Overview
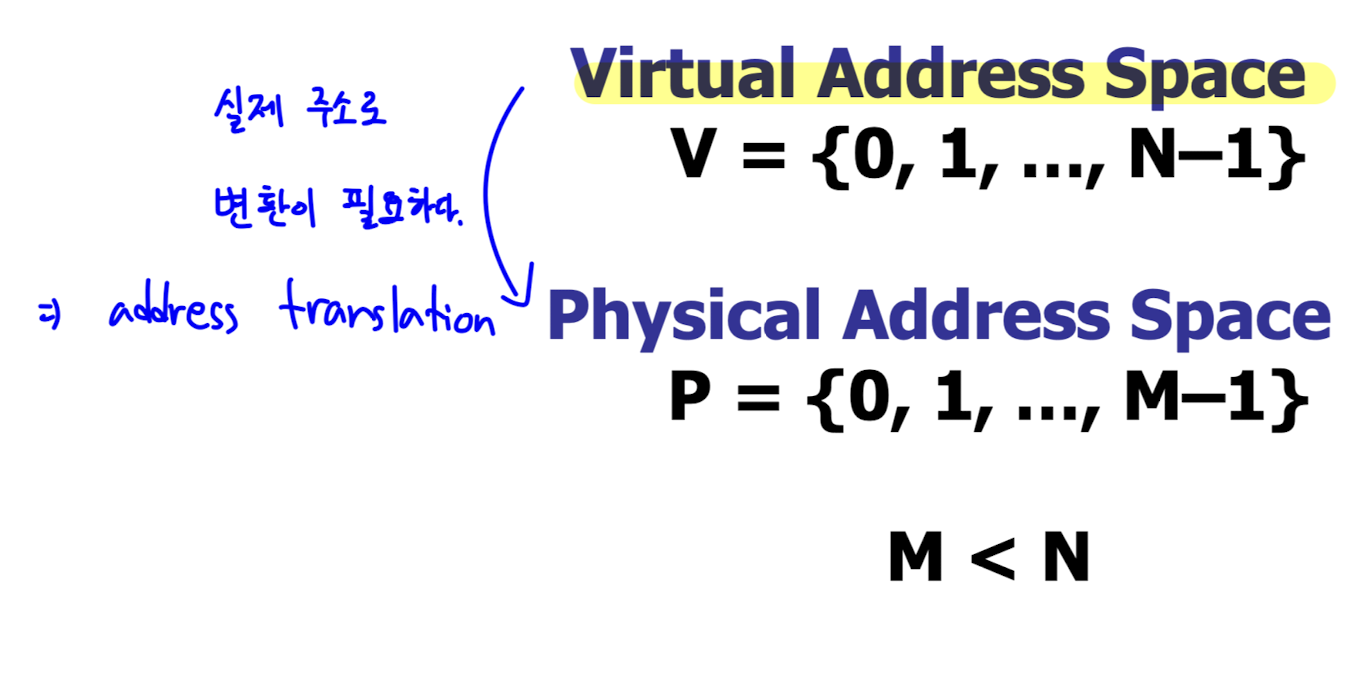
- virtual address space 를 이용하면 프로세스의 실제 address space 가 physical memory size 를 초과해 사용할 수 있다.
- virtual address 를 실제 주소로 변환하는 과정을 address translation 이라고 한다.
- address translation 은 mapping table 을 이용하는 것이 일반적이다.
- 이후에는 각 프로세스가 자신의 메모리 영역만 접근할 수 있도록 보장하는, memory protection 이 필요하다.
- 전반적으로 알아가야 할 내용은 다음과 같다.
- memory management strategy 에는 세 가지가 있다.
=> contiguous memory allocation
=> paging
=> segmentation - 각 방식에서 address translation 및 memory protection 이 어떤 과정으로 일어나는가?
Basic Hardware
MMU
- address translation 과 memory protection 을 돕는 하드웨어의 총칭이다.
- MMU 에는 크게 두 종류가 있으며, 메모리 관리 기법에 따라 이용 양상이 다르다.
- register : 필요한 값들을 저장하고, 빠르게 접근해 사용한다. 값 update 는 kernel 을 통해 이뤄진다.
- TLB (Translation Lookaside Buffer) : 작고 빠른 메모리 공간으로, page table 의 일부를 저장한다.
- MMU 를 이용한 mapping method 에는 여러 가지가 있다. 이 중 simple method 에 대해 살펴보자.
Simple Method
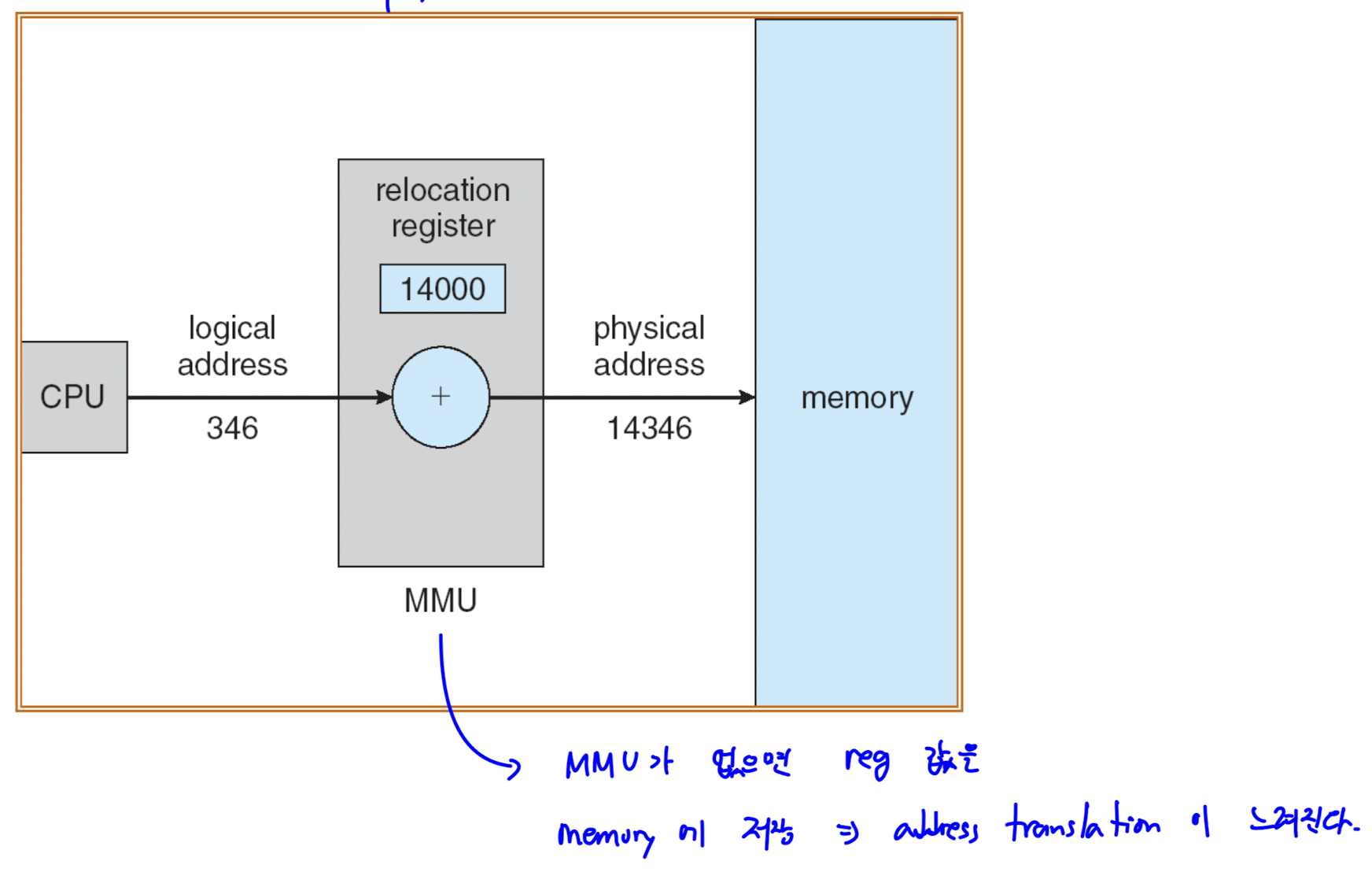
- contiguous allocation 에서 이용하는 방식이다.
- relocation register 에 시작 주소를 저장한다.
- logical address 에 relocation register 의 값을 더해 physical address 를 구한다.
- MMU 가 없다면, reg 값을 memory 에 저장해야 하고, 이는 address translation 을 느리게 만든다.
Address Binding
- 프로그램을 memory 와 disk 사이에서 allocation 시킬 때 들어갈 주소를 결정하는 과정이다.
- 이는 세 단계로 나눠진다.
- symbolic address : 소스 코드 상의 주소
- relocatable address : 시작점으로부터 얼마나 떨어졌는지 나타내는 주소, compiler 에 의해 결정
- absolute address : 숫자 형태로 된 절대 주소
- address binding 은 absolute address 가 결정되는 시점에 따라 분류된다.
