- 여러 개의 프로세스가 공통된 데이터에 접근할 때, 서로 간의 동기화가 없다면 문제가 생길 수 있다.
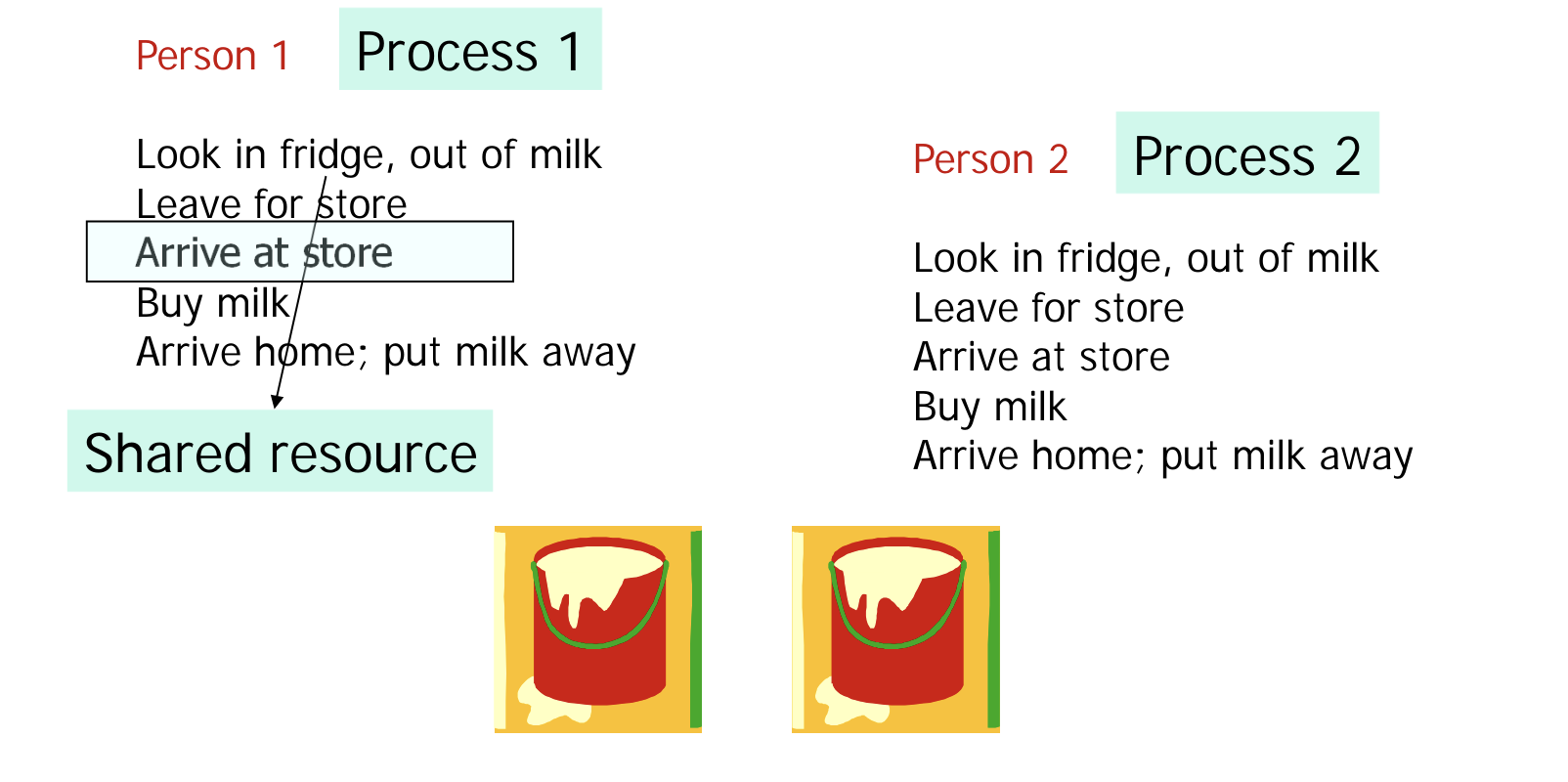
- too much milk problem 으로 불리는 예시다.
