- process scheduling 은 한정된 CPU 의 자원을 여러 개의 process 에게 분배하는 방법이다.
- 프로세서의 갯수는 한정적이기 때문에, 언제 어느 프로세스를 실행할 지 정하는 것이다.
- scheduling 이 일어나는 기준을 scheduling criteria, 이를 실행하는 방법을 scheduling algorithm 이라고 한다.
- scheduling 에는 크게 두 가지 유형이 있다.
- preemptive scheduling
기존에 수행되던 프로세스가 실행 중일 때, priority 가 더 높은 프로세스가 있으면 실행중이던 프로세스를 중단하고, context switch 가 일어난다. - non preemptive scheduling
위와 반대로, 기존에 수행되던 프로세스가 끝나길 기다린 후 context switch 가 일어난다. 다시 말해, 수행 중이던 프로세스가 자원을 자발적으로 반납하도록 허용하는 유형이다.
Basic Concepts
Property of Processes
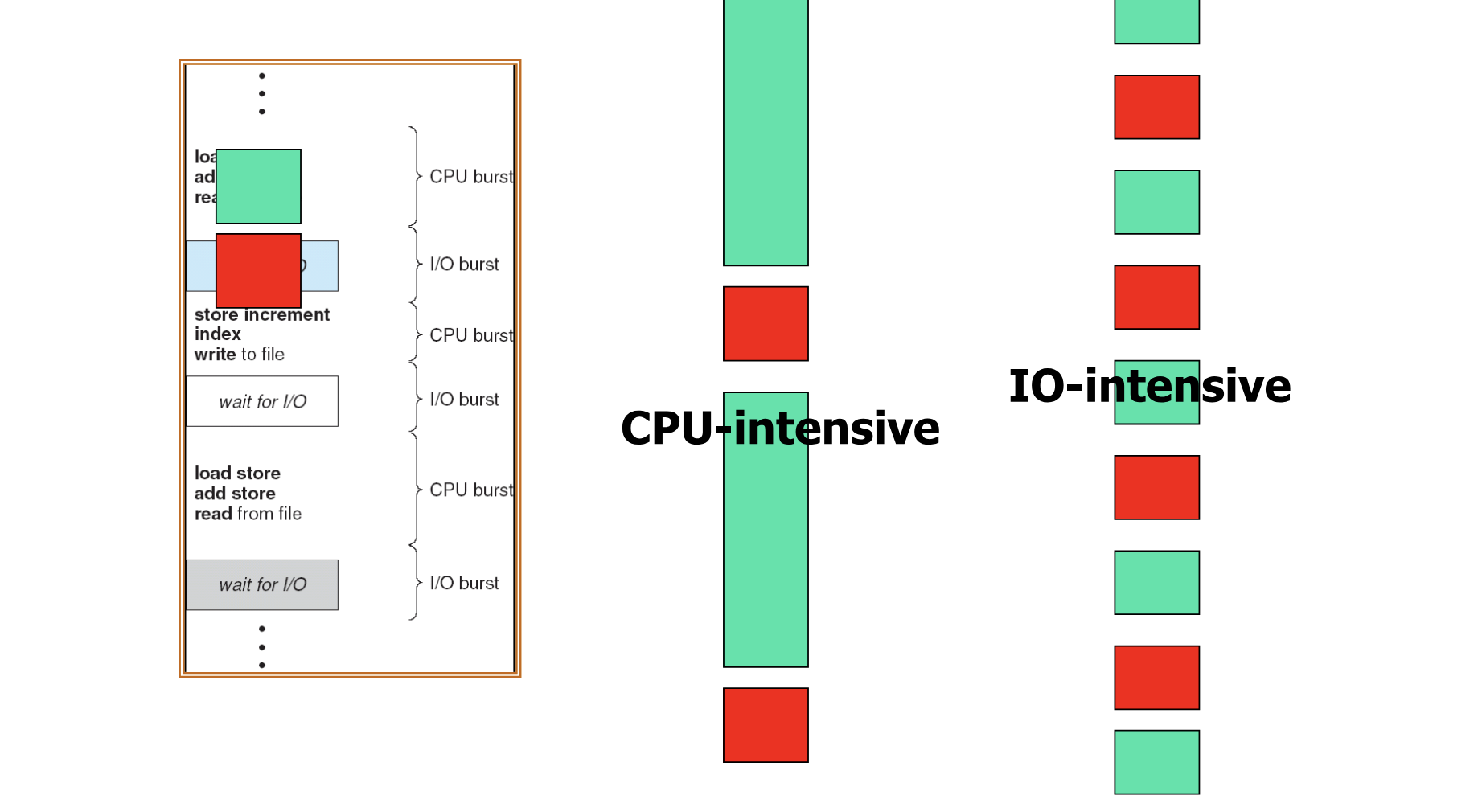
- 프로세스는 자주 일어나는 연산에 따라 두 가지로 분류할 수 있다. CPU 를 사용하는 연산이 소모하는 시간을 CPU burst, I/O operation 에 소비되는 시간을 I/O burst 라고 한다.
- 프로세스 내부에서는 두 연산이 번갈아 일어난다.
- 긴 CPU burst 를 가지는 프로세스를 CPU - intensive, 짧은 CPU burst 를 가져 I/O burst 의 비중이 더 높은 프로세스를 I/O - intensive 라 한다.
General Rule of Scheduling
- I/O intensive 한 프로세스가 같은 시간 동안 더 많은 일을 할 수 있기에, scheduling 의 우선 순위는 I/O intensive 한 프로세스에게 있다.
- 이는 average waiting time 을 줄여 starvation 을 방지하기 위함이다.
CPU Scheduler
- ready queue 에서 CPU 자원을 할당해 실행시킬 프로세스를 선택하는 역할을 한다.
- CPU scheduling 은 프로세스에 다음의 네 가지 변화가 나타날 때 일어난다.
- running 에서 waiting 상태로 전환
- running 에서 ready 상태로 전환
- waiting 에서 ready 상태로 전환
- terminate 될 때
- 프로세스가 자발적으로 자원을 반납하고 실행을 멈출 때 scheduling 이 일어나는 non preemptive scheduling 이 해당하는 경우 => 1, 4
- preemptive scheduling 이 일어날 수 있는 경우 => 1,2,3,4
=> 3의 경우, 실행 중이던 프로세스 보다 ready 로 새로이 전환된 프로세스의 priority 가 더 높을 때 preemptive scheduling 이 일어난다. - 정리하자면, scheduling 이 일어나는 경우는 다음과 같다.

- preemptive scheduling 은 non preemptive 가 일어나는 경우에 더불어 다음의 경우에 일어난다
- 우선 순위가 높은 프로세스가 block 상태에서 ready 상태가 됨
- interrupt 가 끝나면 wait 상태이던 프로세스가 ready 로 돌아간다.
- preemptive scheduling 시, 강제로 종료 시켰던 프로세스의 context 를 저장해야 하므로, shared data access 에 대한 고려를 해야 한다.
Preemption in the Kernel
- system call 이나 interrupt 가 일어날 때, preemption 이 일어날 수 있다.