- compile time : starting location 이 바뀌면 recompilation 이 필요한 단점 존재
- load time : swapping 시 주소가 달라질 수 있어 relocatable code 가 필요한 단점 존재
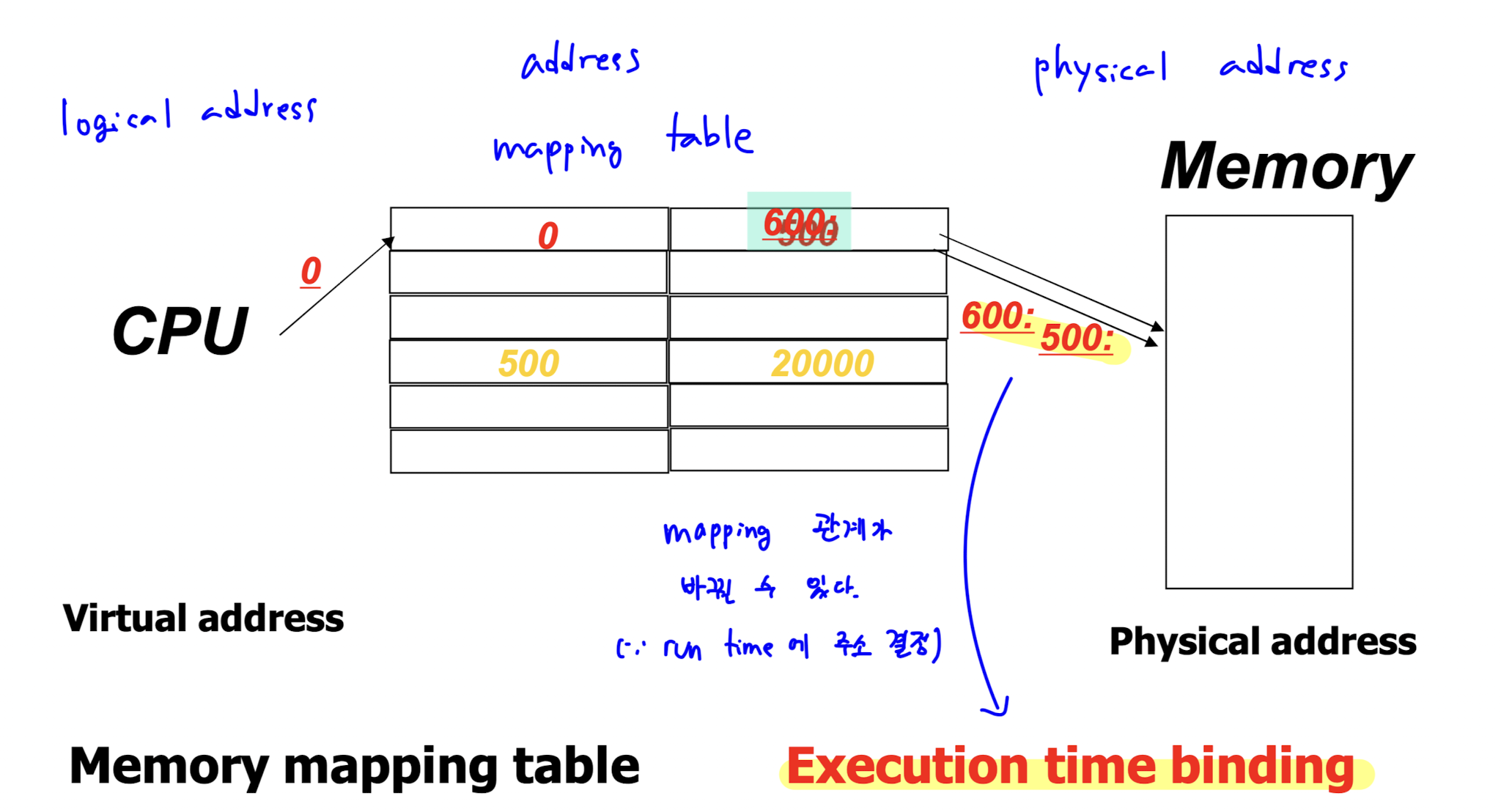
- execution time : 프로세스 실행 시 마다 absolute address 가 달라질 수 있기 때문에, 현대 OS 는 execution time binding 을 사용한다. 이를 위해 address mapping table 과 MMU 가 필요하다.
Process Address Space
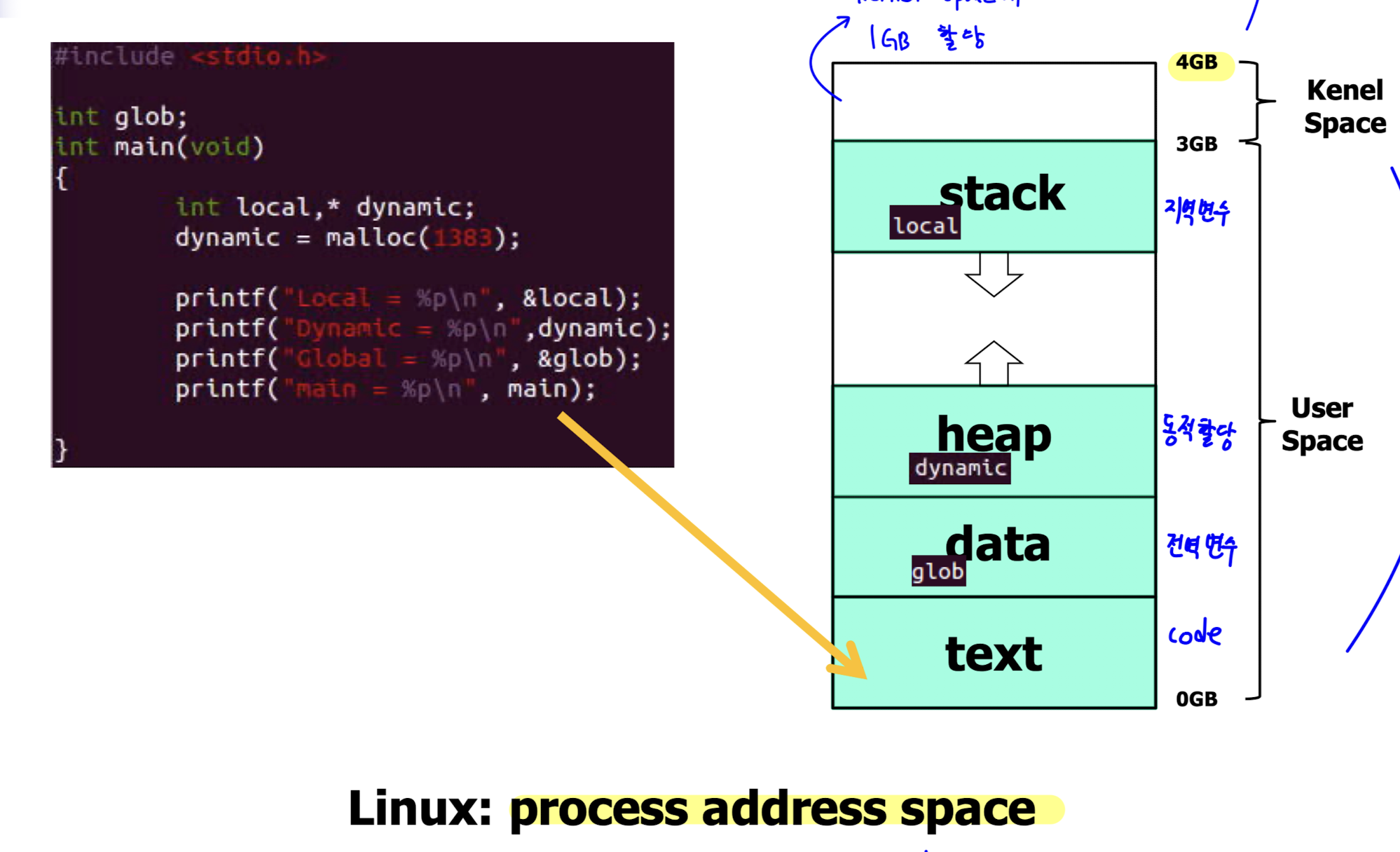
- process address space 는 프로세스가 보는 공간이기 때문에, virtual memory 이다.
=> 즉, 이를 다루기 위해서는 address translation 이 필요하다. - 32bit 주소체계에서는 최대로 표현할 수 있는 주소는 4GB 이다. (2^30 * 2^2)
- 이 중, kernel space 에 1GB 를, 프로세스에 3GB 를 할당한다.
Dynamic Loading, Linking, Shared Library
1. Dynamic Loading
- routine 의 호출 시점까지 loading 과정을 미룬다는 의미다.
- 사용되지 않는 routine 에 대한 loading 은 일어나지 않기에, 메모리 사용이 더 효율적이다.
- 이는 OS 의 도움 없이 library 에 의해 제공된다.
2. Dynamic Linking
- 실행 시점까지 linking 을 미루는 것이다.
- linking 정보를 담은 코드 조각들을 stub 라고 한다. 이는 execution time 에 library 주소로 대체되고, library 속 해당 주소의 routine 이 실행된다.