- 두 사람이 서로 다른 시점에서 우유가 없는 것을 확인하고, 우유를 사러 떠난다.
- 서로 간의 소통이 없다면, 필요했던 양보다 과도하게 우유를 사게 된다.
Process Synchronization
-
여러 개의 프로세스가 공통 영역을 동시에 접근하게 되는 시간을 critical session (CS) 라고 한다.
-
synchronization 의 부재로 여러 프로세스가 CS 를 동시에 access 상황은 race condition 이다.
-
race condition 은 프로세스 실행 중간에 scheduling 이 일어나는 preemptive 에서 발생한다.

-
위와 같이 race condition 이 발생하면, scheduling 순서에 따라 공유 변수의 값이 달라질 수 있기 때문에
data consistency 가 저해되는 문제가 발생한다. -
race condition 을 방지하기 위해, 한 프로세스 가 CS 에 접근하는 동안 다른 접근을 막아야 한다.
=> 이 방법을 locking method 라고 한다. -
locking method 의 기본 아이디어는 CS 에 대한 접근을 atomic 하게 실행하는 것이다.
Critical Session Problem
-
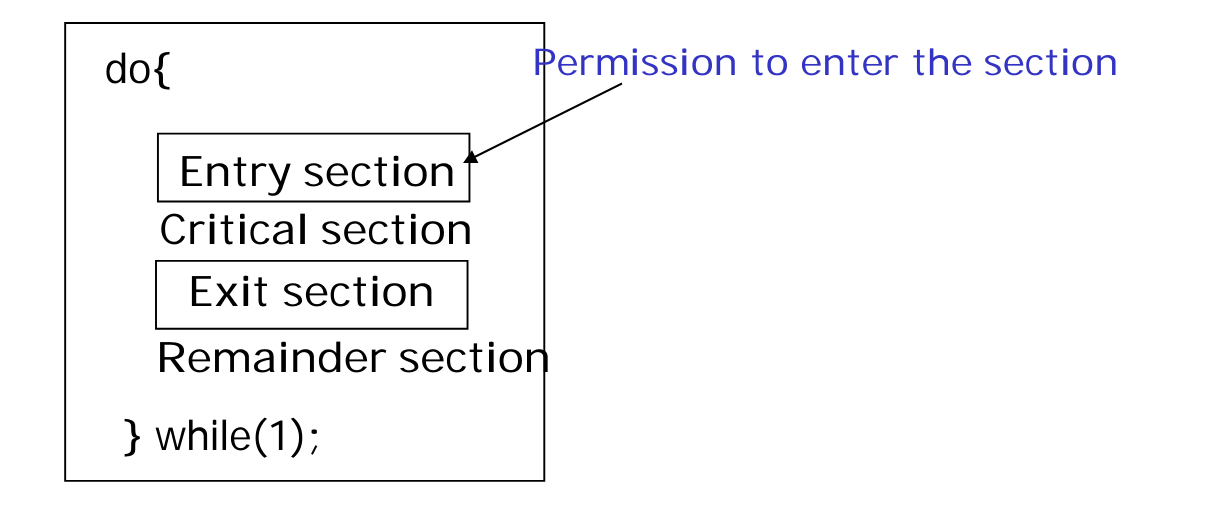
race condition 을 막기 위해, CS 의 위아래로 entry / exit section 이라는 코드를 삽입한다.
-
entry, exit section 이 만족해야 할 속성들은 다음과 같다
1. Mutual Exclusion
하나의 프로세스만이 CS 에 접근하도록 한다.
2. Progress
entry section 에서 CS access 를 기다리는 프로세스들이 있다면, 그 중 반드시 하나는 CS 에 입장할 수 있어야 한다. 즉, 대기 시간이 무한정 길어져서는 안된다.
