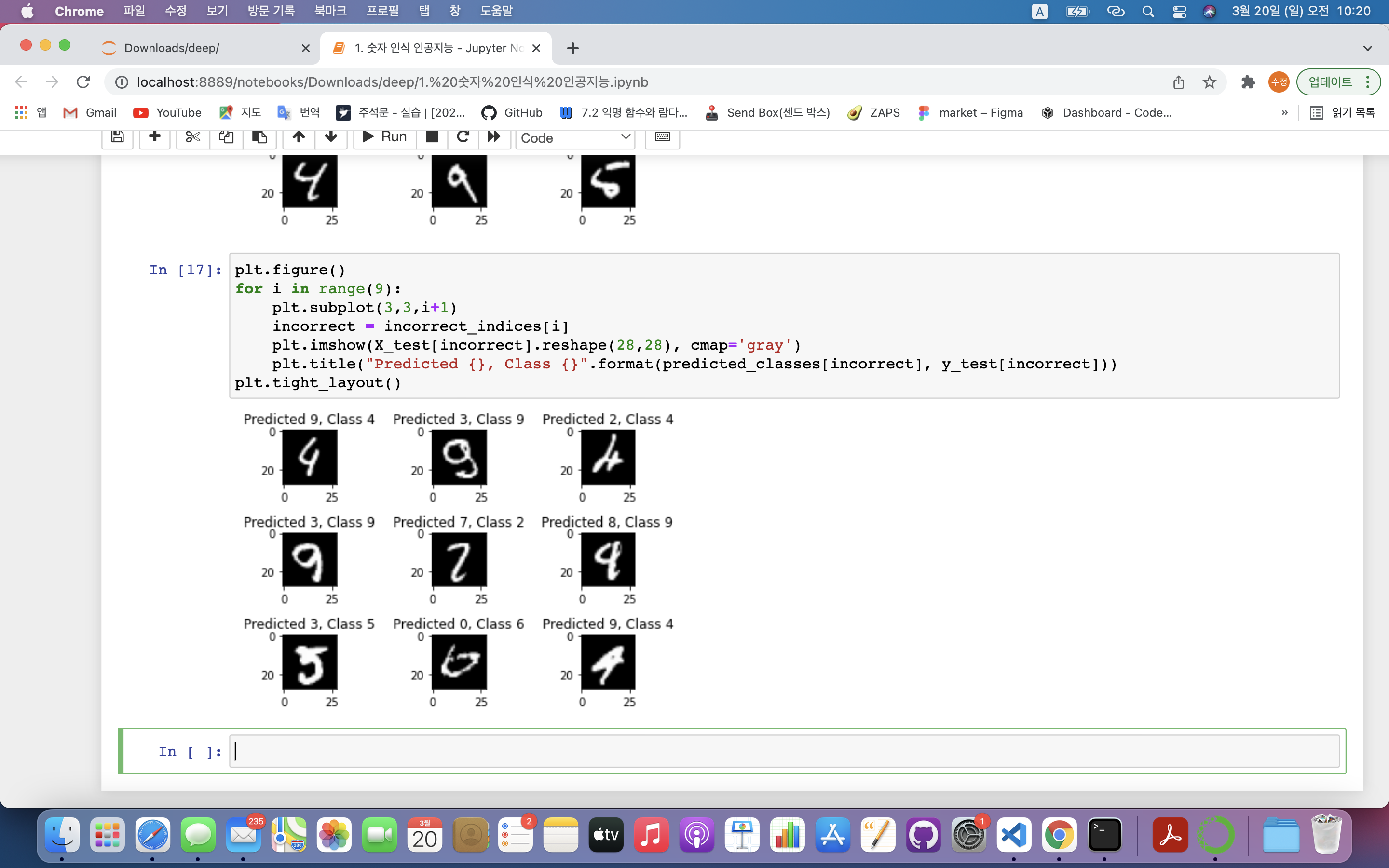
3. 전염병 예측 인공지능 만들기
RNN 이용
- 이전 확진자 수를 토대로 다음날 확진자 수 예측하는 모델 생성
1) 개발환경
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import math
import numpy as np
import matplotlib.pyplot as plt
from pandas import read_csvfrom tensorflow.keras.layers import SimpleRNN, Dense: 순환신경망을 표현하는 3가지 기법- SimpleRNN : 가장 기본적인 순환 신경망
- LSTM, GRU : SimpleRNN 심화 버전
from sklearn.preprocessing import MinMaxScaler: 데이터 정규화를 위해 MinMaxScaler를 불러옴 ➡️ 데이터를 인공지능에 넣기 전에 모델에 적합하게 만드는 함수from sklearn.metrics import mean_squared_error: 결과의 정확도를 계산하기 위해 mean_squared_error 함수 불러옴 ➡️ 회귀 문제이기 때문에 오차 계산은 MSE로 함.from sklearn.model_selection import train_test_split: 데이터를 훈련 데이터와 테스트 데이터로 나눔
2) 데이터 가져오기
target = "https://raw.githubusercontent.com/yhlee1627/deeplearning/master/corona_daily.csv"
dataframe = read_csv(target, usecols=[3], engine='python', skipfooter=3)
print(dataframe)
dataset = dataframe.values
dataset = dataset.astype('float32')+) github clone이 실패하여 그 대신 csv파일의 raw url을 사용하여 데이터를 읽어옴.
- 데이터 구조
- Date : 날짜
- Inspected : 검사자 수
- Negative : 검사자 중 음성
- Confirmed : 검사자 중 양성
- Recovered : 양성 중 회복
- Death : 양성 중 사망
dataframe = read_csv(target, usecols=[3], engine='python', skipfooter=3): 3번째 열(Confirmed)만 사용하여 모델 생성할 거임.- 1️⃣ 첫번째 파라미터 : 파일 경로
- 2️⃣ 두번째 파라미터 : 사용할 데이터
- 3️⃣ 세번째 파라미터 : 사용할 언어
dataset = dataframe.values: 꼭 필요한 값만 가져옴 ➡️ 사용할 데이터(확진자 수)만 추출- dataframe : 각 데이터에 대한 설명, 데이터 순서 포함되어 있음.
- dataframe : 각 데이터에 대한 설명, 데이터 순서 포함되어 있음.
