Generative Pretrained Transformer (GPT)
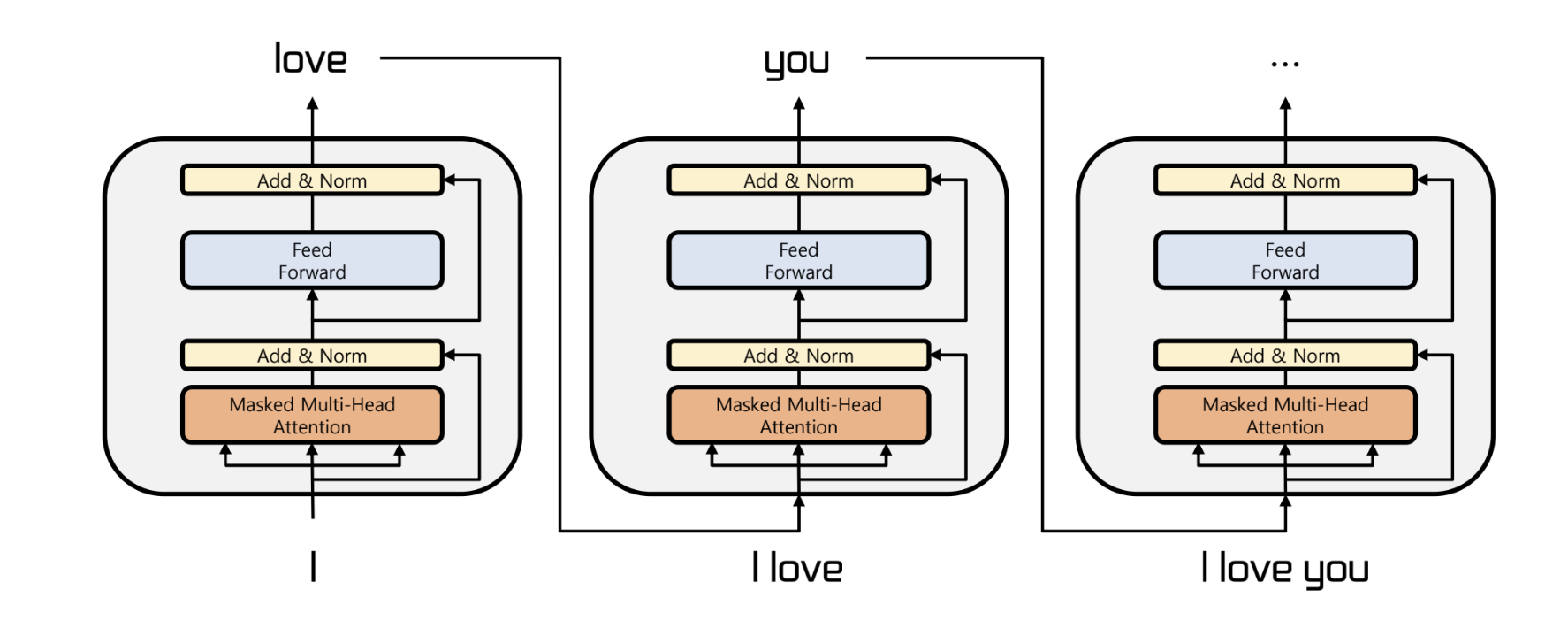
- transformer 의 decoder 만을 이용해 만들어짐
- LM 을 pretrain 한 후 task 에 전이학습 수행
- 이전의 단어들이 주어지면 다음 단어를 예측하는 방식
- fine tuning 을 진행할 때도 이 방식을 따라야 한다
- 뒤 쪽의 단어들에 masking 처리가 되기 때문에, 단방향 훈련만이 가능하다
BERT
- transformer 의 encoder 만을 이용한 양방향 LM
- NLU 에서 매우 좋은 성능
- 하지만, 생성 task 에는 적용 불가능
- GPT 보다 적은 parameter 로 뛰어난 성능
- BERT 의 훈련 방식에는 두 가지가 있다.
- Masked Language Model (MLM) : 입력에서 일부 단어를 마스킹하고, 그 단어를 예측
- Next Sentence Prediction (NSP) : 두 문장이 연속해서 나오는지 아닌지를 예측
Masked Language Model
- 일정 비율의 토큰을 가린 채, 문장을 복원하도록 학습하는 방법
- GPT 같은 단방향 LM 에서 벗어나 양방향 LM 생성
- 다른 LM 과의 차이?
