VGGNet
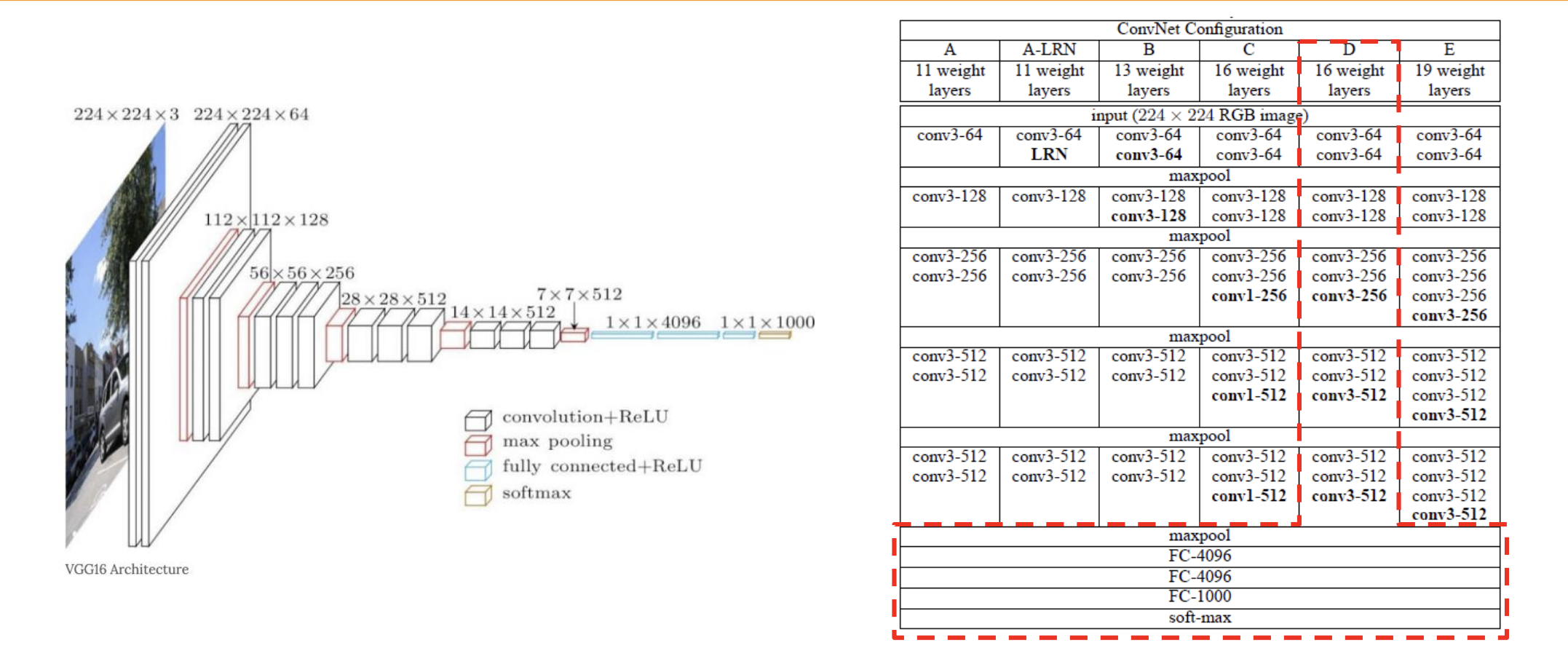
- 논문에 제시된 구조를 토대로 layer 를 쌓을 수 있어야 한다
=> size 에 대한 개념이 중요 (어디서 어떤 layer 를 쌓아야 하는지) - convolution layer 에 입력되는 이미지는 논문에 제시된 크기로 맞춰야 한다
- 오른쪽의 용어들을 살펴보자
- n weight layers : 사용하는 레이어가 n 개
- conv3-64 : 3x3 size kernel 을 가진 필터를 64개 사용함 (padding = 1, stride = 1)
Receptive Field
layer 를 많이 쌓을수록 모델의 성능이 더 좋아질까?
- 어떤 feature map 에 filter 가 적용되는 과정을 살펴보자
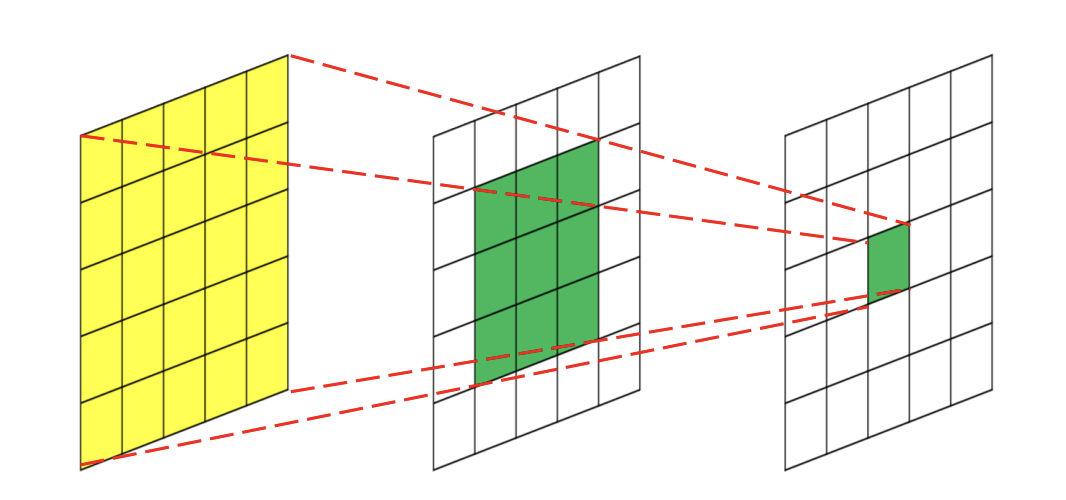
- 필터가 집중적으로 보는 이미지의 영역을 Receptive Field 라고 한다
- convolution 을 통해 feature map 이 작아지기 때문에 Receptive Field 는 층을 지날수록 커진다

- 위 예시를 보면, 같은 크기의 kernel 을 통해 얼굴 전체를 인식할 수 있게 되었다
왜 큰 크기의 filter 를 쓰지 않을까?