dataset = dataset.astype('float32'): 정규화를 위해 실수로 변경(정규화는 보통 나눗셈으로 함) ➡️ 읽어온 데이터는 정수형이므로 실수형으로 변경해줌
3) 데이터 정규화 및 분류
- 데이터 정규화 : 0~1 사이의 숫자로 변경
scaler = MinMaxScaler(feature_range=(0,1))
Dataset = scaler.fit_transform(dataset)
train_data, test_data = train_test_split(Dataset, test_size=0.2, shuffle=False)
print(len(train_data), len(test_data)) # 89 23 출력scaler = MinMaxScaler(feature_range=(0,1)): 데이터 정규화를 위해 사이킷런의 MinMaxScaler 함수 이용 ➡️ 정규화 방법을 scaler로 지정하고 데이터 정규화 범위를 0~1 사이로 지정

- 스케일링 : 데이터 모델링 전 반드시 거쳐야하는 과정
➡️ 사이킷런에서는 다양한 스케일러 제공- 1️⃣ MinMaxScaler : 최대/최소값이 각각 1, 0이 되게 함. 즉 모든 데이터는 0~1 사이에 있음
- 스케일링 : 데이터 모델링 전 반드시 거쳐야하는 과정
Dataset = scaler.fit_transform(dataset): 데이터 정규화- 스케일러 : fit, transform 메서드를 가지고 있음
- 1️⃣ fit : 훈련 데이터에만 적용하여 훈련 데이터의 분포 우선 학습
- 2️⃣ transform : 훈련 데이터와 테스트 데이터에 적용하여 스케일 조정
➡️ 즉, 훈련 데이터 : fit_transform(), 검증 데이터 : transform() 함수 적용
- 스케일러 : fit, transform 메서드를 가지고 있음
train_data, test_data = train_test_split(Dataset, test_size=0.2, shuffle=False): 전체데이터를 훈련 데이터와 검증 데이터로 나눔- Dataset : 분류할 데이터
- test_size : 검증 데이터 비율 ➡️ 20%
- shuffle=False : 추출 방법
- 데이터 추출 방법
1️⃣ 무작위 추출 : shuffle=True
2️⃣ 순차 추출 : shuffle=False ➡️ 시계열 데이터(날짜 등)에서 주로 사용
- 데이터 추출 방법
4) 데이터 형태 변경
- 예측된 데이터 모습을 연속적인 형태로 변경해야함
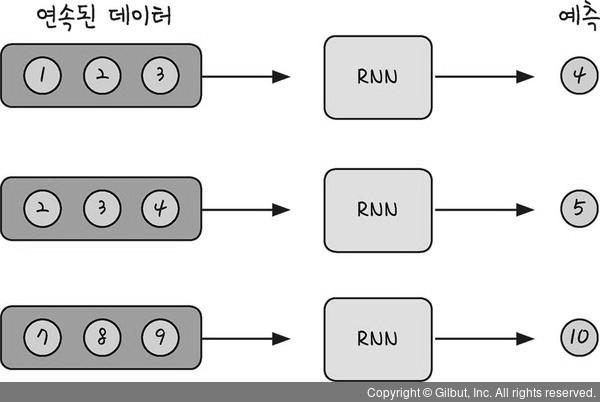
- 3일치 확진자 수 토대로 다음날 확진자 수 예측

- 왼쪽과 같이 한 줄로 나열된 데이터를 연속된 데이터 형태로 변경해 주어야 함

- x_data와 y_data 형태
def create_dataset(dataset, look_back):
x_data = []
y_data = []
for i in range(len(dataset) - look_back - 1):
data = dataset[i:(i+look_back), 0]
x_data.append(data)
y_data.append(dataset[i + look_back, 0])
return np.array(x_data), np.array(y_data)def create_dataset(dataset, look_back):- 첫번째 파라미터 : 원래의 데이터
- 두번째 파라미터 : 연속되는 데이터의 개수
x_data = []; y_data = []: 데이터를 넣을 빈 배열 생성- x_data : n~n+2일차 데이터
- y_data : n+3일차 데이터 ➡️ 인공지능이 학습할 데이터
- 즉, 10일치 데이터가 있는 경우 7번의 반복이 필요함
for i in range(len(dataset) - look_back - 1):: 전체 길이에서 연속되어야 하는 데이터 개수 제외data = dataset[i:(i+look_back), 0]: 전체 데이터 중 i부터 i+2까지의 데이터를 추출, 그 중 인덱스가 0번인 첫번째 열(확진자 수가 있음)에서 데이터 추출함x_data.append(data): 앞에서 추출한 연속 3개 데이터를 배열에 추가함y_data.append(dataset[i + look_back, 0]): 추출한 연속된 3개의 데이터 이후의 데이터를 y_data에 추가함return np.array(x_data), np.array(y_data): 계산이 용이하도록 numpy 배열형태로 변경
5) 입력 데이터 생성
- 실제 인공지능 모델에 입력할 수 있는 데이터 만들기
look_back = 3
x_train, y_train = create_dataset(train_data, look_back)
x_test, y_test = create_dataset(test_data, look_back)
print(x_train.shape, y_train.shape) # (85, 3) (85,)
print(x_test.shape, y_test.shape) #(19, 3) (19,)x_train, y_train = create_dataset(train_data, look_back):- x_train : 85개의 행과 3개의 열로 이루어져 있음(연속된 3개의 데이터가 열로 존재)
- y_train : label이므로 다음날 확진자 수만 존재(1차원임)
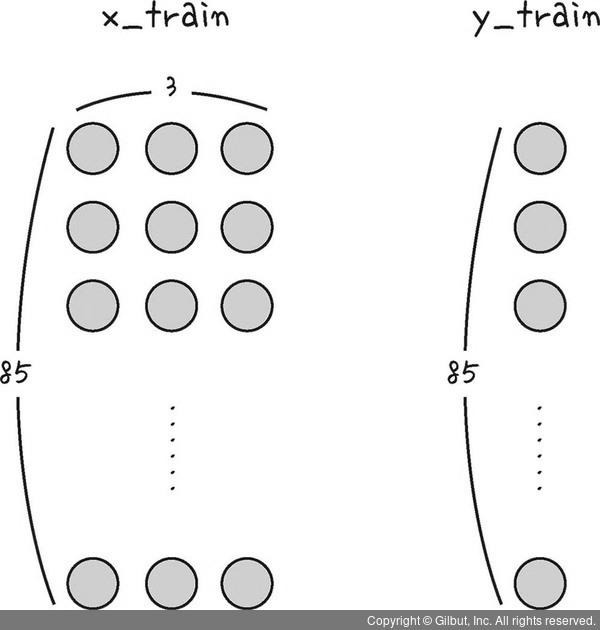
6) 인공지능에 넣을 데이터 형태로 바꿔주기
- 데이터를 3차원 배열로 변환 ➡️ 1 X 3 형태의 배열을 모델에 한 줄씩 85번 넣기 위함.
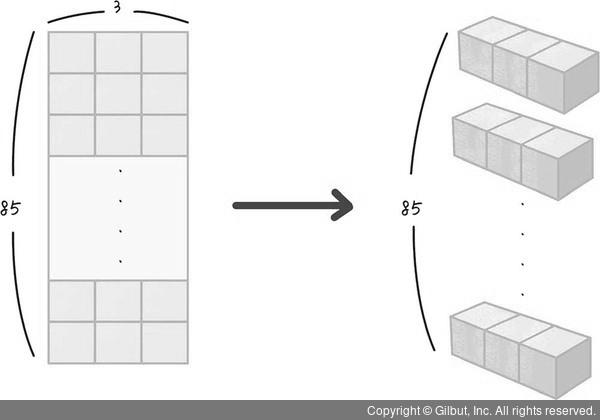
X_train= np.reshape(x_train, (x_train.shape[0], 1, x_train.shape[1]))
X_test = np.reshape(x_test, (x_test.shape[0], 1, x_test.shape[1]))
print(X_train.shape) #(85, 1, 3)
print(X_test.shape) #(19, 1, 3)X_train= np.reshape(x_train, (x_train.shape[0], 1, x_train.shape[1])): 바꿀 데이터(x_train)와 어떤 형태로 바꿀지 입력- x_train.shape[0] : x_train.shape의 첫 번째 결과 값 ➡️ 85
- x_train.shape[1] : x_train.shape의 두 번째 결과 값 ➡️ 3
7) 인공지능 모델
- 순환 신경망 : 신경망의 학습에서 순환적인 학습을 하는 모델
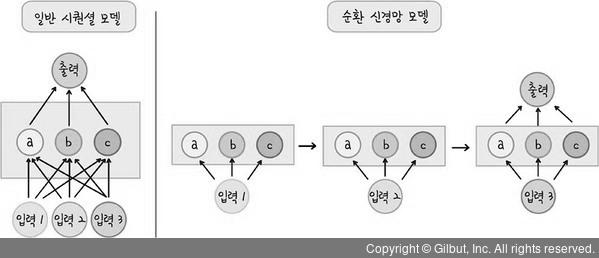
- 입력 데이터 : 3일치 기준으로 출력값 예측이기 때문에 입력값은 3개임
- 은닉층 a,b,c : 한 번에 데이터를 넣는 것이 아닌 순차적으로 데이터 입력
1️⃣ 첫번째 데이터를 넣고 은닉층에 있는 파라미터들(가중치, 편향) 학습
2️⃣ 얻은 결과값을 출력하지 않고 다음 두번째 입력 데이터와 함께 학습
3️⃣ 결과를 다음 단계로 넘겨주며 세번째 입력 데이터와 학습 후 최종값 예측하여 출력
- 은닉층 a,b,c : 한 번에 데이터를 넣는 것이 아닌 순차적으로 데이터 입력
model = Sequential()
model.add(SimpleRNN(3, input_shape=(1, look_back)))
model.add(Dense(1, activation="linear"))
model.compile(loss='mse', optimizer='adam')
model.summary()model = Sequential(): RNN 모델도 결국은 레이어들이 선형으로 연결된 모습이기 때문에 시퀀셜 모델로 설정model.add(SimpleRNN(3, input_shape=(1, look_back)))- SimpleRNN 뉴런의 개수 : 3
- SimpleRNN input_shape : 어떤 데이터 형태를 넣을지 결정 ➡️ (1, look_back) 이기 때문에 1Xlook_back 형태의 2차원 배열을 넣을 것.