- 이는 shared library 이용 시 효과적이다. 이유는 다음과 같다
- 메모리의 효과적 사용
=> dynamic linking 을 사용하면 여러 프로그램이 동일한 라이브러리의 단일 복사본을 메모리에서 공유할 수 있다. 이는 각 프로그램이 라이브러리의 복사본을 메모리에 따로 유지할 필요가 없다는 것을 의미하므로, 메모리 사용량이 크게 줄어든다. - 자동적인 memory update
=> library update 마다 linking 을 다시 해줄 필요가 없다. - Lazy Loading
=> 프로그램이 시작될 때 모든 것을 로드하는 대신, 실제로 필요할 때까지 라이브러리의 로딩을 지연시킬 수 있다. 이는 프로그램의 시작 시간을 단축시키고, 필요하지 않은 코드는 메모리에 로드되지 않도록 할 수 있다.
3. Shared Library
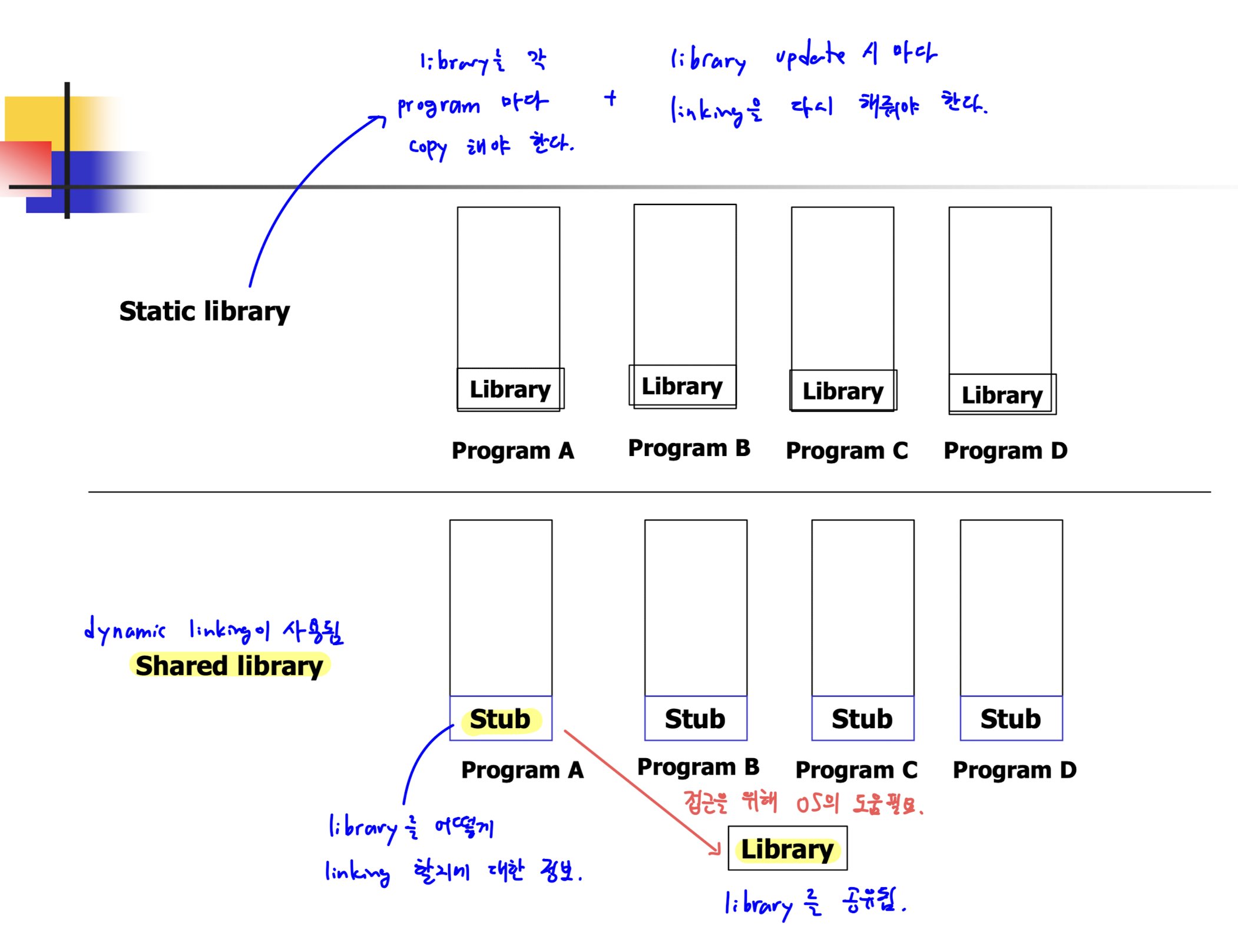
- run time 에 임의의 주소에 로드되는 개체로, 메모리 속 프로그램과 link 될 수 있다.
- 각 프로세스는 자신의 공간이 아닌 외부의 공간인 shared library 에 접근하기 때문에, kernel 의 도움이 필요하다.
Swapping
- main memory 에 적재되지 않은 데이터를 저장하기 위한 디스크 공간을 backing store 라 한다.
- swapping 은 main memory 와 backing store 사이에서 프로세스를 올리고 내리는 과정을 말한다.
- 요청한 프로세스가 메모리 상에 없으면, 해당 프로세스를 swap in 한다.
- swap in 을 해야 하는데 memory 가 꽉 찼다면, swap out 한다.
- main memory 와 backing store 에 접근하는 시간은 차이가 많이 난다.
=> memory 에 접근하는 것이 효율적
Contiguous Allocation
- 연속적인 주소에 프로세스를 저장하는 방식이다.
- 연속된 주소를 사용하기 때문에 프로세스에 접근하기 위해서 base address 와 offset 을 알면 된다.
- 주소 접근과 관리가 쉽다.
- 이를 위해 두 개의 MMU 가 사용된다.
- relocation register : base address 저장
- limit register : logical address 의 범위 (프로세스의 크기) 를 저장
- address translation 은 relocation register 의 base 값에 offset 을 더하는 것이다.
- memory protection 은 limit register 의 값보다 offset 이 큰지 판별하는 것이다.
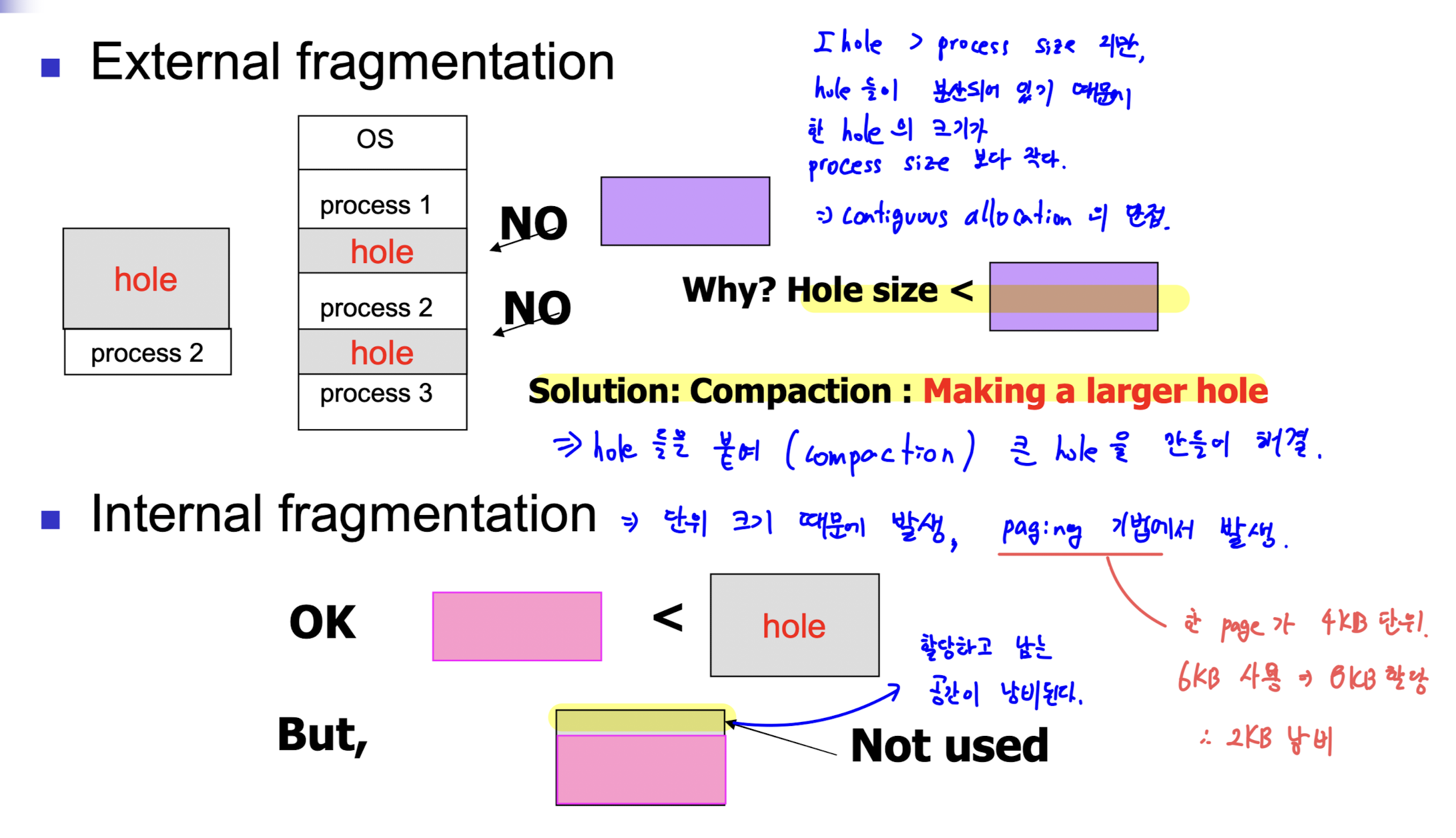
=> 한 프로세스의 크기보다 큰 offset 은 허용되지 않는다. - 연속된 주소를 사용해야 하기 때문에, 할당해야 하는 프로세스들을 담을 연속된 공간이 없으면 공간 여유가 있음에도 프로세스를 할당하지 못하는 문제가 생긴다. (빈 공간이 연속적이지 않아 발생)
=> 이를 external fragmentation 이라고 한다.
