개요
1. 이상치처리란?
1) 이상치를 검출하고, 처리하는 과정을 통칭한다
2) 검출한 이상치의 형태에 따라 어떻게 처리할지가 결정된다.
- 이상치 처리 프로세스
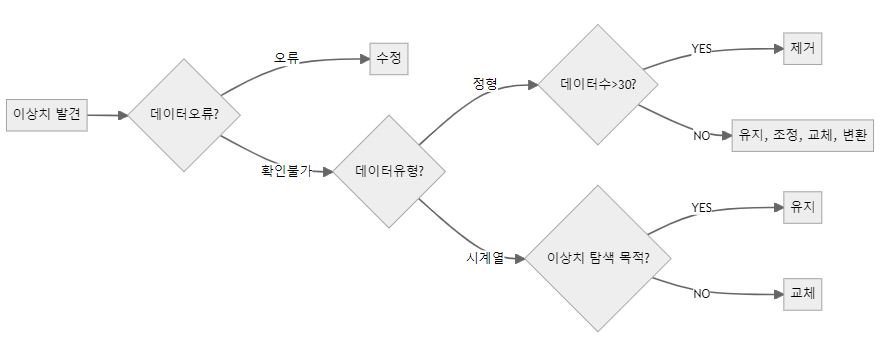
3) 이상치란?
-
일부 관측치의 값이 전체 데이터의 범위에서 크게 벗어난 극단적인 값을 갖는 것
-
분산을 과도하게 증가시켜 검정력, 예측력 등 통계적 특성을 악화시킴
-
전체 데이터수가 많으면, 이상치의 영향이 감소함
4) 통계적 이상치 발생 원인 -
데이터 입력 오류 / 측정 오류 / 실험 오류 / 고의적인 이상값 / 표본
추출 에러
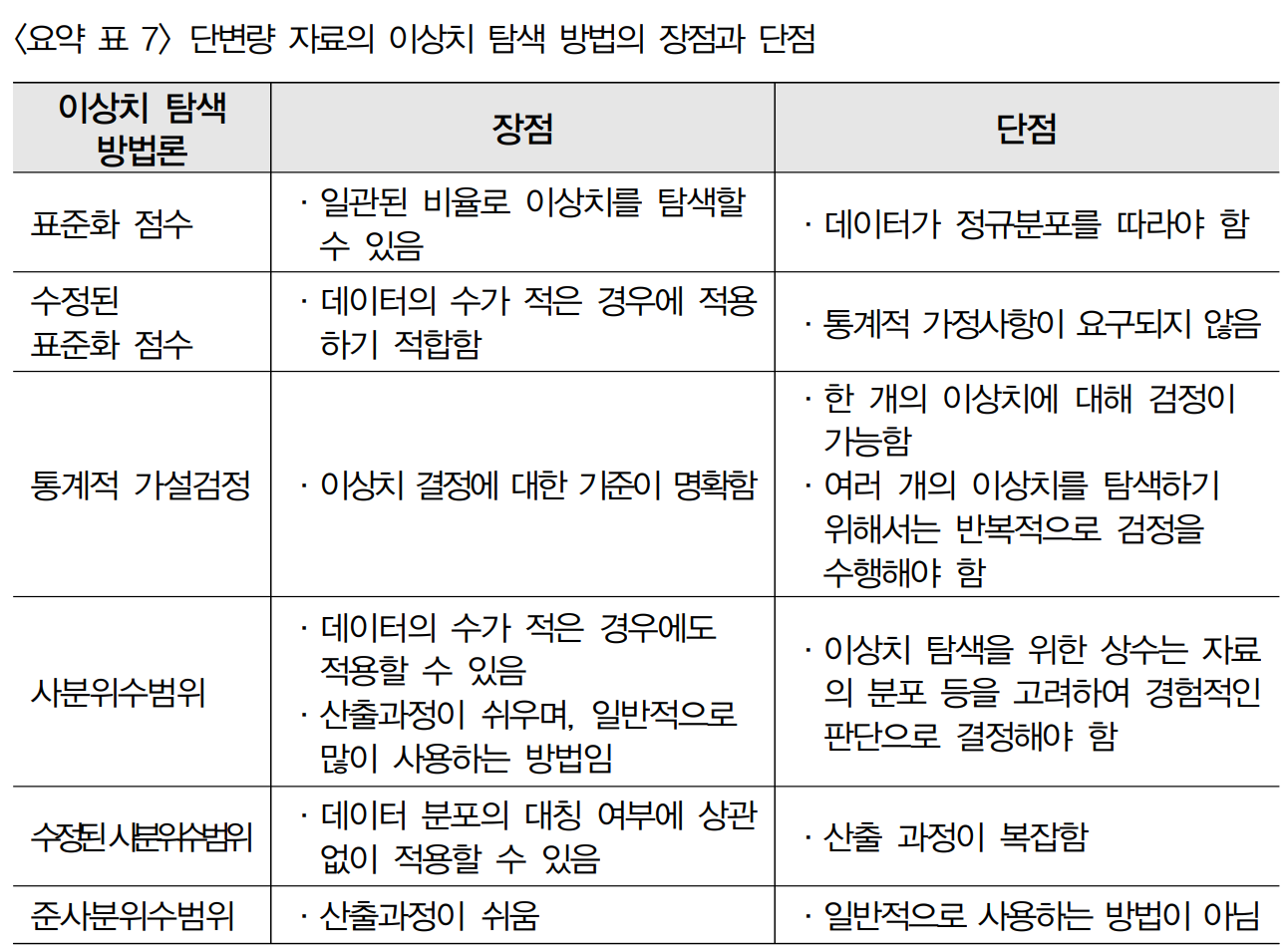
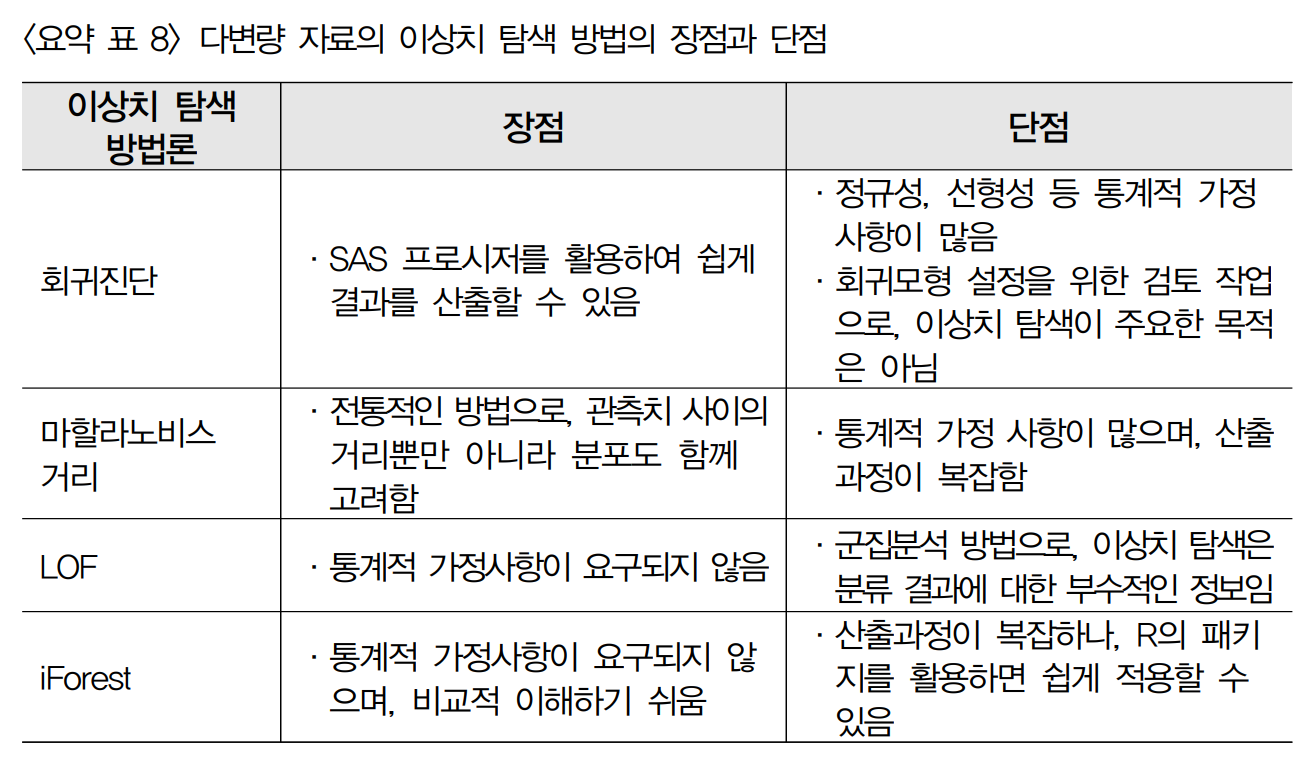
5) 이상치 검출 방법 -
개별 데이터 관찰 / 통계기법 이용(평균, 최빈값,분산등등..) / 시각화
이용(확률 밀도 함수, 히스토그램등등..) / 머신 러닝 기법 이용(K-mean)
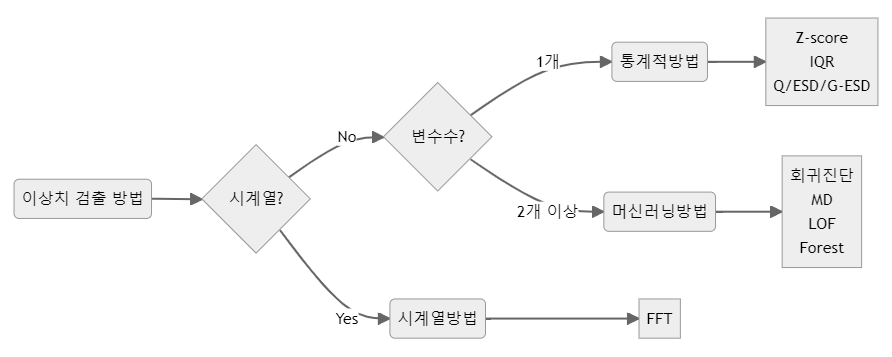
-
단변량 이상치 검출
-
다변량 이상치 검출
- 이 챕터에서는 이상치를 검출하는 과정에대한 코드를 주로 다룰 것이다
이상치 검출 코드
1. 단변량 이상치 검출
1) Z-score를 이용한 이상치 검출
import pandas as pd
from scipy.stats import t, zscore
df = pd.DataFrame({'x':[4, 5, 6, 2, 12, 4, 3, 1, 2, 3, 23, 5, 3]})
z = zscore(df.x)
print('Z-score Outliers:', df.x[(z<-3)|(z>3)].values)2) IQR 및 scikit_posthocs을 이용한 이상치 검출
# IQR(seaborn boxplot)을 이용
import seaborn as sns
sns.boxplot(df.x)
Q1 = df.x.quantile(0.25)
Q3 = df.x.quantile(0.75)
IQR = Q3 - Q1
ols = df.x[(df.x < (Q1 - 1.5 * IQR))|(df.x > (Q3 + 1.5 * IQR))]
print('IQR Outliers 1:', ols.values)
# scikit_posthocs 이용
import scikit_posthocs as sp
print('IQR Outliers 2:', sp.outliers_iqr(df.x, ret = 'outliers'))3) Grubb's test(ESD test) 이용
import scikit_posthocs as sp
# outliers_grubbs는 inliers를 반환함
inliers = sp.outliers_grubbs(df.x)
outliers = df.x[(df.x<inliers.min())|(df.x>inliers.max())]
