1. malloc 과 포인터 복습
- 학습목표: 포인터의 개념과 malloc 함수의 용법을 잘 이해할 수 있다.
- 핵심단어: 포인터, malloc
- 포인터를 선언한 후 malloc 사용하여 메모리를 할당한 후 값을 넣을 수 있다.
- 메모리를 할당하지 않고 값을 넣으려고 한다면 error 발생
2. 배열의 크기 조정하기
- 학습목표: 배열의 크기는 조정하는 코드를 작성할 수 있다.
- 핵심단어: malloc, realloc
- 메모리 주변에 다른 것들이 있을 경우 배열에 새 값을 추가할 수 없다.
- 메모리를 할당할 때마다 NULL이 반환되는지 확인하는 것이 좋은 방법이다.
- realloc(재할당할 것, 배열크기, sizeof(자료형))
-- ex) realloc(list, 4, sizeof(int));
-------------- ↪ int *list = malloc(3 * sizeof(int));
3. 연결리스트 도입
- 학습목표: 연결리스트의 정의를 설명할 수 있다.
- 핵심단어: 연결리스트
- . (dot) : 구조체의 속성 값을 가져올 때 -- ex) 이름.~~~
- * : 역참조 연산자 (using pointer)
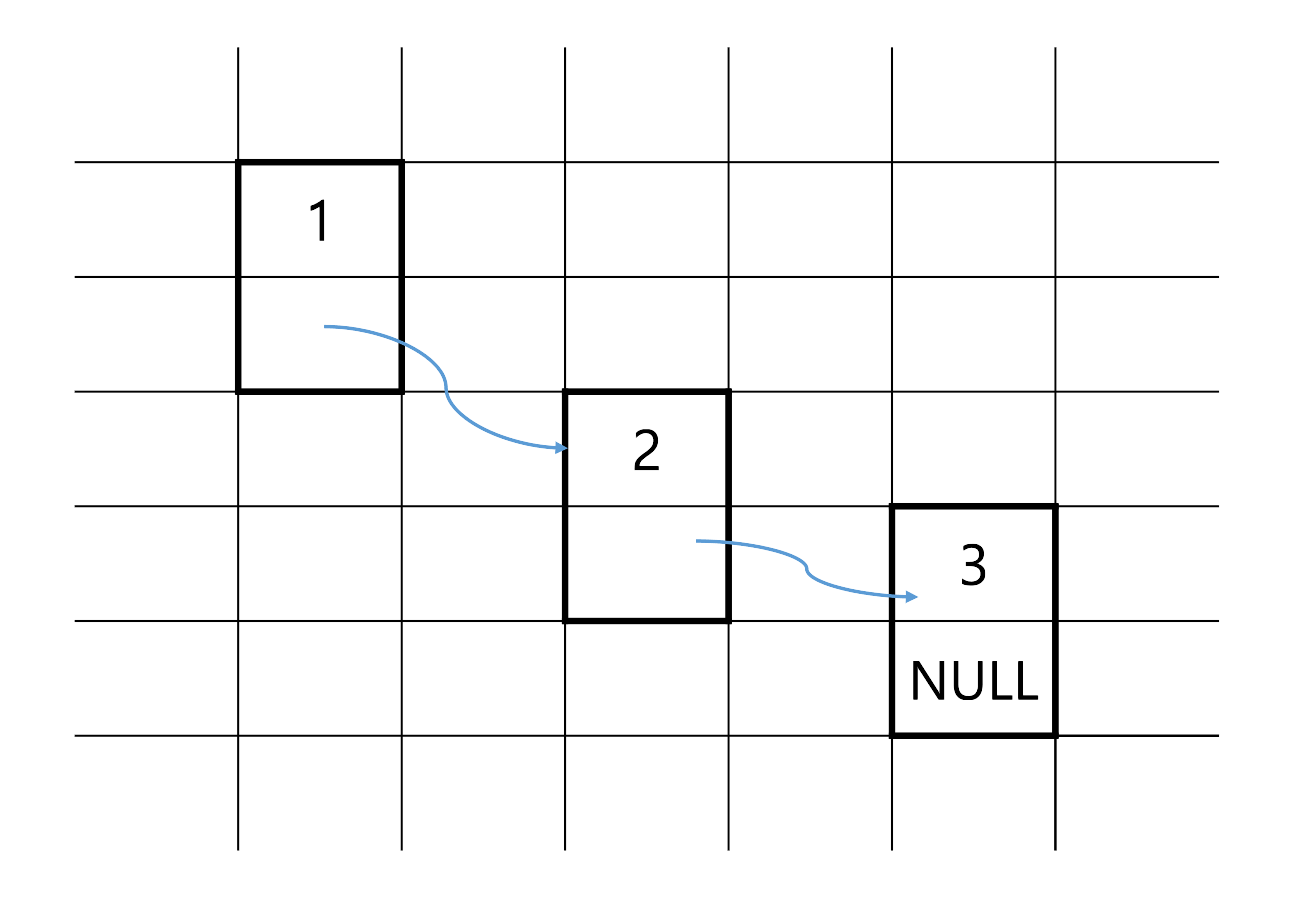
- 메모리 덩어리 여러개를 포함한 데이터 구조를 연결리스트라고 한다.