Multiple Partition Allocation
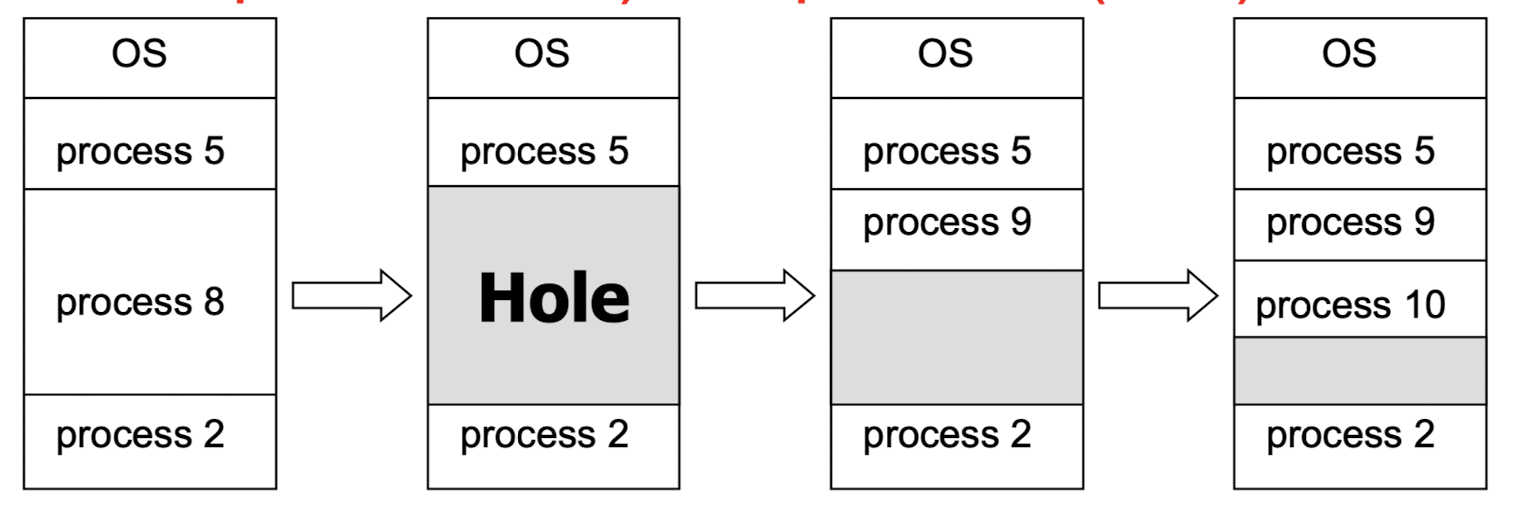
- contiguous allocation 의 한 형태로, 메모리 공간을 여러 개의 partition 으로 나누어 할당한다.
- 각 partition 은 연속된 주소 공간이기 때문에, contiguous allocation 의 형태인 것이다.
- 비어있는 partition 을 hole 이라고도 하며, hole 에 프로세스를 할당하는 방법은 세 가지가 있다.
- first fit : 크기가 충분한 hole 중 가장 먼저 만나는 것에 할당
- best fit : 크기가 충분한 hole 중 가장 크기가 작은, 딱 맞는 것에 할당
- worst fit : 가장 크기가 큰 hole 에 할당
=> 속도와 공간 효율 측면에서 first / best fit 이 좋다.
- 이를 통해 external fragmentation 을 줄일 수 있다.
- 하지만, 항상 hole 의 크기에 딱 맞는 프로세스를 할당할 수는 없기에, hole 내부에서 발생하는 internal fragmentation 이 발생할 수 있다. (할당 기본 단위 크기가 정해져 있어서 발생)
Paging
- contiguous allocation 과 달리, 프로세스를 연속되지 않은 주소에 저장한다.
- physical memory 는 frame 으로, logical memory 는 page 로 분할해 할당한다.
- page 의 기본 크기는 4KB 이고, 이것이 할당의 단위 크기이다.
=> 6KB 프로세스에는 두 개의 page 즉 8KB 가 할당된다. - frame 과 page 의 크기는 같고, address translation 에는 page table 이 이용된다.

- logical memory 의 6KB 주소를 translate 하는 과정을 살펴보자.
- 6KB 주소는 logical memory 의 page 1 의 offset 2KB 에 존재한다. (4KB * 1 + 2KB = 6KB)
- 해당 page number 를 page table 에서 lookup 한다. page 1 에 해당하는 frame number 는 4 다.
- page 와 frame 의 크기는 같기 때문에, page 와 frame 에서의 offset 은 동일하다.
- 그러므로, physical memory 상에서는 18KB (4KB * 4 + 2KB) 에 mapping 된다.
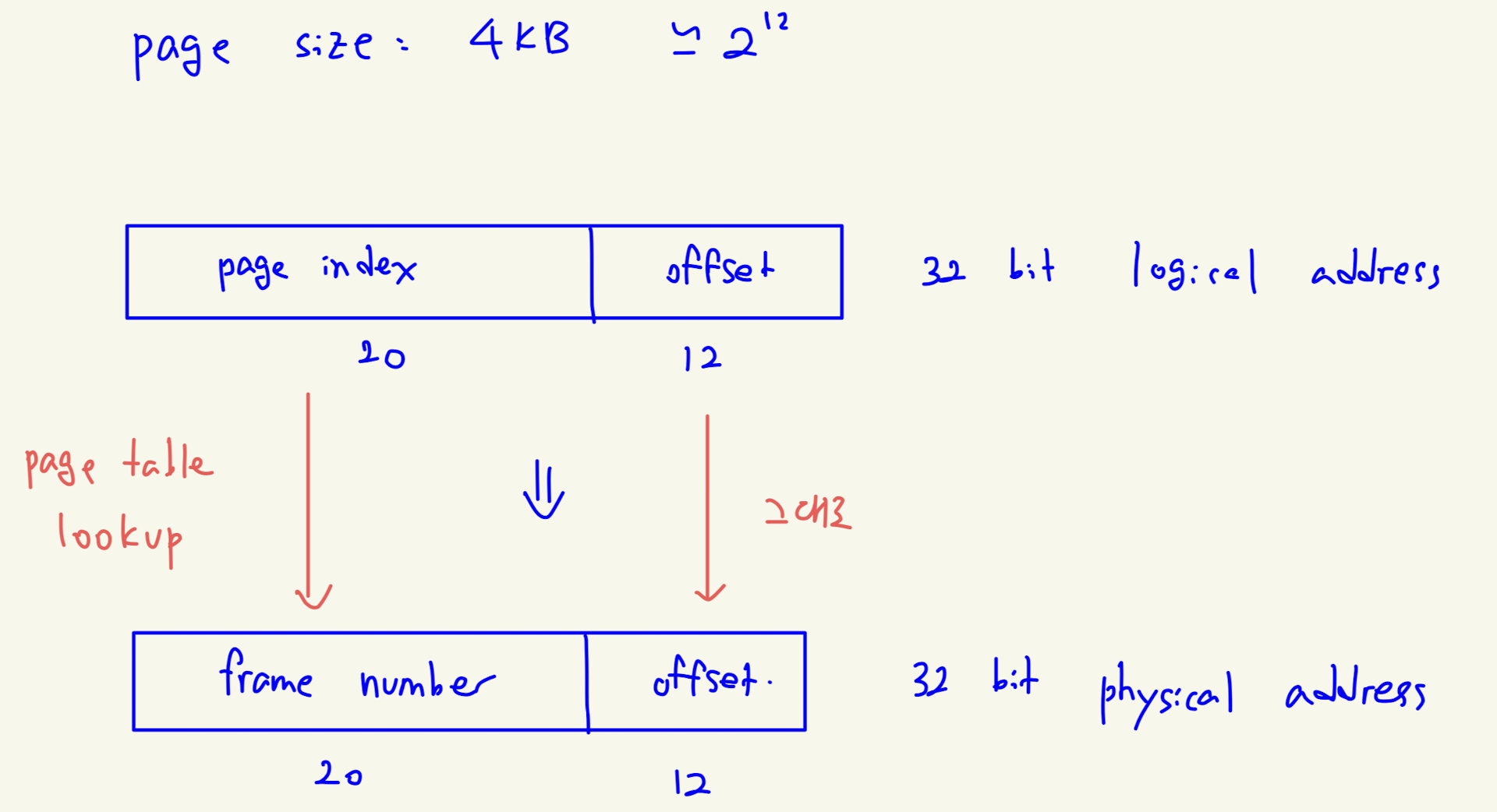
- 위와 같이, logical address 를 page size 로 나눈 몫은 page number, 나머지는 offset 이 된다.
