- virtual memory 공간의 관리에 대해 다룬다.
Demand Paging
- page 가 프로세스 수행에 필요해 access 돼야 하는 시점에 메모리 에 load 하는 것이다.
- demand 가 없으면 page 가 메모리에 load 되지 않는다.
=> 일부 page 는 memory 에 없을 수 있다. - demand paging 을 사용하는 pager 를 lazy swapper 라고 한다.
- paging 는 한 page 내에서의 swapping 을 의미하고, swapping 보다 보편적으로 쓰인다.
Valid and Invalid Bits
- 메모리에 있는 page 들을 분류하는 기준으로, 메모리 접근이 legal 한지 명시한다.
- legal 한 page 는 메모리 상에 있는 것이다.
- illegal 한 page 는 메모리 상에 없거나, 접근 자체가 illegal 한 경우다.
=> 두 경우는 internal table 을 이용해 구별한다.
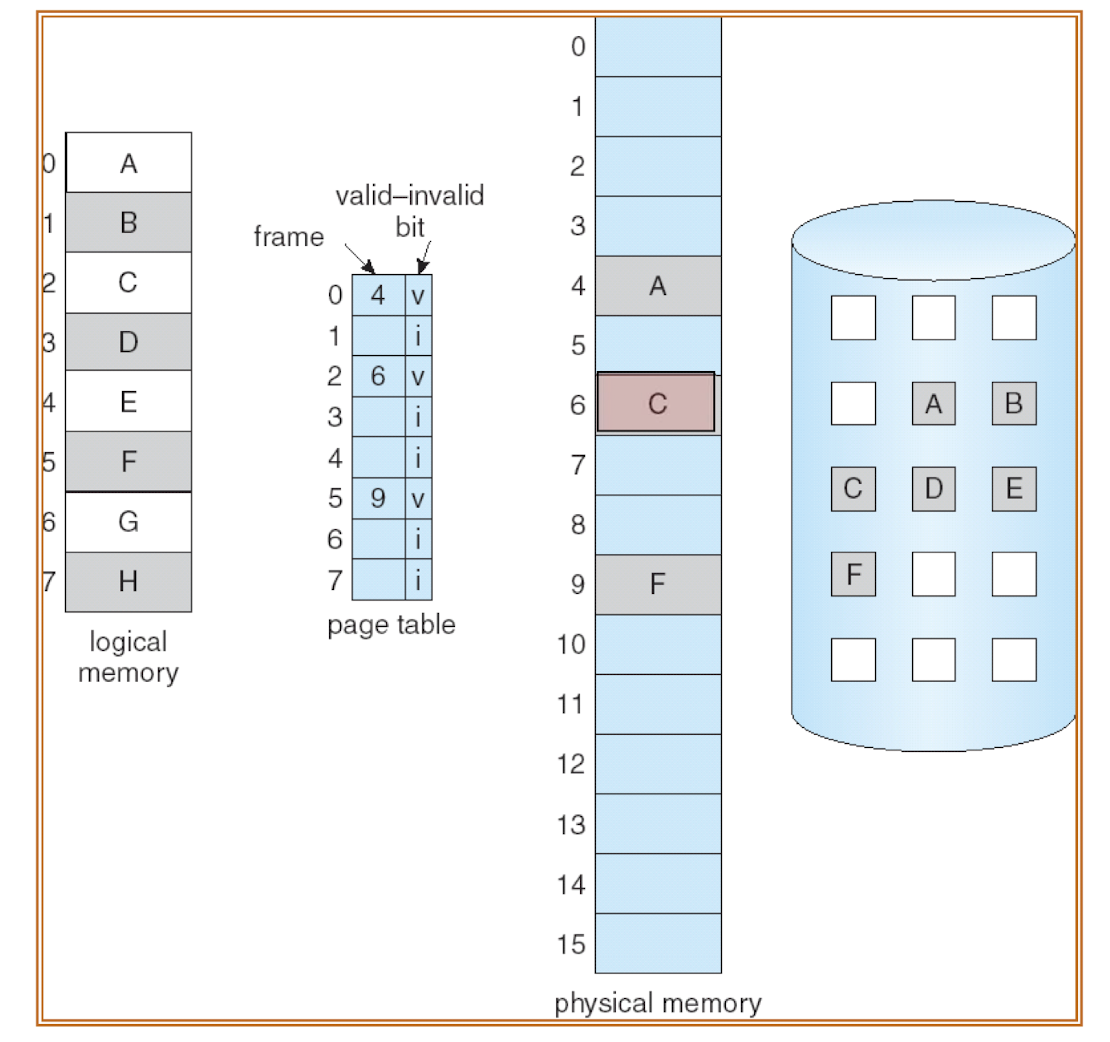
- page A, C, F 가 load 된 위의 상황을 살펴보자.
- page number 는 각각 0, 2, 5 이고, page table 의 해당 index 에 frame number 가 저장된다.
- 이들만 physical memory 에 저장되어 있으므로, valid bit 이 1 이 된다.
- 만약 B 가 요청되면, memory 에 없는 page 를 요청한 "page fault" 가 발생한다.
=> 이 경우 page 를 메모리에 load 해와야 한다. 이 과정을 page fault handling 이라고 한다.
Page Fault Trap
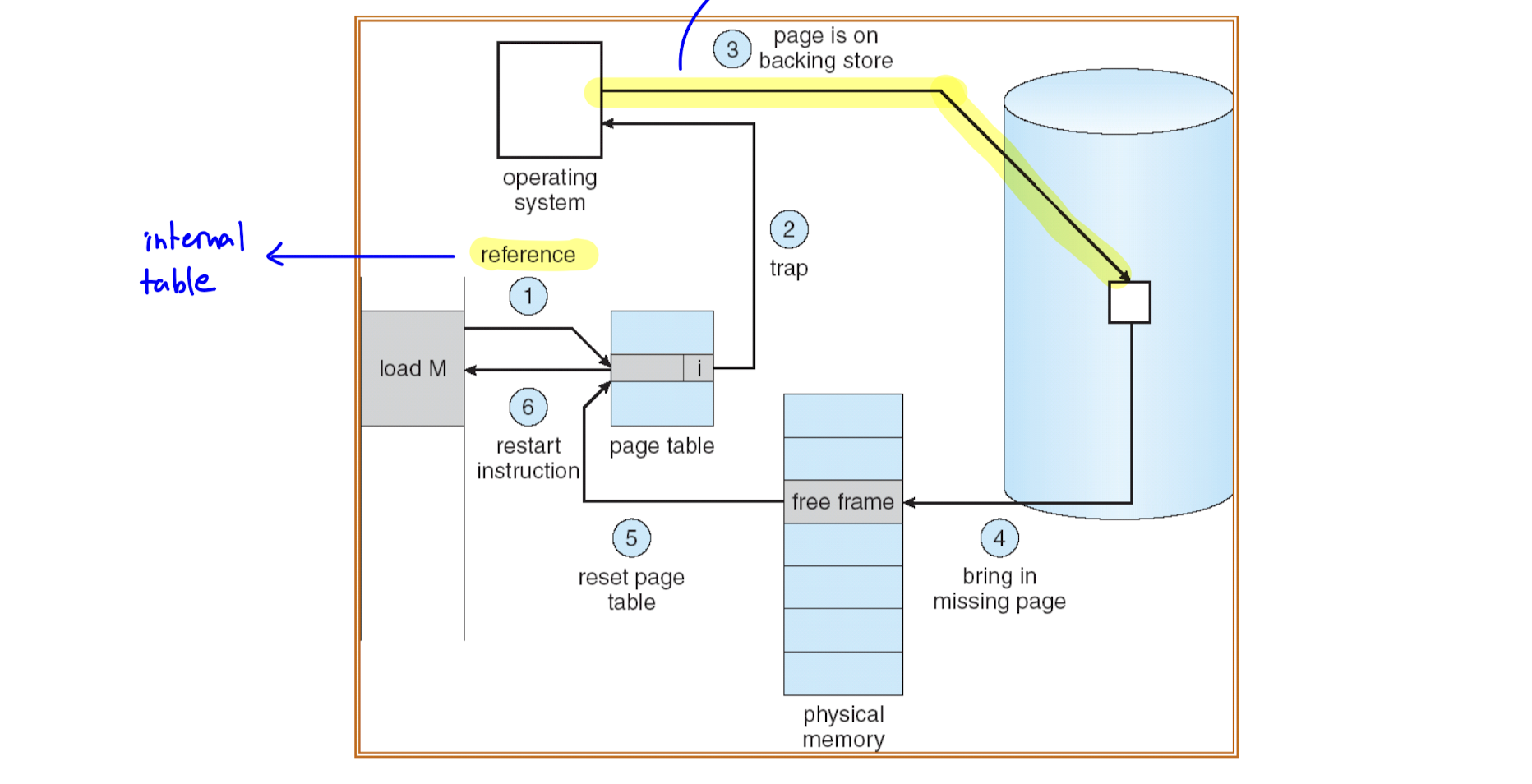
- page fault handling 은 trap 의 형태로 이루어지며, 6개의 단계가 있다.