3. Bounded Waiting
CS 진입 허용 횟수에는 한도가 있어야 한다. 다른 프로세스가 무한정 기다리는 상황을 방지하기 위함이다. -
이를 만족하도록 entry / exit section 을 구현하는 방법에는 여러 가지가 있다.
Peterson's Solution
- flag 와 turn 변수를 이용해 entry 와 exit 을 구현한 방법이다.
//entry
do {
flag[i] = true;
turn = j;
while (flag[j] && turn == j);
// critical session
flag[i] = FALSE;
} while (1);- 다음에 실행된 프로세스의 변수 값을 조절해 접근을 막는 방식이다.
- 이 방법이 어떻게 세 가지 속성을 만족하는 지 살펴보자
1. Mutual Exclusion
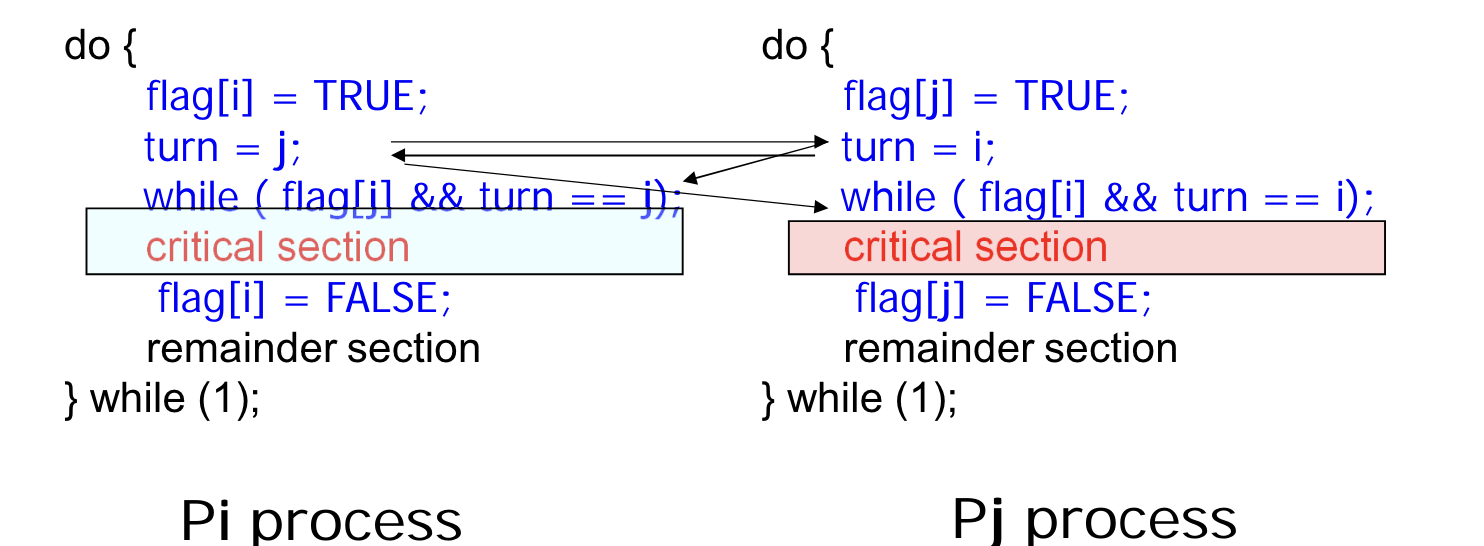
- 두 프로세스가 동시에 CS 에 접근한 상황을 가정해보자.
- Pi 에서는 turn 의 값이 i, Pj 에서는 turn 의 값이 j 여야 while 을 탈출해 CS 에 접근할 수 있다.
- 하지만, 같은 시점에서 turn 의 값이 두 개일 수 없기 때문에 모순이다.
=> Mutual Exclusion 을 만족한다.