ex) 하나의 메모리 덩어리만 사용하지 않고 두 배의 메모리를 주어 더 유연하게 만들 수 있다.
※ 컴퓨터 공학에서 node 는 직사각형으로 나타낼 수 있는 메모리 덩어리를 의미함
- ex_wrong
: node 정의되기 전이므로 사용 Xtypedef struct{ int number; node *next; }node; // node가 정의 되는 때
- ex_right
: struct node : 구조체의 정식 명칭typedef struct node{ int number; struct node *next; }node; // node가 정의 되는 때, 구조체의 별칭
4. 연결리스트 : 코딩
- 학습목표: 연결리스트를 구현하고 사용할 수 있다.
- 핵심단어: 연결리스트
node *n = malloc(sizeof(node));- ↪ 3번에서 정의한 node 크기만큼 메모리를 할당 받는다.
- ↪ pointer n 은 node를 가르키는 주소를 담고 있다.
-----------------------------------———————————————
(*n).number = 2;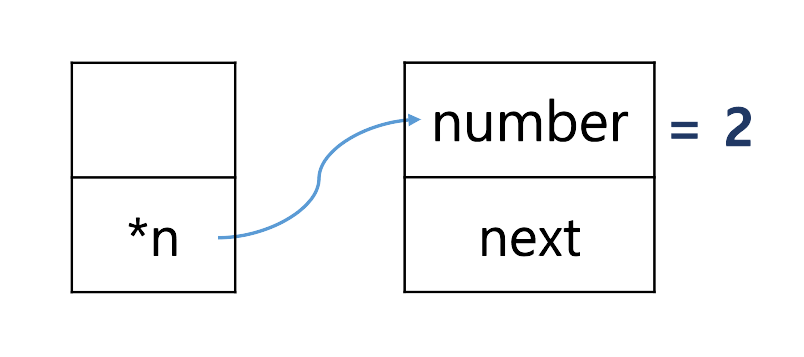