- OS 가 PCB 내의 internal table 을 lookup 해 invalid reference 인지, 메모리에 없는 것인지 판별
=> invalid reference 인 경우 abort, 메모리에 없던 것이면 단계 진행 - 비어있는 frame 을 찾는다.
- page 를 해당 frame 에 swap in 한다.
=> 이는 disk 을 access 하는 disk I/O operation 이기 때문에 프로세스는 waiting state 가 된다. - table update
- 새로운 entry 의 validation bit 을 1 로 변경한다.
- page fault 를 일으켰던 instruction 을 재실행한다.
Pure Paging
- page fault 가 발생하면 disk access 가 필요하기 때문에 page fault 를 줄이는 것이 중요하다.
- demand paging 을 이용하면, page 가 필요한 시점에 load 하기 때문에 처음에는 load 된 page 가 없어 몇 번의 page fault 는 불가피하다.
- page fault 가 불가피함에도 memory access 에는 locality of reference 가 존재해 page fault 의 수가 많지 않아 합리적인 성능을 기대할 수 있다.
- locality 에는 두 가지 종류가 있다.
- spatial locailty : 특정 page 부분만 접근하는 패턴이 존재.
- temporal locality : 시간적으로 근접한 기간에 접근하는 page 들은 일정하다.
Performance of Demand Paging
- reference 중 page fault 가 발생하는 빈도를 page fault rate (p) 라고 하자.
- EAT (Effective Access Time) 은 다음과 같다.

- fault 가 없으면 memory access time 이 필요하고, fault 가 발생하면 page fault handling 의 overhead 가 추가로 발생한다.
- memory access time 은 200 nanosecond, page fault handling 의 overhead 는 8ms 정도.
=> 차이가 크기 때문에 page fault 를 줄이는 것이 중요하다. - fault 횟수를 줄이는 방법 외에, fault handling 시간을 줄이는 방법도 있다.
- disk 의 일부분이 swap space (backing store) 로 할당되면, handling 시간이 감소한다.
- 하지만, 애초에 느린 동작이다 보니 효과에는 한계가 있다.
- 그러므로, 이런 방법 보다는 미래에 접근할 page 를 예측해 fault rate 를 줄이는 것이 더 중요하다
=> 이를 위한 방법을 page replacement algorithm 이라고 한다.
Page Replacement
- free frame 이 없다면, 메모리 상의 page 를 disk 로 내리고 사용하고자 하는 page 를 load 해야 한다.
- 이 과정을 page fault 를 최소화하며 이루는 것이 목표다.
- 메모리 상에 있던 교체 당하는 page 를 victim page 라고 한다.
=> page replacement algorithm 의 목표는 적절한 victim page 를 찾는 것이다.
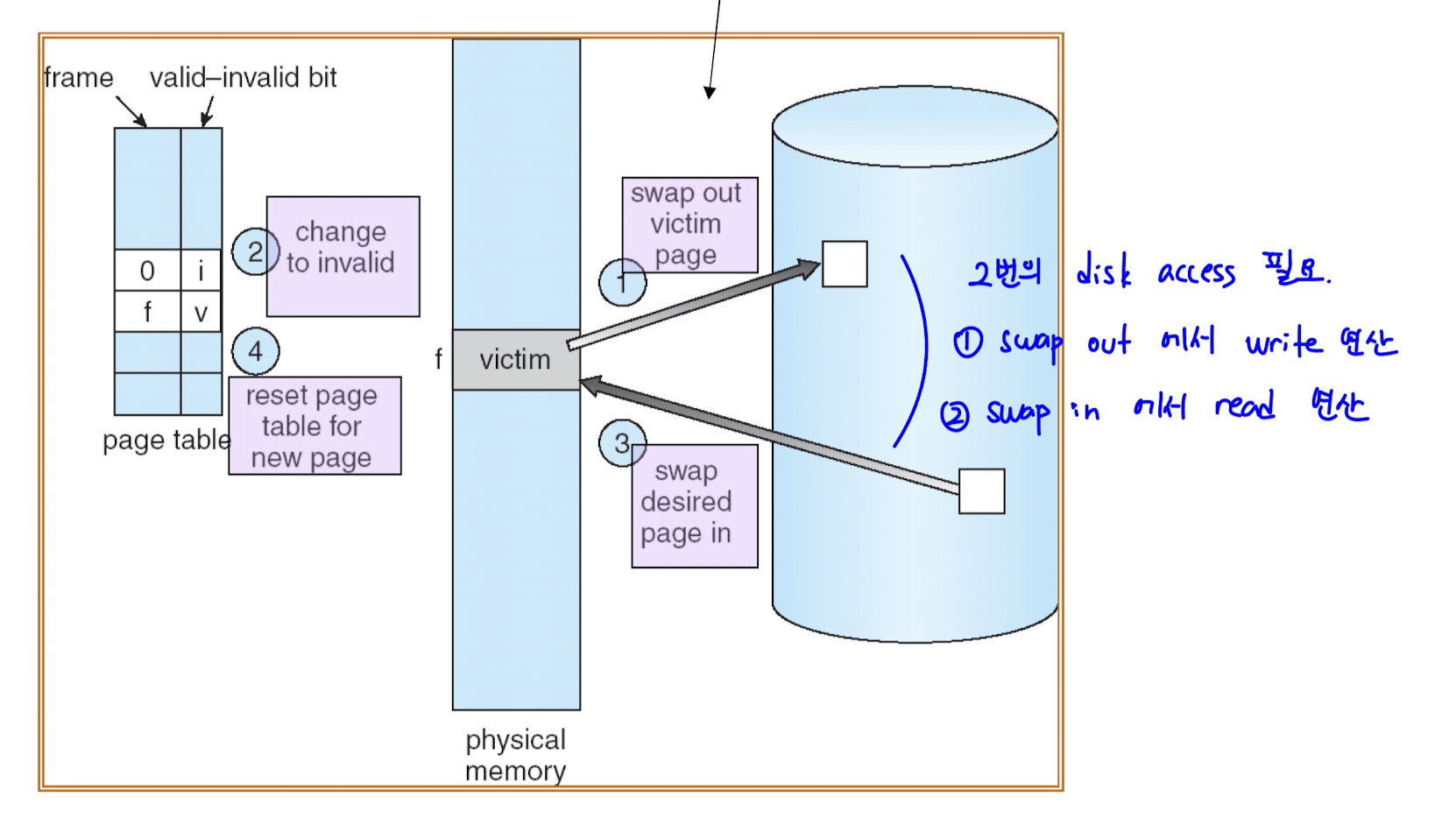
- swapping 의 기본 과정은 다음과 같다.