- 위 예시에서 3x3 필터를 두 번 사용한 feature map 의 크기는 5 x 5 필터 한 번 사용한 것과 같다
- 그렇다면 왜 굳이 작은 필터를 여러 번 사용한걸까?
=> 보더 더 세밀한 특징 정보를 추출할 수 있기 때문이다 - 하지만 큰 필터는 한 번에 더 많은 위치 정보를 감지할 수 있다는 장점이 있긴 하다
VGGNet 은 3x3 필터를 많이 사용해 receptive field 를 늘리는 것에 초첨을 맞췄다
Inception V1
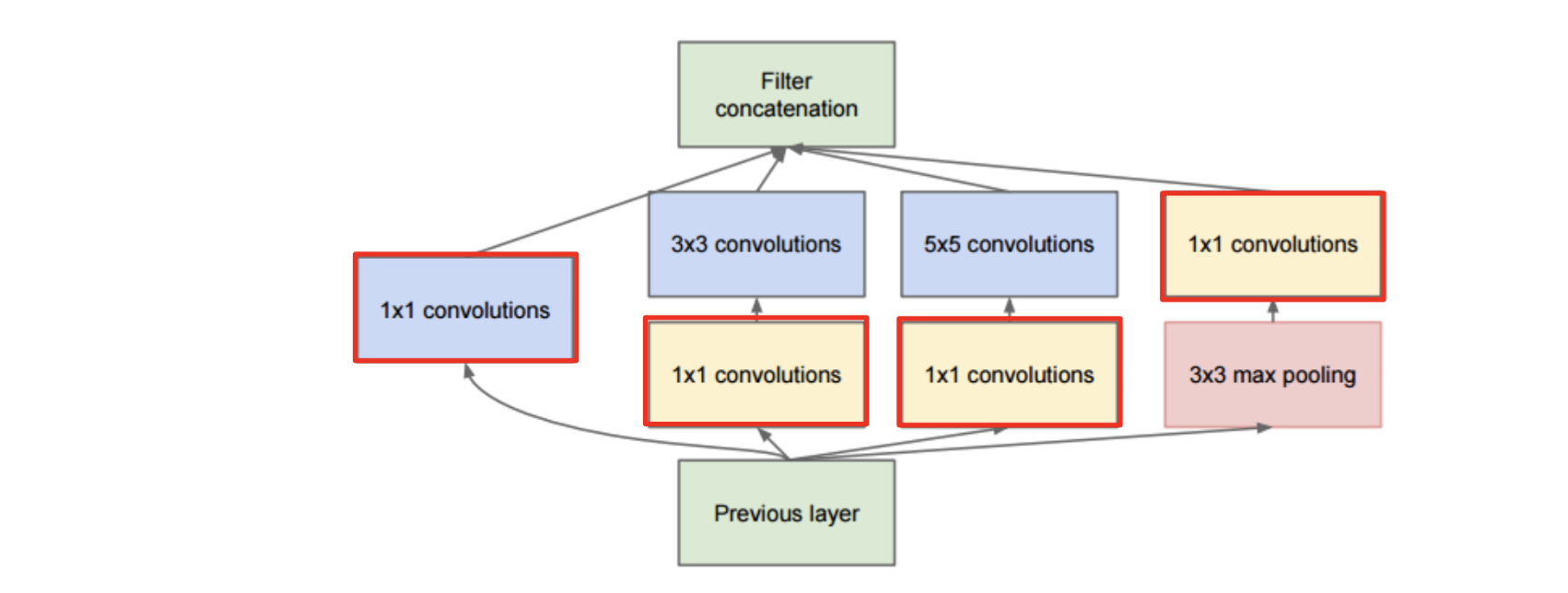
- inception 은 다양한 크기의 필터를 이용해 feature map 을 조합하는 데 초점을 두었다
=> 1x1, 3x3, 5x5 필터를 동시에 통과시켜 concatenate - concatenate 를 하기 위해 각 convolution 의 결과물의 height, width 를 맞춰줘야 한다