- ↪ n 은 pointer 이므로 n.number 는 잘못된 방법
- ↪ 화살표를 사용한 다른 방법 O
----- ex) n → number = 2;
----- ex) n → next = NULL;
-----------------------------------———————————————
if(n != NULL)- ↪ n 이 NULL 인지 확인 (= 끝인지 확인)
-----------------------------------———————————————
node *tmp = list;
while (tmp -> next != NULL){
tmp = tmp -> next
}
tmp -> next = n;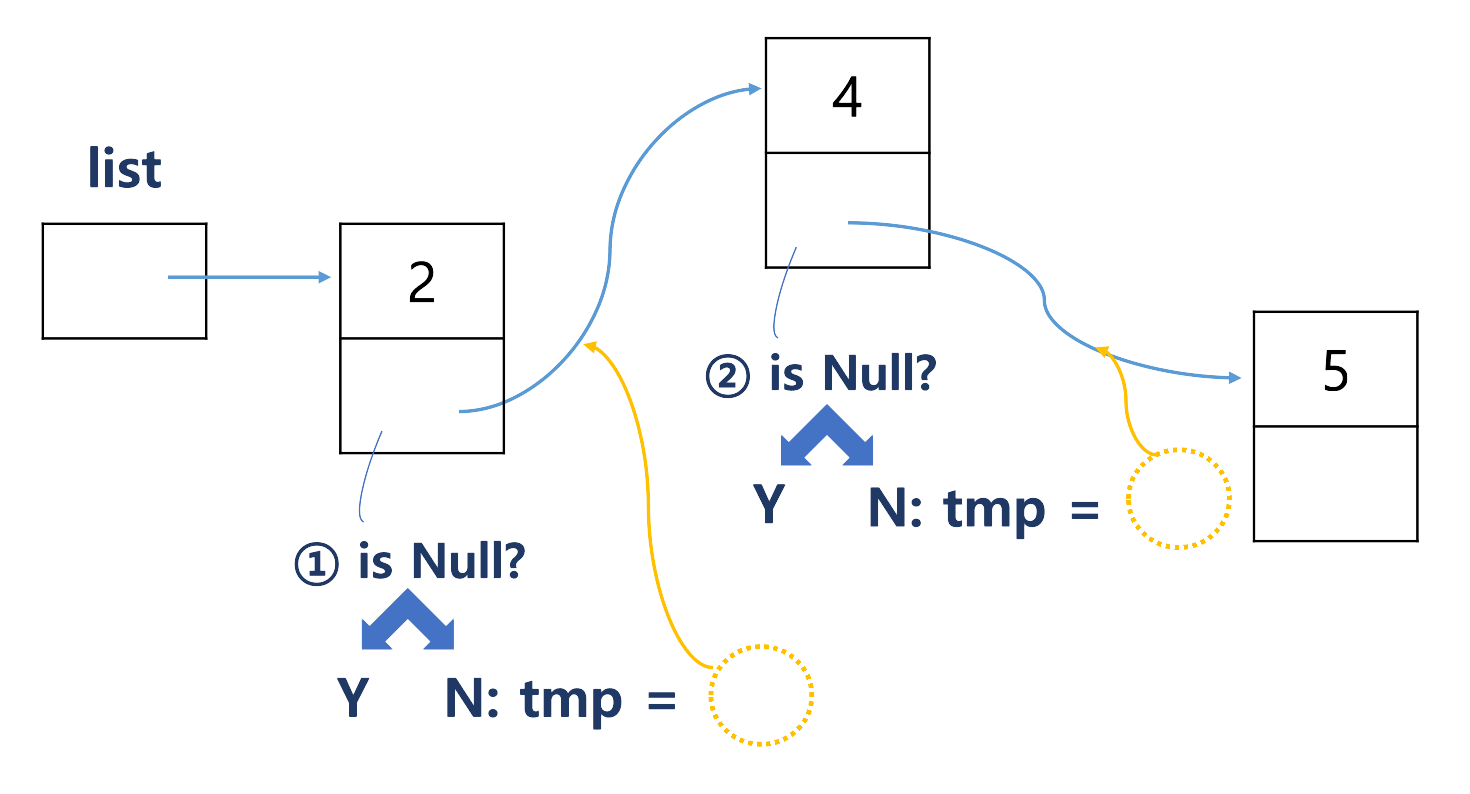
-----------------------------------———————————————
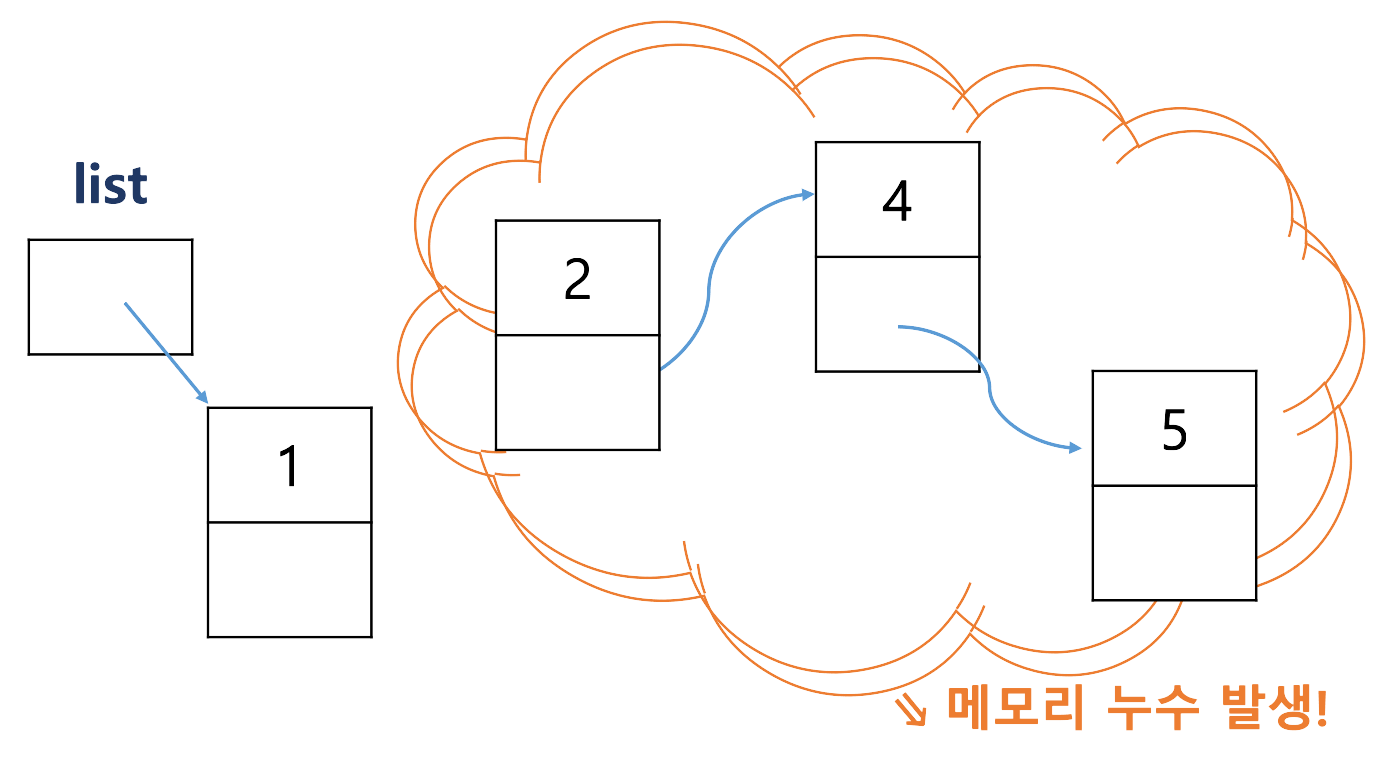
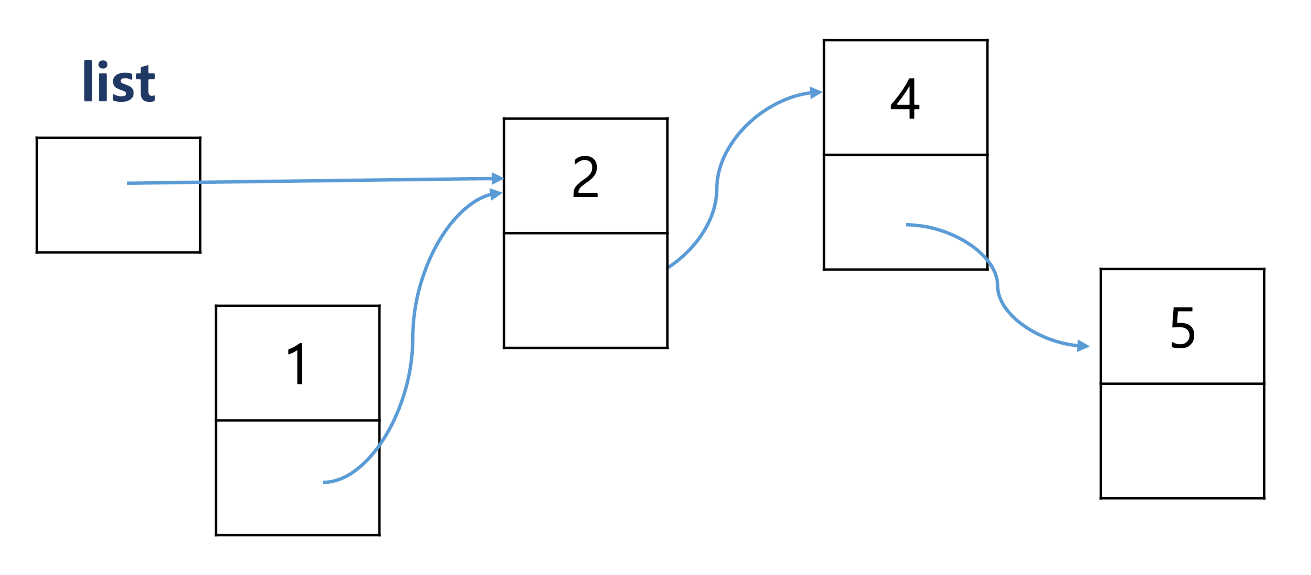
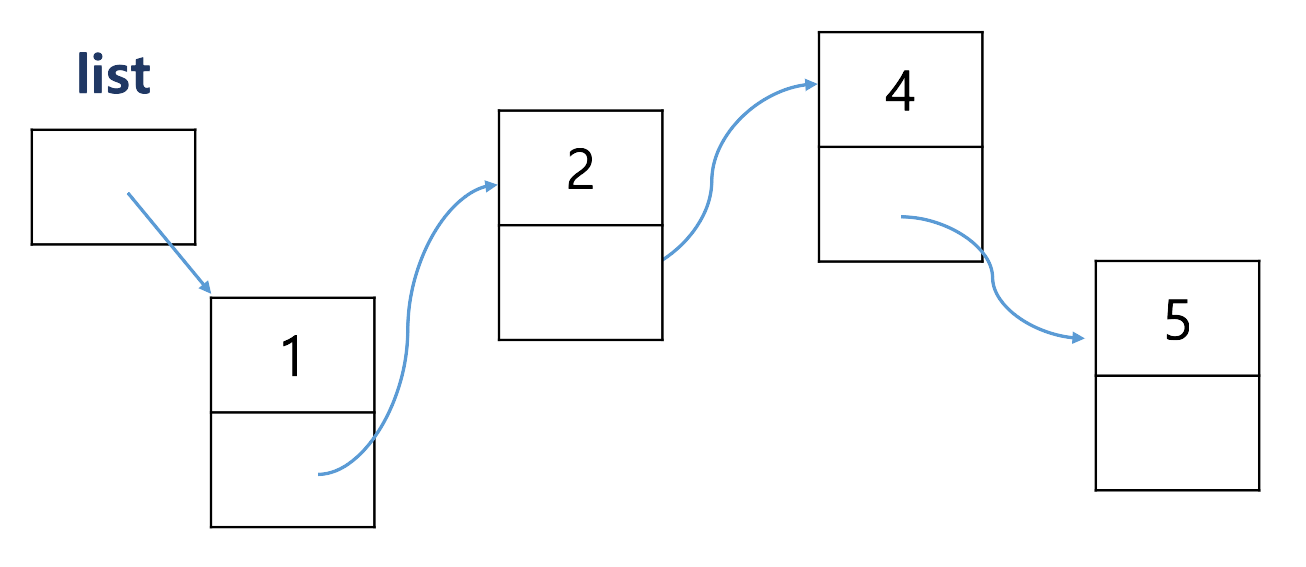
1을 앞에 끼우고 싶을 때
- wrong