- physical memory 에서 victim page 를 disk 로 swap out
- victim page 의 valid bit 을 invalid 로 설정
- 요청한 page 를 disk 에서 victim page 로 swap in
- page table update
=> 두 번의 disk access 가 필요하다.
- disk access 는 overhead 가 크기 때문에, 최대한 줄이는 것이 좋다.
- 그러므로 victim page 가 swap in 이후 수정되지 않았다면, 1번 과정을 생략한다.
=> physical memory 와 disk 에 저장된 정보가 동일하기 때문에, 복사해서 옮겨줄 필요가 없기 때문 - 이를 위해 수정 여부를 확인하는 modify bit 을 둔다.
- modify bit 은 page 마다 존재하고, 수정이 되었었다면 1로 설정된다.
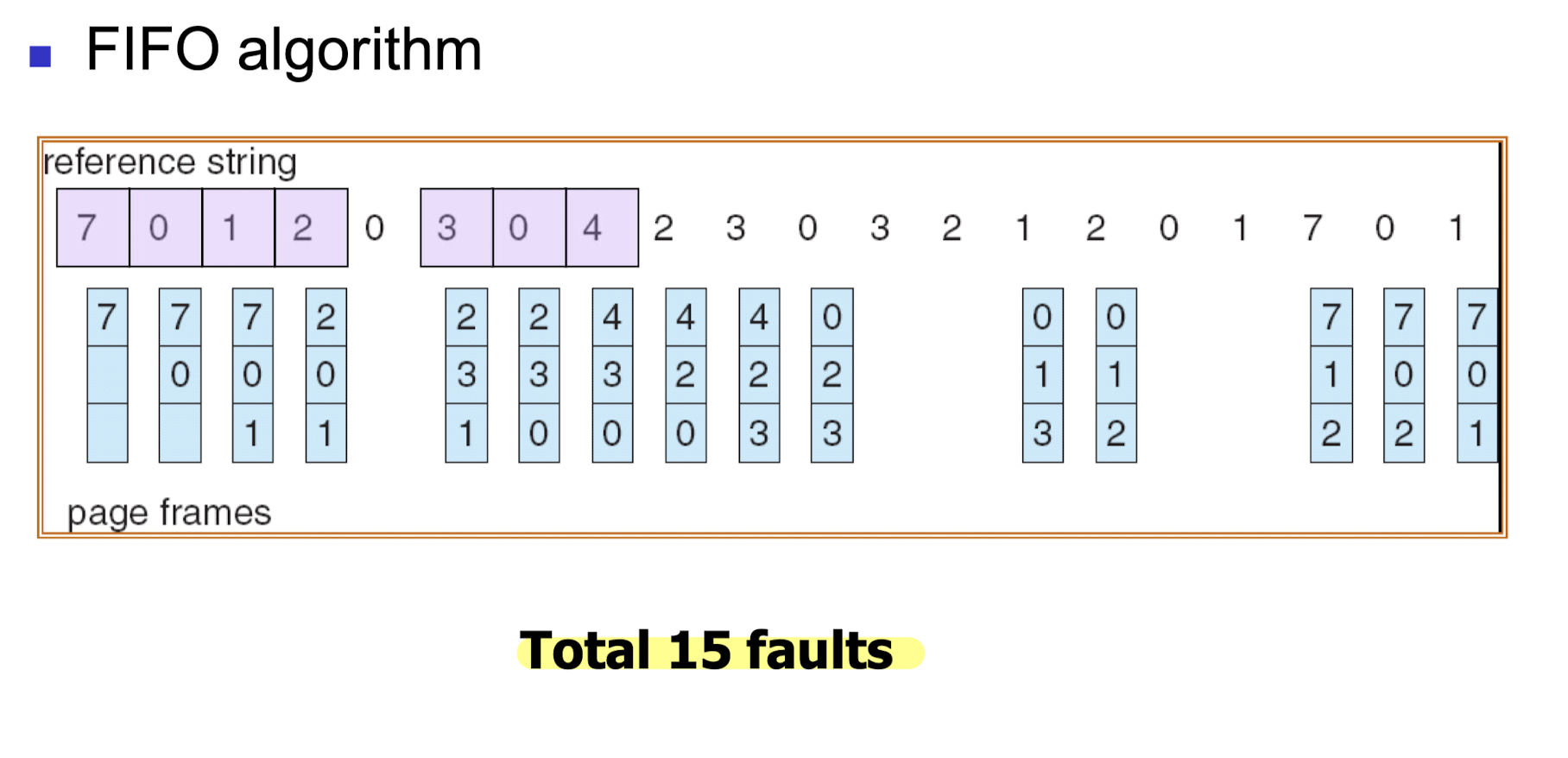
FIFO Algorithm
- 요청된 page 들을 시간 순으로 나열한 것을 reference string 이라고 하자.
- FIFO algorithm 은 먼저 들어온 page 를 victim 으로 설정하는 방식이다.
- reference string 순서대로 할당하고, 먼저 할당된 page 부터 replace 한다.
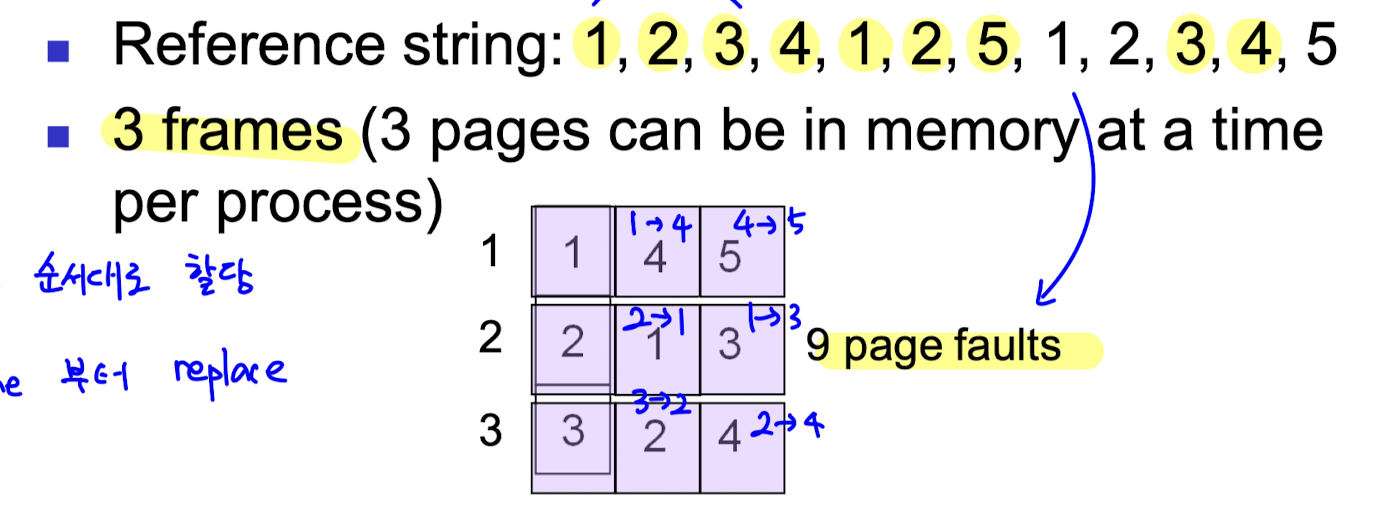
- 위와 같은 reference string 을 3 개의 frame 에 할당하는 경우를 살펴보자.
- 아래의 사항들을 고려하며 page replecement 가 일어난다.
- demand paging 이 사용되기 때문에, 첫 3회의 할당에서는 page fault 가 불가피하다.
- 이미 할당되어 있는 page 에 대해서는 replacement 와 page fault 가 발생하지 않는다.
- frame 이 꽉 차있다면, 가장 먼저 할당되었던 page 를 replace 한다.
- frame 이 3 개일때는 위 그림에서 형광색으로 칠해진 9번의 할당에서 fault 가 발생한다.