model.add(Dense(1, activation="linear")): 최종 예측 값은 확진자 수, 즉, 값은 1개뿐이므로 1개 노드만 구성함model.compile(loss='mse', optimizer='adam'): 인공지능 계산- loss = 'mse' : |실제 확진자 수 - 예측한 수|^2
- 옵티마이저 : 아담
summary: 생성된 모델 요약
- 결과분석
- simple_rnn (Simple RNN) : Simple RNN 사용
- Output Shape : 총 노드의 수(3개)
- Param : simple_rnn의 파라미터(가중치, 편향)의 수
- dense (Dense) : 출력층의 형태 및 파라미터 수
💢 tensorflow와 numpy 버전 호환성 문제로 오류가 발생하였음(22.3.20)
- python : 3.7.11
- tensorflow : 2.0.0
- numpy : 1.19.2
- 해결 방법
1️⃣ 터미널에서 새로운 가상환경 생성(아나콘다 입력 시 해당 패키지도 동시 설치됨) : conda create -n tf2 anaconda
➡️ 파이썬 버전을 맞춰서 가상환경 생성하기 원한다면, pip python=3.7.0 이런식으로 가상환경 이름 뒤에 적어주면 됨. 따로 안 적어주면 아나콘다 최신 버전으로 설치됨
2️⃣ 설치 완료 되면 가상환경으로 이동(base는 건들지 않을 예정) : conda activate tf2
3️⃣ 파이썬 버전 맞춰주기 : conda search python(설치가능한 파이썬 버전을 보여줌) ➡️ conda install python=3.7
‼️ Error : failed with initial frozen solve. Retrying with flexible solve. ➡️ conda update --all 후 재설치 시도 : conda가 구버전이라서 발생하는 에러라고 함.
4️⃣ 텐서플로우 설치 : conda search tensorflow(2.0.0까지만 나옴) ➡️ conda install tensorflow=2.0.0
‼️ Error : module 'pandas' has no attribute 'core' ➡️ conda install pandas : 단순히 판다스 재설치
5️⃣ 넘파이 다운그레이드 : conda install numpy=1.19.2(텐서플로 2.0과 호환 되는 버전이 넘파이 1.19 이하인 것 같음) - 중간에 pip로 설치되어 있던 numpy, tensorflow가 계속 안 바뀌어서 가상환경을 삭제하고 처음부터 다시 진행했다. 자세한 건 더 찾아봐야겠지만 pip로 다운로드 하면 안되는 거 같다. 전체 conda로 처음부터 쭉 설치하니까 이상 없이 돌아간다.
8) 모델 학습시키기
- 순환 신경망에 데이터 추가해 신경망 학습
model.fit(X_train, y_train, epochs=100, batch_size=1, verbose=1)
9) 데이터 예측하기
- 모델 성능 측정하기 전 예측 데이터 값을 구하여 실제값과 비교할 수 있게(모델 성능 측정) 만들어줘야 함
- 실제 데이터 예측값 - 실제 데이터값 ➡️ 정규화를 거치지 않은 실제 데이터값 필요함
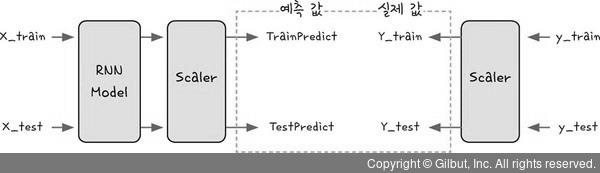
- 입력 데이터 : X_train, X_test
- 출력 데이터 : TrainPredict, TestPredict ➡️ 정규화된 값임
- scaler를 통해 실제값으로 변환
trainPredict = model.predict(X_train)
testPredict = model.predict(X_test)
TrainPredict = scaler.inverse_transform(trainPredict)
Y_train = scaler.inverse_transform([y_train])
TestPredict = scaler.inverse_transform(testPredict)
Y_test = scaler.inverse_transform([y_test])trainPredict = model.predict(X_train): 인공지능 모델에 값을 넣고 얻은 결괏값(0~1 사이), 2차원 배열TrainPredict = scaler.inverse_transform(trainPredict): 정규화 하기 전 값으로 돌려줌(자연수)Y_train = scaler.inverse_transform([y_train]): y_train은 1차원 배열이므로 2차원 배열로 만들어줌
10) 모델의 정확도
- 예측한 값과 실제 값과의 차이 비교