=> channel 수는 달라도 된다
=> 그러므로, channel 방향으로 concat 진행
Bottleneck
- inception 은 다른 convolution 전 1x1 convolution 을 통해 채널의 수를 줄여준다
=> 위 사진의 빨간 부분
=> 이를 bottleneck 이라고 한다 - padding 을 사용하는 것 보다 연산의 수(parameter 수)가 적다
- 3x3 convolution 과의 비교를 통해 bottleneck 의 효과를 알아보자
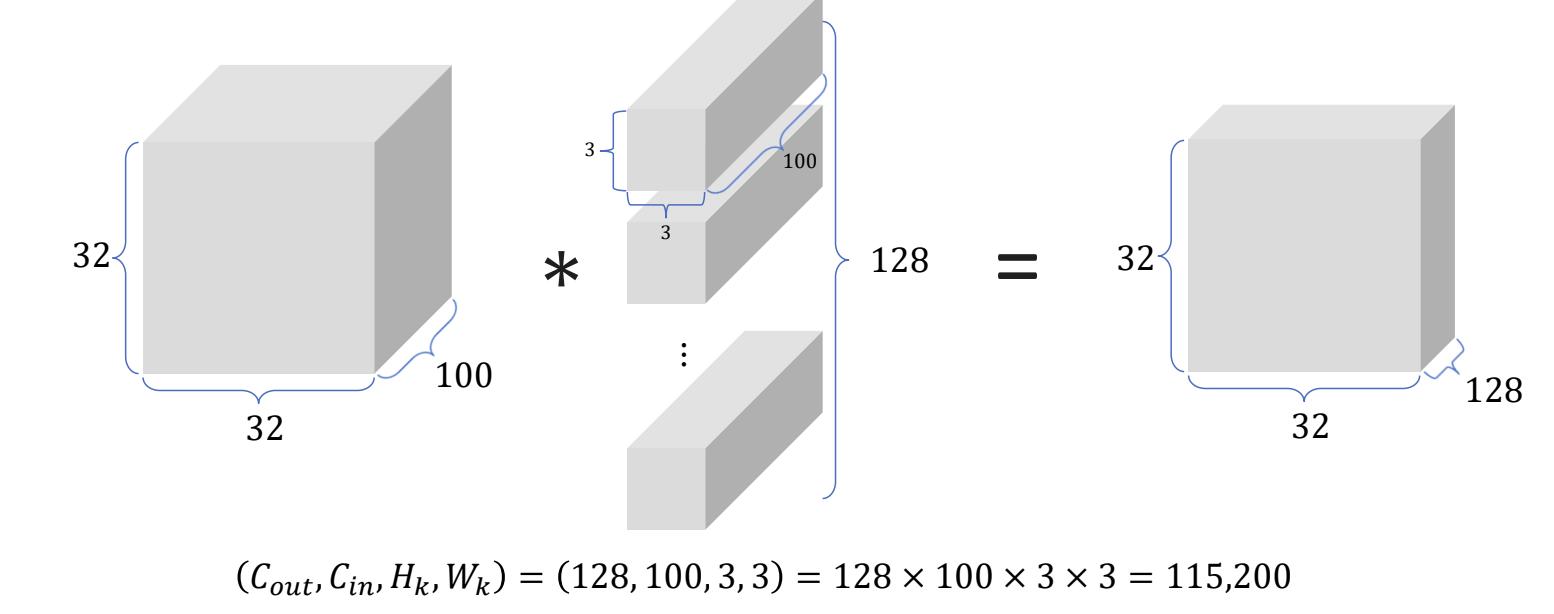
- 3x3 convolution 사용 시 115,200 개의 params 필요
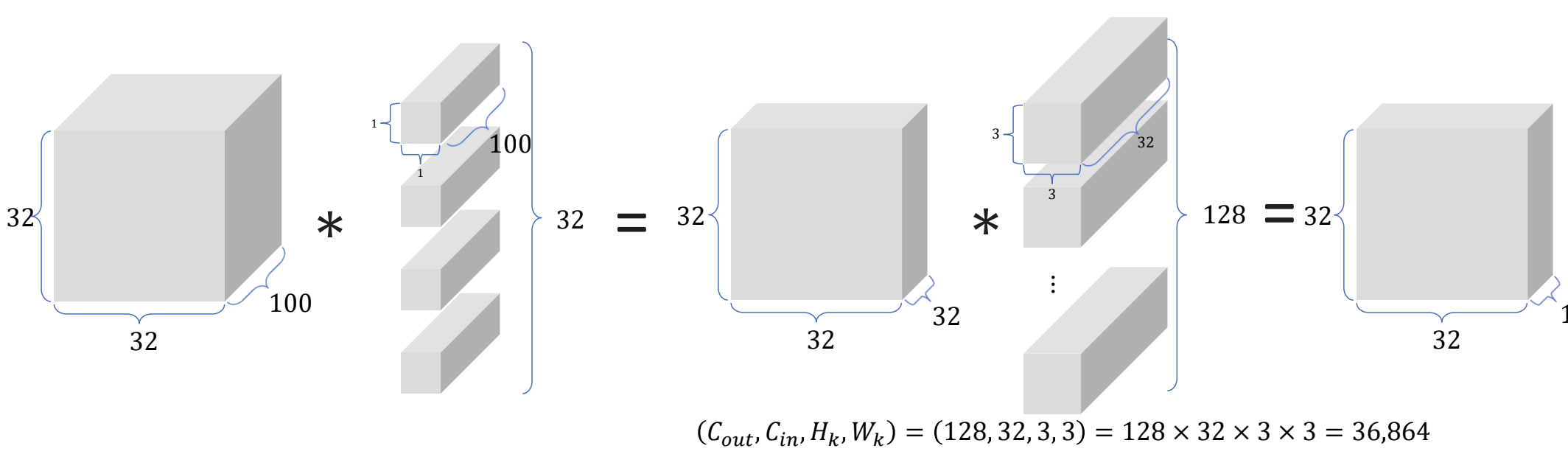
- 의도한 feature map 을 얻으면서 params 의 수가 확연하게 줄어든 것을 관찰할 수 있다.