- 이를 이진수로 표현하면 다음과 같다.

- page size 가 4KB 이면, 2^12 이므로, 주소의 하위 12 bit 가 offset 이 된다.
- 변환 과정을 그림으로 정리하면 다음과 같다.
- paging 은 연속적인 주소를 사용하지 않기 때문에, external fragmentation 은 일어나지 않는다.
- 하지만, 할당의 최소 단위가 page size 로 정해져 있기 때문에, internal fragmentation 은 일어난다.
- internal fragmentation 을 줄이려면 page size 를 줄이면 된다. 하지만, 이 방법은 page 갯수를 증가시켜 page table 의 크기를 키운다.
=> page table 은 프로세스마다 존재하기 때문에, 크기가 커지면 관리에 overhead 가 커진다.
Frame Table
1. Free Frame List
- 비어있는 frame 들의 정보를 담은 표를 free-frame list 라고 한다.
- 새로운 프로세스가 실행되면, free frame list 에서 비어있는 frame 을 lookup 해 할당한다.
- 이후에는 새로운 mapping 정보로 page table 을 update 한다.
2. Frame Table
- frame 의 총 갯수와 할당 여부를 담은 표를 frame table 이라고 한다.
- 프로세스는 각각의 virtual address space 를 가지고, physical address 에 mapping 되는 정보가 다 다르기 때문에, 프로세스는 각자의 page table 을 가진다.
- 그러므로 프로세스는 각자의 PCB 에 frame table 의 사본을 저장한다.
Hardware Support
- paging 에서는 세 가지 MMU 가 사용된다.
- PTBR (Page Table Base Register) : 메모리 상의 page table 의 위치 표시
- PTLR (Page Table Length Register) : page table 의 크기 (process size) 를 나타냄
=> page table lookup / 실제 data 접근으로 총 두 번의 memory access 가 필요하다. 이를 줄이기 위해 TLB 가 사용된다. - TLB : page table 의 일부가 저장되는 cache 의 일종이다. 찾고자 하는 page index 가 TLB 에 있으면 메모리 접근이 필요 없어 overhead 가 줄어든다. 그러므로 TLB 의 hit rate 을 높이는 것이 중요하다. associative memory 라고도 불린다.
=> PID 정보가 추가된 TLB 를 ASID (address space identifier) 라고 한다. PID 를 통해 프로세스를 구분할 수 있어 여러 프로세스의 정보를 담을 수 있다. 이로 인해 context switch 시 page table 을 flush 하는 overhead 를 줄일 수 있다.
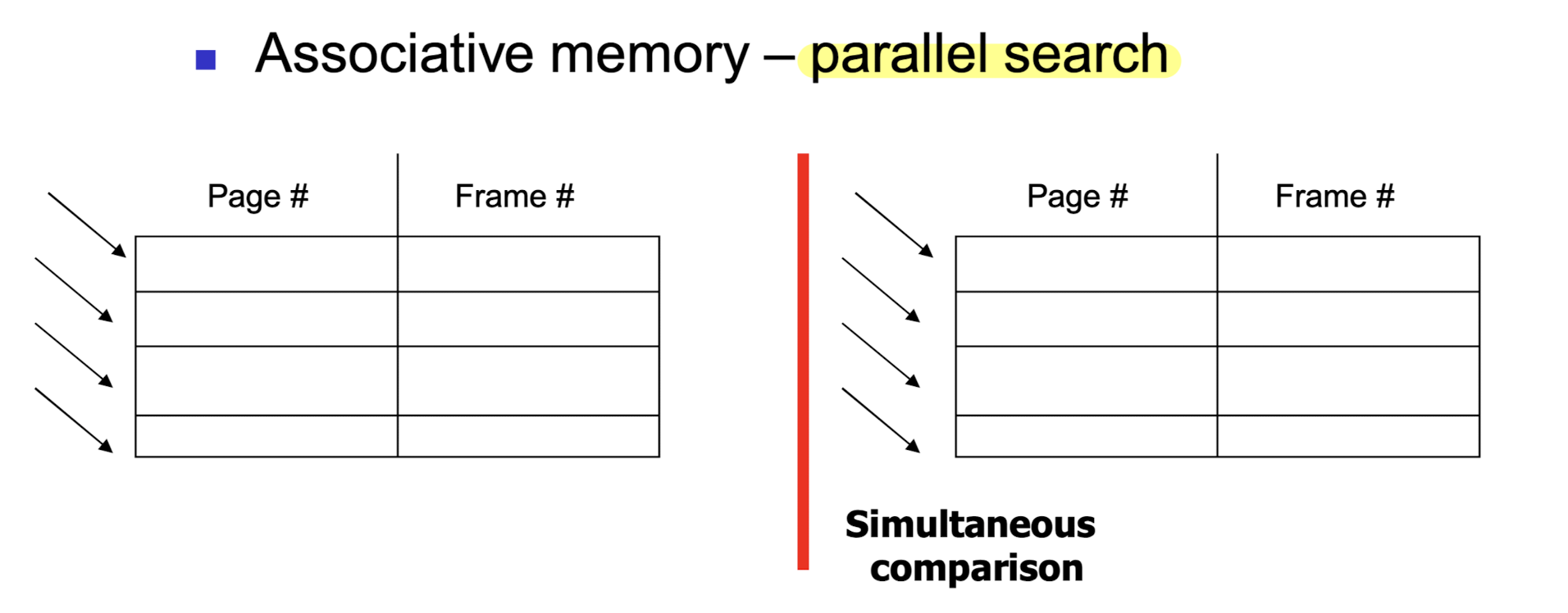
- TLB 에 simultaneous search 가 적용되면 보다 더 빠른 탐색을 할 수 있다.
- simultaneous search 는 TLB 내 여러 개의 entry 를 한꺼번에 탐색하는 기술이다.
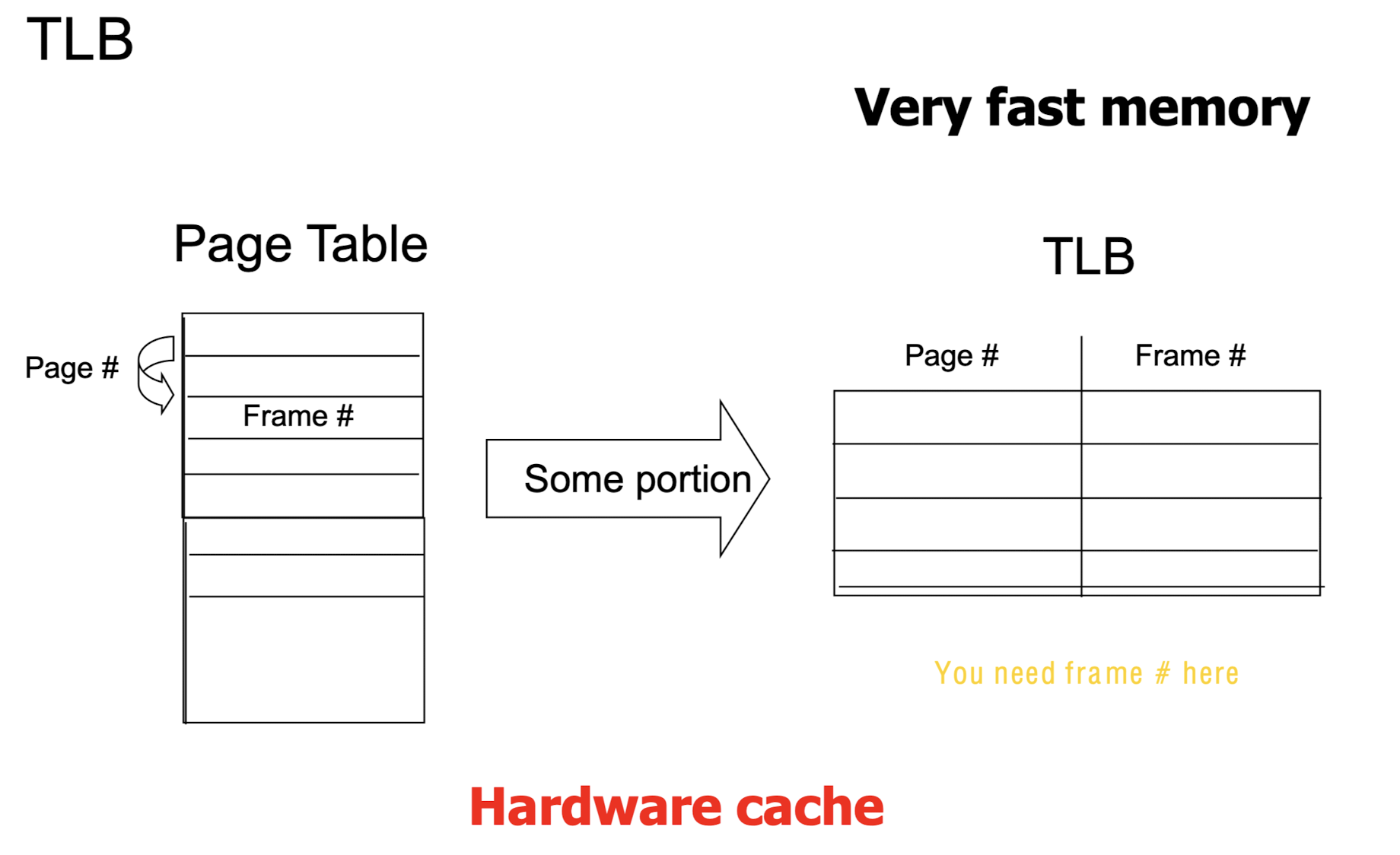
- 정리하자면, TLB 는 page table 의 일부를 담은 cache 의 일종이며, 메모리 접근이 필요 없어 속도가 빠르기 때문에 자주 사용하는 page 를 TLB 에 넣어 hit rate 을 높이는 것이 중요하다.
