개요
1. 노이즈 처리(디노이징(Denoising))란?
1) 노이즈란?
-
측정된 변수에 무작위의 오류(random error) 또는 분산(variance)이 존재하는 것
-
정형 데이터의 노이즈(분산 / 오차항(설명할 수 없는 무작위 변동ϵ))
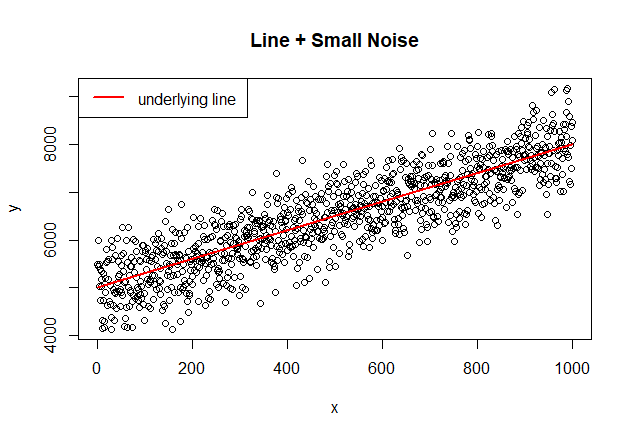
-
이미지 / 영상 데이터의 노이즈(blur / white,pink,Gausian noise)

-
시계열 / 음성 / 신호 데이터의 노이즈(white, Gausian noise)
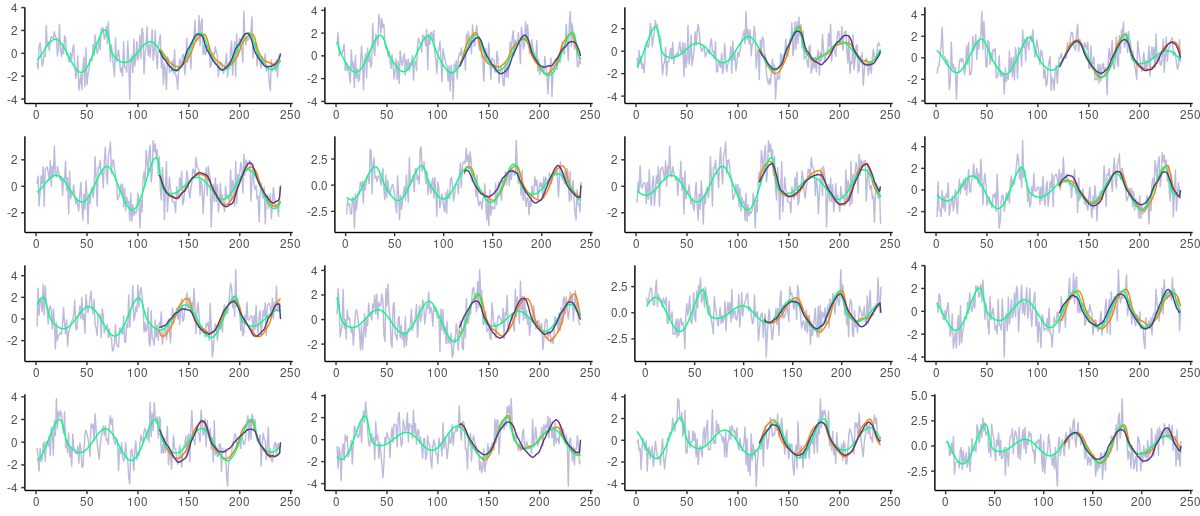
-
텍스트 데이터 노이즈(철자오류, 구두점 누락, 반복 오류등등..)

