해당 링크의 설명을 참고하며 custom 학습을 진행하였다.
우선 custom dataset이 필요하다.
공개되어 있는 데이터셋을 이용하거나, 데이터셋을 직접 취득하고 라벨링해줘도 된다.
Label format을 대신 맞춰주어야 한다.

만약 label format이 다른 형태라면 gpt한테 도움을 받고 위 라벨링 format에 맞게 새롭게 .txt파일을 만들어주는 python 코드를 짜달라고 해보자.. ㅋㅋ
예를 들어, 폴더 A에 있는 .txt폴더들은 어떻게 라벨링 되어있는데 이를 어떻게 변경시켜서 폴더 B에 새로 저장해줘~~~
데이터셋은 아래 폴더처럼 정리해둬야 한다.
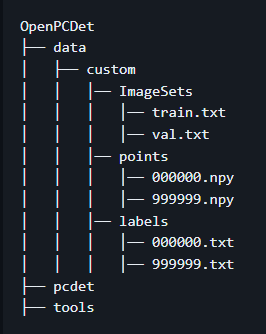
동일하게 파일들을 배치해준 뒤, 아래 명령어를 실행하면 data info들을 생성해준다.
python -m pcdet.datasets.custom.custom_dataset create_custom_infos tools/cfgs/dataset_configs/custom_dataset.yaml최종적인 custom dataset 준비 구성은 아래와 같이 될 것이다.
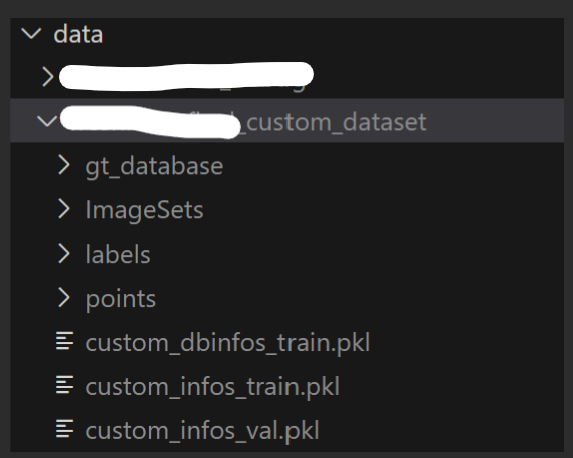
수정한 custom_dataset.py 는 다음과 같다.
import copy
import pickle
import os
import numpy as np
from ...ops.roiaware_pool3d import roiaware_pool3d_utils
from ...utils import box_utils, common_utils
from ..dataset import DatasetTemplate
class CustomDataset(DatasetTemplate):
def __init__(self, dataset_cfg, class_names, training=True, root_path=None, logger=None):
"""
Args:
root_path:
dataset_cfg:
class_names:
training:
logger:
"""
super().__init__(
dataset_cfg=dataset_cfg, class_names=class_names, training=training, root_path=root_path, logger=logger
)
self.split = self.dataset_cfg.DATA_SPLIT[self.mode]
split_dir = os.path.join(self.root_path, 'ImageSets', (self.split + '.txt'))
self.sample_id_list = [x.strip() for x in open(split_dir).readlines()] if os.path.exists(split_dir) else None
self.custom_infos = []
self.include_data(self.mode)
self.map_class_to_kitti = self.dataset_cfg.MAP_CLASS_TO_KITTI
def include_data(self, mode):
self.logger.info('Loading Custom dataset.')