- TLB 의 hit rate 을 높였을 때의 효과를 살펴보자.

- memory lookup 은 1 microsecond, TLB lookup 은 e time unit 이 걸린다고 가정하자.
- TLB 에 찾던 entry 가 있을 확률인 hit ratio 는 a 이다.
- TLB 를 동원했을 때의 lookup time 기댓값인 EAT (Effective Access Time) 은 다음과 같다.
- 탐색 성공의 경우 : (1 + e) * a => memory access 한 번, TLB lookup 한 번, 성공 확률 a
- 탐색 실패의 경우 : (2 + e) * (1 - a) => memory access 한 번 추가, 실패 확률 (1 - a)
- hit ratio 가 0.8 에서 0.98 로 증가했을 때, EAT 가 감소하는 것을 알 수 있다.
Memory Protection of Paging
- 각 주소가 유효한지 판별하기 위해 page table 의 entry 에 valid-invalid bit 이 추가된다.
- memory protection 을 위해 page table 을 lookup 해 valid-invalid bit 을 살펴본다.
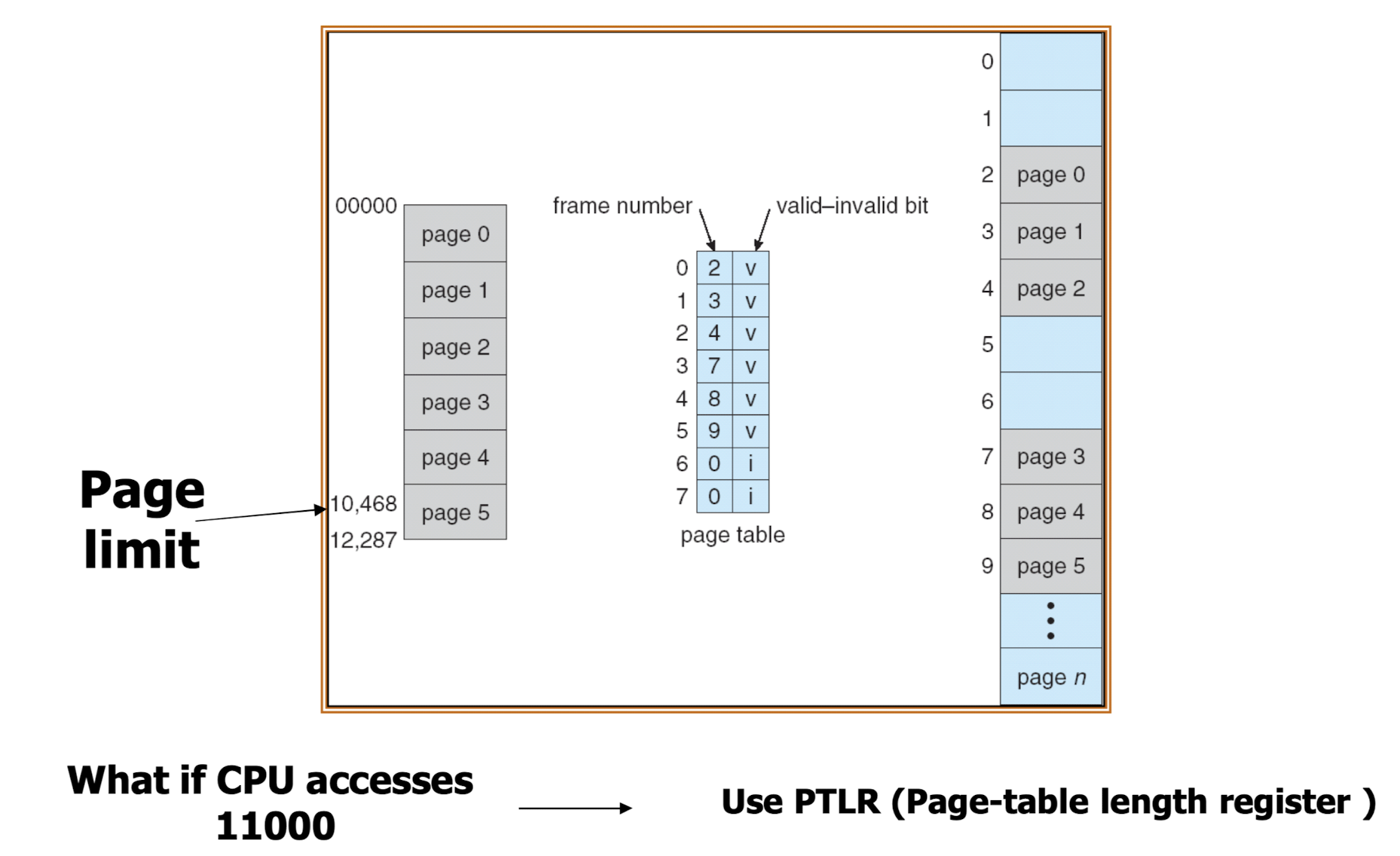
- 주소가 유효한지 판별은 PTLR 값을 이용한다. PTLR 값을 넘어선 주소를 가지는 page 는 invalid 하다.
- 위 그림에서는 page 5 까지가 PTLR 의 값에 들어간다.
=> page 6 과 7 은 invalid 이므로 valid-invalid bit 이 0으로 설정된다.
Shared Code
- 여러 프로세스가 공통으로 사용하는 코드를 의미한다. 이는 physical memory 상에는 한 공간에 위치하고, 여러 곳의 logical memory 에 mapping 될 수 있다.
- 이를 통해 여러 프로세스가 코드를 공통으로 사용할 수 있다.
- 이는 각 프로세스는 각자의 logical address space 를 가지기 때문에 가능한 것이다.
Structure of the Page Table
- 32 bit 주소에서는 최대 4GB 의 주소를 표현할 수 있다. (2^32 = 2^30 * 4)
- page size 가 4KB (2^12) 라고 가정하면, 주소의 하위 12 비트가 offset 표현에 쓰인다.
=> 상위 20 비트가 page number 표현에 사용되어, page table 에는 2^20 개의 entry 가 들어간다. - 각 entry 가 4 비트라면, page table size 는 4MB (4 * 2^20 entries) 가 된다.
- page table 은 각 프로세스마다 따로 가지기 때문에, page table size 를 줄이는 것이 중요하다.
- page table 의 구조에는 여러가지가 있고, 각자 page table size 를 줄이는 방법을 가진다.
Hirerachical Paging
- logical address space 를 여러 개의 page table 로 나누는 방법이다.
- 예시로, two level page table 을 살펴보자.