print('Grubb\'s Outliers:', outliers.values)4) Generalized ESD test 이용
import scikit_posthocs as sp
# outliers_gesd는 test summary를 제공함
print(sp.outliers_gesd(df.x, outliers = 3, report = True))
# outliers_gesd는 inliers를 반환함
inliers = sp.outliers_gesd(df.x)
outliers = df.x[(df.x<inliers.min())|(df.x>inliers.max())]
print('G-ESD Outliers:', outliers.values)2. 다변량 이상치 검출
1) 회귀진단을 이용
- 필요한 패키지 불러오기 및 데이터 준비 / 분석
import pandas as pd
import seaborn as sns
# 데이터세트 불러오기
df = pd.read_csv('../data/outlier_students.csv', sep=',')
# id, name, enployed는 사용하지 않으므로 삭제
df.drop(['id', 'name', 'employed'], axis=1, inplace=True)
df.head()
# 기술통계량 확인
df.describe()
# 그래프로 확인하기
sns.pairplot(df, diag_kind='kde', hue='sex')
# 산점도를 통해 확인
sns.regplot(data=df, x='mid_exam', y='score')
# Boxplot으로 확인하기
sns.boxplot(df_infl, orient="h")- score ~ mid_exam + final_exam에 대한 회귀분석 하기
import statsmodels.api as sm
import statsmodels.formula.api as smf
lm = smf.ols(formula='score ~ mid_exam + final_exam', data=df).fit()
print(lm.summary())- 회귀분석 후 각종 통계량(또는 값)확인
# 영향점(influence point) 계산
import numpy as np
infl = lm.get_influence()
# 레버리지 계산
leverage = infl.hat_matrix_diag
print('Leverage: \n', leverage)
print('Outliers using Leverage: \n', np.where(leverage > 3*np.mean(leverage)))
print()
# 표준화 잔차 계산
resid_standard = lm.resid_pearson
print('Standardized Residuals: \n', resid_standard)
print('Outliers using Standardized Residuals: \n', np.where(np.abs(resid_standard) > 2))