Inception V1 Structure
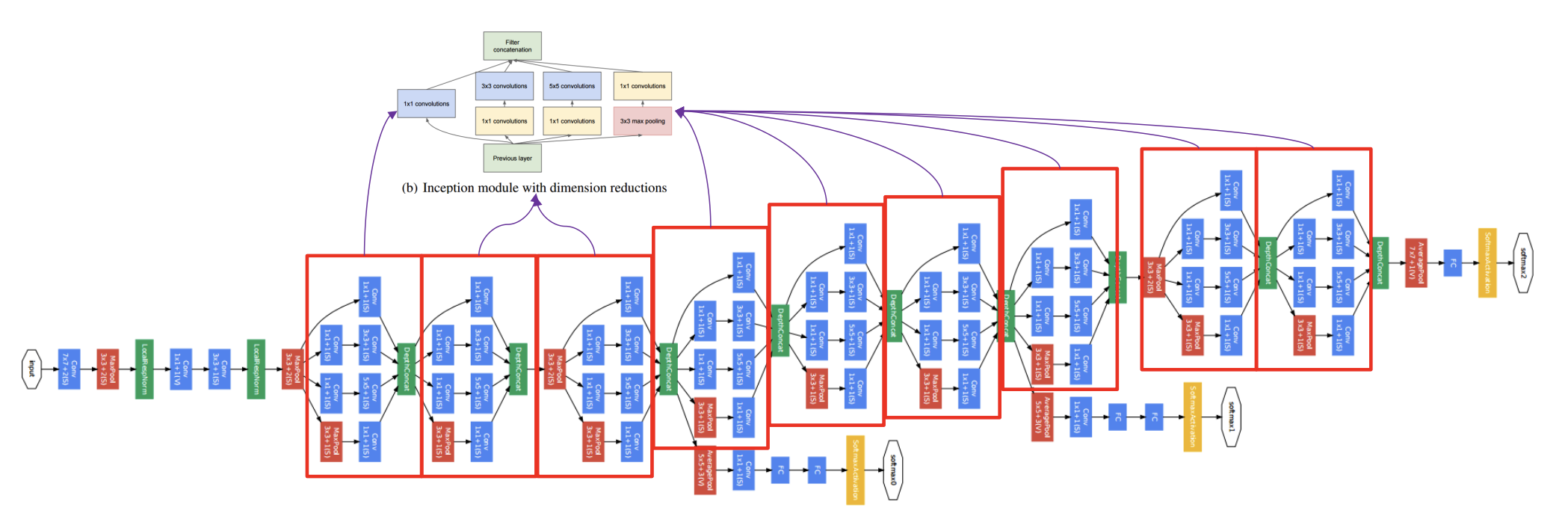
- 1x1, 3x3, 5x5 필터를 활용한 모듈 구조가 계속해서 반복된다
- bottleneck 활용으로 인해 층이 깊어졌다.
- 이 때, back propagation 에서 문제가 생긴다
- 층이 깊어 vanishing gradient 발생 가능
- 훈련 과정 중 auxilary classifier 로 기울기를 추가적으로 전달해 기울기 소실 방지
Inception V2, V3
- VGG net 의 아이디어를 수용, 확장
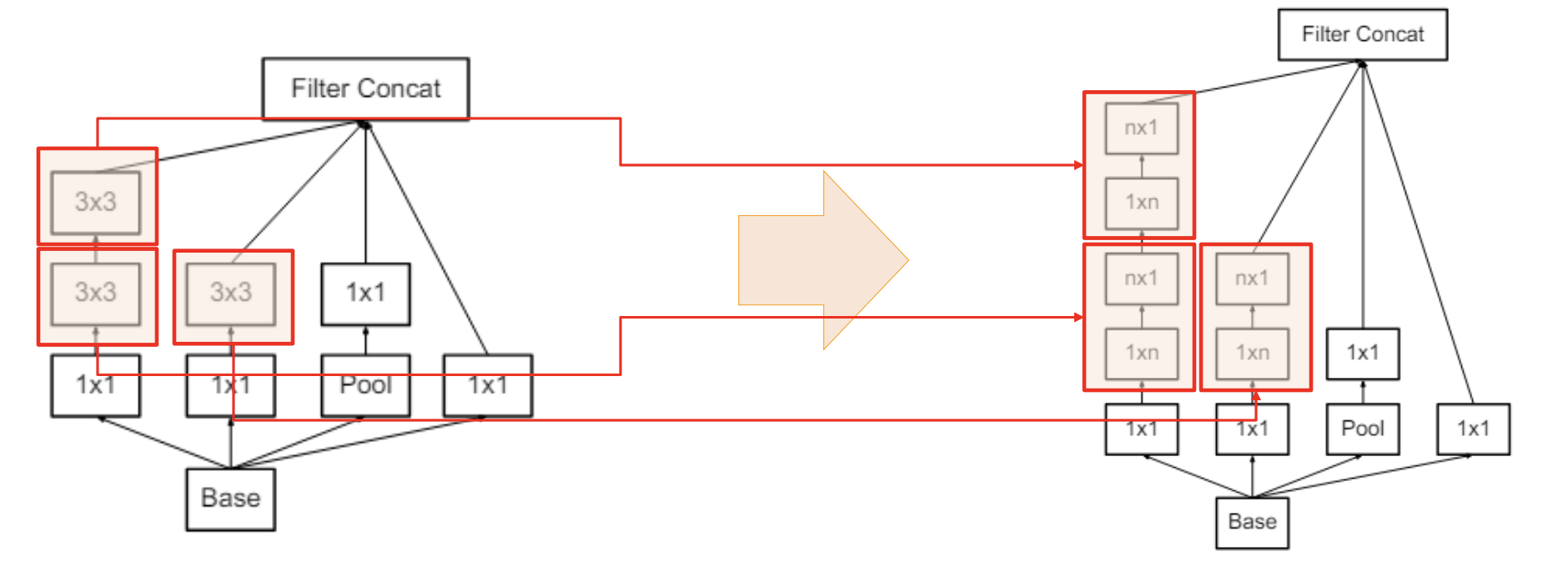