custom_infos = []
for info_path in self.dataset_cfg.INFO_PATH[mode]:
info_path = self.root_path / info_path
if not info_path.exists():
continue
with open(info_path, 'rb') as f:
infos = pickle.load(f)
custom_infos.extend(infos)
self.custom_infos.extend(custom_infos)
self.logger.info('Total samples for CUSTOM dataset: %d' % (len(custom_infos)))
def get_label(self, idx):
label_file = self.root_path / 'labels' / ('%s.txt' % idx)
assert label_file.exists()
with open(label_file, 'r') as f:
lines = f.readlines()
# [N, 8]: (x y z dx dy dz heading_angle category_id)
gt_boxes = []
gt_names = []
for line in lines:
line_list = line.strip().split(' ')
gt_boxes.append(line_list[:-1])
gt_names.append(line_list[-1])
return np.array(gt_boxes, dtype=np.float32), np.array(gt_names)
def get_lidar(self, idx):
lidar_file = self.root_path / 'points' / ('%s.npy' % idx)
assert lidar_file.exists()
point_features = np.load(lidar_file)
return point_features
def set_split(self, split):
super().__init__(
dataset_cfg=self.dataset_cfg, class_names=self.class_names, training=self.training,
root_path=self.root_path, logger=self.logger
)
self.split = split
split_dir = self.root_path / 'ImageSets' / (self.split + '.txt')
self.sample_id_list = [x.strip() for x in open(split_dir).readlines()] if split_dir.exists() else None
def __len__(self):
if self._merge_all_iters_to_one_epoch:
return len(self.sample_id_list) * self.total_epochs
return len(self.custom_infos)
def __getitem__(self, index):
if self._merge_all_iters_to_one_epoch:
index = index % len(self.custom_infos)
info = copy.deepcopy(self.custom_infos[index])
sample_idx = info['point_cloud']['lidar_idx']
points = self.get_lidar(sample_idx)
input_dict = {
'frame_id': self.sample_id_list[index],
'points': points
}
if 'annos' in info:
annos = info['annos']
annos = common_utils.drop_info_with_name(annos, name='DontCare')
gt_names = annos['name']
gt_boxes_lidar = annos['gt_boxes_lidar']
input_dict.update({
'gt_names': gt_names,
'gt_boxes': gt_boxes_lidar
})
data_dict = self.prepare_data(data_dict=input_dict)
return data_dict
def evaluation(self, det_annos, class_names, **kwargs):
if 'annos' not in self.custom_infos[0].keys():
return 'No ground-truth boxes for evaluation', {}
def kitti_eval(eval_det_annos, eval_gt_annos, map_name_to_kitti):
from ..kitti.kitti_object_eval_python import eval as kitti_eval
from ..kitti import kitti_utils
kitti_utils.transform_annotations_to_kitti_format(eval_det_annos, map_name_to_kitti=map_name_to_kitti)
kitti_utils.transform_annotations_to_kitti_format(
eval_gt_annos, map_name_to_kitti=map_name_to_kitti,
info_with_fakelidar=self.dataset_cfg.get('INFO_WITH_FAKELIDAR', False)
)
kitti_class_names = [map_name_to_kitti[x] for x in class_names]
ap_result_str, ap_dict = kitti_eval.get_official_eval_result(
gt_annos=eval_gt_annos, dt_annos=eval_det_annos, current_classes=kitti_class_names
)
return ap_result_str, ap_dict
eval_det_annos = copy.deepcopy(det_annos)
eval_gt_annos = [copy.deepcopy(info['annos']) for info in self.custom_infos]
if kwargs['eval_metric'] == 'kitti':
ap_result_str, ap_dict = kitti_eval(eval_det_annos, eval_gt_annos, self.map_class_to_kitti)
else:
raise NotImplementedError
return ap_result_str, ap_dict
def get_infos(self, class_names, num_workers=4, has_label=True, sample_id_list=None, num_features=4):
import concurrent.futures as futures
def process_single_scene(sample_idx):
print('%s sample_idx: %s' % (self.split, sample_idx))
# print('%s sample_idx: %s' % (self.mode, sample_idx))
info = {}
pc_info = {'num_features': num_features, 'lidar_idx': sample_idx}
info['point_cloud'] = pc_info
if has_label:
annotations = {}
gt_boxes_lidar, name = self.get_label(sample_idx)
