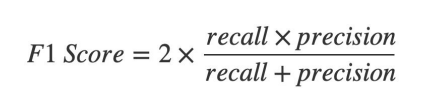EDA에 관련된 간단한 프로젝트 진행 후 머신러닝에 대해 배우는 시간을 가지게 되었습니다.
5/21~5/31 인강 + 실강 형식으로 진행되었습니다.
머신러닝?
지도학습
머신 러닝은 말 그대로 기계가 배워서 그와 관련된 문제를 주면 해결하게 하는 방식입니다.
그 중 지도학습은 문제에 관련된 정보를 주고 그에 맞는 답안지를 같이 제공해서 정보를 토대로 답을 알아내는 과정을 유추해 모델을 만들어서 나중에는 정보만 줘도 답을 맞추는 것이 목표가 되는 방식입니다.
이 이야기를 들으니 고등학교 때 수학의 정석을 풀면서 답안지의 풀이와 제 풀이를 맞춰보는 것이 생각났습니다. 기계도 별수 없구만
그래도 기계는 0과 1만 구분하는 거로 아는데 이걸 어떻게 배우는 걸까라는 의문을 가진 채 수업을 듣기 시작했습니다.
비지도학습
비지도학습은 정답지는 주지 않고 정보만 제공하는 방식입니다. 그렇게 되면 뭘 알아낼수 있겠냐를 생각할 수 있지만 그 정보들을 분류해서 일종의 패턴을 알아내 분류하는 것이죠.
나중엔 정보가 들어오더라도 자동으로 분류가 되어 관리하기 편해지기 위해 나눈다고 생각하니 편했습니다.
데이터의 분류
정형 데이터
정형 데이터는 테이블의 형태로 정리할 수 있는 데이터입니다.
예시로 우리가 회원가입을 할 때 입력하는 정보들이 됩니다.(이름, 나이, 아이디, 주소 ...)
비정형 데이터
비정형 데이터는 테이블로 만들기는 힘든 데이터 형식입니다.
예시로 이미지, 동영상, 음성, 뉴스나 소설처럼 긴 글 형식의 텍스트 ... 등이 있습니다.
머신러닝의 사용처
어뮤징 감시
사람이 24시간 감시하기 힘들고 양이 많아서 인력으로 처리하기 힘든 작업입니다.
스팸메일을 분류하거나 로그인 보안등을 이를 통해 해결하고 있습니다.
추천 시스템
이 역시 모든 고객을 대상으로 추천 시스템을 짜주는 직원을 배치하기는 쉽지 않습니다.
하지만 OTT에 들어가면 해당 고객의 취향에 맞는 작품을 추천해주는데 이는 비지도학습으로 본인과 비슷한 취향을 가진 사람들의 그룹에서 높은 평가를 받은 작품을 추천해주는 것 입니다.
머신러닝 평가 방식
Confusion Matrix
머신러닝을 통해 만들어진 모델을 평가하기 위해서 일정한 공식이 사용됩니다.
● TP : (모델이) 맞았다고 했는데(실제로) 맞은 것
● FN : (모델이) 틀렸다고 했는데 (실제로) 맞은 것
● FP : (모델이) 맞았다고 했는데 (실제로) 틀린 것
● TN : (모델이) 틀렸다고 했는데 (실제로) 틀린 것
● Precision = TP / (TP+FP)
- (모델이) 맞았다고 예측한 것 중 (실제로) 맞는 것 비율
● Recall = TP / (TP + FN)
- (실제) 맞는 것들 중에 (모델이) 맞았다고 예측한 비율
F1 Score
위에서 사용한 Precision과 Recall만으로는 부족한 면이 있어 이를 보안하기 위해 만들어진 공식입니다.
● Precision과 Recall 의 조화평균으로, 두가지 지표를 모두 고려하는 평가지표
● 불균형한 데이터에서 Accuracy 보다 효과적인 평가지표