- 평균 제곱근 오차(Root Mean Squared Error) 이용
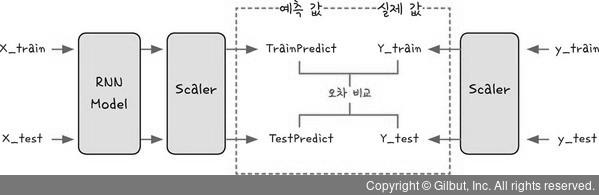
trainScore = math.sqrt(mean_squared_error(Y_train[0], TrainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
testScore = math.sqrt(mean_squared_error(Y_test[0], TestPredict[:,0]))
print('Test Score: %.2f RMSE' % (testScore))trainScore = math.sqrt(mean_squared_error(Y_train[0], TrainPredict[:,0]))- mean_squared_error() : sklearn 라이브러리 함수.
- Y_train[0] : 실제 값 전체
- TestPredict[:, 0] : 예측값 전체(2차원 배열로 이루어져 있음)
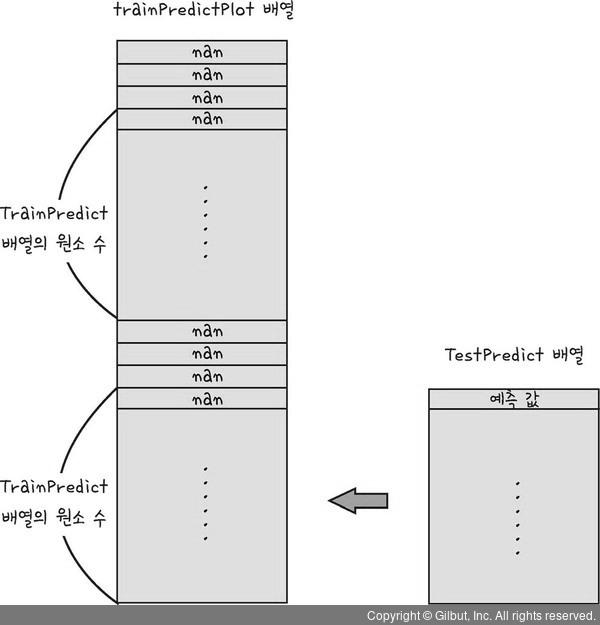
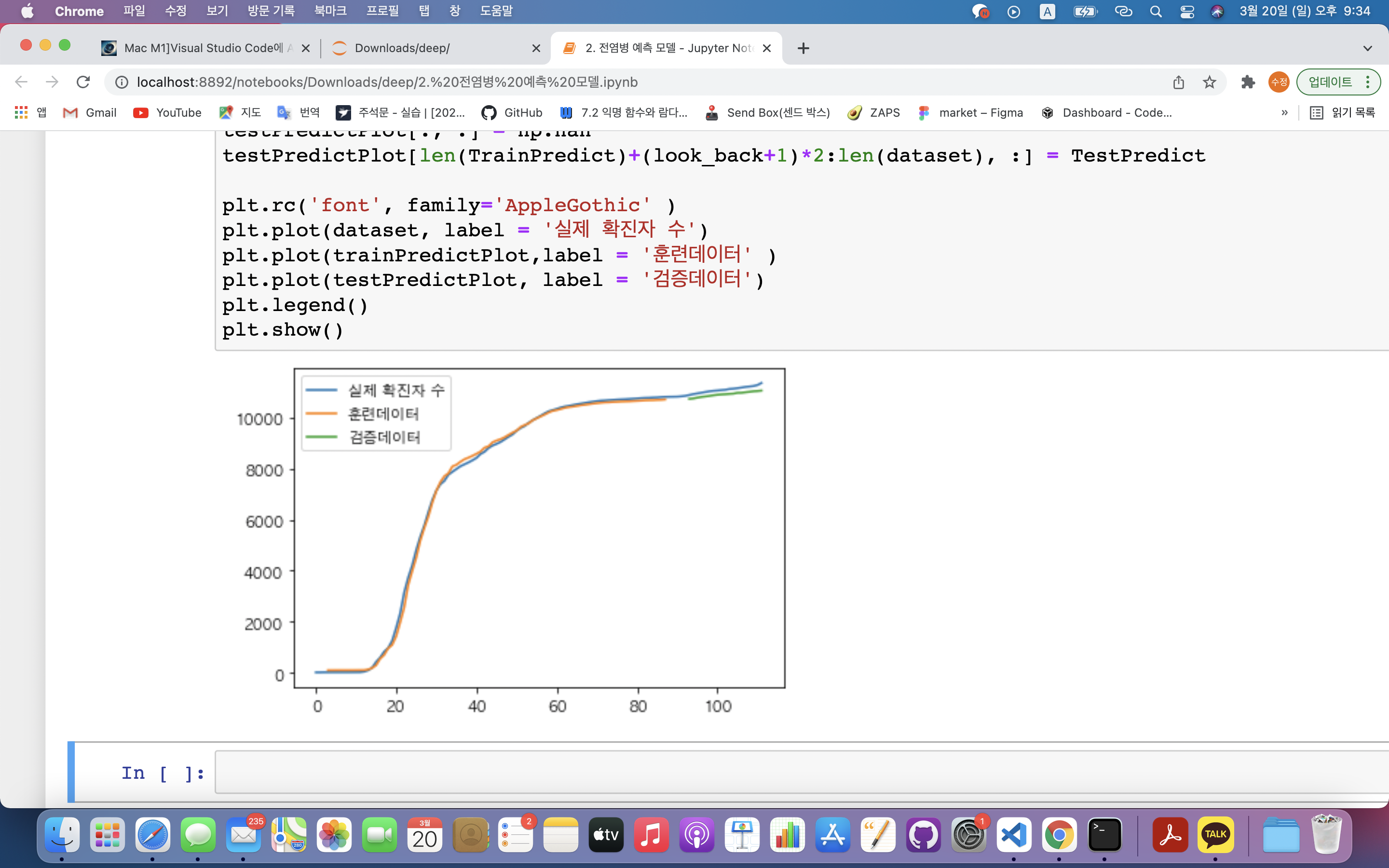
11) 결과 시각화
- 직전 3일을 바탕으로 결과를 예측하므로 첫 3일은 결과가 없음
- 파란색 선 : 인공지능이 예측한 결과
trainPredictPlot = np.empty_like(dataset)
trainPredictPlot[:, :] = np.nan
trainPredictPlot[look_back:len(TrainPredict)+look_back, :] = TrainPredict
testPredictPlot = np.empty_like(dataset)
testPredictPlot[:, :] = np.nan
testPredictPlot[len(TrainPredict)+(look_back+1)*2:len(dataset), :] = TestPredict
plt.plot(dataset)
plt.plot(trainPredictPlot)
plt.plot(testPredictPlot)
plt.show()trainPredictPlot = np.empty_like(dataset): 전체 데이터셋과 동일한 크기의 빈 배열을 만듦trainPredictPlot[:, :] = np.nan: 만들어진 배열의 모든 값을 NaN값으로 설정

trainPredictPlot[look_back:len(TrainPredict)+look_back, :] = TrainPredict: 예측값은 4일차 부터 시작하기 때문에 look_back 구간을 건너뛰고 배열에 값을 넣어야 함. ➡️ look_back ~ TrainPredict 배열의 크기 + look_back = 결국 TrainPredict 길이와 같음testPredictPlot[len(TrainPredict)+(look_back+1)*2:len(dataset), :] = TestPredict:
testPredictPlot은 전체 데이터셋을 받아왔기 때문에 앞의 훈련데이터 이후에 검증데이터 예측값이 들어가야 함 ➡️- len(TrainPredict)길이만큼 더해준 후,
- looK_back이 앞뒤로 두번 들어갔기 때문에 (look_back+1)*2
- len(dataset)까지 testPredict 넣으면 됨
4. 숫자 생성 인공지능 만들기
1) 개발 원리
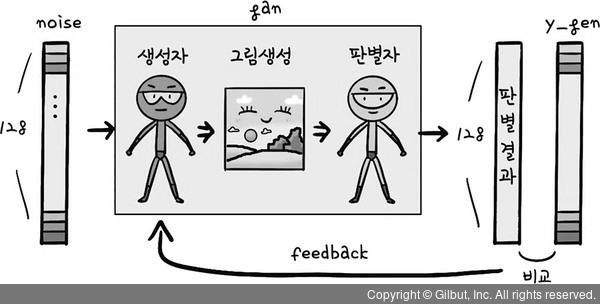
- GAN(Generative adversarial network) : 적대적 생성 신경망 이용
- 1️⃣ 판별자 신경망 : 진짜 그림과 가짜 그림 구별
- ✅목표 : 생성자가 만든 그림을 구별해 내는 것
- 2️⃣ 생성자 신경망 : 가짜그림 생성
- ✅목표 : 판별자가 생성자가 만든 가짜 그림을 구별 못하게 하는 것
➡️ 두 신경망이 목표를 가지고 서로 이기기 위해 학습함
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.layers import LeakyReLU
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.datasets import mnist
from tqdm import tqdm
import numpy as np
import matplotlib.pyplot as pltfrom tensorflow.keras.models import Model, Sequential: 두 개의 신경망을 구성해야 함 ➡️ 두 신경망 모두 시퀀셜 모델로 만듦from tqdm import tqdm: 모델학습을 시각적으로 보여주는 라이브러리