annotations['name'] = name
# annotations['gt_boxes_lidar'] = gt_boxes_lidar[:, :7]
# annotations['gt_boxes_lidar'] = gt_boxes_lidar[:, :7] if len(gt_boxes_lidar.shape) == 2 else gt_boxes_lidar
# Prevent np indexing error when only one sample exist!
try:
annotations['gt_boxes_lidar'] = gt_boxes_lidar[:, :7]
except:
annotations['gt_boxes_lidar'] = gt_boxes_lidar[:7]
info['annos'] = annotations
return info
sample_id_list = sample_id_list if sample_id_list is not None else self.sample_id_list
# create a thread pool to improve the velocity
with futures.ThreadPoolExecutor(num_workers) as executor:
infos = executor.map(process_single_scene, sample_id_list)
return list(infos)
def create_groundtruth_database(self, info_path=None, used_classes=None, split='train'):
import torch
database_save_path = Path(self.root_path) / ('gt_database' if split == 'train' else ('gt_database_%s' % split))
db_info_save_path = Path(self.root_path) / ('custom_dbinfos_%s.pkl' % split)
database_save_path.mkdir(parents=True, exist_ok=True)
all_db_infos = {}
with open(info_path, 'rb') as f:
infos = pickle.load(f)
for k in range(len(infos)):
print('gt_database sample: %d/%d' % (k + 1, len(infos)))
info = infos[k]
sample_idx = info['point_cloud']['lidar_idx']
points = self.get_lidar(sample_idx)
annos = info['annos']
names = annos['name']
gt_boxes = annos['gt_boxes_lidar']
num_obj = gt_boxes.shape[0]
point_indices = roiaware_pool3d_utils.points_in_boxes_cpu(
torch.from_numpy(points[:, 0:3]), torch.from_numpy(gt_boxes)
).numpy() # (nboxes, npoints)
for i in range(num_obj):
filename = '%s_%s_%d.bin' % (sample_idx, names[i], i)
filepath = database_save_path / filename
gt_points = points[point_indices[i] > 0]
gt_points[:, :3] -= gt_boxes[i, :3]
with open(filepath, 'w') as f:
gt_points.tofile(f)
if (used_classes is None) or names[i] in used_classes:
db_path = str(filepath.relative_to(self.root_path)) # gt_database/xxxxx.bin
db_info = {'name': names[i], 'path': db_path, 'gt_idx': i,
'box3d_lidar': gt_boxes[i], 'num_points_in_gt': gt_points.shape[0]}
if names[i] in all_db_infos:
all_db_infos[names[i]].append(db_info)
else:
all_db_infos[names[i]] = [db_info]
# Output the num of all classes in database
for k, v in all_db_infos.items():
print('Database %s: %d' % (k, len(v)))
with open(db_info_save_path, 'wb') as f:
pickle.dump(all_db_infos, f)
@staticmethod
def create_label_file_with_name_and_box(class_names, gt_names, gt_boxes, save_label_path):
with open(save_label_path, 'w') as f:
for idx in range(gt_boxes.shape[0]):
boxes = gt_boxes[idx]
name = gt_names[idx]
if name not in class_names:
continue
line = "{x} {y} {z} {l} {w} {h} {angle} {name}\n".format(
x=boxes[0], y=boxes[1], z=(boxes[2]), l=boxes[3],
w=boxes[4], h=boxes[5], angle=boxes[6], name=name
)
f.write(line)
def create_custom_infos(dataset_cfg, class_names, data_path, save_path, workers=4):
dataset = CustomDataset(
dataset_cfg=dataset_cfg, class_names=class_names, root_path=data_path,
training=False, logger=common_utils.create_logger()
)
train_split, val_split = 'train', 'val'
num_features = len(dataset_cfg.POINT_FEATURE_ENCODING.src_feature_list)
train_filename = save_path / ('custom_infos_%s.pkl' % train_split)
val_filename = save_path / ('custom_infos_%s.pkl' % val_split)
print('------------------------Start to generate data infos------------------------')
dataset.set_split(train_split)
custom_infos_train = dataset.get_infos(
class_names, num_workers=workers, has_label=True, num_features=num_features
)
with open(train_filename, 'wb') as f:
pickle.dump(custom_infos_train, f)
print('Custom info train file is saved to %s' % train_filename)
dataset.set_split(val_split)
custom_infos_val = dataset.get_infos(
class_names, num_workers=workers, has_label=True, num_features=num_features
)
with open(val_filename, 'wb') as f:
pickle.dump(custom_infos_val, f)
print('Custom info train file is saved to %s' % val_filename)
print('------------------------Start create groundtruth database for data augmentation------------------------')
dataset.set_split(train_split)
dataset.create_groundtruth_database(train_filename, split=train_split)
print('------------------------Data preparation done------------------------')
if __name__ == '__main__':
import sys
if sys.argv.__len__() > 1 and sys.argv[1] == 'create_custom_infos':
import yaml
from pathlib import Path
from easydict import EasyDict
dataset_cfg = EasyDict(yaml.safe_load(open(sys.argv[2])))
ROOT_DIR = (Path(__file__).resolve().parent / '../../../').resolve()
print(ROOT_DIR)
create_custom_infos(
dataset_cfg=dataset_cfg,
# class_names=['Vehicle', 'Pedestrian', 'Cyclist'],
class_names=['Pedestrian', 'Chair'],
data_path=ROOT_DIR / 'data' / '~_custom_dataset',
save_path=ROOT_DIR / 'data' / '~_custom_dataset',
# data_path=Path(dataset_cfg.DATA_PATH),
# save_path=Path(dataset_cfg.DATA_PATH)
)
마지막 부분에서 classnames, data_path, save_path를 각자 custom dataset에 맞게 설정해줘야 한다.