- 이제 frame 의 갯수가 4개로 늘었다.
- frame 의 갯수가 늘었기 때문에, 공간이 더 많아 fault 가 덜 발생할 것이라고 예상된다.
- 하지만 fault 를 세어보면 오히려 10번으로 증가한 것을 알 수 있다.
- FIFO algorithm 에서 frame 을 늘렸을 때 fault 역시 증가하는 상황을 Belady's Anomaly 라고 한다.
- 예제)
Optimal Algorithm
- page replacement 에서 가장 최적의 알고리즘을 뜻하며, 더 좋은 방법은 존재하지 않는다.
- 가장 오랫동안 접근되지 않을 page 를 예측해 replace 하는 방식이다.

- 각 replacement 시점을 기준으로, 가장 오랫동안 접근되지 않을 page 를 교체한다.
- 위의 reference string 에서는 5를 swap in 해야 하고, 그 시점에서는 4가 가장 늦게 접근된다.
- 하지만 미래를 정확하게 예측하는 것은 불가능하기 때문에 실제 사용은 불가능하다.
=> 다른 algorithm 의 효율성을 평가하는 지표로 사용됨 - 예제)

LRU Algorithm
- optimal algorithm 의 방식과 유사하게, 가장 접근될 확률이 낮은 page 를 victim 으로 설정한다.
- 가장 오래 전에 사용된 page (LRU, Least Recently Used) 가 다시 접근될 확률이 가장 낮다고 판단한다.
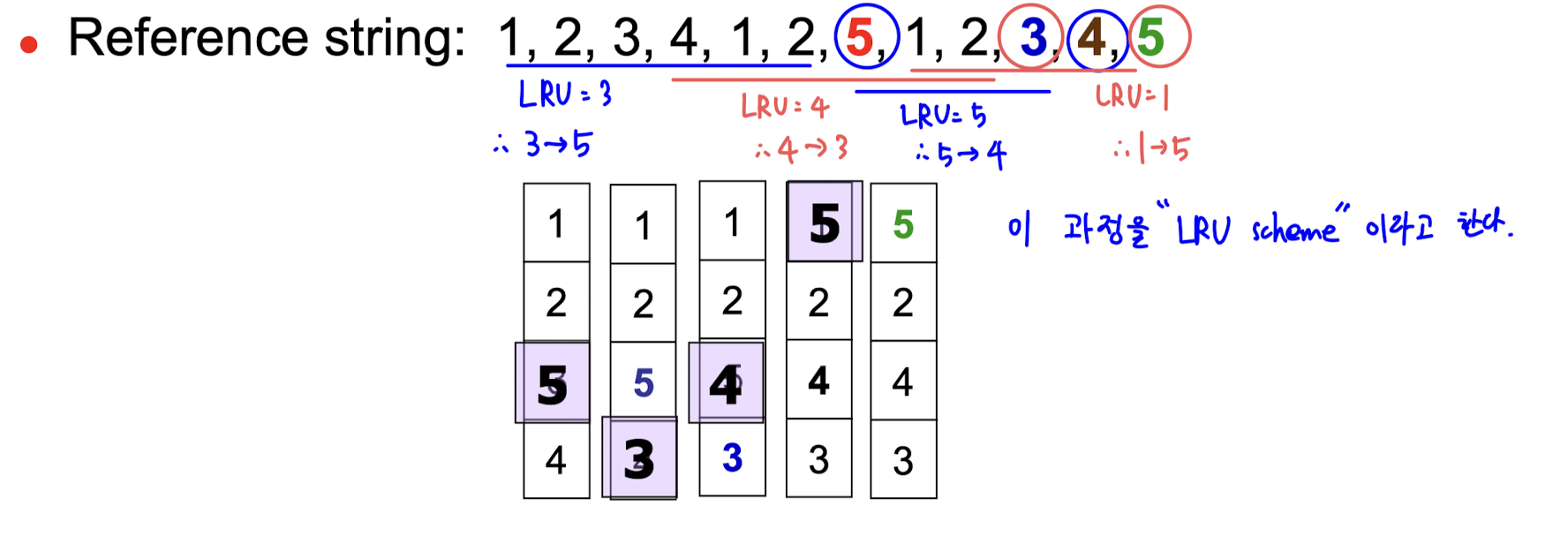
- frame 이 4개인 위와 같은 상황을 살펴보자.
- 첫 교체 시기는 빨간색 5가 접근되는 시점이다. 저 때 LRU 는 3이기 때문에, 3이 victim 으로 설정된다.
- 두 번째 교체 시기는 파란색 3이 접근되는 시점이다. LRU 는 4다.
- 이와 같이 LRU 를 victim 으로 설정하는 과정을 LRU scheme 이라고 한다.
- LRU 는 전반적으로 높은 효율을 보여주지만, 시간 개념이 추가되어 구현이 어렵다는 단점이 있다.
- 구현 방법에는 두 가지가 있다.
1. Counter Implementation

- 각 page 마다 접근된 시간을 기록하는 방법이다.
- page 에 counter 를 두어 접근 시마다 counter 값을 증가시킨다.
=> counter 는 logical time 을 나타내는 것이다. - 교체 시기에서 최소의 counter 값을 가지는 page 가 LRU 가 된다.
2. Stack Implementation
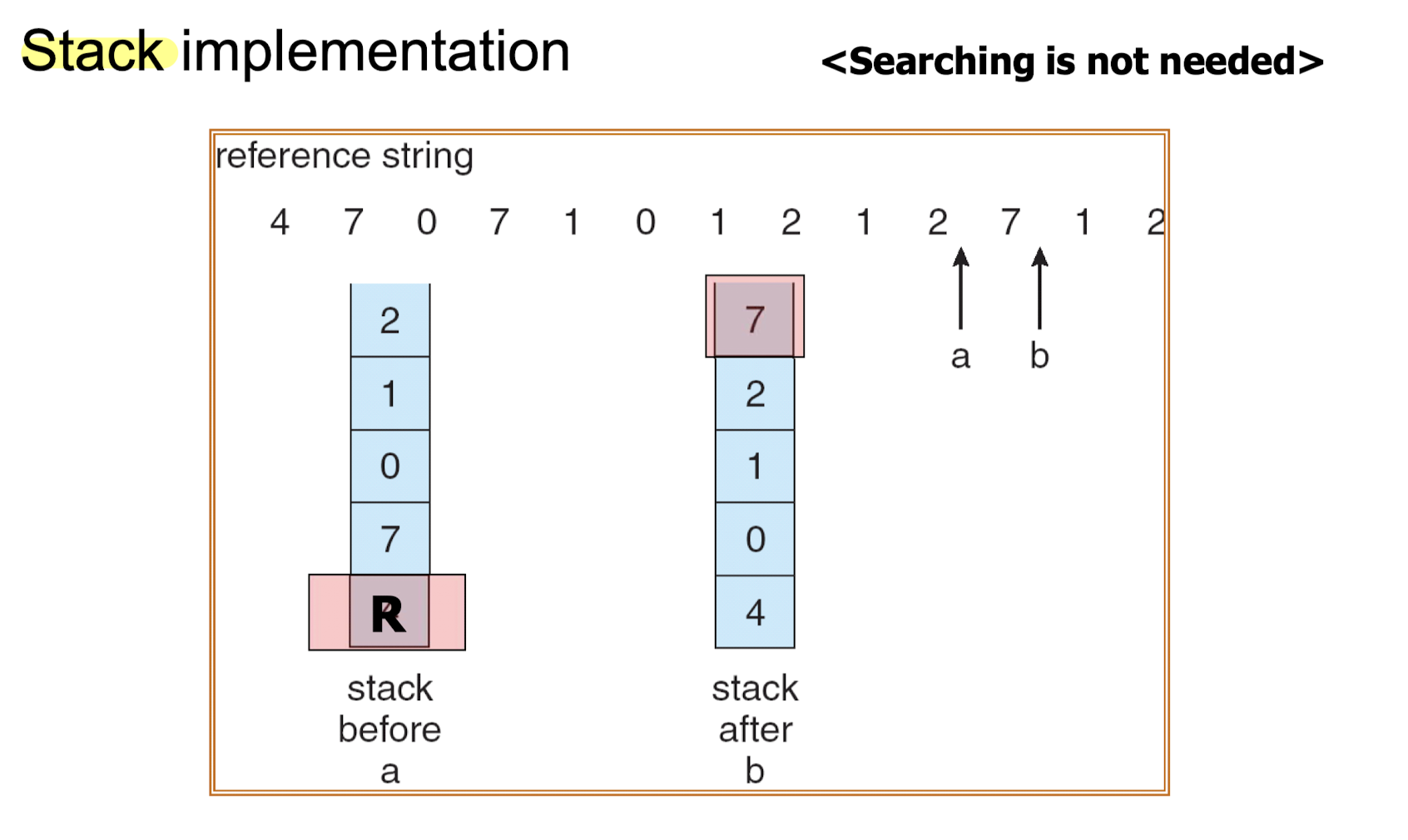
- 접근 순서대로 page number 를 쌓아 접근 순서를 유지시키는 방법이다.