2) 데이터 불러오기
- 기존의 손글씨 데이터를 학습하여 새로운 손글씨 데이터 생성
- mnist 데이터 일부만 사용(다 사용하면 학습이 오래걸림) : mnist 데이터셋은 훈련데이터(6만개)와 검증데이터(1만개)로 구성되어 있음
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_test = (x_test.astype(np.float32) - 127.5)/127.5
mnist_data = x_test.reshape(10000, 784)
print(mnist_data.shape) #(10000, 784)
len(mnist_data) # 10000(x_train, y_train), (x_test, y_test) = mnist.load_data(): mnist 데이터셋은 크게 4부분으로 나눠져 있음.- 훈련데이터 : 픽셀값으로 이루어진 이미지데이터, 이미지데이터가 나타내는 숫자가 무엇인지 알려주는 데이터
- 검증데이터 : 픽셀값으로 이루어진 이미지데이터, 이미지데이터가 나타내는 숫자가 무엇인지 알려주는 데이터
x_test = (x_test.astype(np.float32) - 127.5)/127.5: 데이터 정규화(정규화 함수 미사용) ➡️ -1~1 사이의 값들로 변경- mnist 그림은 0~255 사이의 값들로 이루어져있음(픽셀) ➡️ 중간값인 127.5를 뺀 후 나눠주면 0은 -1, 255는 1로 변경됨
mnist_data = x_test.reshape(10000, 784): 28X28 형태인 데이터를 1개 배열(784X1)로 나타내기 위해 데이터 변형
3) 생성자 신경망
- 아무런 의미없는 숫자(노이즈) 입력하면 숫자이미지 생성해줌

def create_generator():
generator = Sequential()
generator.add(Dense(units=256, input_dim=100))
generator.add(LeakyReLU(0.2))
generator.add(Dense(units=512))
generator.add(LeakyReLU(0.2))
generator.add(Dense(units=784, activation='tanh'))
return generator
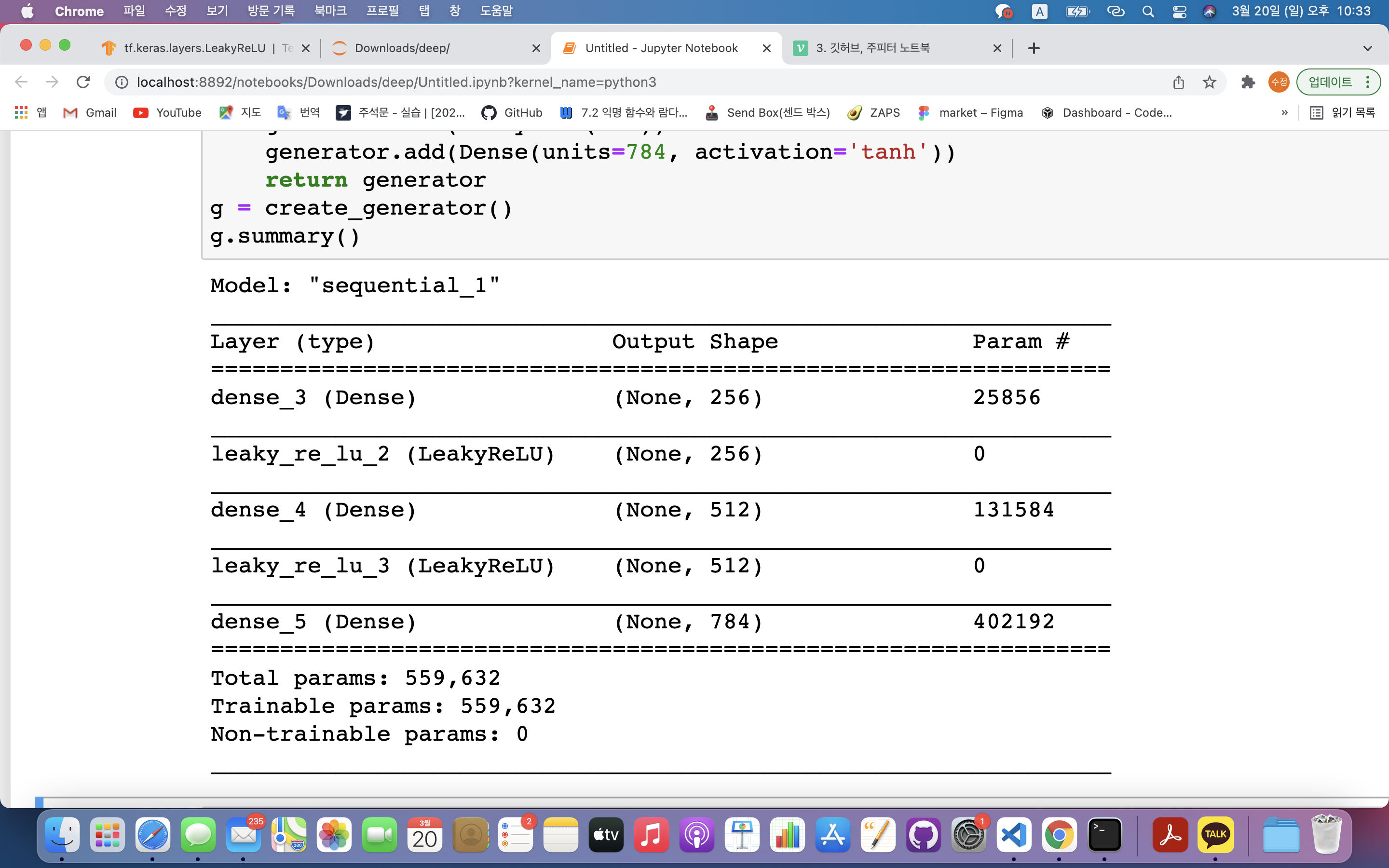
g = create_generator()
g.summary()generator.add(Dense(units=256, input_dim=100))- units : 첫번째층에는 256개의 노드로 구성
- input_dim : 모델에 입력하는 값은 100(100개의 픽셀을 넣을 예정) ➡️ 100개 픽셀은 노이즈 값으로 랜덤한 값임
generator.add(LeakyReLU(0.2)): 활성화 함수 음수값의 기울기 0.2generator.add(Dense(units=784, activation='tanh')): 출력층 노드 개수 784개, 활성화함수는 tanh 사용
4) 판별자 신경망
- 생성자 신경망이 만든 이미지가 가짜인지 정확하게 판별
def create_discriminator():
discriminator = Sequential()
discriminator.add(Dense(units=512, input_dim=784))
discriminator.add(LeakyReLU(0.2))
discriminator.add(Dense(units=256))
discriminator.add(LeakyReLU(0.2))
discriminator.add(Dense(units=1, activation='sigmoid'))
discriminator.compile(loss='binary_crossentropy', optimizer = Adam(lr = 0.0002, beta_1=0.5))
return discriminator
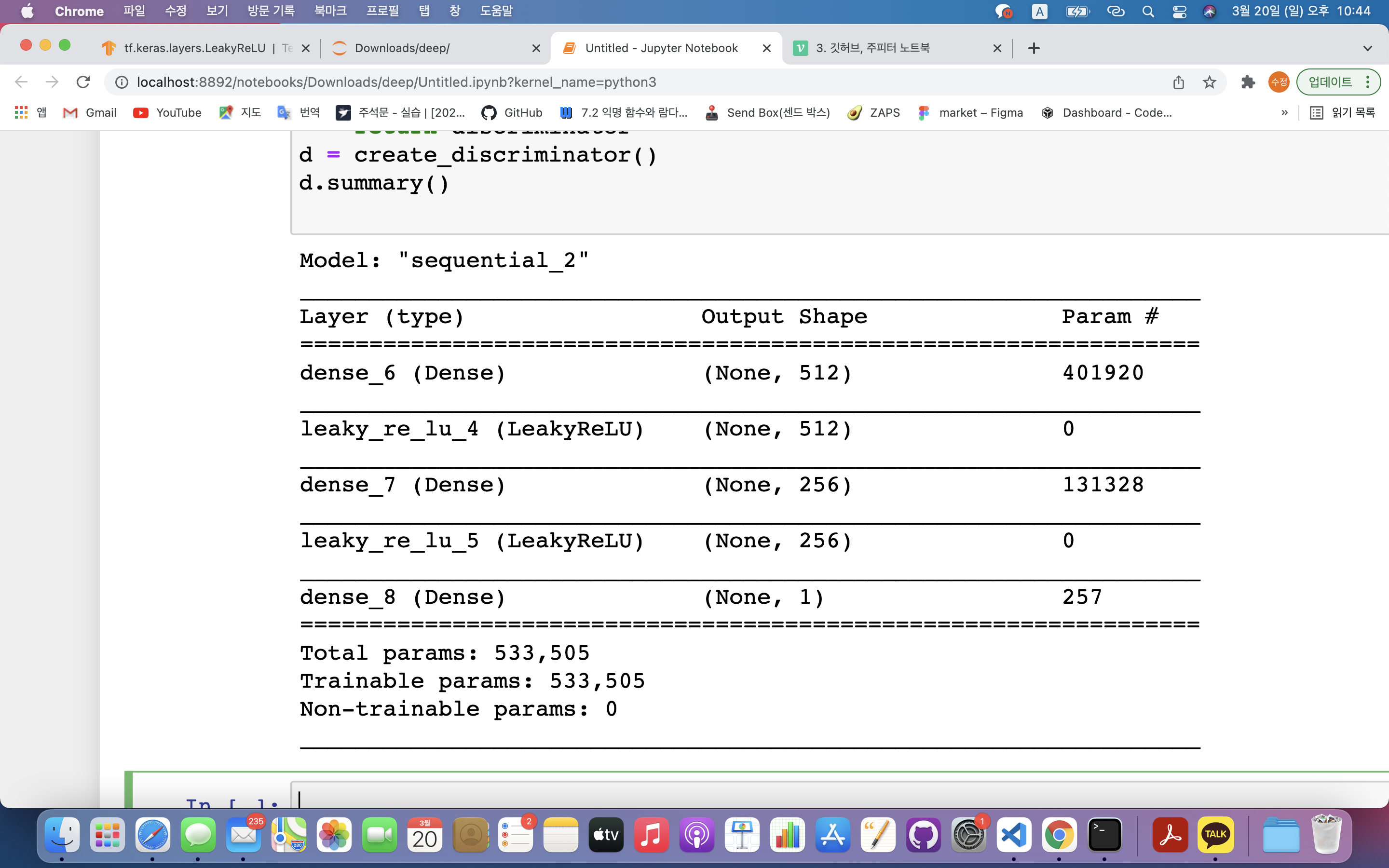
d = create_discriminator()
d.summary()discriminator.add(Dense(units=512, input_dim=784))- input_dim=784 : 생성자가 만드는 그림은 784개의 픽셀로 이루어져 있기 때문
- units=512 : 첫 번째 층 512개의 노드로 구성
discriminator.add(Dense(units=1, activation='sigmoid')): 최종 출력값은 1개.- 데이터의 진위여부 파악 (참이면 1, 아니면 0) ➡️ sigmoid 사용
