개요
1. 파이프라인(Pipe line)이란?
1) 파이프 라인의 개념 및 특징
- 여러 개의 데이터의 처리를 하나의 처리과정으로 만들어 데이터를 일괄
처리해 주는 기능 - 파이프라인을 사용하면 데이터 전처리나 모델 구축 과정 등을
짧은 코드 + 더 가시성 있게 + 더 효율적으로 처리가능함
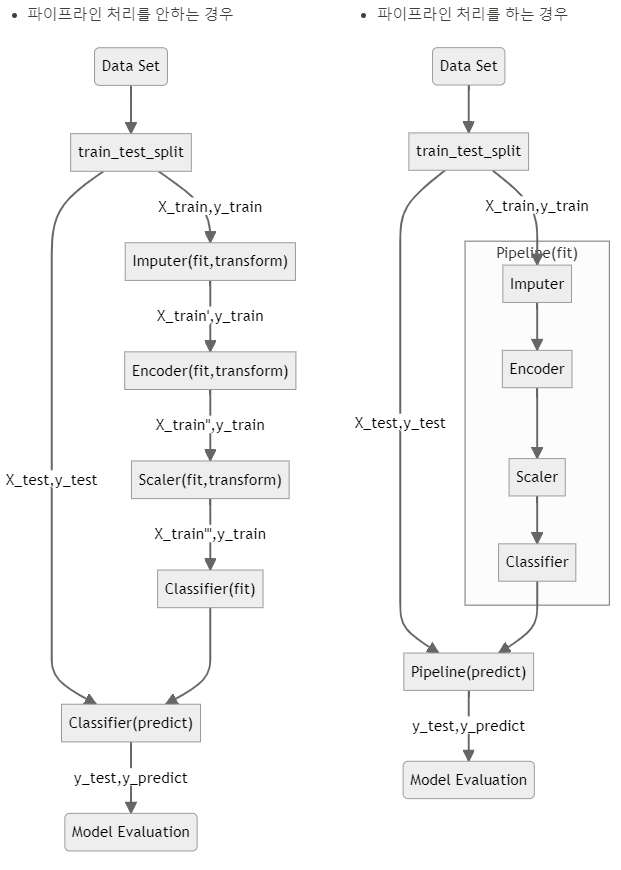
- 파이프라인을 제공하는 패키지
- pandas / polas -> 데이터프레임에서 사용
- SciKit-Learn -> 머신러닝에서 사용(!!중요!!)
- TensorFlow / PyTorch -> 딥러닝에서 사용
파이프라인
1. SciKit-Learn의 파이프라인 코드
- 특이사항 : 코드형태가 key / value 형식을 띔
1) Pipeline() 함수사용
# 필요 라이브러리(클래스 / 함수) 가져오기
from sklearn.pipeline import Pipeline # 파이프라인
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.preprocessing import StandardScaler
# 의사결정나무 분류기 가져오기
from sklearn.tree import DecisionTreeClassifier
# SciKit-Learn에서 iris 데이터세트 가져오기
from sklearn.datasets import load_iris
# iris 데이터세트 로드
X, y = load_iris(return_X_y=True)
# pipeline 구축(피쳐 선택->표준화->학습 모델설정)
pipeline = Pipeline([
('Feature_Selection', SelectKBest(f_classif, k=2)),
('Standardization', StandardScaler()),
('Decision_Tree', DecisionTreeClassifier(max_depth=3))
])
# 파이프라인 구성을 시각화
display(pipeline)
# 모형 학습(fit)
pipeline.fit(X, y)
# 예측결과 확인
print('Estimate : ', pipeline.predict(X)[:3])
# 성능평가 확인
print('Accuracy : ', pipeline.score(X, y))2) make_pipeline() 함수사용(파이프라인 이름을 자동으로 만들어 줌)
# 필요 함수 가져오기(파이프라인)
from sklearn.pipeline import make_pipeline
# 파이프라인 만들기(make_pipeline함수 사용)
pipeline_auto = make_pipeline(SelectKBest(f_classif, k=2),
StandardScaler(),
DecisionTreeClassifier(max_depth=3))
# 파이프라인 시각화
display(pipeline_auto)3) 파이프라인 내부 중간결과 확인하기
# pipiline의 Feature_Selection step에 인덱스 할당(0)
pipeline.named_steps['Feature_Selection'] == pipeline[0]
# pipiline의 Standardization step에 인덱스 할당(1)
pipeline.named_steps['Standardization'] == pipeline[1]
# pipiline의 Decision_Tree step에 인덱스 할당(2)
pipeline.named_steps['Decision_Tree'] == pipeline[2]
# pipiline의 Feature_Selection step의 결과 확인
print('Selected features:', pipeline.named_steps['Feature_Selection'].get_feature_names_out())
# Standardization과정을 transform시켜 저장
X_transformed = pipeline[1].transform(X_selected)
# 그 결과를 보여줌
print('Standard Scaled: \n', X_transformed[:5, :])2. 파이프라인 결합
1) 수치형 데이터 파이프라인 + 범주형 데이터 파이프라인 결합