- stack 에 있던 page 가 접근되면 top 으로 다시 올라간다.
- stack 의 가장 아래에 존재하는 page 가 LRU 가 되는 것이다. 즉, bottom 이 victim 이 된다.
- bottom 에 있는 것을 victim 으로 설정하기 때문에 replacement 시 search 가 필요 없다.
- 여기서 주의할 점은 stack 자료구조의 형태를 따를 뿐, LIFO 특징까지 따르지는 않는다는 것이다.
LRU Approximation Algorithm
- 앞에서 언급했듯이, LRU algorithm 은 효율적이지만 구현이 복잡하다.
- LRU 와 유사하지만 덜 복잡한 구현을 가진 방식들이 LRU approximation algorithm 이다.
1. Reference Bit
- reference bit 은 page 의 참조 여부를 나타낸다. 초기값은 0이고, 참조 시 1로 설정된다.
- page 중 reference bit 이 0인 page 를 victim 으로 설정한다.
- 이 방식은 reference bit 이 0인 page 가 여러 개일 때, 순서를 알 수 없는 경우가 있다는 단점이 있다.
2. Additional Reference Bits Algorithm

- page 당 여러 개의 reference bit 을 두어, 접근 순서를 알 수 있는 방식이다.
- 위의 예시에서는 8개의 bit 을 사용한다.
- page 가 접근되면, 가장 왼쪽의 bit 을 1로 설정한다.
- 일정한 주기를 설정해, 주기마다 bit 을 오른쪽으로 shift 시킨다.
=> 오른쪽에 있는 bit 일수록 이전의 시점을 나타내는 것이다. - 아래의 두 page 중, 오른쪽의 page 가 더 접근된 지 오래됐기 때문에 victim 으로 설정된다.
3. Second Chance Algorithm
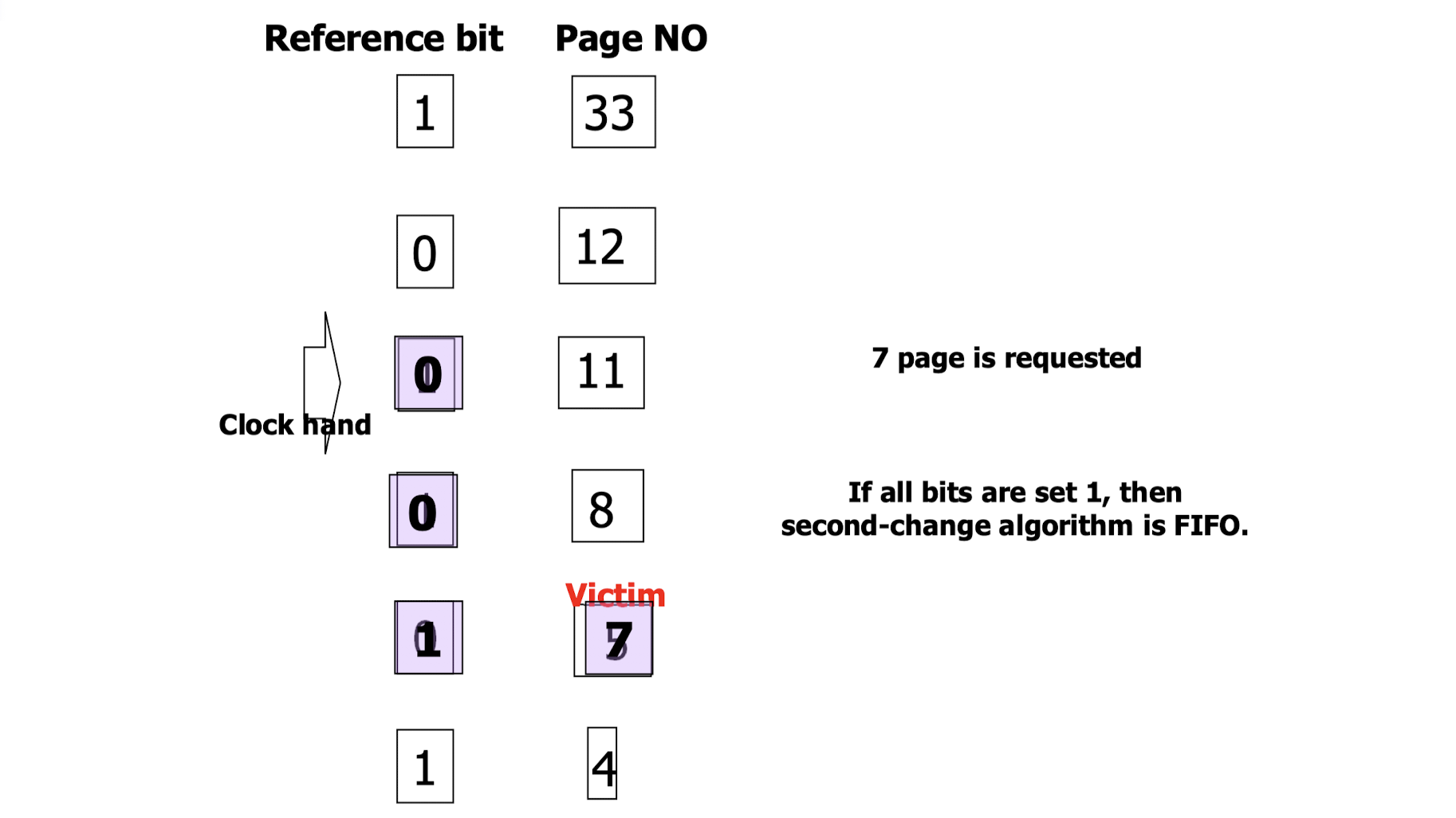
- clock algorithm 이라고도 불리며, 하나의 reference bit 을 사용한다.
- clock hand 가 순회하며, 처음 만나는 reference bit 이 0 인 page 를 victim 으로 설정하는 것이 기본 방식이다.
- 이에 추가로, bit 이 1인 page 를 만나면 bit 을 0으로 바꾸기만 하고 memory 에 남겨둔다.
=> clock hand 가 만나는 page 를 바로 교체하지 않아서 second chance 를 준다고 하는 것이다. - 모든 page 의 reference bit 이 0이면 FIFO 와 동일하다.
4. Enhanced Second Chance Algorithm
- reference bit 에 추가로 modify bit 을 두어 이들의 조합으로 page 를 분류한다.

- 분류 방식은 위와 같고, 낮은 (숫자가 작은) class 를 우선적으로 victim 으로 설정한다.
5. Counter Based Algorithm
- reference 횟수를 명시하는 counter 를 이용하는 방식으로, 두 가지가 있다.
- LFU algorithm : 가장 낮은 count 가 victim 이 된다.