discriminator.compile(loss='binary_crossentropy', optimizer = Adam(lr = 0.0002, beta_1=0.5))- 오차값 : 이항교차엔트로피 사용 ➡️ 참/거짓 구분만 하면 되기 때문
- 옵티마이저 : 아담 ➡️ GAN은 정교한 옵티마이저 필요함
- lr : 학습속도(학습률)
- 학습률 : 오차가 작아지는 방향으로 가중치 값을 이동할 때, 한 번에 얼마정도 크기로 이동하는지 결정
- beta_1 : 베타 최적화
- 베타 : 아담 옵티마이저 사용할 때 사용자가 옵티마이저의 세부값을 수정 가능함(베타1, 베타2)
- lr : 학습속도(학습률)
5) GAN 생성 함수
- 생성자와 판별자가 서로 이기기 위해 적대하며 학습함
- 생성자는 더 정교하게 손글씨 작성, 판별자는 가짜 판별을 위해 점점 더 성능을 올려감
def create_gan(disriminator, generator):
disriminator.trainable = False
gan_input = Input(shape=(100,))
x = generator(gan_input)
gan_output = disriminator(x)
gan = Model(inputs=gan_input, outputs=gan_output)
gan.compile(loss='binary_crossentropy', optimizer='adam')
return gan
gan = create_gan(d, g)
gan.summary()def create_gan(disriminator, generator):: gan 생성을 위해서는 두 개의 신경망 필요disriminator.trainable = False: 판별자가 학습하지 못하도록 막음gan_input = Input(shape=(100,)): gan에 입력할 데이터의 모습을 정함 ➡️ 입력값은 100개의 값으로 이루어진 데이터- Input() : 모델에 값을 넣을 때 사용하는 명령어
- shape(100,) : 뒤의 값을 비워주면 자동적으로 실제 총 데이터개수로 채워짐
x = generator(gan_input): 픽셀 100개의 값(노이즈)과 데이터 전체 수만큼 데이터 넣음 = Input(shape=(100,)) ➡️ 데이터를 넣으면 생성자가 만든 새로운 그림들이 x 변수에 저장됨gan_output = disriminator(x): gan의 결괏값 데이터 ➡️ 판별자가 생성자가 만든 그림 x를 보고 판단한 결과gan = Model(inputs=gan_input, outputs=gan_output)- 입력값(input) : 생성자 신경망이 만든 그림
- 출력값(output) : 판별자 신경망이 판단한 결과
gan.compile(loss='binary_crossentropy', optimizer='adam'): 신경망의 오차값을 줄이기 위함
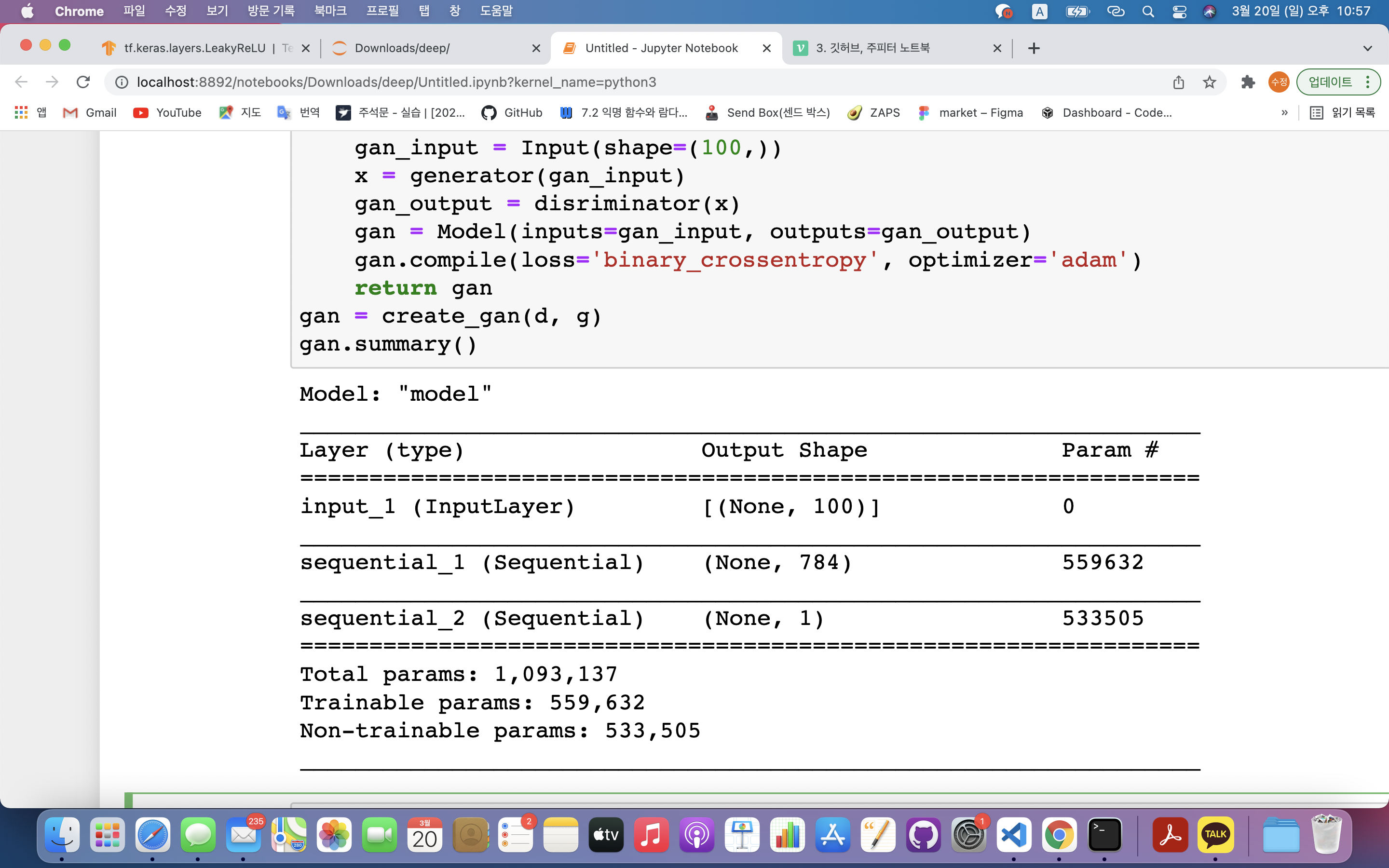
- 입력층 : 노이즈값이 100개의 픽셀값으로 들어감
- 두 번째 레이어 : 생성자 신경망에서 출력된 값
- 출력층 : 판별잘 신경망에서 판단한 결과값
6) 결과 출력 함수
- 신경망의 정확도 확인
def plot_generated_image(generator):
noise = np.random.normal(loc=0, scale=1, size=[100,100])
generated_img = generator.predict(noise)
generated_img = generated_img.reshape(100,28,28)
plt.figure(figsize=(10,10))
for i in range(generated_img.shape[0]):
plt.subplot(10,10,i+1)
plt.imshow(generated_img[i], interpolation='nearest')
plt.axis('off')
plt.tight_layout()def plot_generated_image(generator):: 그림을 그릴 때 어떤 생성자로 그릴지 결정noise = np.random.normal(loc=0, scale=1, size=[100,100]): 생성자에 넣어줄 노이즈값 생성np.random.normal(0,1, [batch_size, 100])- 첫 번째 파라미터 : 평균 0
- 두번째 파라미터 : 평균에서 1만큼 떨어져있음(즉, -1~1)
- 세번째 파라미터 : 노이즈를 100개 생성, 각각의 노이즈는 숫자 100개씩 구성되어 있다 ➡️ 함수를 호출할 때마다 100개의 그림을 그려달라!