- preemption 은 급박한 일을 먼저 처리할 수 있다는 장점이 있다.
- real timeness 를 보장하기 위해 LINUX 2.6 부터는 system call 에서의 preemption 을 허용한다.
- 이와 반대로 HW interrupt handler 호출 시에는, 시스템 내부에서 예측하지 못한 급박한 상황이므로, preemptive / non preemptive 여부와 상관 없이 먼저 실행된다.
Dispatcher
- scheduler 가 다음으로 실행될 프로세스를 골랐다면, dispatcher 는 이를 실제로 실행시킨다.
- dispatching 과정은 다음과 같다
- context switching
- 프로세스 실행을 위해 user mode 로의 전환
- 올바른 실행 위치로의 jump
- scheduling 완료 시점으로부터 실제 실행 시점까지의 시간차를 dispatch latency 라고 한다.
- dispatching 은 시간이 많이 걸리는 expensive 한 연산이다.
Scheduling Criteria
- Scheduling algorithm 이 추구하는 기준으로, 크게 5가지가 있다.
1. CPU utilization
CPU 가 실제 일한 시간의 비율
2. Throughput
단위 시간 내에 완료한 task 의 수
=> 1, 2번은 전체 프로세스에 적용되는 내용이다.
3. Turnaround time
제출된 시간부터 완료된 시간까지의 소요 시간
4. Waiting time
ready queue 에서 기다린 총 시간
5. Response time
request 제출 후 첫 응답 산출까지 걸린 시간
=> 3, 4, 5 번은 특정 프로세스에게 적용되는 내용이다. - 우리는 scheduling algorithm 선정 시 4, 5 번에 집중할 것이다.
- 특히, average waiting time 을 줄이는 것에 집중한다.
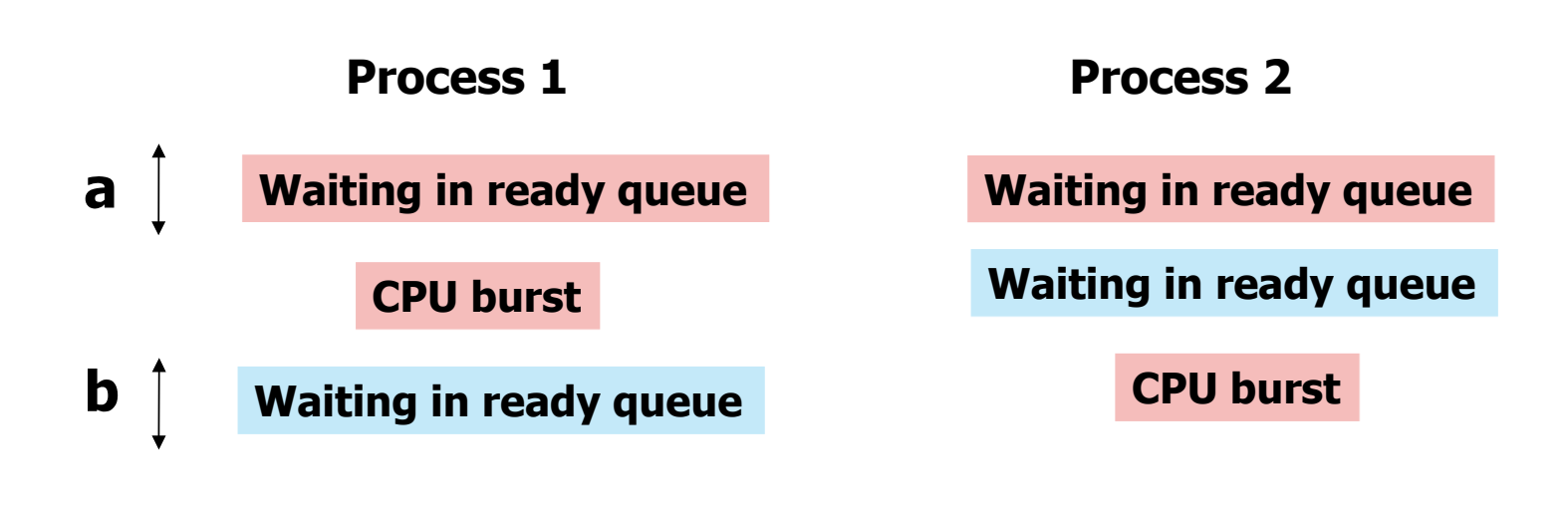
- process 1 이 실행되다가, a 만큼의 시간이 지난 후 process 2 로 context switch 가 된 상황이다.
- process 1 의 waiting time = a + b, response time = a
- process 2 의 waiting time 과 response time 은 동일하다.
Scheduling Algorithms
First Come, First Served (FCFS)
- process 실행 요청이 도착한 순서대로 scheduling 하는 방식이다.
| proess | burst time |
|---|---|
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
- 이 경우, scheduling 순서는 1, 2, 3 이다.
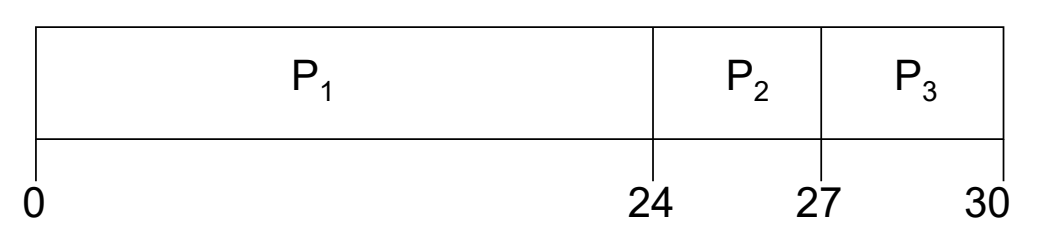
- 이에 대한 Gantt Chart 를 그려보면, 다음과 같다.
- average waiting time 은 (0 + 24 + 27) / 3 = 17 이다.
- 만약 도착 순서가 2, 3, 1 로 달라졌다면, 이렇게 될 것이다.

- average waiting time 은 (0 + 3 + 6) / 3 = 3 으로, 훨씬 작아졌다.
- 이렇듯 실행 순서에 따라 waiting time 이 달라지는 현상을 Convoy Effect 라고 한다.
- 이를 토대로 average waiting time 을 줄이는 방법은 다음과 같다.
- burst time 이 짧은 short process 들을 앞에 배치한다.
- 위와 같은 맥락으로, I/O bound process 에게 우선순위를 주어 앞에 배치한다.
Short Job First (SJF) Scheduling
- 가장 짧은 CPU burst 를 가지는 프로세스를 우선시하는 방법이다.
- FCFS 에서 봤듯이, short process 를 앞에 둘수록 avg waiting time 이 짧아졌다. 그렇기에 SJF 는 avg waiting time 을 줄이는 측면에서 optimal 하다.
- scheduling 양상이 preemptive 인지 non preemptive 인지에 따라 과정이 달라진다.