=> 3x3 convolution 을 두 번 이용해 5x5 receptive field 를 얻는다 - inception v1 의 5x5 conv 를 두 개의 3x3 으로 교체
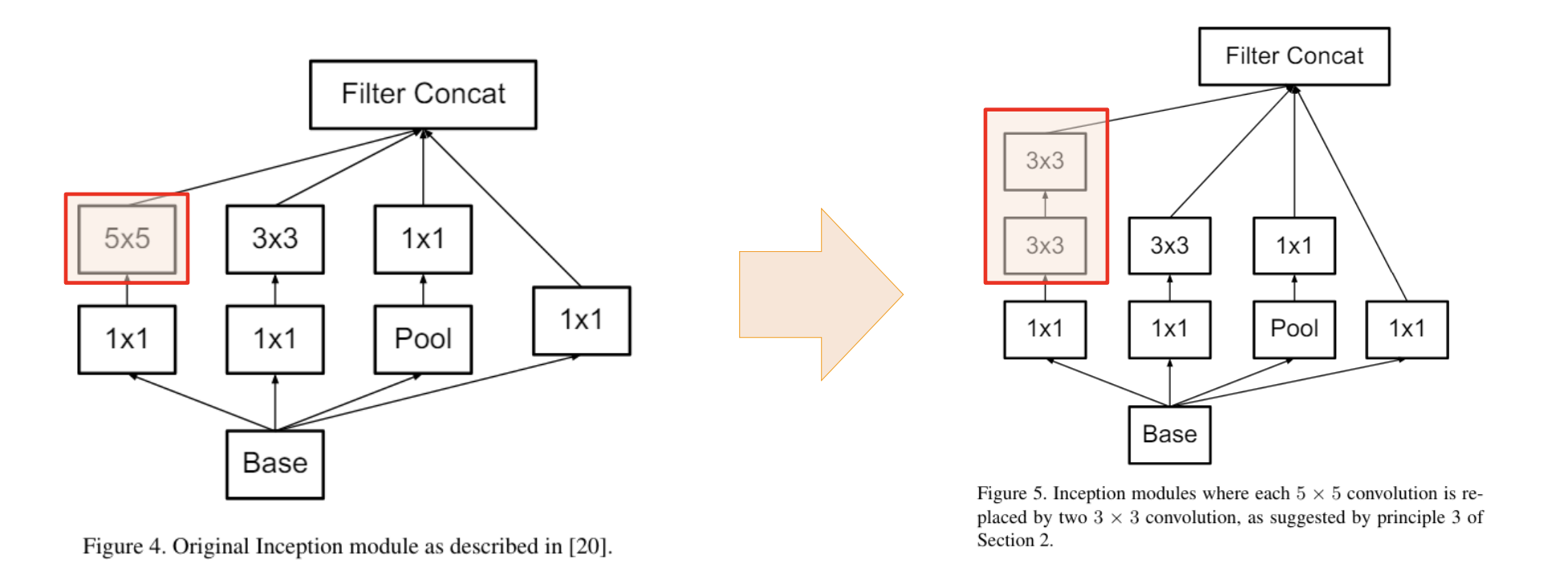
- 더 세밀하게 데이터를 볼 수 있지만, parameter 수가 많아진다
- parameter 갯수를 줄이기 위해 3x3 conv 를 1x3 + 3x1 로 쪼개는 방법도 제시된
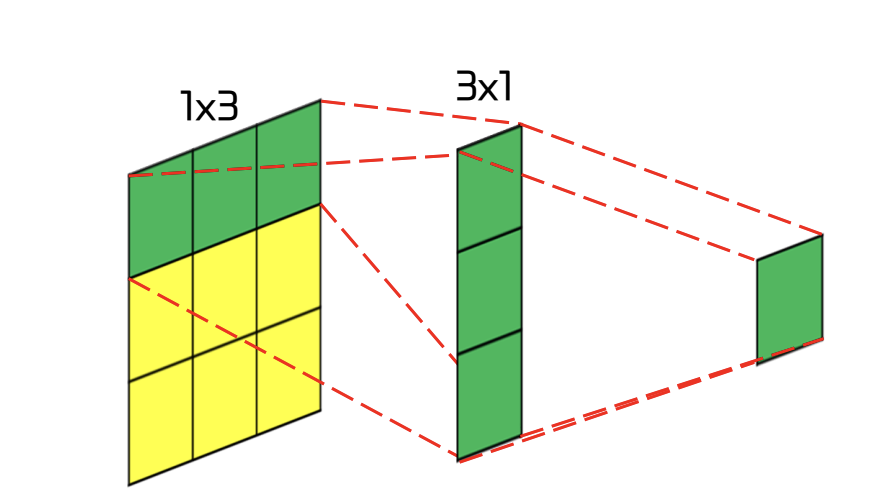
- 논문에서는 n 을 7로 제시함 (7x7 => 1x7 + 7x1)
Residual Network
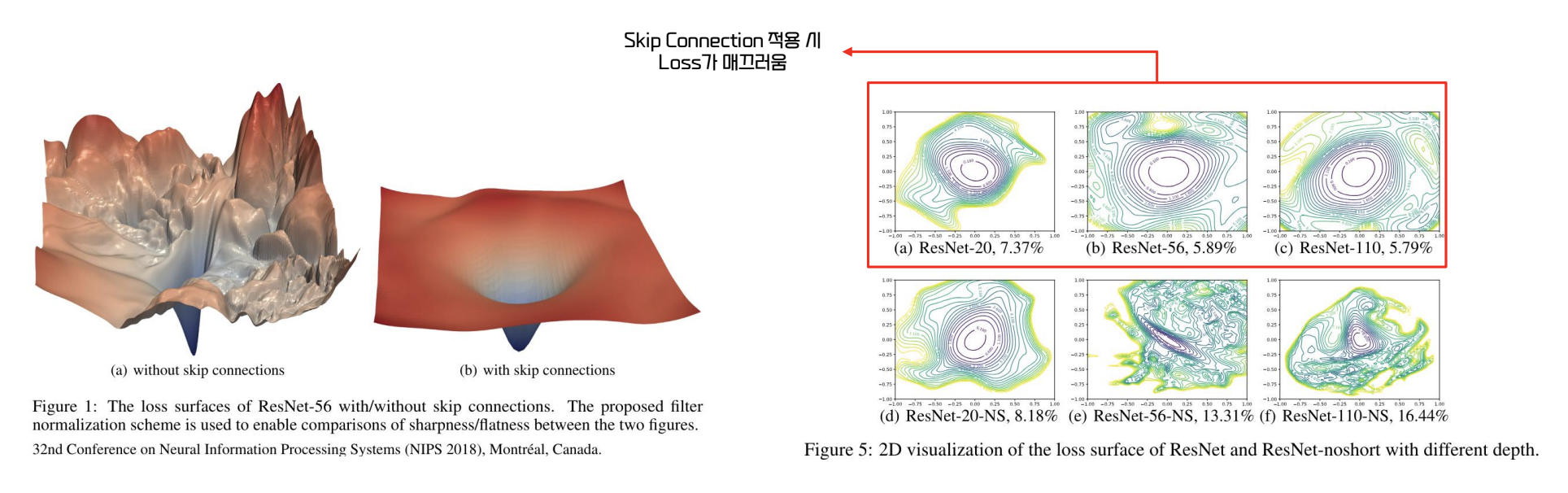
Loss Landscape