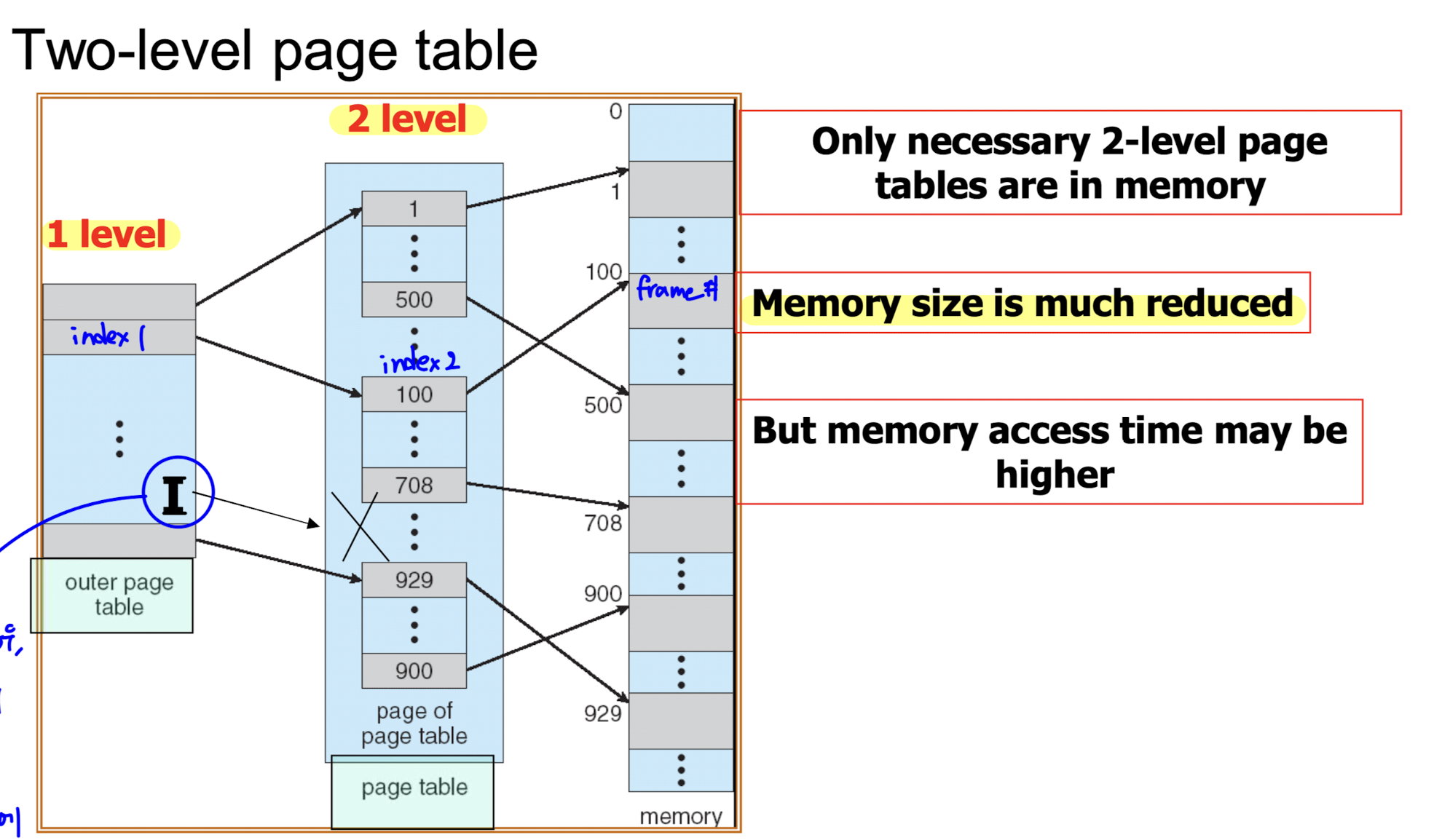
- logical address space 가 두 개의 page table 로 분리 되었다.
- 1 level page table 은 2 level page table 의 시작 주소를 가리킨다.
- 2 level page table 은 실제 frame number 를 담는다.
- 1 level page table 에서 주소가 valid 한지 검증해, invalid 한 경우 2 level 에 저장하지 않는다.
=> 이로 인해 page table size 가 크게 줄어든다. - 단점으로는 여러 개의 page table 을 lookup 해야 해서 memory access time 이 길어질 수 있다.
- 주소 표현이 (page number / offset) 에서 (index 1 / index 2 / offset) 으로 바뀐다.
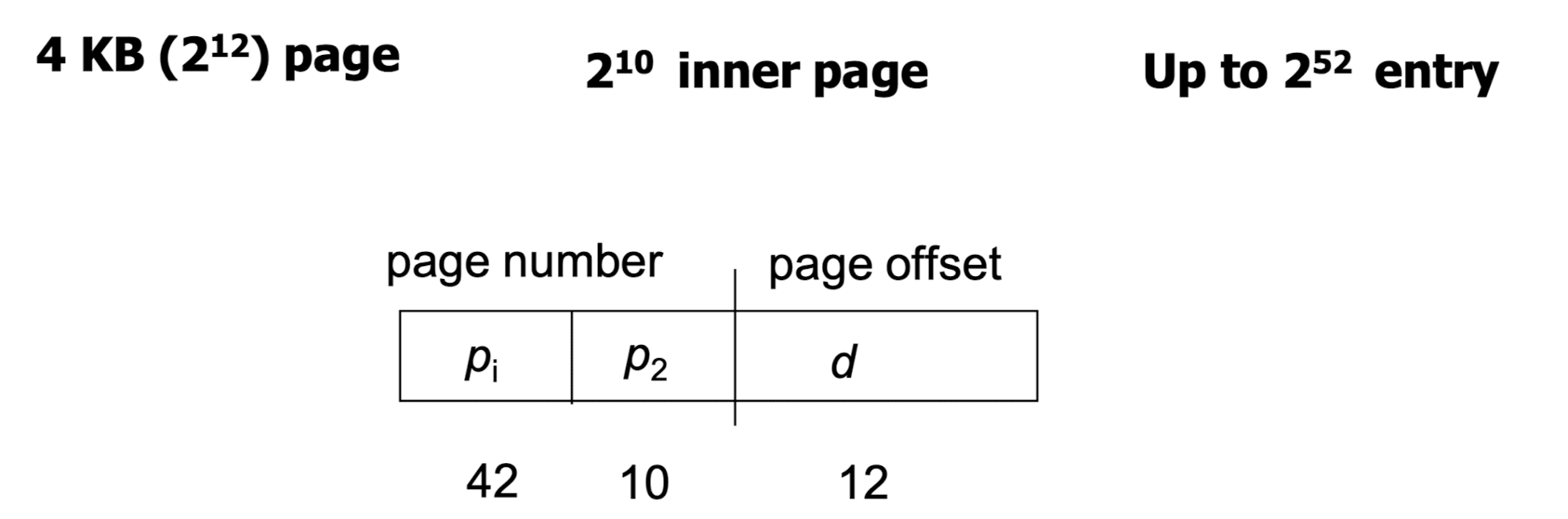
- 위 그림은 2^52 개의 entry 와 2^10 개의 inner page 가 있는 경우의 주소 표현이다.
- two level page table 을 사용했음에도 1 level page table 의 크기가 너무 크다.
=> three level page table 을 사용한다.

- 1 level page table 의 크기가 줄어든 것을 볼 수 있다.
Hashed Page Table
- page table 의 크기를 줄이기 위해 hashing 기법을 사용한 방법이다.
- page table 대신 hash function 과 hash table 을 이용한다.
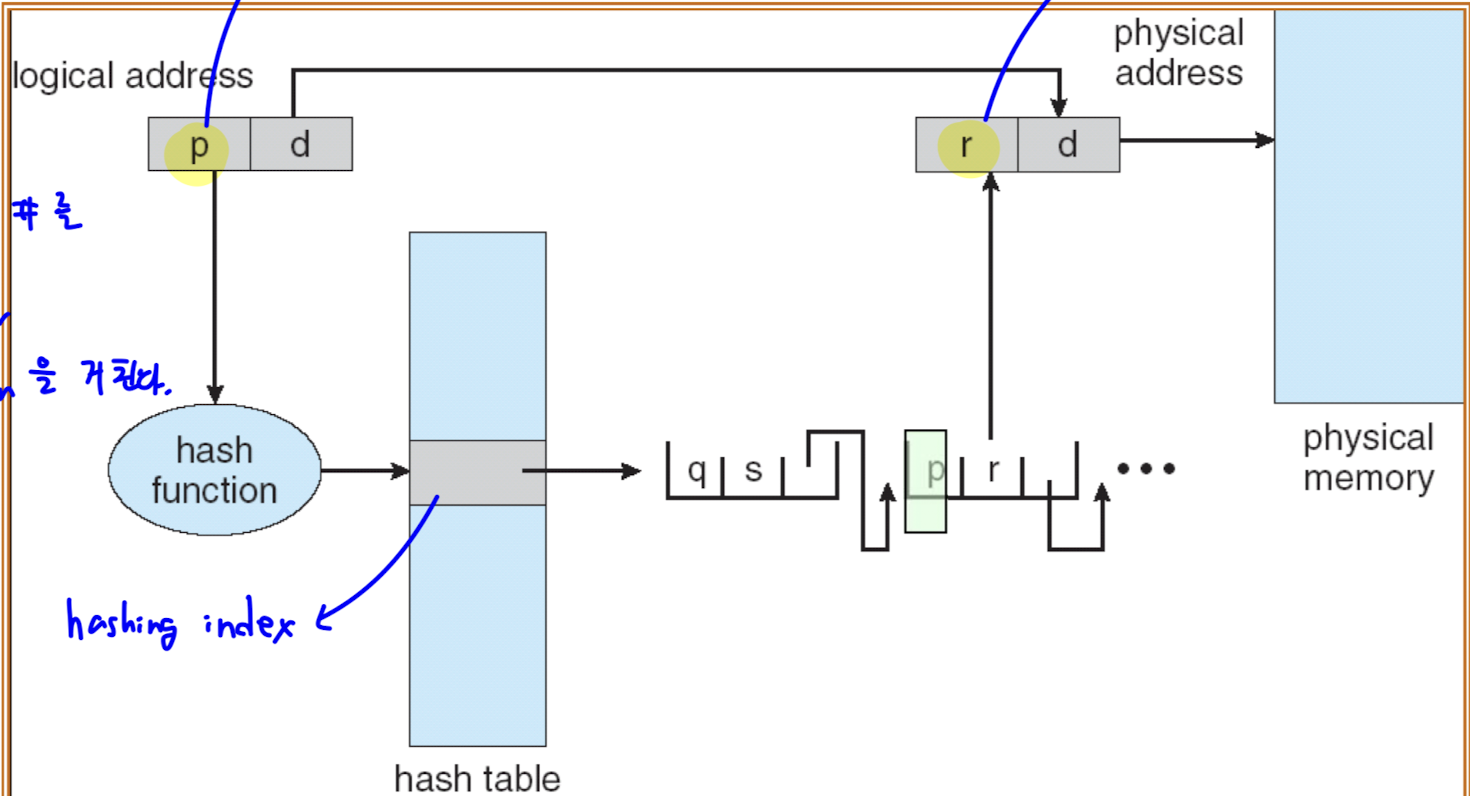
- logical address 를 page number 와 offset 으로 분할하는 과정은 동일하다.