print()
# 스튜던트 잔차 계산
resid_student = infl.resid_studentized_internal
print('Studentized Residuals: \n', resid_student)
print('Outliers using Studentized Residuals: \n', np.where(np.abs(resid_student) > 3))
print()
# 스튜턴트 제외 잔차 계산
resid_student_remove = infl.resid_studentized_external
print('Studentized Deleted Residuals: \n', resid_student_remove)
print('Outliers using Studentized Deleted Residuals: \n', np.where(np.abs(resid_student_remove) > 3))
print()
# Cook's distance 계산
(cooks, p) = infl.cooks_distance
print('Cook\'s Distance: \n', cooks)
print('Outliers using Cook\'s Distance: \n', np.where(np.abs(cooks) > 1))
print()
# DFFITS 계산
(dffits, p) = infl.dffits_internal
print('DFFITS: \n', dffits)
print('Outliers using DFFITS: \n', np.where(dffits > 1))
print()
# DFBETAS 계산
dfbetas = infl.dfbetas
print('DFBETAS: \n', dfbetas)
print('Outliers using DFBETAS: \n', np.where(dfbetas.max(axis=1) > 1, ))
print()
# 영향점 통계량 summary(Pandas)
df_infl = infl.summary_frame()
df_infl
# Boxplot으로 확인하기
sns.boxplot(df_infl, orient="h")
# 영향점(influence point) 그래프로 찾기
import matplotlib.pyplot as plt
fig, axs = plt.subplots(3, 2, figsize=(10, 10))
# 각 영향점 그래프
infl.plot_index(y_var="leverage", threshold=3*np.mean(leverage), ax=axs[0,0])
infl.plot_index(y_var="cooks", threshold=2*np.mean(cooks), ax=axs[0,1])
infl.plot_index(y_var="resid_student", threshold=1, ax=axs[1,0])