- non preemptive
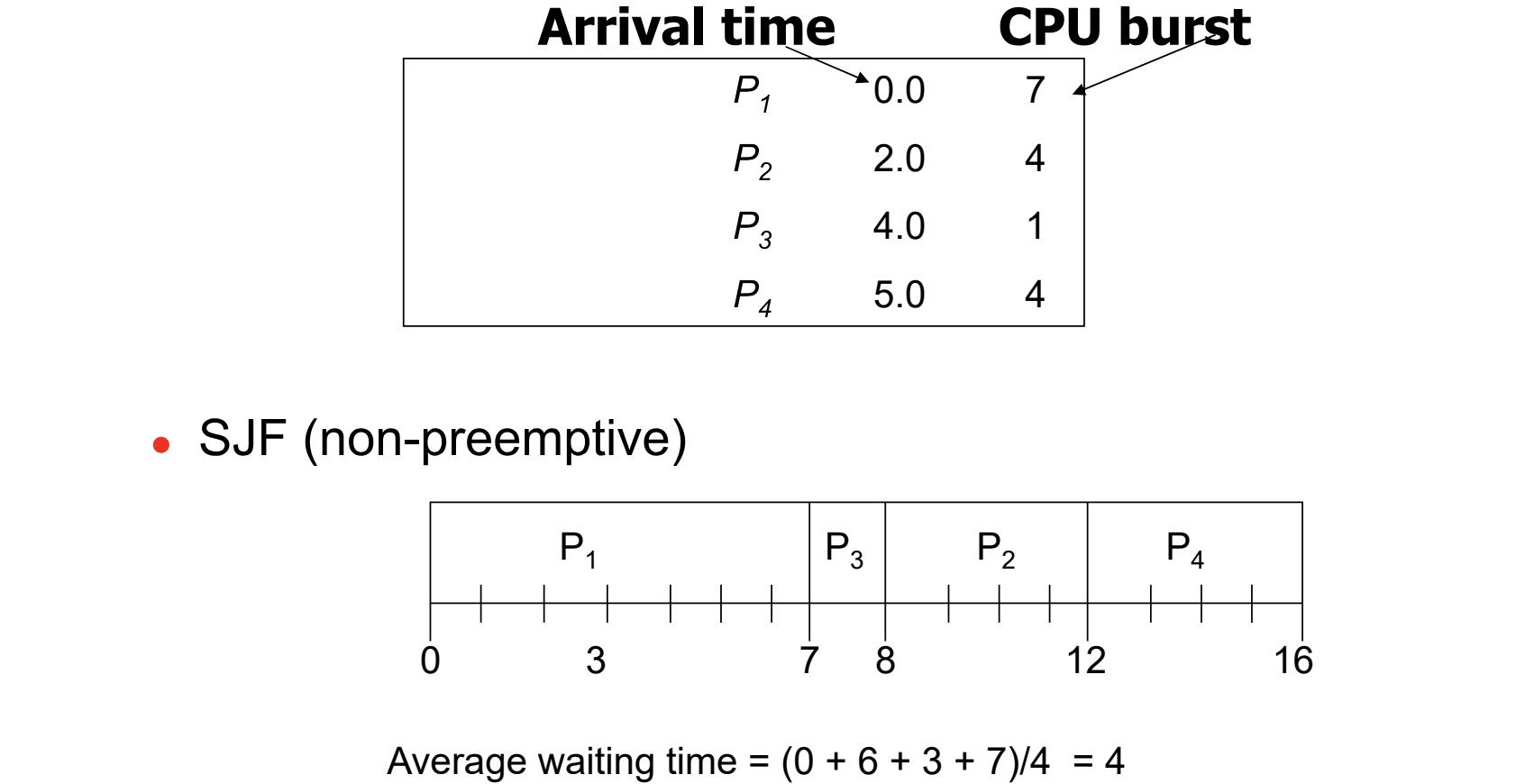
- task 수행 중에 preemption 이 일어나지 않는다.
- 그러므로, 수행 이후 남은 task 중 가장 적은 CPU burst 를 가지는 쪽에 우선순위를 둔다.
- 마지막 과정의 P2, P4 처럼 같은 burst 를 가진다면, 먼저 도착한 쪽에 우선순위를 둔다.
- preemptive

- task 수행 중 preemption 이 일어난다.
- 새로운 task 에 대한 요청이 도착할 때 마다 남은 burst 를 비교해 context switch 를 한다.
- preemptive 의 경우가 avg waiting time 이 더 적음을 알 수 있다.
- 이 방식을 Shortest Remaining Time First (SRTF) 라고도 한다.
Exponential Averaging
- SJF 는 프로세스의 다음 CPU burst 를 기반으로 scheduling 을 하므로, 미래의 CPU burst 에 대한 예측이 필요하다.
- 이를 예측하는 방법이 exponential averaging 이다. 두 가지 기준을 사용하는데,
- 이전의 수행시간을 기반으로 예측
- 최근의 정보일수록 가중치를 더 둔다.
- 이를 바탕으로 세운 수식은 다음과 같다.

- 여기서 a 는 가중치 인자로, 오래된 정보일수록 값을 줄여 가중치를 줄이는 역할을 한다.
- a = 0 이라면, t 항이 없어져 실제 값이 반영되지 않고, 1 이라면 예측 값이 반영되지 않는다.
- define 식을 전개해보자.

- n 번째 예측항을 define 식의 형식으로 치환하면, 항이 거듭될수록 (1 - a) 가 곱해진다.
- (1 - a) 는 0보다 작은 값이므로, 곱해지는 인자가 점점 작아진다.
- 이를 이용해 오래된 예측일수록 작은 가중치를 부여할 수 있다.
Priority Scheduling
- 프로세스마다 우선순위를 나타내는 priority number 를 배정한다. 이 값이 작을수록 우선순위가 높다.
- 무조건 우선순위가 높은 프로세스를 CPU 에 할당시켜주는 방법이다.
- SJF 는 priority number 이 burst 의 예측값에 기반하는 priority scheduling 의 일종이다.
- 우선순위만을 고려하다 보면, 낮은 우선순위의 프로세스가 오래도록 실행되지 못하는 starvation 이 발생할 수 있다.
- 이에 대한 해결책으로 오래 실행되지 못한 프로세스의 우선순위를 점진적으로 높여주는 aging 이 있다.
- 우선순위가 고정된 static priority 와 그렇지 않은 dynamic priority 가 있다. aging 은 dynamic priority 에서 사용할 수 있는 기법인 것이다.
Round Robin
- 프로세스들을 번갈아가며 수행하되, 최대 실행 시간인 time quantum 을 설정하는 방법이다.
- 프로세스가 한번에 끝까지 실행되지 못하기 때문에 preemtive 에 속하는 방법이다.
- time quantum 이 너무 크면 FIFO 와 다를 바가 없고, 너무 작으면 context switch 의 overhead 가 크다.
- 다음은 time quantum 을 20으로 설정한 경우다.