2. Progress
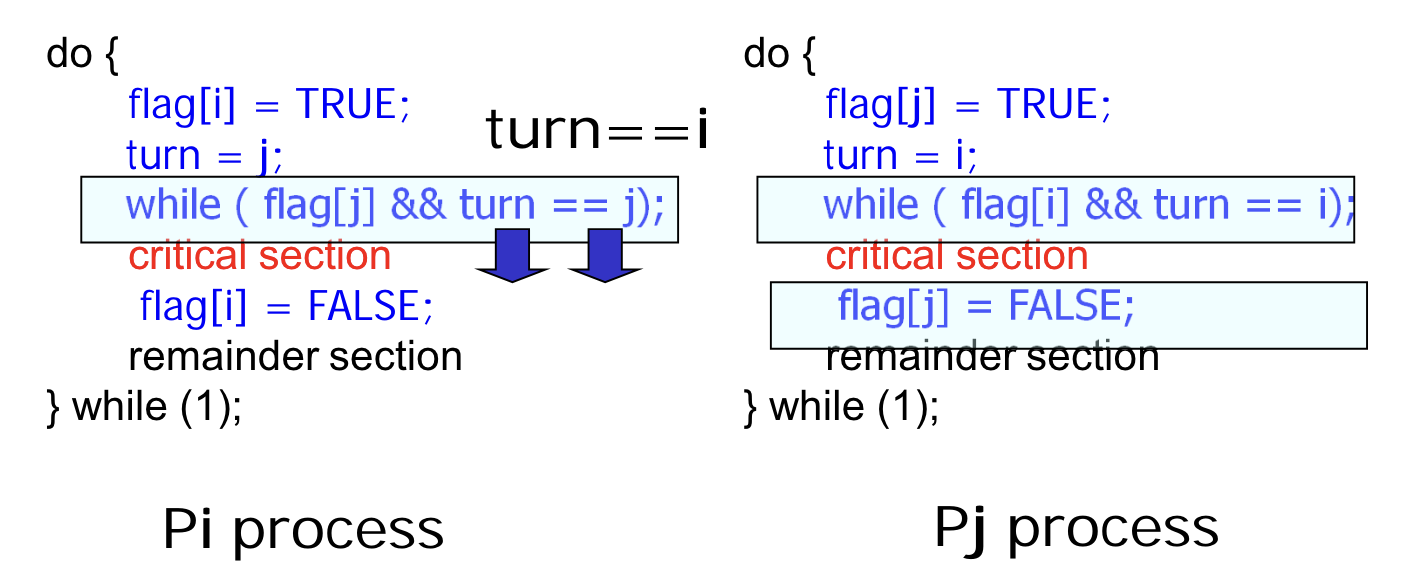
- Pi 가 while 문을 수행 중이고, CS 에 접근 가능한 상황을 가정하자.
- Pj 는 while 문을 수행 중이거나, CS 접근을 마치고 flag 를 FALSE 로 설정하는 단계일 것이다.
- Pj 가 while loop 을 수행 중이라면, turn == i 이므로 Pi 는 while loop 을 탈출할 수 있다.
- Pj 가 CS 를 탈출했다면, flag[j] == FALSE 이므로 역시 Pi 는 while loop 을 탈출할 수 있다.
- 즉, 둘 중 하나의 프로세스가 CS 밖에 있다면 다른 프로세스는 CS 에 접근할 수 있는 것이다.
=> Progress 를 만족한다.