infl.plot_index(y_var="dfbeta", idx=1, threshold=0.5, ax=axs[1,1])
# 레버리지 vs. 스튜던트 잔차 플롯
sm.graphics.influence_plot(lm, criterion='cooks', ax=axs[2,0], plot_alpha=0.5)
sm.graphics.influence_plot(lm, criterion='DFFITS', ax=axs[2,1], plot_alpha=0.5)
fig.tight_layout()
plt.show()
# 5번 이상치를 제거한 후 회귀분석 실시
df = pd.read_csv('../data/outlier_students.csv', sep=',')
df.drop(['id', 'name', 'employed'], axis=1, inplace=True)
df.drop([5], inplace=True)
lm = smf.ols(formula='score ~ mid_exam + final_exam', data=df).fit()
print(lm.summary())2) 머신러닝기법 사용
- 필요한 패키지 불러오기 및 데이터 준비 / 분석
import pandas as pd
df = pd.read_csv('../data/outlier_students.csv', sep=',')
# 시각화를 위해 mid_exam과 final_exam 만 사용
df = df[['mid_exam', 'final_exam']]
# 산점도 데이터 포인트에 인덱스를 표시해서 이상치 확인
# seaborn object 활용
import seaborn.objects as so
(
so.Plot(df, x='mid_exam', y='final_exam', text=df.index)
.add(so.Dot())
.add(so.Text(valign="bottom"))
)- 학습1
# MD, iForesest, LOF 모형 학습시키기
from sklearn.covariance import EllipticEnvelope
from sklearn.ensemble import IsolationForest
from sklearn.neighbors import LocalOutlierFactor
# outliers 비중 초기값
outliers_fraction = 0.1
# 모형의 인스탄스를 생성하고 데이터로 학습시킴
md = EllipticEnvelope(contamination=outliers_fraction).fit(df)
iforest = IsolationForest(contamination=outliers_fraction).fit(df)
#LOF은 fit_predict()을 사용해야 함
lof = LocalOutlierFactor(n_neighbors=5, contamination=outliers_fraction)- 학습2
import numpy as np
import matplotlib.pyplot as plt