새로운 node를 할당하는 코드를 사용한다.
- ↪ ❗ 메모리 누수 발생
- right
1이 2를 가르키게 한 후 list가 1을 가르키게 한다.n -> next = list; list = n;
-----------------------------------———————————————
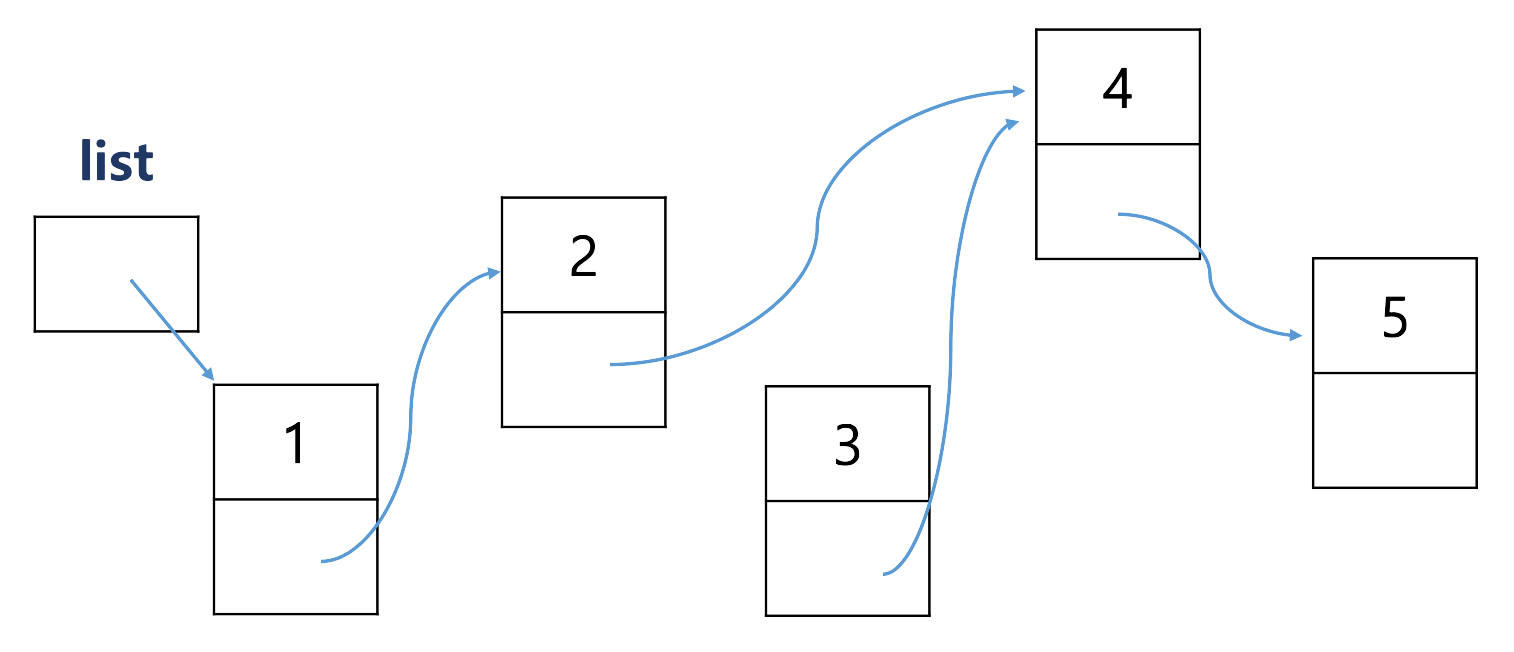
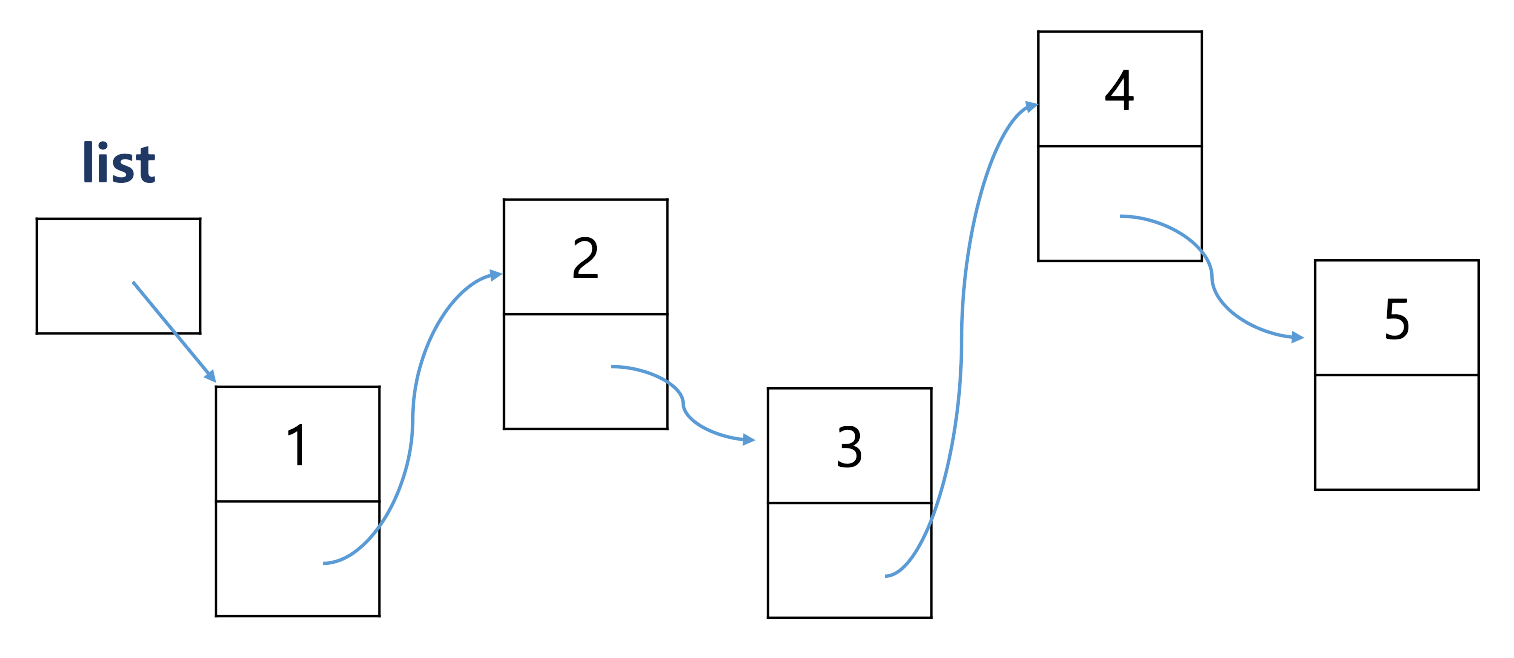
순서에 맞춰 중간에 값을 넣고 싶을 때
--반복문 등으로 대소 비교하고 포인터를 업데이트 하는 과정이 필요하다.