- MFU algorithm : 가장 높은 count 가 victim 이 된다.
Thrashing
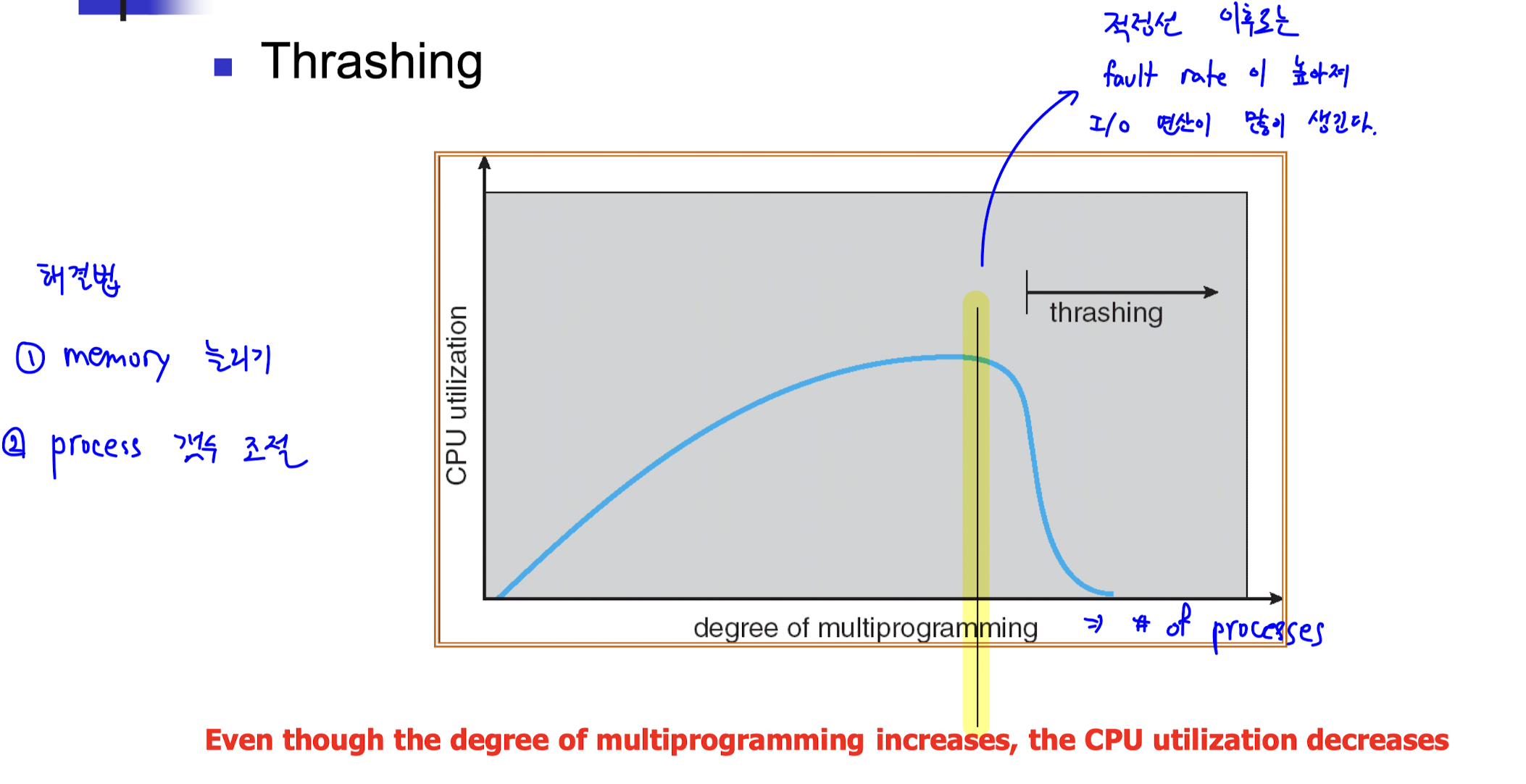
- 메모리 부족으로 발생하는 현상이다.
- page fault rate 가 높다.
- swapping 이 자주 일어난다.
- disk 접근이 많아져 CPU utilization 이 낮다.
- CPU utilization 이 떨어져 OS 는 프로세스 갯수를 늘려 task 을 수행하고자 한다.
- 정리하자면, 메모리가 부족해 swapping 을 많이 하느라 바빠 task 가 제대로 수행되지 못하는 것이다.
- 위의 그래프에서 degree of multiprogramming 이 늘어갈 때 일정 시점에서 CPU utilization 이 급격히 감소하는 thrashing 발생 지점을 관찰할 수 있다.
- thrashing 을 방지하기 위해서는 frame 의 수에 맞게 프로세스의 수를 조절해야 한다.
- 적절한 프로세스의 수는 locality model 을 이용해 측정한다.
- locality model 은 전체 page 가 아닌, 집중적으로 접근되는 page 들만을 고려한다.
=> 전체 page 를 다 신경쓰면, 필요한 프로세스를 과도하게 측정하는 over estimation 발생 - 즉, 프로세스가 필요한 메모리는 locality 의 크기로 판정하는 것이다.
=> locality : 특정 지점에 active 하게 접근되는 크기를 의미 - 집중적으로 접근되는 page 의 수가 (size of locality) 메모리보다 클 때 thrashing 이 발생한다.
Working Set Model
- locality 의 크기를 파악해 현재 메모리 상황에 가장 알맞은 프로세스의 갯수를 찾는 방법이다.
- locality 파악을 위해 window 라는 시간 개념이 등장한다. 쉽게 말해 window 는 특정 시간 간격이다.
=> window size 가 10이면, 10 단위 시간을 살핀다는 뜻이다. - WSSi (Working set of Process Pi) : Pi 에서 특정 window 에 접근하는 page 의 수
- WSSi 의 총 합 D 는 필요한 frame 의 총 갯수를 의미한다.
- D 값이 physical memory size 보다 크면 thrashing 이 일어난다.
- 적절한 window size 의 설정은 중요하다.
- window size 가 너무 크면, 과도한 범위를 참고해 over estimation 이 발생
- window size 가 너무 작으면, cover 하는 locality 가 부족해 thrashing detection 이 어려워진다.
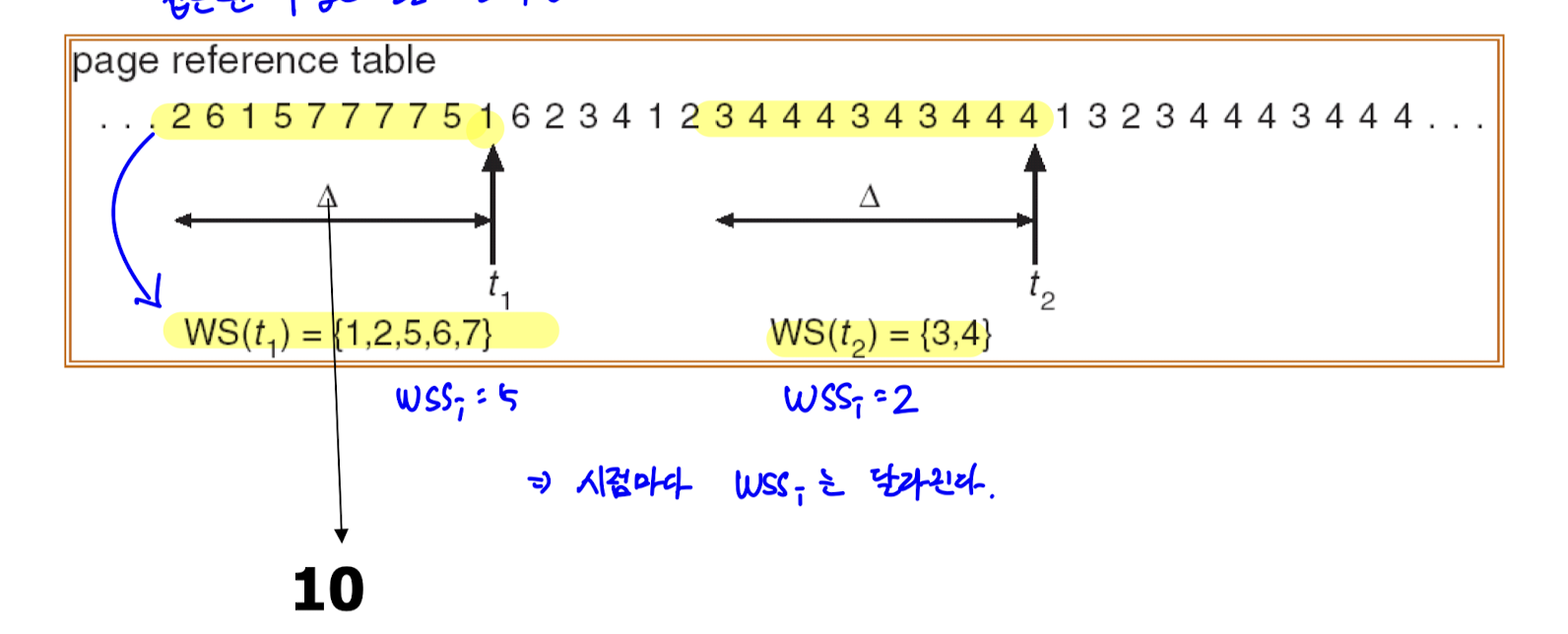
- 위 그림은 window size 가 10 인 경우다. 시점마다 WSSi 가 달라지는 것을 알 수 있다.