- page number 이 바로 frame number 를 가리키지 않고, hash function 의 input 으로 사용된다.
- hash function 의 output 이 hash table 의 index 로 사용된다.
- hash table 의 collision 방지를 위해, chain 형태의 data structure 를 이용한다.
- 처음에 input 으로 사용된 page number 와 일치하는 p 값의 chain 의 r 값을 frame number 이다.
- 위 과정에서 얻은 frame number 에 맨 처음의 offset 을 더해 address translation 이 일어난다.
Inverted Page Tables
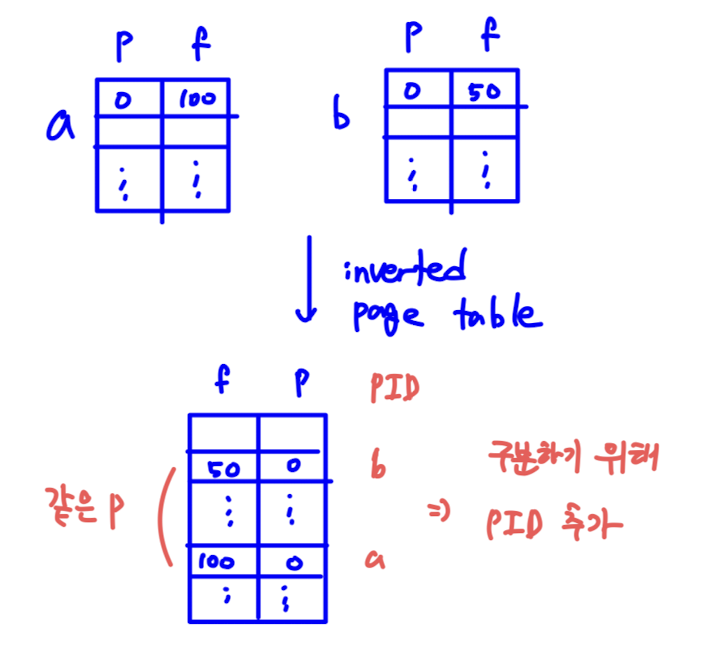
- frame number 와 page number 의 위치를 바꾼 (invert) 한 table 이다.
- frame 은 시스템 내에 유일하게 존재하기 때문에,
=> entry 가 memory size 만큼만 존재한다.
=> inverted page table 은 프로세스마다 있는 것이 아닌, OS 내에 global 하고 유일하게 존재한다. - 앞에서 언급했듯이, 하나의 frame 은 여러 개의 logical address 에 할당될 수 있다.
- 그렇기에, 같은 page number 를 가지는 서로 다른 entry 들을 구별하기 위해, PID 도 명시해준다.
- 단점으로는 원하는 frame number 를 찾기 위해 page table 을 순차적으로 탐색해야 한다는 것이다.
Page Tables in LINUX

- 위 그림과 같이 LINUX 는 3 level page table 을 사용한다.
- page table 은 task_struct 타입의 PCB 에 담긴다.
- follow_page() 는 원하는 page number 를 찾는 함수다.
=> 3 level page table 을 이용하기 때문에 3번 호출된다.
Segmentation
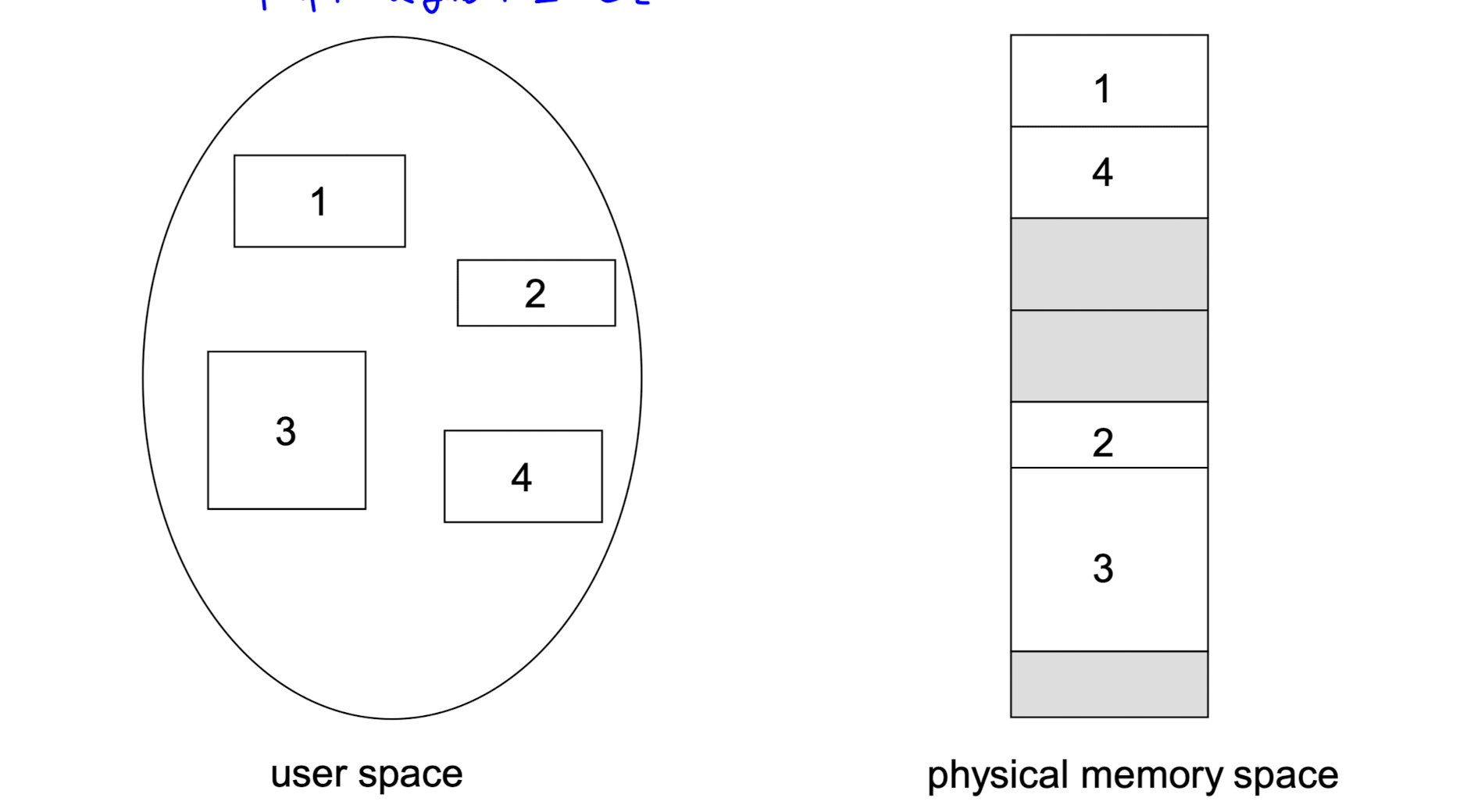
- contiguous allocation 과 유사한 memory allocation 방식이다.
- contiguous allocation 에서 연속적인 단위는 process 전체였다면, segmentation 에서는 segment 라는 단위다.
- segment 는 프로세스를 logical unit 으로 분할한 것이다.
=> logical unit 에는 함수, 객체, stack, array 등이 포함된다. - 그림은 4개의 segment 로 분할된 프로세스와 이들을 physical memory space 에 할당한 모습이다.
- contiguous allocation 과 달리, 프로세스 전체가 아닌 segment 끼리만 연속적인 주소에 저장된다.
1. Address Translation - segment 들이 연속된 주소에 저장되므로, 각 segment 의 시작 주소를 알면 된다.
- 시작 주소(base)와 segment 길이(limit)는 segment table 에 저장된다.
- 두 가지 MMU 가 사용된다.
- STBR (Segment Table Base Register) : 메모리 내 segment table 의 위치를 가리킨다.
- STLR (Segment Table Length Register) : 프로세스 내 segment 의 갯수를 명시한다.
2. Memory Protection
- segment table 을 lookup 해 limit 을 넘어가는 지 확인한다.
- segment number 이 STLR 보다 크면 illegal 한 것이다.
- segment table 에는 validation bit 와 segment 의 권한을 표시하는 열이 추가된다.
- illegal statement 의 validation bit 은 0 이다.

인하대학교 컴퓨터공학과