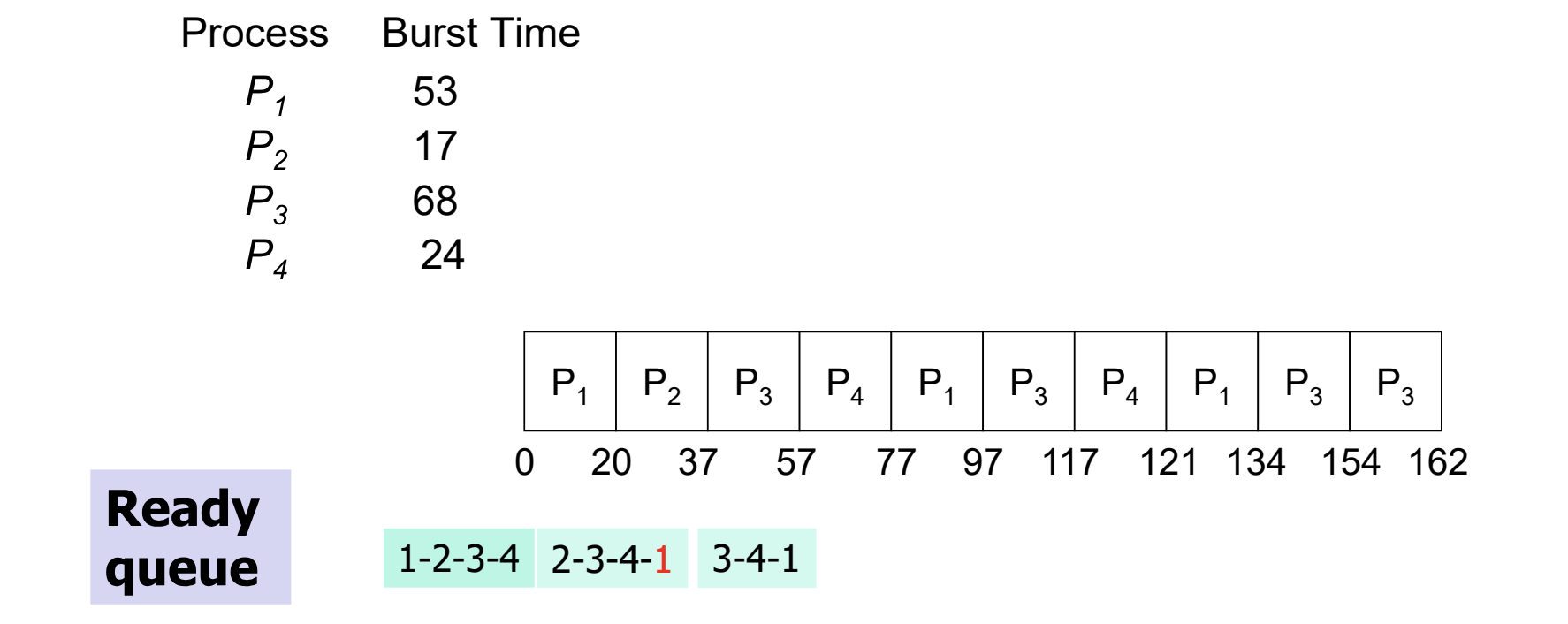
- 실행 중 시간이 다 되어 정지되면, ready queue 의 마지막에 push 된다.
- context switch 가 자주 일어나 overhead 가 크지만, 가장 response time 을 잘 보장하는 방법이다.
- time quantum 이 짧을수록 response 가 증가한다.
Multilevel Queue
- 여러 scheduling algorithm 들을 혼합한 방법이다.
- ready queue 가 여러 개의 queue 로 나눠지고, 각각의 queue 에는 자신만의 scheduling algorithm 을 사용한다.
- 각 queue 마다 최상 우선순위를 가지는 프로세스를 선별하고, 그 프로세스들 간에 scheduling 을 한번 더 진행한다. 즉, queue 내부의 scheduling 과 queue 간의 schedulig 이 일어난다.
- 다음은 queue 간의 scheduling algorithm 을 fixed priority 로 설정한 모습이다.
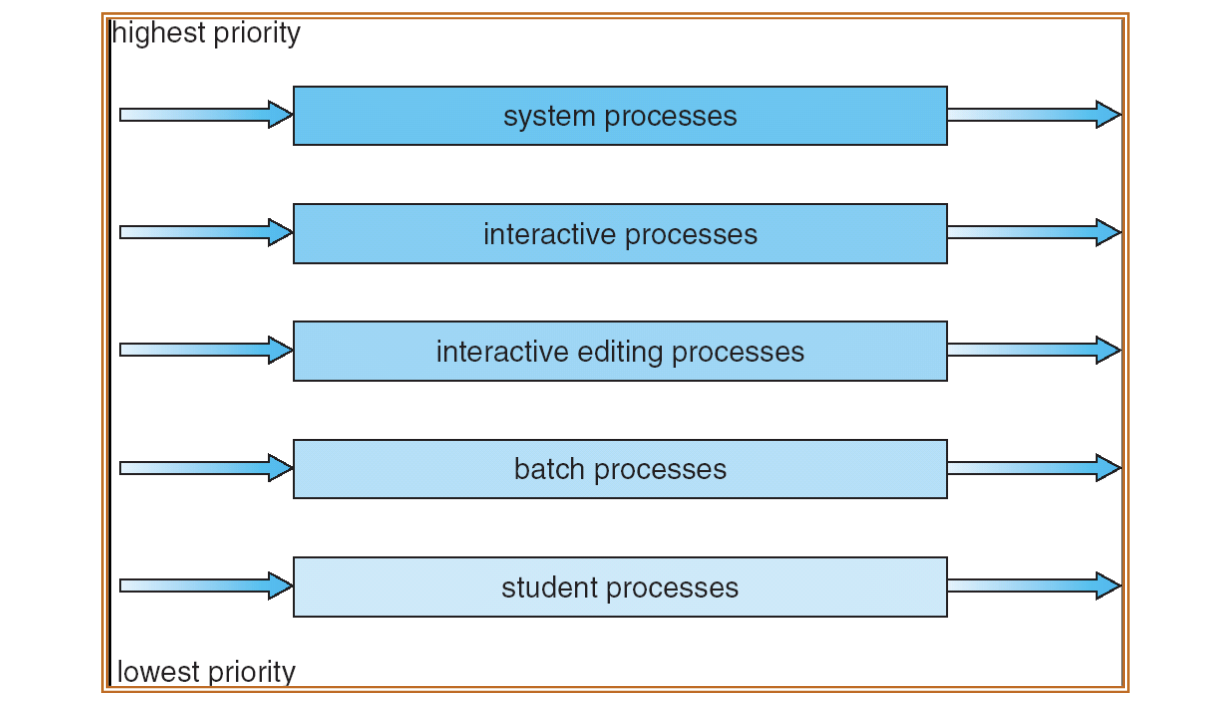
Multilevel Feedback Queue
- multilevel queue 의 기능에 추가로 process 가 queue 간 이동을 할 수 있게 허용한 방식이다.
- 그렇기에 queue 간의 이동(upgrade, demote) 양상을 추가로 정해주어야 한다.