generated_img = generator.predict(noise): generator도 신경망이므로 노이즈를 넣어서 값을 예측하게 함generated_img = generated_img.reshape(100,28,28): 노이즈 값 100개를 28X28 배열의 모습으로 변형for i in range(generated_img.shape[0]):: 100개의 그림을 그려주는 반복문; 위치 설정해줌plt.imshow(generated_img[i], interpolation='nearest'): 이미지 출력 함수- interpolation='nearest' : 이미지를 출력할 때 각 픽셀을 어떻게 나타낼지 결정 ➡️ i 위치에 i번째 그림을 넣겠다
plt.axis('off'): 그림 이름 생략
7) 적대적 신경망 훈련
batch_size = 128
epochs = 5000
for e in tqdm(range(epochs)):
noise = np.random.normal(0, 1, [batch_size, 100])
generated_img = g.predict(noise)
image_batch = mnist_data[np.random.randint(low=0, high=mnist_data.shape[0], size=batch_size)]
X = np.concatenate([image_batch, generated_img])
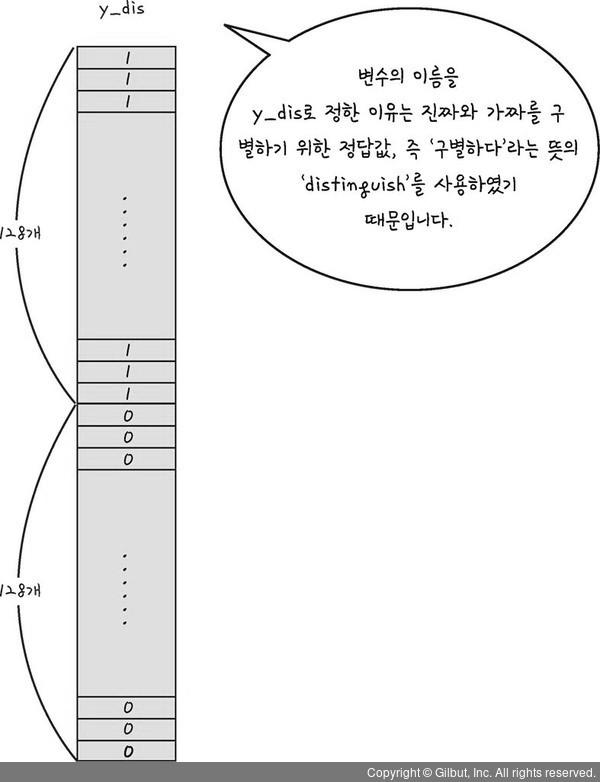
y_dis = np.zeros(2 * batch_size)
y_dis[:batch_size] = 1
d.trainable = True
d.train_on_batch(X, y_dis)
noise = np.random.normal(0, 1, [batch_size, 100])
y_gen = np.ones(batch_size)
d.trainable = False
gan.train_on_batch(noise, y_gen)
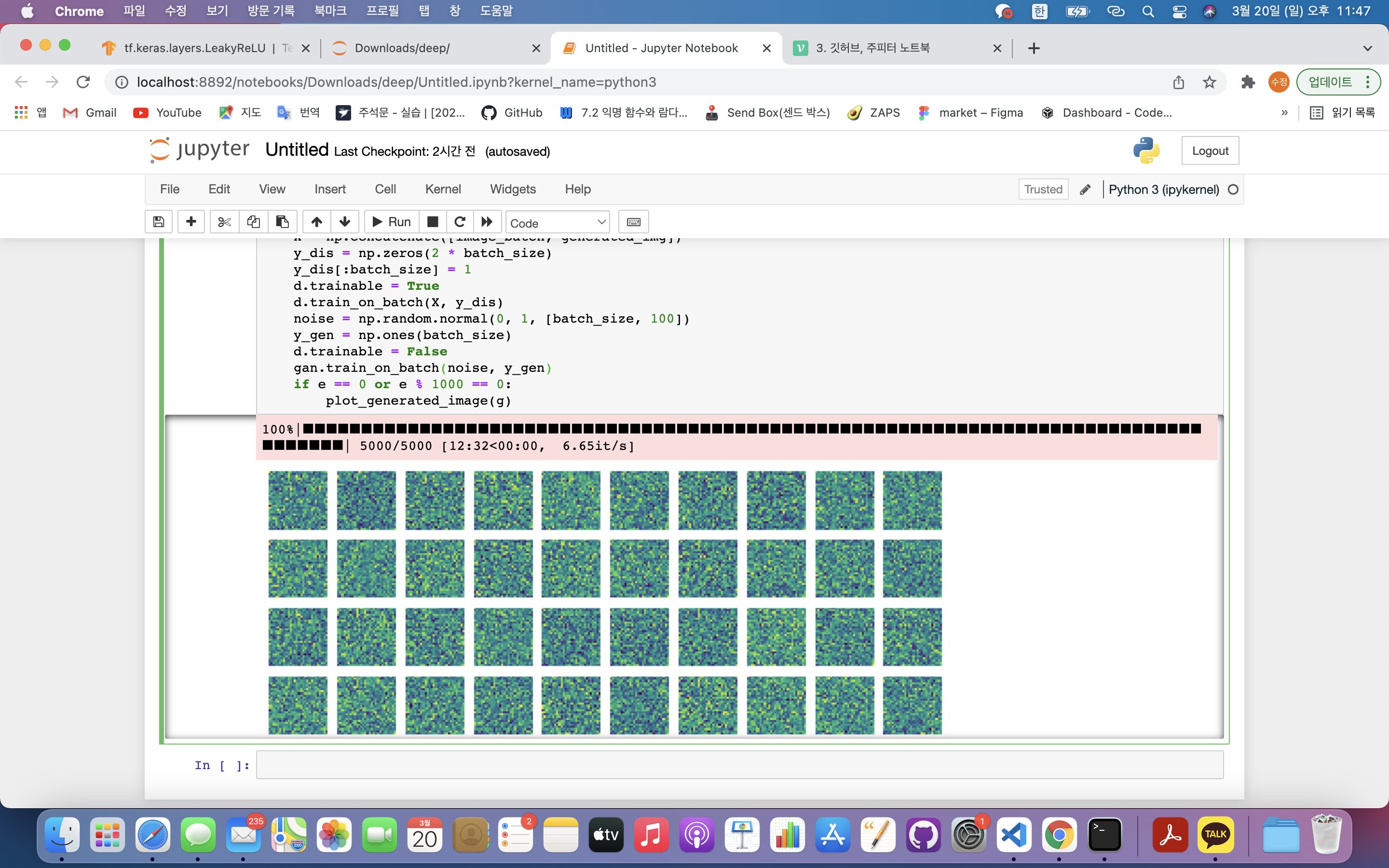
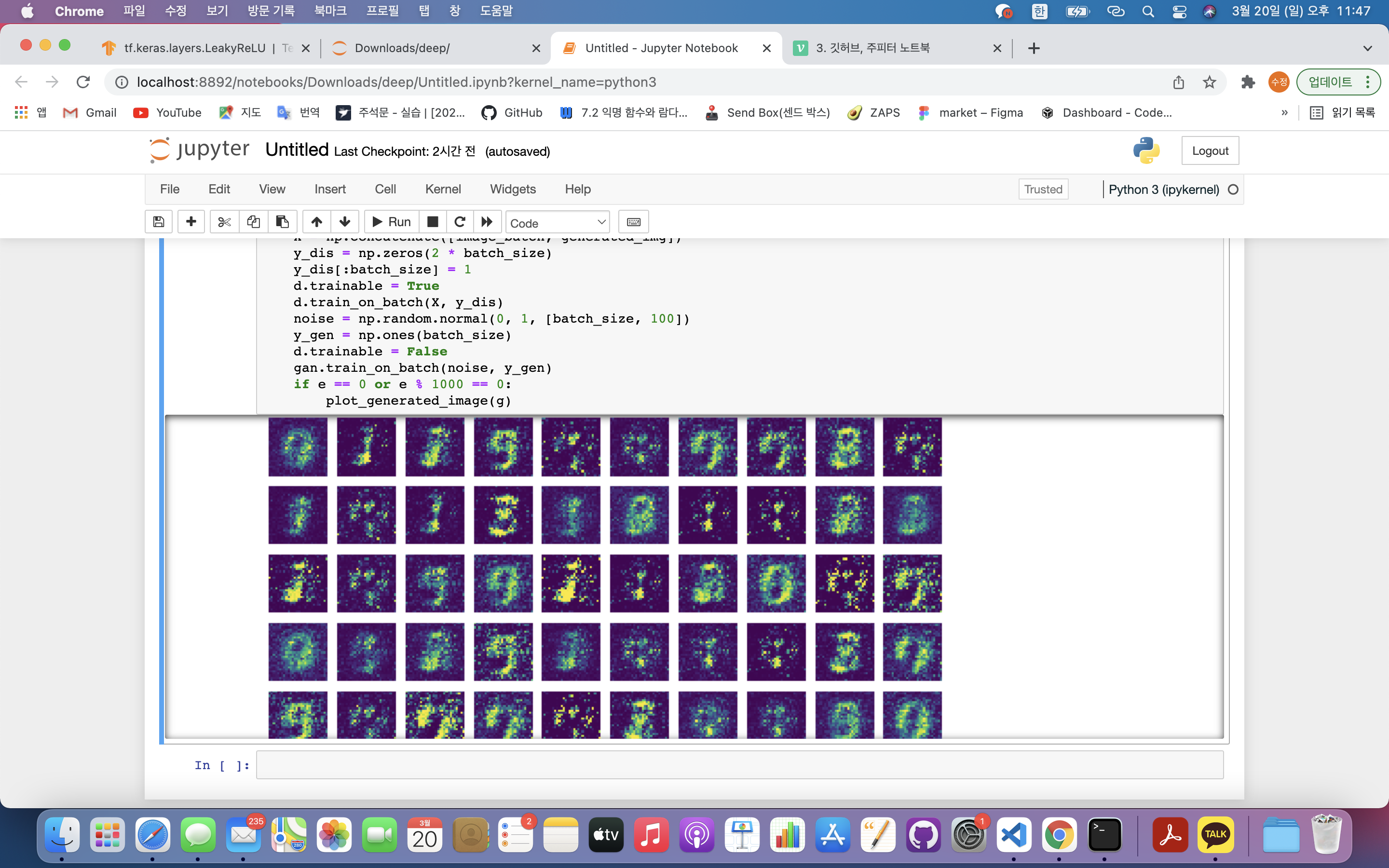
if e == 0 or e % 1000 == 0:
plot_generated_image(g)batch_size = 128: GAN에 한 번에 학습시킬 데이터(그림)의 양 ➡️ 한 번에 128개 학습epochs = 5000: GAN을 몇 번 반복해서 학습시킬지 결정 ➡️ 5000번 반복 학습for e in tqdm(range(epochs)):: 반복문과 tqdm 라이브러리를 사용하여 신경망에 반복학습 ➡️ tqdm 라이브러리를 사용하여 몇번째 반복학습 중인지 시각화하며 epochs(5000)만큼 반복하겠다는 의미.noise = np.random.normal(0, 1, [batch_size, 100]): 생성자에게 줄 노이즈 값 생성 ➡️ 균일한 값 생성을 위해 넘파이의 normal 이용.