- 딥러닝 모델의 1 원칙은 층을 많이 쌓아 학습을 위한 parameter 를 많이 준비하는 것이었다.
- 하지만, 오히려 층이 깊어질수록 과소적합이 발견되었다.
=> loss 의 모양이 이상함을 발견함
 - skip connection 을 이용해 깊은 층에서도 제대로 된 학습이 되도록 해결
- skip connection 적용 시 loss 가 매끄러워진다
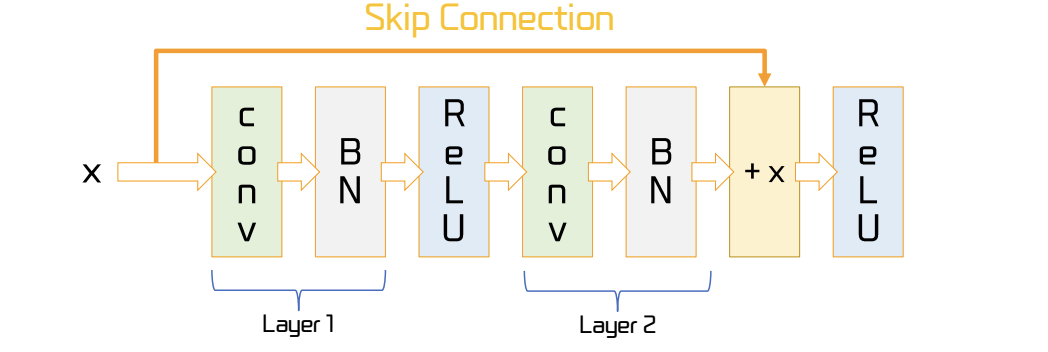
skip connection
- 어떤 레이어를 함수 로 생각하면, 가 입력되었을 때 가 나오는 것이 기존의 방식
- skip connection 은 가 아닌 가 나오게 하는 것
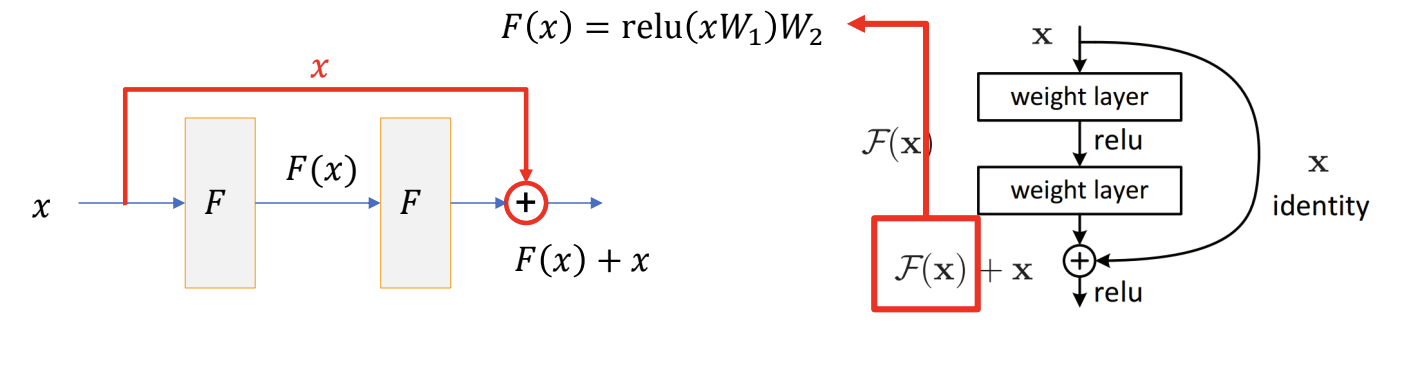
를 이용했을 때의 차이점이 뭘까?