- 위 그림은 WSSi 의 총 합이 physical memory size 를 초과해 thrashing 이 발생한 경우다.
- window size 가 클수록 thrashing detection 이 좋아짐을 알 수 있다.
Allocating Kernel Memory
- kernel 의 동작에 필요한 메모리를 할당, 해제하는 과정을 알아보자.
- kernel memory 는 지금까지 살펴본 user memory 와는 다른 할당 방식을 사용하는데, 이유는
- kernel 은 다양한 크기의 구조체를 위한 메모리를 필요로 한다.
- kernel memory 는 contiguous 하게 관리되어야 하는 상황이 있다.
Buddy System
- 위에서 언급한 메모리가 contiguous 하게 관리되어야 하는 상황에 사용하는 방법이다.
- 기본 아이디어는 power of 2 allocator 의 사용이다. 쉽게 말해, 2^n 단위의 메모리 할당이다.
- coalescing (병합) 과 splitting (분할) 연산이 사용된다.
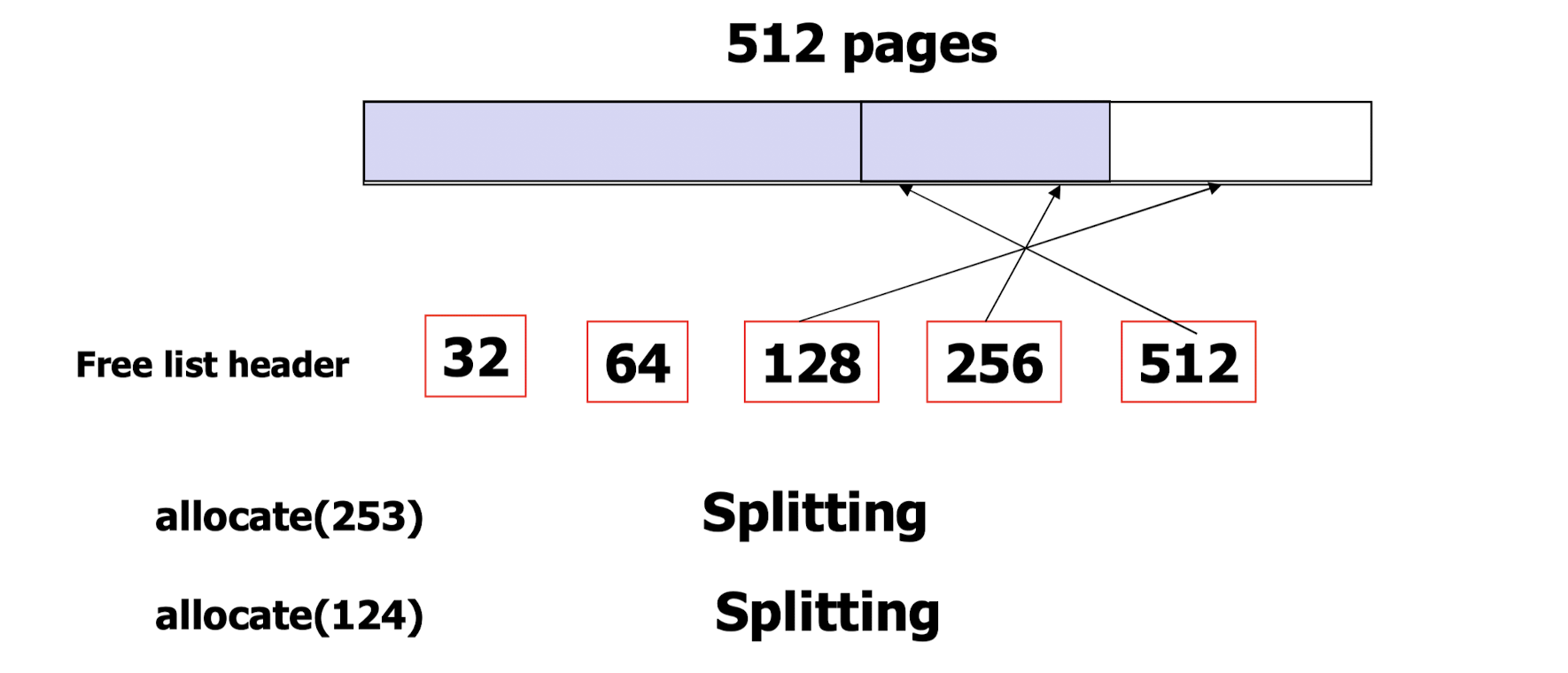
- 512 개의 page 를 할당하는 과정을 살펴보자.
- free list header 는 비어있는 공간을 가리켜 크기를 명시한다.
- 아무것도 할당하지 않았을 때는 빈 공간이 512고, free list header 의 512 가 공간을 가리킨다.
- 253 pages 가 요청되었다. power of 2 allocator 를 사용하기 때문에 256 pages 가 할당된다. 이제 빈 공간의 크기는 256 이고, free list header 의 256 이 빈 공간을 가리킨다.
=> free memory 보다 작은 크기의 메모리 할당을 위해 공간을 분할하는 splitting 연산이 일어났다. - 124 pages 가 요청되었다. power of 2 allocator 를 사용하기 때문에 128 pages 가 할당된다. 이제 빈 공간의 크기는 128 이고, free list header 의 128 이 빈 공간을 가리킨다.