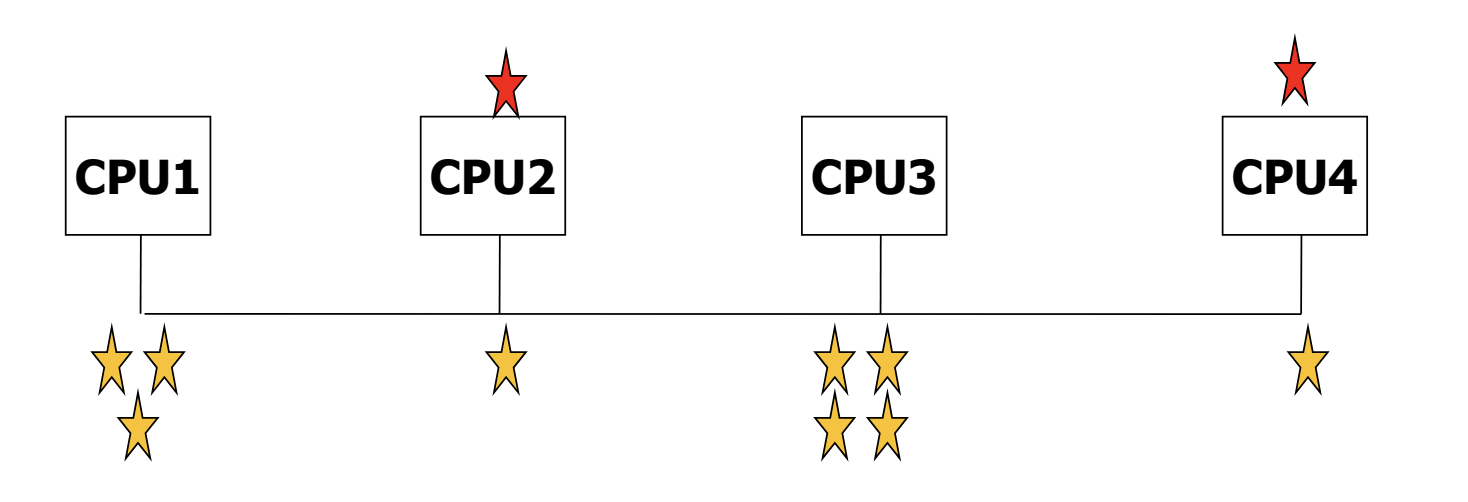
Multiple Processor Scheduling
- multiprocessor 를 이용해, 한 번에 여러 프로세스를 scheduling 하고 실행시킬 수 있다.
- scheduling 된 프로세스들을 어느 CPU 에 할당할지 정하는 task allocation 이 중요한 문제가 된다.
- multiprocessing 의 양상에 따라 task allocation 의 방식이 달라진다.
- Symmetric Multiprocessing (SMP) : 각 프로세서가 자신의 scheduling decision 을 내린다.
- Asymmetric Multiprocessing : master slave relationship 이 존재하기에, master processor 만이 system data structure 에 접근해 scheduling 을 결정할 수 있다.
Process Affinity
- task allocation 의 과정에서, 프로세스와 CPU 간의 친밀도를 고려하는 과정이다.
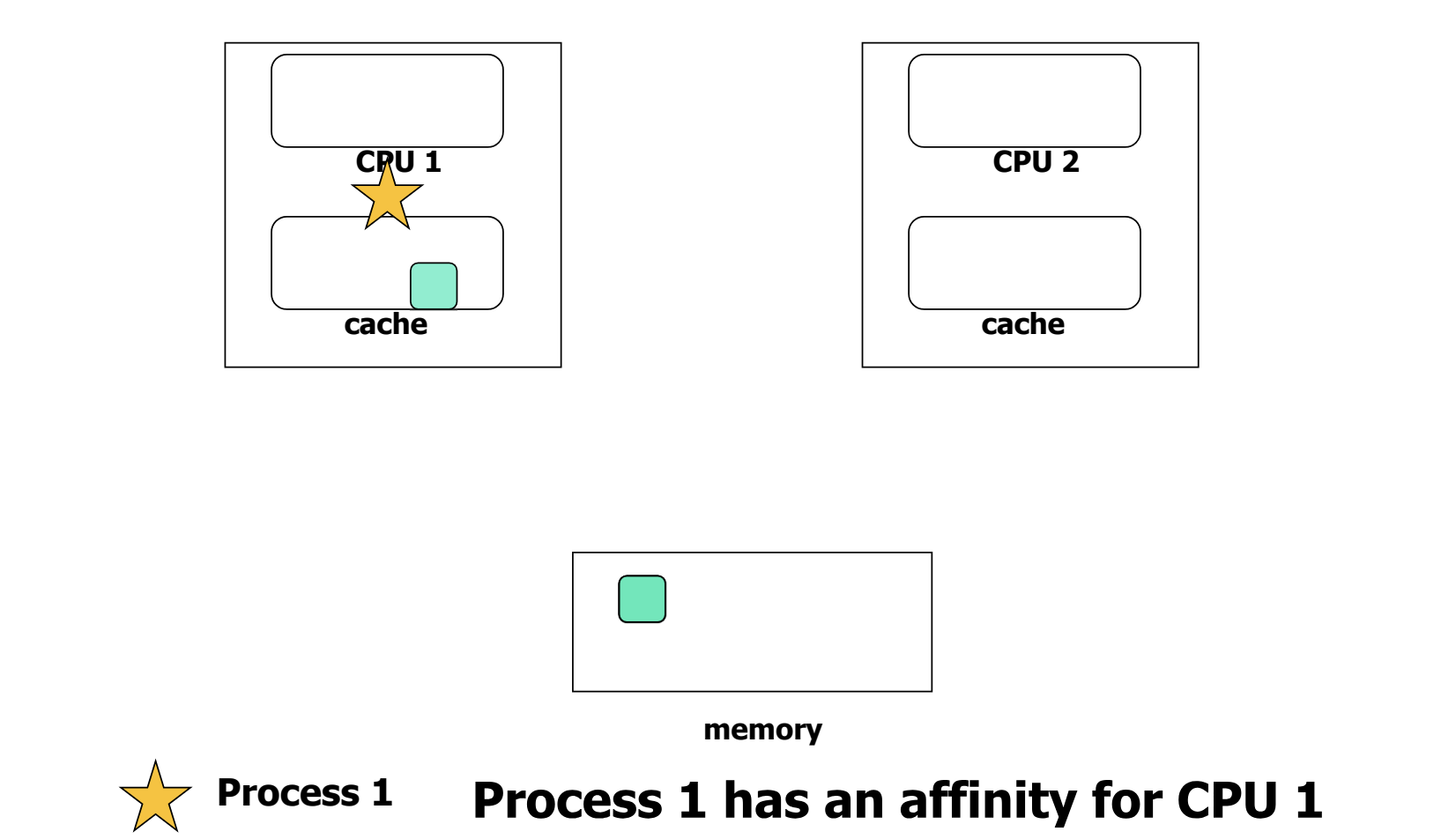
- task 가 CPU 1 에 할당된 모습이다. memory 에서 데이터를 caching 해 CPU 1 에서 실행 중이다.