- 가 입력되었을 때 가장 이상적인 (loss 가 감소하는) 출력을 라고 해보자
- 에 가까워지기 위해서 필요한 가중치 행렬은 다음과 같다:
- without skip connection : 항등행렬 (I)
- with skip connection : 영행렬
- 더하는 값이 생겼으므로 vanishing gradient 개선
Residual (잔차)
위의 예시에서 인 상황을 가정한 이유는 뭘까?
- 매우 깊은 긴경망이 존재한다면, loss 도달 까지 값을 차근차근 바꿔나가는 것이 더 좋다
- 급격하게 값이 바꾼다면, 분류 성능도 나빠질 것
- 으로 수식이 정리된다
=> 를 잔차라고 한다
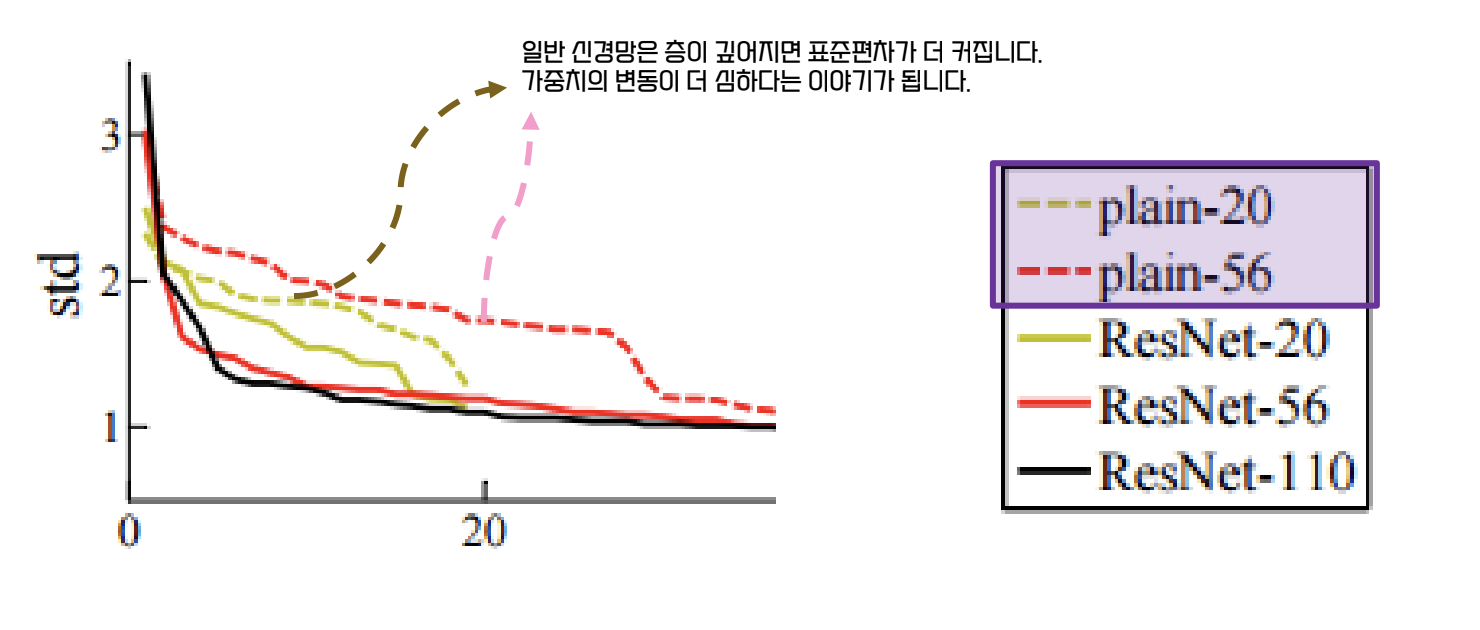
=> 잔차가 0 에 가까워지도록 학습하는 것이 ResNet - ResNet 은 층이 깊어질수록 값을 조금씩 바꾸어, 표준편차가 작다
Residual Learning
- 한 층만 가지고 skip connection 적용 시 효율이 그리 좋지 못했음
=> 2개, 3개의 층을 점프
=> 3개 점프 시 bottleneck 사용
VGG 와 비교
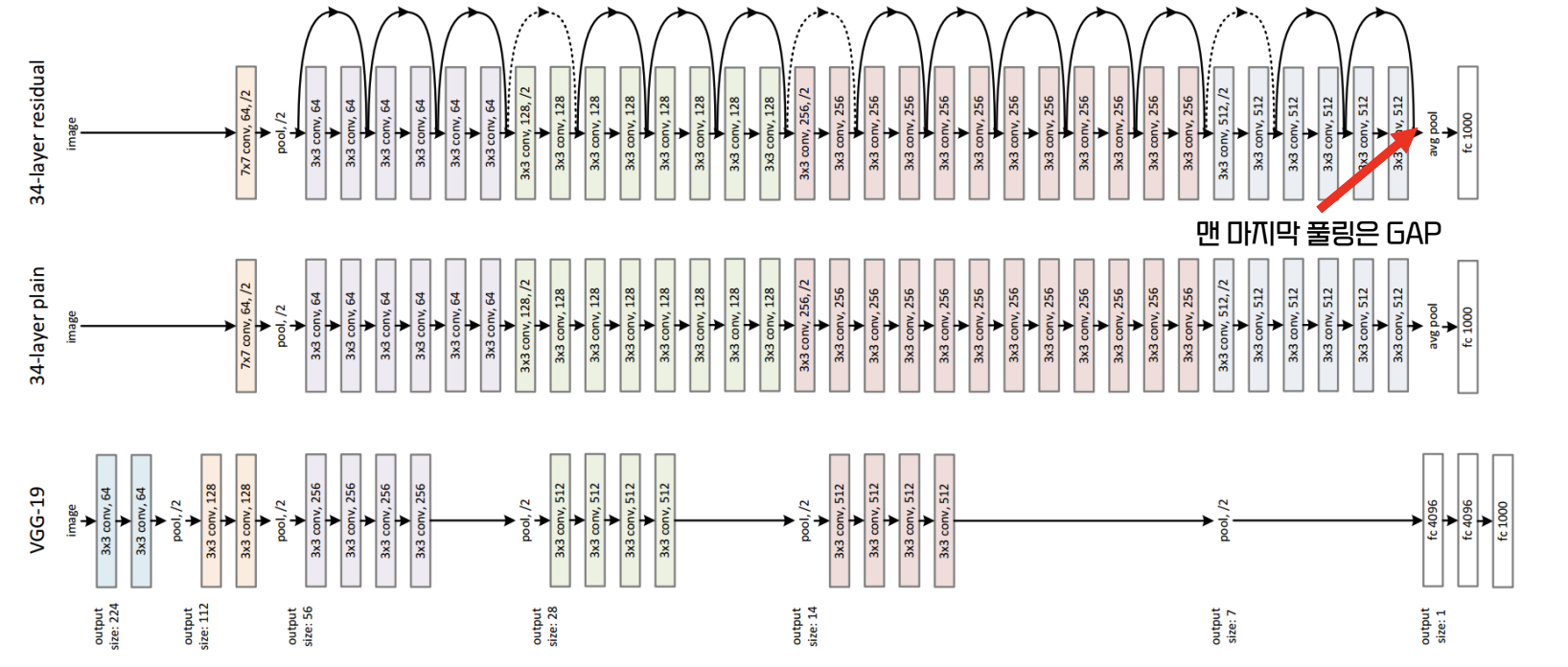