# Contour를 그리기 위한 데이터세트 생성
# meshgrid()를 이용해서 바둑판 모양의 입력데이터 생성
xx, yy = np.meshgrid(np.linspace(0, 120, 200), np.linspace(0, 120, 200))
df_test = pd.DataFrame(np.c_[xx.ravel(), yy.ravel()], columns=['mid_exam', 'final_exam'] )
# subplot 설정
fig, axs = plt.subplots(1, 3, figsize=(12, 4))
# Mahalanobis Distance, Isolation Forest 그래프 출력
for i, method in enumerate([('Mahalanobis Distance', md), ('Isolation Forest', iforest)]):
Z = method[1].predict(df_test).reshape(xx.shape) # reshape()로 1D -> 2D로 변환
inliers = method[1].predict(df)
print(f'{method[0]}:', inliers)
axs[i].scatter(x=df.mid_exam, y=df.final_exam)
axs[i].contour(xx, yy, Z, levels=[0], linewidths=1, colors="red")
for o, outlier in enumerate(inliers):
if outlier == -1:
axs[i].text(df.mid_exam[o], df.final_exam[o],str(o))
axs[i].set_title(method[0])
# Local Outlier Factor 그래프 출력
inliers = lof.fit_predict(df)
X_scores = lof.negative_outlier_factor_
print('Local Outlier Factor:', inliers)
axs[2].scatter(x=df.mid_exam, y=df.final_exam)
# 데이터 포인트에 X_score의 크기에 따라 그려줄 반원 크기 계산
radius = (X_scores.max() - X_scores) / (X_scores.max() - X_scores.min())
axs[2].scatter(x=df.mid_exam, y=df.final_exam, s=1000 * radius, edgecolors="r", facecolors="none")
for o, outlier in enumerate(inliers):
if outlier == -1:
axs[2].text(df.mid_exam[o], df.final_exam[o],str(o))
axs[2].axis([0,120,0,120])
axs[2].set_title('Local Outlier Factor')
plt.show()
Data Scientist