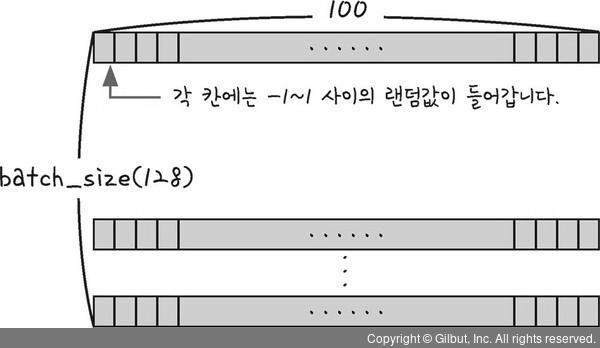
- 각 100개씩 구성된 데이터를 배치 사이즈 만큼 생성한다는 의미
generated_img = g.predict(noise): 노이즈를 입력하여 생성자 신경망이 그림을 그린 뒤 그림의 결과를 해당 변수에 저장image_batch = mnist_data[np.random.randint(low=0, high=mnist_data.shape[0], size=batch_size)]: 실제 mnist 데이터셋(10000개) 중 배치 사이즈(128개)만큼 랜덤하게 뽑음. ➡️ 학습할 때마다 다양한 손글씨를 접할 수 있게 함- np.random.randint : 넘파이의 random 함수를 사용하며 범위와 개수를 지정하기 위해 randint 사용
- (low=0, high=mnist_data.shape[0], size=batch_size) : 첫 번째(0)부터 전체 데이터값(mnist_data)까지 중 128개의 데이터 랜덤 추출
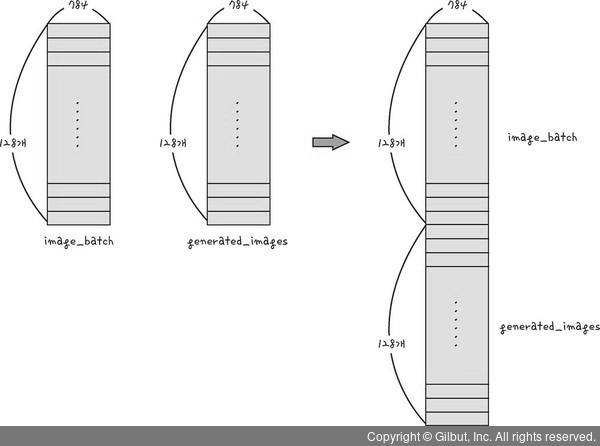
X = np.concatenate([image_batch, generated_img]): 진짜 그림과 생성한 그림을 합침(한 줄로 세움) ➡️ 총 256개의 데이터로 구성되어 있고, 각 데이터에는 -1~1사이의 값들이 784개 있음.
y_dis = np.zeros(2 * batch_size): 판별자에게 전달할 결괏값 ➡️ 위에서 만든 데이터를 판별하기 위해 해당 데이터수만큼(256개) 결과값도 256개 만들어줌
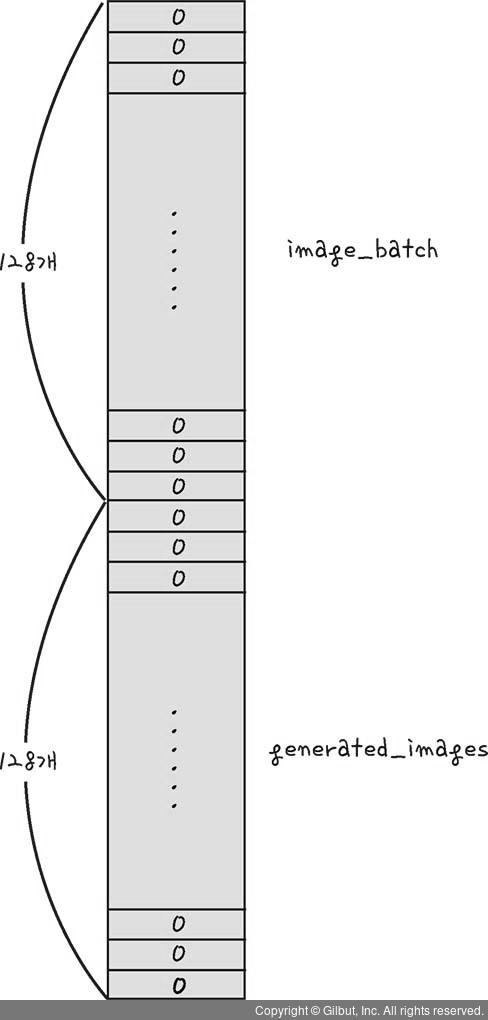
y_dis[:batch_size] = 1: 앞 128개는 실제 그림이 맞기 때문에 1을 넣어줌으로써 이후 가짜그림과 구분할 수 있게 함
d.trainable = True: 처음에는 판별자가 먼저 학습을 할 수 있게 해야 함.- trainable 함수 : 신경망이 훈련 가능하도록 할지 말지 결정
d.train_on_batch(X, y_dis): 판별자 학습- X : 입력 데이터
- y_dis : 출력 데이터
- 판별자에게 입력데이터 X를 주고 나온 출력값과 정답데이터 y_dis를 비교하여 오차를 줄여가는 방식으로 학습시킴
생성자 학습
noise = np.random.normal(0, 1, [batch_size, 100]): 새롭게 노이즈값 생성y_gen = np.ones(batch_size): gan에 넣어줄 값을 모두 1로 설정해서 만들어줌 ➡️ 판별자가 그림을 모두 진짜라고 판단하도록 하기 위함
d.trainable = False: 판별자의 학습이 불필요해짐 ➡️ 단순히 생성자의 그림을 판별만 하면 되기 때문gan.train_on_batch(noise, y_gen)
- 입력 : 노이즈값
- 출력 : 모두 진짜(y_gen이 모두 1이기 때문)
❗️GAN 학습 과정 : 생성자가 판별자를 속일 수 있도록 진짜 같은 가짜 그림을 생성하게 생성자를 학습시킴
- train_on_batch 함수 사용 시 입력값과 정답값을 미리 알려줘야함
- 출력값 : 판별자 신경망을 거쳐서 나오는 판별 결과값
- 판별 결과값을 y_gen과 비교하여 판별결과가 1이 나올때까지 학습시킴
if e == 0 or e % 1000 == 0 : plot_generated_image(g): 에포크별 훈련을 잘 하는지 확인 ➡️ 첫번째 에포크, 1000, 2000, 3000, 4000, 5000번째 에포크일 때만 생성자가 만든 그림 출력


hello world!