3. Bounded Waiting
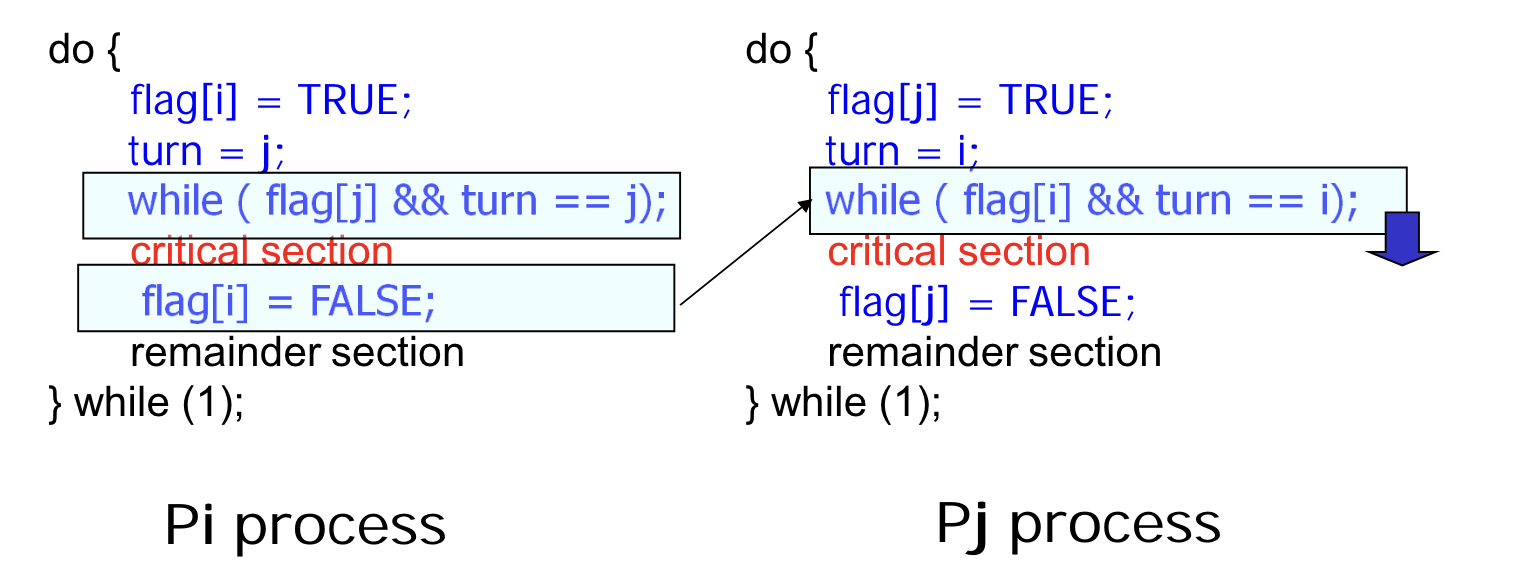
- Pi 가 CS 접근을 마친 상황을 가정하자.
- flag[i] 의 값이 FALSE 로 설정되어, while loop 에서 대기 중이던 Pj 가 CS 에 접근할 수 있다.
- 한 프로세스가 접근을 마치면, 다음 프로세스가 접근할 수 있도록 보장해주는 것이다.
=> Bound waiting 을 만족한다. - 속성은 만족했지만, 다음으로 와야 하는 프로세스를 명시해야 한다는 단점이 있다.
- Peterson's solution 은 위와 같이 모든 속성을 만족하지만, 코드가 길다는 단점이 있다.
- 또한, 대기 중인 프로세스가 while loop 을 계속 반복해야 하는 busy waiting 도 단점이다.
Hardware Support for Synchronization
- OS 에서 제공하는 atomic instruction 을 이용해 구현을 간소화 하는 방법이 있다.
TestAndSet()
boolean TestAndSet (boolean* target) {
boolean rv = *target;
*target = TRUE;
return rv;
}- 전달받은 target 의 값을 TRUE 로 바꾸면서, 반환값은 target 그대로 내보내는 연산이다.
- entry 와 exit 의 구현은 다음과 같다
do {
while (TestAndSet(&lock));
//critical session
lock = FALSE;
} while (1);- lock 값은 CS 의 locking 여부를 나타내는 변수로, 기본값은 FALSE 다.
- lock 값이 TRUE 로 입력되면, while 의 조건문과 lock 여부 모두 TRUE 가 된다.
=> CS 로의 접근이 차단된다. - lock 값이 FALSE 로 입력되면, while 의 조건문은 FALSE, lock 여부는 TRUE 가 된다.