- 수치형 파이프라인 생성(자세한 설명 생략)
# 필요 패키지(클래스 / 함수) 가져오기
import seaborn as sns
import pandas as pd
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
# 데이터 로드
df = sns.load_dataset('diamonds')
print(df.info())
X = df.drop('price', axis=1)
y = df['price']
# 데이터를 유형에 따라 분리(수치형 / 범주형 구분위함)
numeric_col = list(X.select_dtypes(exclude='category').columns)
category_col = list(X.select_dtypes(include='category').columns)
print(f'numeric_col: {numeric_col}')
print(f'category_col: {category_col}')
# 파이프라인 구축(수치형) / Nan값 평균값으로 채우기 -> 표준화과정
numeric_pipeline = Pipeline(
steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
# 파이프라인 시각화(수치형)
display(numeric_pipeline)
# 파이프라인 학습+적용(.fit_transform())
numerical_data_piped = numeric_pipeline.fit_transform(X[numeric_col])
pd.DataFrame(numerical_data_piped, columns=numeric_col).head()- 범주형 파이프라인 생성(자세한 설명은 생략)
# 필요한 패키지(클래스 / 함수) 가져오기
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
# 파이프라인 구축
# 비어있는 값을 'missing'으로 채우기-> Onehotencoder(인코딩) 과정
category_pipeline = Pipeline(
steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(sparse_output=False)),
])
# 파이프라인 시각화
display(category_pipeline)
# 파이프라인 학습+적용(fit_transform())
category_data_piped = category_pipeline.fit_transform(X[category_col])
# 추가 : Onehotencoder의 컬럼명 확인
category_colnames = category_pipeline[1].get_feature_names_out(category_col)
# 파이프라인 이후 데이터(array형 -> 데이터프레임으로 변경됨)
pd.DataFrame(category_data_piped, columns=category_colnames).head()- 파이프라인 결합(수치형 + 범주형)
# 필요패키지(클래스 / 함수) 가져오기
from sklearn.compose import ColumnTransformer
from sklearn.linear_model import LinearRegression
# 수치형 / 범주형 파이프라인 합치기(ColumnTransforme()함수 사용)
preprocessor = ColumnTransformer(
transformers=[
('numeric', numeric_pipeline, numeric_col),
('category', category_pipeline, category_col)
])
# 합친 파이프라인(preprocessor)에 선형회귀(LinearRegression)추가
pipe = make_pipeline(preprocessor, LinearRegression())
# 파이프라인 시각화(구성확인)
display(pipe)
# 학습시키기(fit)
pipe.fit(X,y)
# 결과확인
print('Estimate : ', pipe.predict(X))
print('Accuracy : ', pipe.score(X, y))
Data Scientist