2) 노이즈 처리는 데이터나 신호에서 발생하는 위와같은 노이즈를 제거 또는 감소시키는 과정을 의미한다
3) 이러한 노이즈는 데이터의 원래 패턴이나 신호를 왜곡시키고 분석 결과에 부정적인 영향을 미칠 수 있다
4) 따라서 노이즈 처리의 목적은 정확성 향상과 의미 있는 정보 추출을 도모하는 것이다
5) 위에서 설명한것처럼 다양한 노이즈들이 발생할 수 있지만, 그 중에서 가장 빈번하게 발생하는 정형데이터에 대한 노이즈 처리(디노이징)방식을
아래에서 설명하겠다.
정형 데이터 디노이징 코드
1. 구간화(동일 간격 구간화 / 동일 빈도 구간화)
- 구간화란?
정렬된 데이터 값들을 몇개의 구간으로 분할하고, 이를 대표값으로 대체하는 과정
1) 구간별 대표값 설정 방법(대체할 값을 선정함)
- 평균값 평활화 : bin에 있는 값들을 평균값으로 대체
- 중앙값 평활화 : 중앙값으로 대체
- 경계값 평활화 : 경계값 중 가까운 값으로 대체
2) 동일 간격 구간화(동일한 간격으로 구간을 설정)
- pandas의 cut() 함수 사용
- 정상 데이터가 한쪽으로 편중되고 outlier에 의해 영향 을 많이 받음 * 한쪽으로 몰려있는 데이터들은 다 동일한 구간으로 들어오기 때문에skewed data를 다룰 수 없음
3) 동일 빈도 구간화(동일한 개수의 데이터를 가지는 구간으로 설정)
- pandas의 qcut() 사용
-
구간화 코드
-
구간화 할 데이터 생성
import pandas as pd
import numpy as np
df = pd.DataFrame({'uniform': np.sort(np.random.uniform(0,10,10)),
'normal': np.sort(np.random.normal(5,1,10)),
'gamma': np.sort(np.random.gamma(2, size=10))})
df.plot(kind='hist', bins=15, alpha=0.5)
df.describe()- 동일 간격 / 동일 빈도 구간화 실행
# cut(), qcut() 준비
col = 'uniform'
num_bins = 5
df_binned = pd.DataFrame()
df_binned[col] = df[col].sort_values() # 원 데이터
# 동일 간격 구간화
df_binned['eq_dist_auto'] = pd.cut(df_binned[col], num_bins)
# 동일 빈도로 나누기
df_binned['eq_freq_auto'] = pd.qcut(df_binned[col], num_bins)
# 결과 확인
df_binned- 구간화 된 데이터를 평균값으로 대체하기
# 구간화하여 평균값 대체하기
cols = ['uniform', 'normal', 'gamma']
# 데이터 준비 / 추후에 비교하여 보여주기 위해서 copy함
df_ew = df.copy()
# 동일 간격 구간화(구간분할 / 평균값 계산 후 대체과정)
for col in cols:
df_ew[col+'_eq_dist'] = pd.cut(df_ew[col], 3)
means = df_ew.groupby(col+'_eq_dist')[col].mean()
df_ew.replace({col+'_eq_dist': means}, inplace=True)
# 결과 확인
display(df_ew)
# 동일 빈도 구간화(구간 분할 / 평균값 계산 후 대체과정)
df_ef = df.copy()
for col in cols:
df_ef[col+'_eq_freq'] = pd.qcut(df_ef[col], 3)
means = df_ef.groupby(col+'_eq_freq')[col].mean()
df_ef.replace({col+'_eq_freq': means}, inplace=True)
# 결과 확인
display(df_ef)
# 시각화(선택사항)
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(10,5))
df_ew.astype(float).plot(ax=axes[0])
df_ef.astype(float).plot(ax=axes[1])
plt.show()2. 군집화
- 군집화란?
유사한 값들을 하나의 군집으로 처리하여 중심점(centroid)을 대표값으로 대체하는 과정
1) K-means 군집화
-
Scikit-Learn의 KMeans() 함수 사용
-
군집화 코드
# 필요한 라이브러리(클래스 / 함수) 가져오기
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
# 예제 데이터 생성
n_samples = 300
random_state = 42
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
# 노이즈 추가
np.random.seed(random_state)
noise = np.random.normal(size=(n_samples, 2))
X_noisy = X + 1.5 * noise
# 군집화 수행 (K-mans)
n_clusters = 3
kmeans = KMeans(n_clusters=n_clusters, random_state=random_state)
kmeans.fit(X_noisy)
# 군집화 결과 확인
labels = kmeans.labels_
centers = kmeans.cluster_centers_
# 그래프로 시각화
plt.scatter(X_noisy[:, 0], X_noisy[:, 1], c=labels, cmap='viridis', alpha=0.7)
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='X', s=200)
plt.title('K-Means Clustering for Noise Removal')
plt.show()
2) DBSCAN (밀도(density) 기반 군집화)
- Scikit-Learn의 DBSCAN()함수 사용
# 필요 라이브러리(클래스 / 함수) 가져오기
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import DBSCAN
# 예제 데이터 생성
n_samples = 300
random_state = 42
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
# 노이즈 추가
np.random.seed(random_state)
noise = np.random.normal(size=(n_samples, 2))
X_noisy = X + 1.5 * noise
# DBSCAN 군집화
eps = 0.5 # 이웃의 최대 거리
min_samples = 5 # 군집으로 간주할 최소 데이터 수
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
labels = dbscan.fit_predict(X_noisy)
# 군집화 결과 확인
core_samples_mask = np.zeros_like(labels, dtype=bool)
core_samples_mask[dbscan.core_sample_indices_] = True
# 그래프로 시각화
plt.scatter(X_noisy[:, 0], X_noisy[:, 1], c=labels, cmap='viridis', alpha=0.7)
plt.title('DBSCAN Clustering for Noise Removal')
plt.show()

Data Scientist