↪ 2의 next 가 3으로 가르키는 것으로 바꾸기 전에 3의 next 가 2의 next 와 같도록 한 후 2가 3을 가르키도록 해야 한다.
5. 연결리스트 : 시연
- 학습목표: 연결리스트와 배열의 장점을 설명할 수 있다.
- 핵심단어: 연결리스트, 배열
- 장점: 배열처럼 숫자를 추가하기 위해 크기를 조절하고 기존의 값을 모두 옮기지 않아도 된다는 것
- 단점: 임의 접근법 X -- ex) 이진탐색
- Big O : O(n) -insert
// Represents a node
typedef struct node{
int number;
struct node *next;
}
node;
int main(void){
// List of size 0
node *list = NULL;
// Add number to List
node *n = malloc(sizeof(node));
if(n == NULL){
return 1;
}
n -> number = 1;
n -> next = NULL;
list = n;
// Add number to List
n = malloc(sizeof(node));
if(n == NULL){
return 1;
}
n -> number = 2;
n -> next = NULL;
list -> next = n;
// …
// …(생략 및 반복)…
// …
// Print list
for (node *tmp = list; tmp != NULL; tmp = tmp ->next){
printf("%i\n", tmp -> number);
}
// Free list
while (list != NULL) {
node *tmp = list -> next;
free(list)
list = tmp;
}
}6. 연결리스트 : 트리
- 학습목표: 트리의 구조를 설명하고 활용하는 코드를 작성할 수 있다.
- 핵심단어: 트리, 루트
--연결리스트는 역동성을 주기 때문에 값들을 옮기느라 시간을 낭비하지 않을 수 있다. 하지만 그렇기 때문에 임의 접근을 할 수 없다.
--그렇지만 1차원적인 자료구조만 만드는 것이 아닌 수직적인 개념을 사용해서 더 흥미로운 방식으로 요소들을 배열할 수 있다.
binary search tress
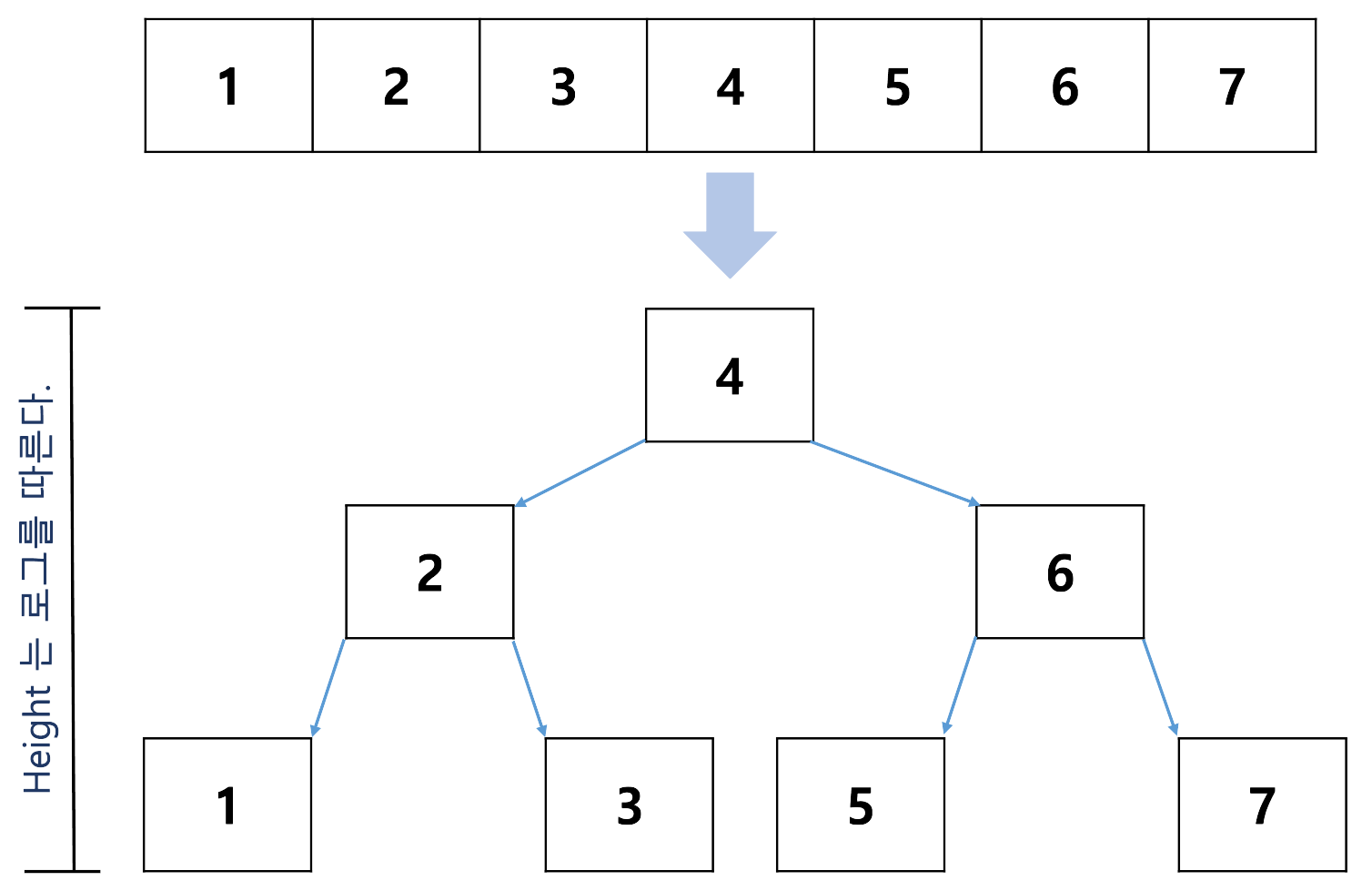