=> 자신은 CS 에 접근하고, 다른 접근은 막는 것이다. - 만약 TestAndSet() 이 atomic 하지 않다면, target 값이 set 되기 전에 context switch 가 일어날 수 있다. 이 경우 다른 접근을 차단하지 못해 mutual exception 이 보장되지 못할 것이다.
Swap
void swap (boolean* a, boolean* b) {
boolean temp = *a;
*a = *b;
*b = temp;
}- 우리가 흔히 알고 있는 swap 연산이다.
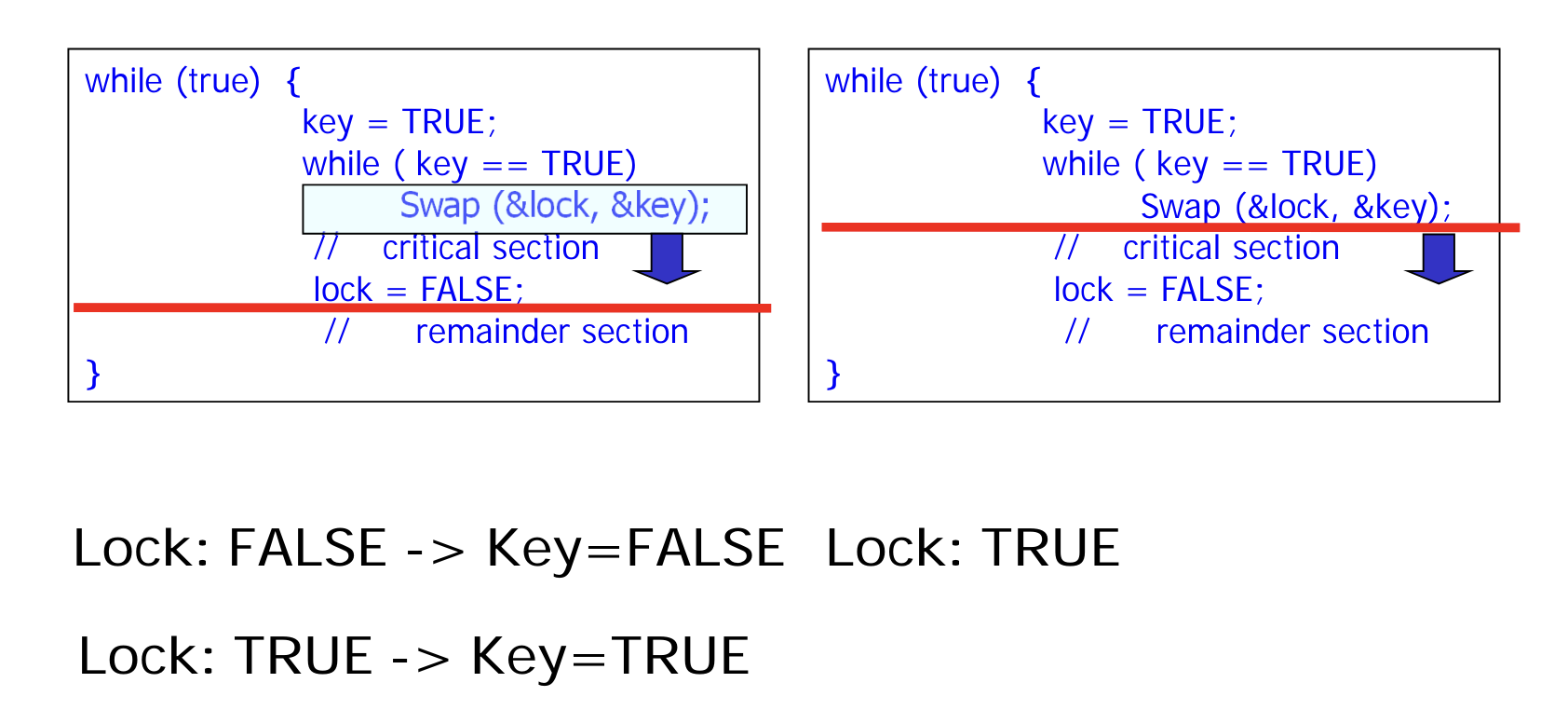
- key 값은 기본적으로 TRUE 로 설정된다.