준비가 다 되었으면 train.py를 실행하면 된다.
만들어준 custom config 경로를 같이 먹여주면 된다.
학습이 완료되면 /output 폴더에 결과들이 저장된다.
train log도 확인할 수 있다.
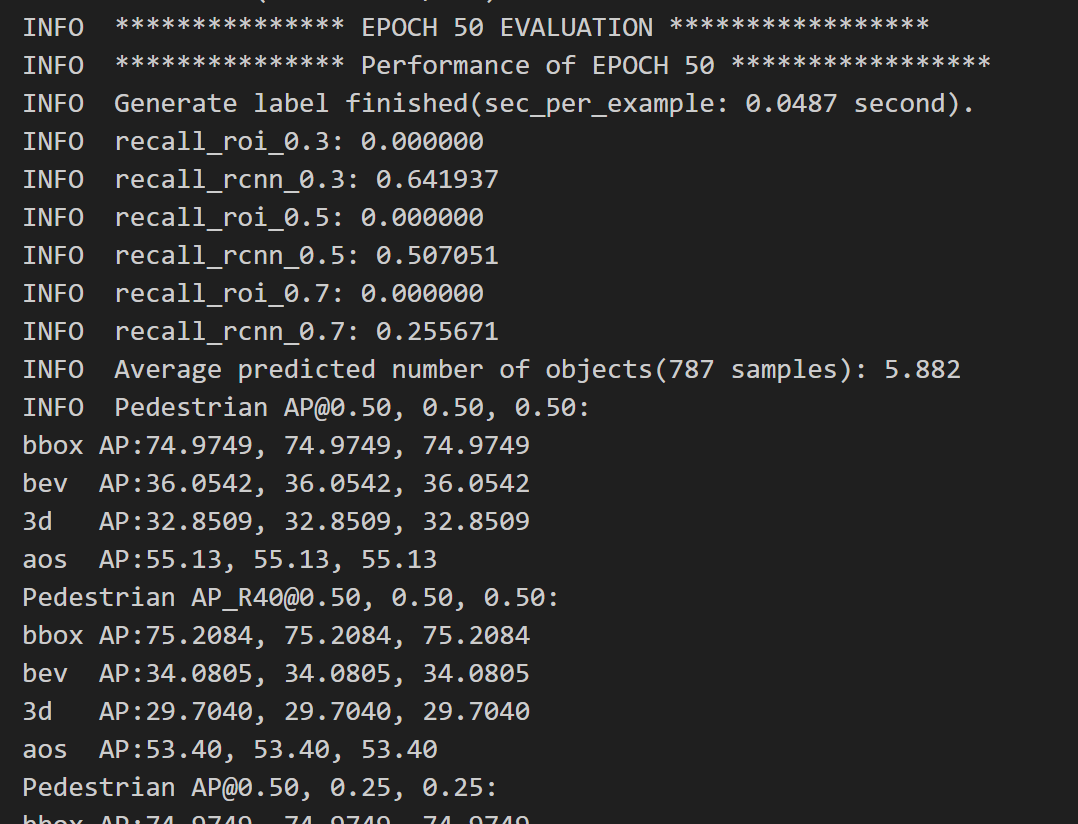
아래 결과는 보행자만 학습시킨 결과이다. custom dataset의 질이 별로 좋지 못해 성능이 아주 좋아보이진 않는다.
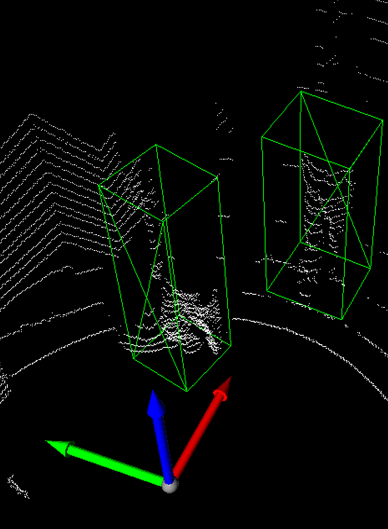
테스트 삼아 학습된 모델로 프레임 한장을 추론해보았다.
이걸 어떻게 인지했지.. ㅋ

화이팅