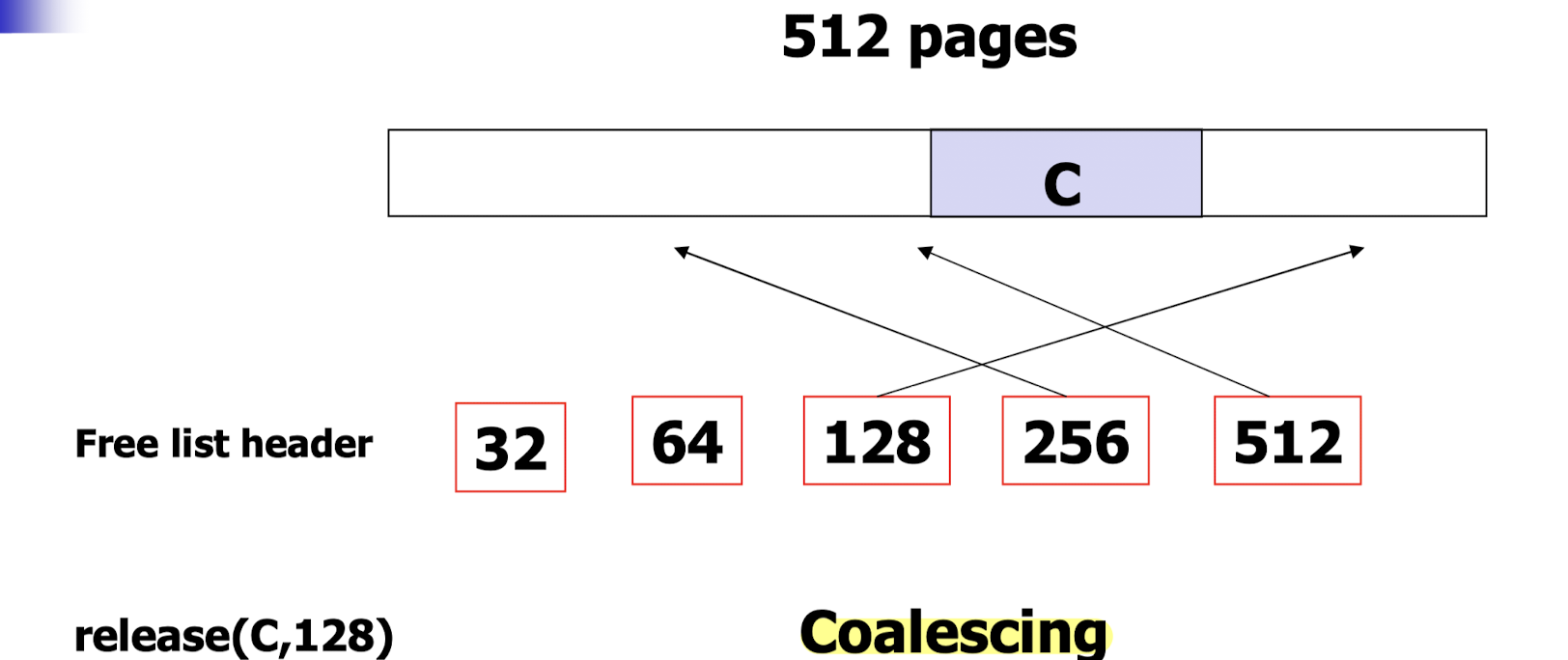
- 512 pages 중 128 pages 를 할당받았던 프로세스 C 가 종료되어, page 들이 반환되는 상황이다.
- 프로세스 종료 이전에는 free list header 의 256 과 128 이 각 빈 공간을 가리키고 있었다.
- 메모리 반환 이후에는 빈 공간을 256, 128, 128 로 관리하는 것이 아닌, coalescing 연산으로 이들을 병합해 512 로 관리한다. 이는 contiguous 한 memory allocation 을 위함이다.
Slab Allocation
- thread pool 과 유사하게 page 들을 미리 할당해 두고, 객체 생성 시마다 주소를 할당해 사용한다.
- 이 때 할당되는 넓은 공간을 slab 이라고 하고, slab 들의 집합을 cache 라고 한다.
- 저장하는 구조체에 따라 semaphore, PCB, spin lock cache 등으로 불린다.
- 이러한 방식으로 두 가지 장점이 생긴다.
- page 단위가 아닌 slab 을 사용해 internal fragmentation 으로 인한 메모리 낭비 최소화
- slab 은 미리 할당되기 때문에 memory allocation 이 빠르다.
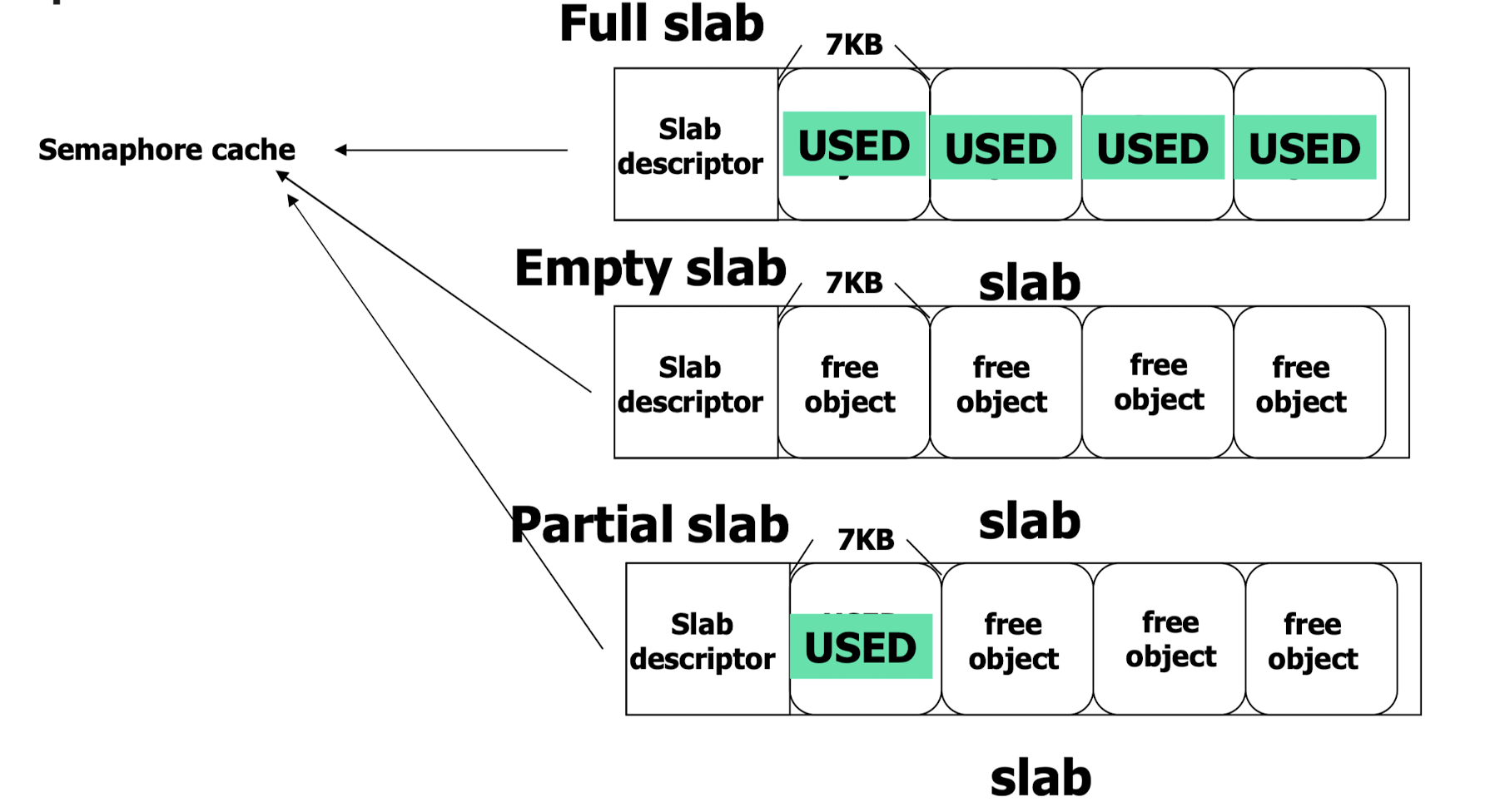
- slab 이 사용되고 있는 정도에 따라 full, empty, partial 로 구분한다.
- empty slab 보다는 partial slab 이 우선적으로 사용된다.
- 공간이 부족할 것 같으면 cache 에 empty slab 을 미리 할당한다.
- 7KB 의 semaphore 에 메모리를 할당할 때, page 를 이용했다면 1KB 의 internal fragmentation 이 발생했을 것이다. slab 을 이용해 메모리 낭비를 최소화 한 것을 관찰할 수 있다.

인하대학교 컴퓨터공학과