- 만약 task 를 CPU 2 로 할당하게 되면, 데이터를 cache 에서 invalidation 하고 loading 하는 과정으로 인해 overhead 가 발생한다.
- 그러므로, 프로세스는 원래 실행되고 있던 CPU 와 친밀도가 있다고 할 수 있다.
- 친밀도에는 두 가지 종류가 있다.
- Soft affinity : task allocation 시 affinity 를 고려하지만, 무조건 보장되지는 않는다.
- Hard affinity : affinity 관계가 보장된다. 특히, 프로그래머가 task 를 특정 프로세서에 할당하고자 요청하는 system call 을 보낼 때 유효하다. LINUX 에서는 system call 이 잦기 때문에 hard affinity 를 이용한다.
Load Balancing
- 프로세서들이 task 들을 balanced 하게 나눠 가지도록 task 의 migration 을 시키는 방법이다.
- 두 가지 방식이 있다.
1. Push Migration - 하나의 task 가 프로세서들을 monitoring 하며, idle 한 프로세서에게 바쁜 프로세서의 task 들을 push 해준다.
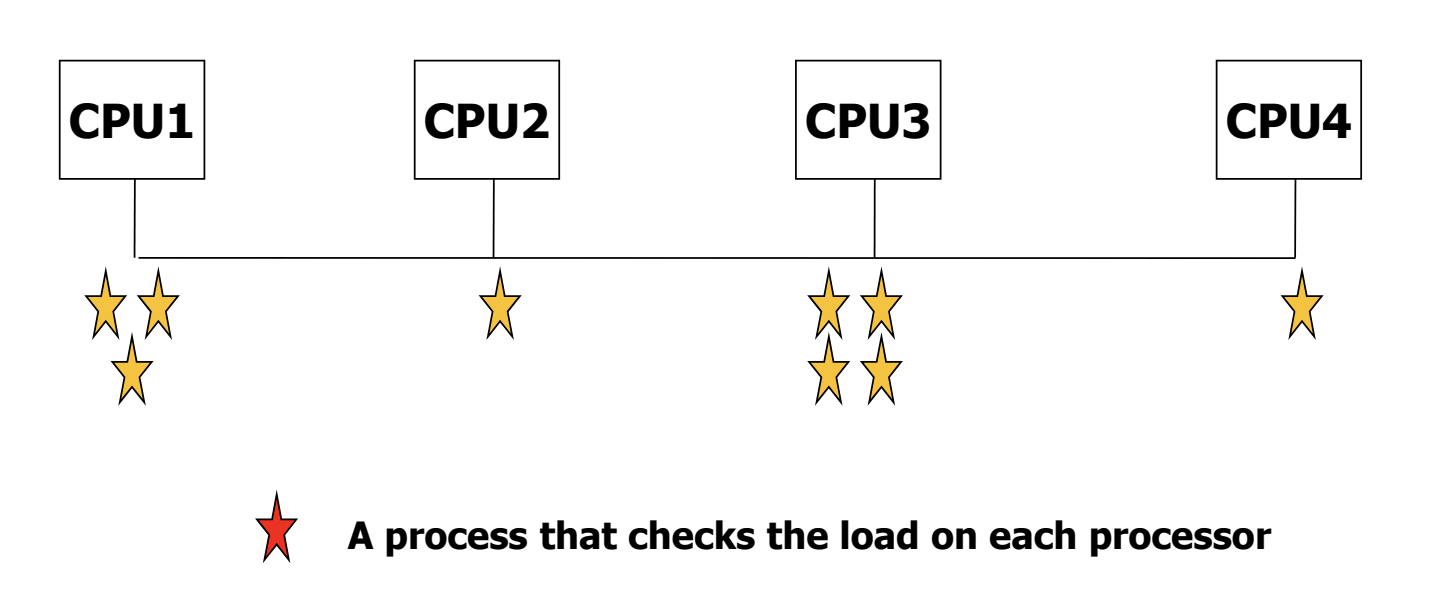
2. Pull Migration - idle 한 프로세서들이 직접 바쁜 프로세스들로부터 task 들을 pull 해 가져온다.
- LINUX 에서 사용하는 방법이다.
Thread Scheduling
- therad 들은 별도 실행되는 객체이기에 별도로 scheduling 된다.
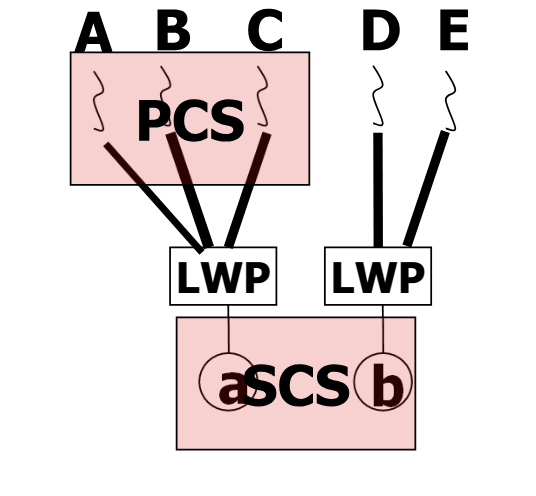
-
Local Scheduling : many to one model 에서, 한 kernel thread 에 mapping 된 user thread 간의 scheduling
-
Global Scheduling : kernel thread 중 하나를 선택하는, 흔히 말하는 scheduling
LINUX 2.6 Examples
- LINUX 의 scheduling 은 우선순위가 각각 다른 scheduling classes 에 기반한다.
- scheduling classes 는 우선순위가 높은 real-time 과 낮은 conventional 로 나뉜다.
- 140 개의 우선순위를, 0 ~ 99 는 real time 에, 100 ~ 139 는 conventional 에 배정한다.
- real time 과 conventional 이라는 두 개의 queue 로 구성된 multilevel queue 의 형태다.

- real time 내에서는 priority, conventional 내에서는 CFS, queue 간에는 priority scheduling 사용
- real time 의 우선 순위가 더 높기 때문에, real time 이 하나라도 있으면 queue 간의 비교에서 conventional 이 무조건 밀리게 되어, starvation 이 발생할 위험이 있다. 그렇기에 real time 을 많이 이용한 프로그래밍은 위험하다.
Real Time Processes
- real time class 는 SCHED_FIFO, SCHED_RR 으로 나뉜다.
- real time class 는 기본적으로 priority scheduling 을 사용하는데, 같은 우선순위인 프로세스를 처리하는 방식에 따라 나뉘는 것이다.