- 제일 처음과 끝의 pooling 을 제외하고는 size 축소 시 pooling 대신 stride 를 2로 설정
- 맨 마지막 pooling 은 GAP 이용
- 같은 크기의 Convolution을 수행하는 단위를 Residual Block 이라고 한다
Shortcuts
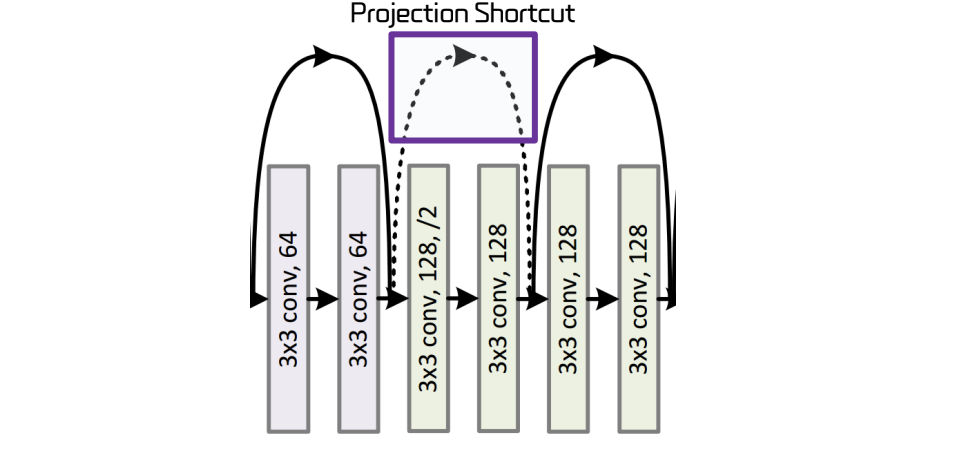
- skip connection 은 shortcut 이라고도 한다.
- shortcut 의 종류에는 두 가지가 있다.
1. Identity Shortcut - 위 그림의 실선에 해당
- 입력값을 별도의 변환 없이 그대로 다음 레이어로 전달하는 방법
- 입력과 출력의 차원이 같은 경우, 를 통해 그대로 더해준다
2. Projection Shortcut
- 위 그림의 점선에 해당
- 입력값과 출력값의 차원이 다를 때, 입력값을 변환해 차원을 맞춰주는 방법
- 단순히 더할 수 없기 때문에 입력에 1x1 conv 를 적용해 차원을 맞춘다
- ( 는 1x1 conv filter)
Residual Learning
- skip connection 을 통해 레이어가 학습해야 할 양을 줄인다
- 깊은 신경망에서의 기울기 소실 해결

인하대학교 컴퓨터공학과