typedef struct node{
int number;
struct node *left;
struct node *right;
}
node;-- ↪ ▼ 재귀 알고리즘으로 생각해 보면 ▼
bool search(node *tree){
if(tree == NULL){
return false;
}
else if (50 < tree -> number){
return search(tree -> right);
}
else if (50 > tree -> number){
return search(tree ->left);
}
else {
return true;
}
}- Big O : O (log n)
7. 해시 테이블
- 학습목표: 해시 테이블의 원리와 구조를 설명할 수 있다.
- 핵심단어: 해시 테이블, 해시 함수
- 배열과 연결리스트를 조합한 것이다.
- 데이터 검색에 대한 연산과정을 줄일 수 있는 자료구조이다.
- key-value 형태
8. 트라이
- 학습목표: 트라이의 원리와 구조를 설명할 수 있다.
- 핵심단어: 트라이
- 어떤 자원을 절약하기 위해 다른 자원을 소비하는 패턴을 가진다.
- 많은 메모리가 들지만, 자료 구조 안에 있는 이름이나 단어를 찾는데 일정한 실행시간을 가진다.
- 트라이는 각 노드가 배열로 구성되어 있는 트리이다.
- 자식 노드 등 인덱스로 이동
- Big O : O(k) 즉 O(1)-- * k 는 상수
- 속도는 빠르지만 메모리가 많이 필요하다.
9. 스택, 큐, 딕셔너리
- 학습목표: 스택, 큐, 딕셔너리의 원리와 구조를 설명할 수 있다.
- 핵심단어: 스택, 큐, 딕셔너리
1) queus
-- FIFO (선입선출) 의 특징을 가진 자료구조--cf) LIFO (Last In First Out)
| in | out |
|---|---|
| enqueue | dequeue |
2) stacks
-- LIFO (후입선출) 의 특징을 가진 자료구조--ex) 받은 메일함
| in | out |
|---|---|
| push | pop |
3) dictionaries
- hash table 과 비슷하다 (key-value)
- 대표적인 차이점으로 hash table은 한 객체 안에 다양한 데이터 타입을 넣을 수 있지만 dictionary 는 객체 생성 시 타입이 정해진다.