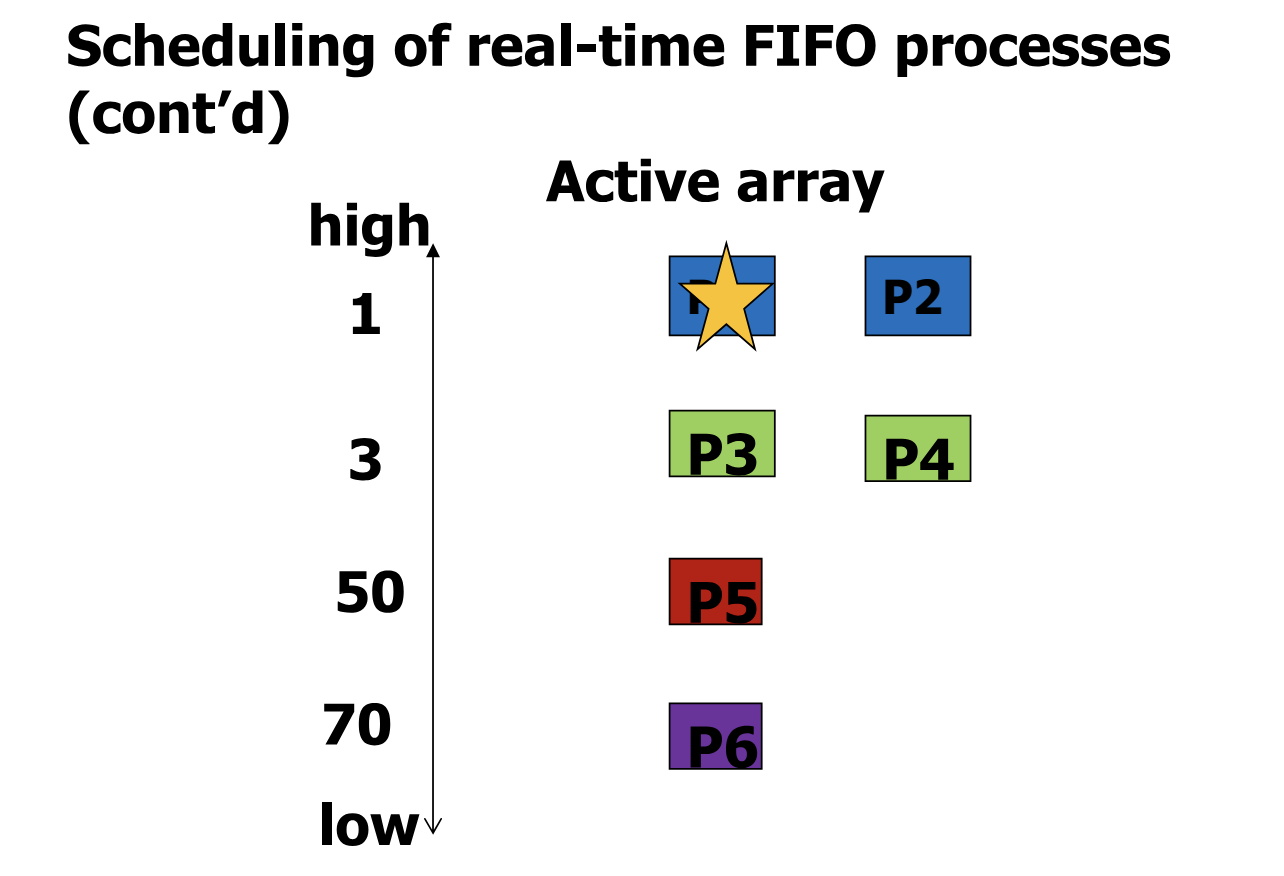
- SCHED_FIFO 의 scheduling 이다.
- 기본적으로 priority scheduling 을 사용하기에, P1 과 P2 가 최우선순위를 가진다.
- 이 둘 중에는 FIFO 를 사용해, P1 을 먼저 실행하고, P1 이 끝나면 P2 를 실행한다.

- SCHED_RR 의 scheduling 이다.
- 마찬가지로 우선 priority scheduling 을 사용하기에, P1 과 P2 가 최우선순위를 가진다.
- 이 둘 중에는 Round Robin 을 사용해, P1 과 P2 를 time quantum 을 두어 번갈아 가며 실행한다.
Conventional Classes
- conventional class 간에는 Completely Fair Sharing (CFS) scheduler 를 사용한다.
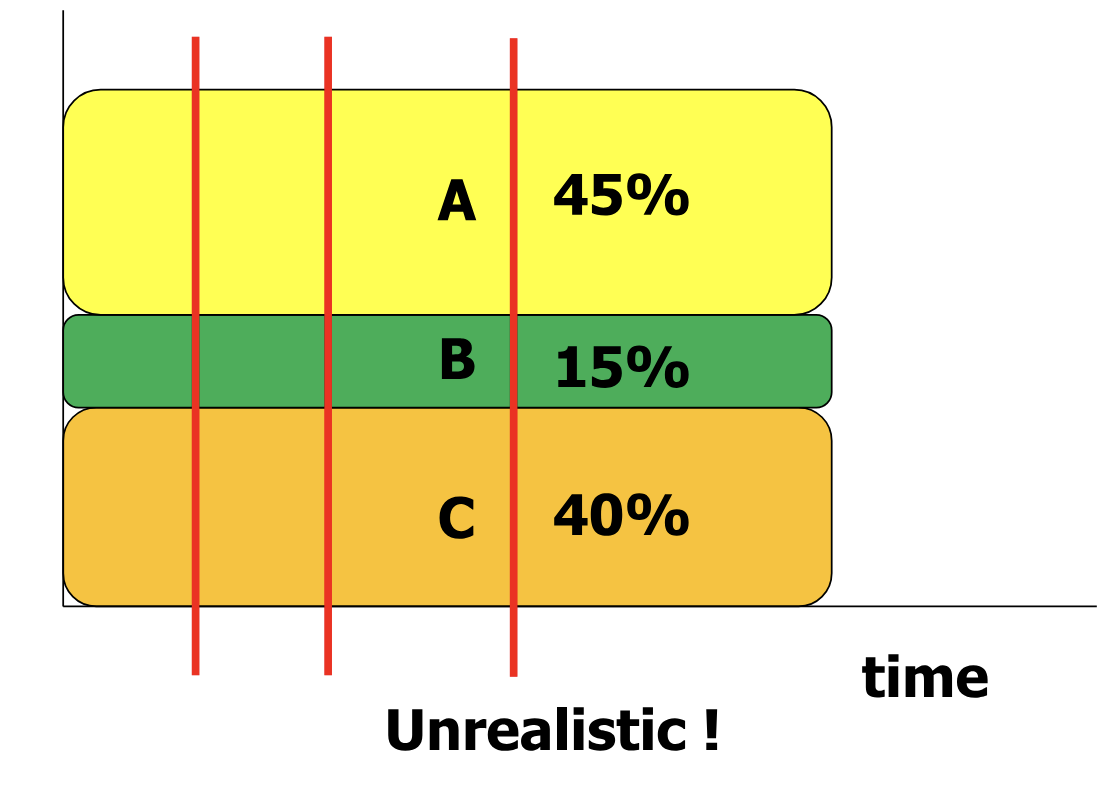
- 각 프로세스들은 각자의 우선순위에 기반해, 실행 시간의 일정 비율을 할당 받는다.