- lock 이 TRUE 인 동안에는 key 와 lock 모두 TRUE 이므로, while loop 을 돈다.
- lock 값이 FALSE 가 되면, swap 으로 인해 key 가 FALSE 가 되어 while loop 을 탈출해 CS 에 접근할 수 있게 된다.
- 위 두 연산들은 bounded waiting 을 보장하지 못한다는 단점이 있다.
- Peterson's 와 달리 다음 실행 순서를 명시하지 않고, 이 결정을 scheduler 에게 맡기기 때문이다.
=> 어떤 프로세스가 다음으로 실행될 지 모르기 때문에, 진입 횟수의 bound 를 설정할 수 없게 된다. - 이에 대한 해결책으로 application level 에 waiting array 를 만들고, 이 순서대로 실행되도록 조절하는 방법이 있다.
Semaphores
- semaphore 라는 정수 값을 이용하는, sychronization 의 가장 보편적인 방법이다.
Semaphore S = 1; // initialized to 1 for mutual exclusion
//entry section
wait(S) {
while (S <= 0);
S--; // S is 0 therefore, other accesses are blocked
}
// critical session
// exit section
signal(S) {
S++;
}- wait() 과 signal() 이라는 atomic operation 으로 CS 를 감싼다.
- 인자로 받는 S 가 semaphore 변수고, 각 CS 마다 각각의 semaphore 를 선언해야 한다.
- semaphore 에는 두 종류가 있다.
- Counting Semaphore : 값의 제한이 없다. => mutual exclusion 보장 못함 (wait, signal 수행 안됨)
- Binary Semaphore : 0 또는 1 만을 값으로 가질 수 있다.
=> mutual exclusion 을 보장하며, 그렇기에 mutex 라고도 불린다.
- 이 방식에도 busy waiting 이 일어난다는 단점이 존재해, 구현을 수정해 이를 해결한다.
Semaphore Without Busy Waiting
- 프로세스를 대기시키는 방법을 바꾸는 것이다.
- while loop 을 돌며 대기하는 것 대신, 프로세스 자체를 waiting state 로 바꿔버리는 것이다.
- waiting state 의 프로세스들이 대기하는 waiting queue 를 만들고, 두 개의 연산을 사용해 프로세스들을 넣고 뺀다.
- block() : 프로세스를 waiting state 로 만들고 waiting queue 에 삽입
- wakeup() : waiting queue 에서 프로세스를 선택해 ready queue 로 올린다.
- 이전의 semaphore 와 구현 방법이 달라진다.
// semaphore 이 구조체로 선언됨
typedef struct {
int value; // semaphore 값
struct process * list; // bounded wait 을 보장하기 위한 waiting list
} semaphore;
// wait 함수
wait(semaphore* S) {
S->value --;
if (S->value < 0) {
add process to S->list;
block();
}
// signal 함수
signal (semaphore* S) {
S->value++;
if (S->value <= 0) {
remove process P from S-> list;
wakeup(P);
}- 이러한 방식은 busy wait 을 해결하지만, waiting state 로의 전환으로 인한 overhead 가 발생한다.
- 그러므로, 긴 대기 시간을 가질 때는 위의 방법이, 짧은 대기 시간을 가질 때는 busy wait 을 하는 semaphore 이 효과적이다.
- LINUX kernel 에서 사용하는 race condition 방지책들을 정리하자면 다음과 같다.
- atomic operations
- semaphores without busy wait
- semaphores with busy wait
- scheduling 자체를 막는다.
- preemption 을 막아 context switch 를 차단
=> 4, 5 는 강경책으로, 권장되지 않는다.