- CFS 의 목적은 시간선의 모든 부분에서 실제 실행 시간의 비율과 위의 비율을 같게 유지하는 것이다.
- 이는 CPU 가 하나이므로 불가능하다. 그래서 CFS 는 이 비율을 최대한 같게 유지하는 방향으로 scheduling 을 진행한다.
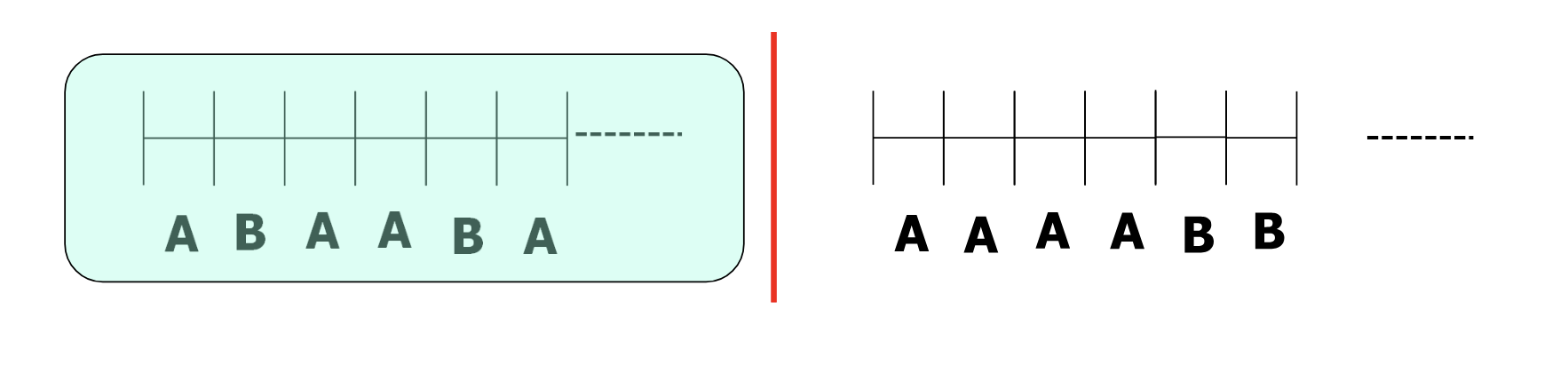
- A 와 B 가 할당받은 비율이 2:1 인 경우를 살펴보자.
- 왼쪽의 경우가 더 많은 시간선에서 위 비율을 유지하므로, CFS 는 왼쪽을 택한다.
- 이러한 scheduling 을 하는 방법은 virtual time mechanism 을 이용하는 것이다.
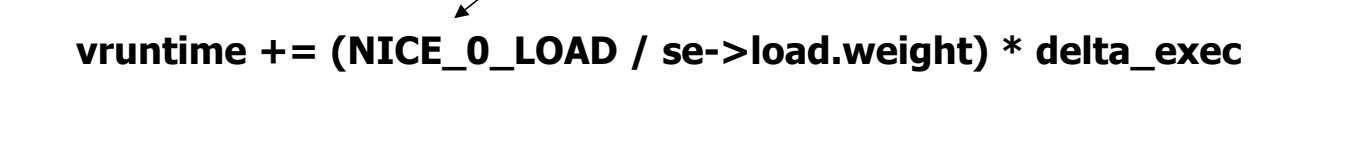
- 다음과 같은 식으로 표현되는 vruntime 변수를 이용한다.
- NICE_0_LOAD 는 1024 값을 가지는 상수
- se->load.weight 는 할당받은 비율
- delta_exec 은 실제 실행된 전체 시간이다.
- scheduling 시점마다 vruntime 이 작은 값을 골라 scheduling 한다.
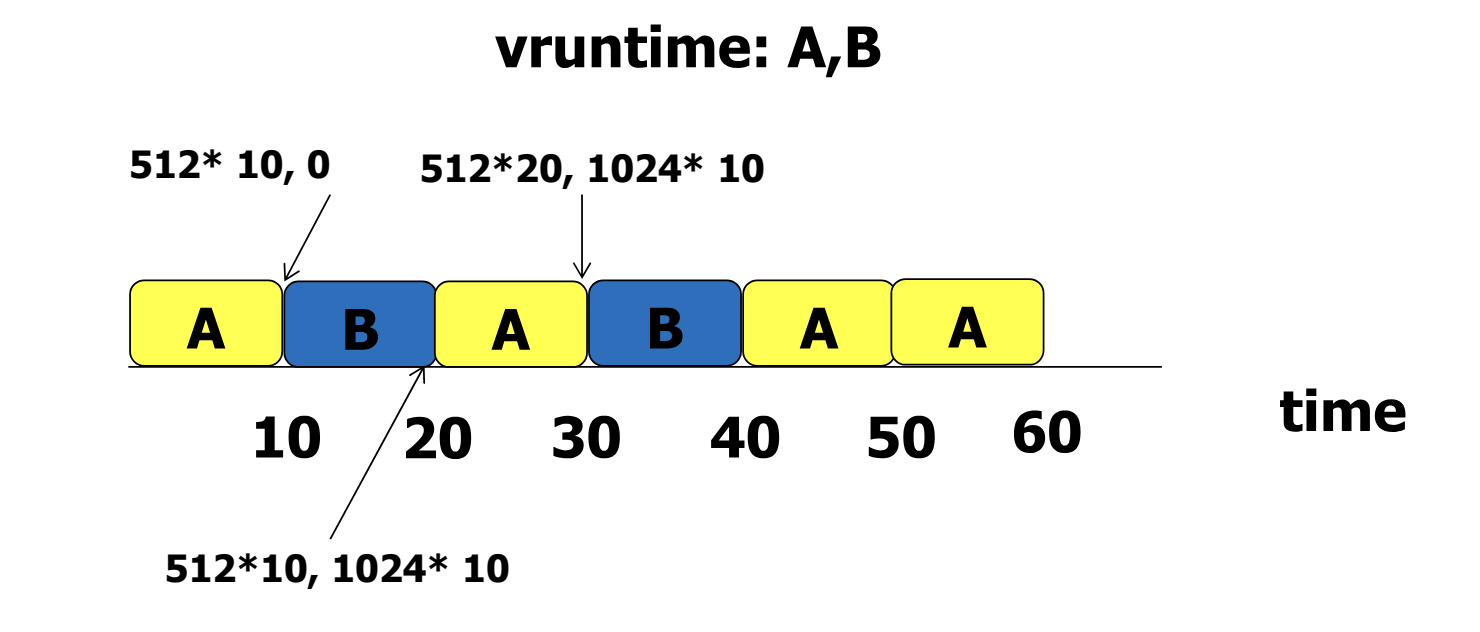
- 숫자로 적힌 A 와 B 의 vruntime 을 따라가보자.
- 세 번째 scheduling 에서 두 개의 vruntime 이 같은 경우가 있다. 이 때는 직전에 수행되지 않은 프로세스를 선택한다.

인하대학교 컴퓨터공학과