- 기존 LM 은 다음 timestep 의 토큰을 예측
- MLM 은 현재 timestep 의 가려진 현재 위치의 단어를 예측
- "I <mask> to <mask> home" -> "I want to go home"
- 양방향 학습을 통해 mask 앞뒤의 단어를 분석하고, 이를 토대로 추론
- 학습과 추론의 괴리를 없애기 위해서 전체 토큰 중 15%의 토큰만 추론 대상으로 선정
Next Sentence Prediction (NSP)
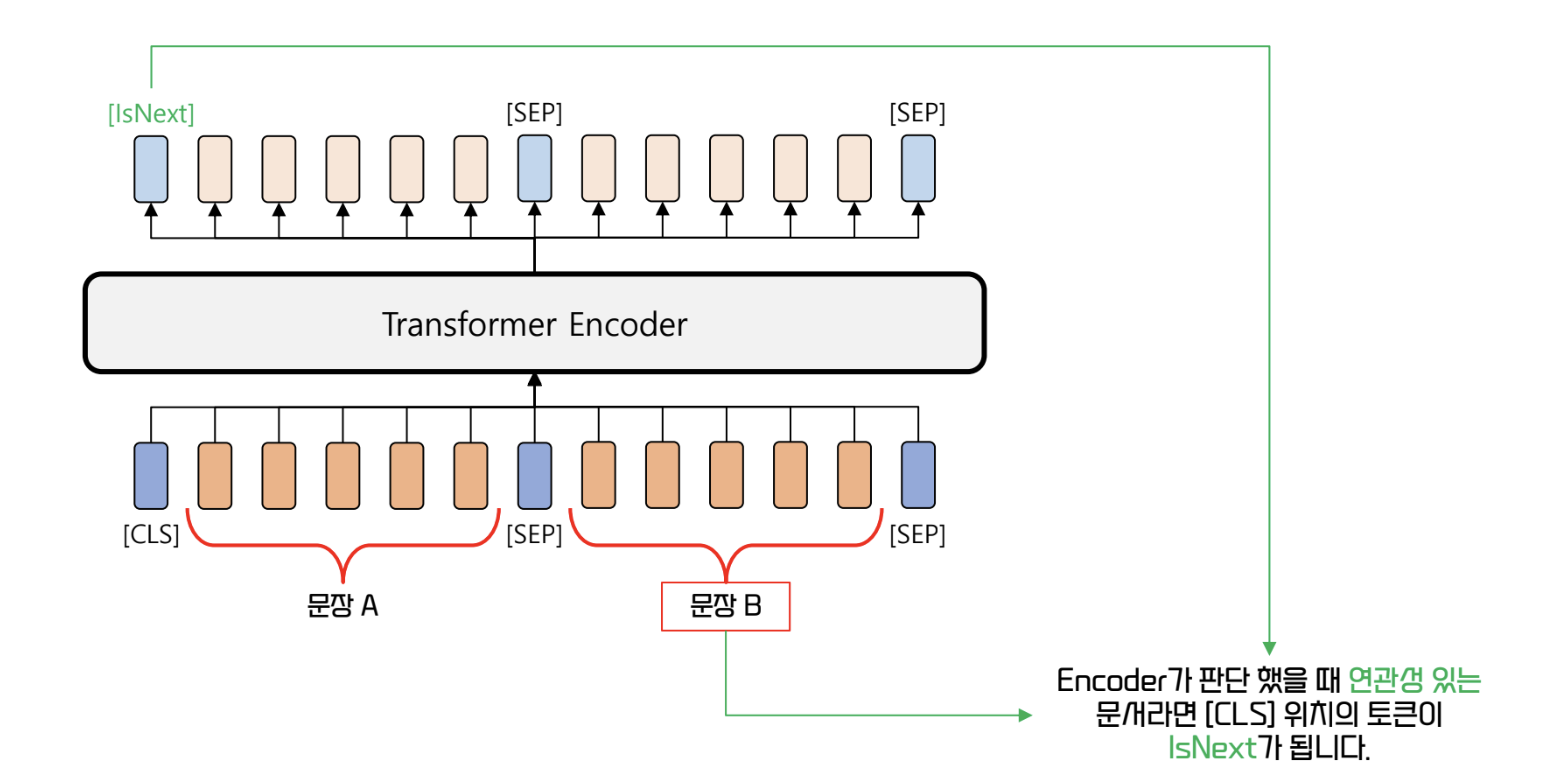
- 두 문장이 연속해서 나오는지 예측
- Question Answering, Textual Entailment task 에서 문장 사이의 관계 파악은 중요하다
- 훈련 시 두 문장을 임의로 선택하고나, 50% 확률로 원래 연결되어있던 문장을 선택해 훈련
- 연결된 문장은 <IsNext>, 그렇지 않은 문장은 <NotNext> 로 훈련시킨다
Embedding Combination
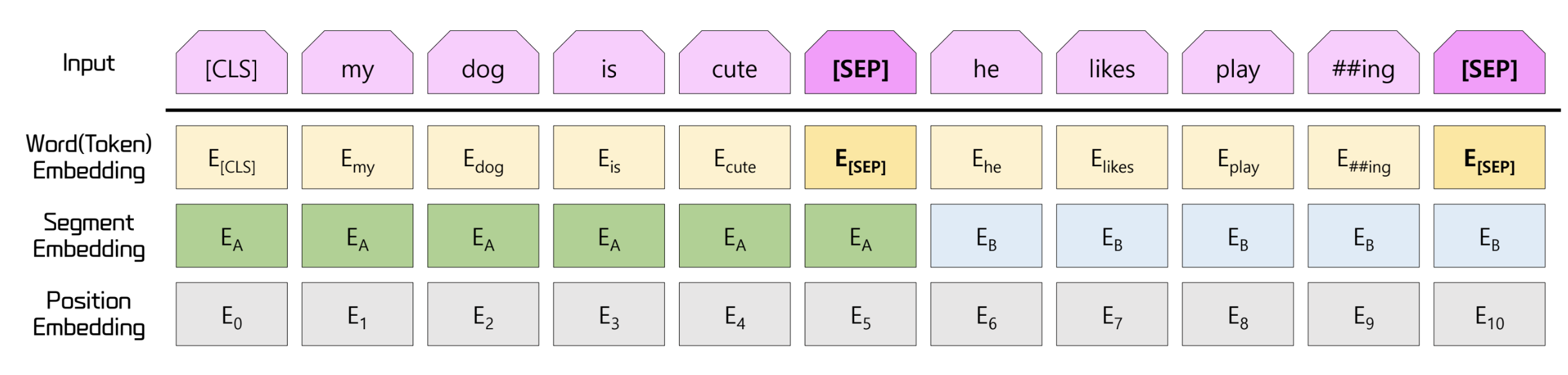
- 기존 transformer 에는 word embedding, positioal embedding 만 존재
- BERT 에서는 이에 추가로 단어의 소속 문장을 나타내는 segment embedding 도 함께 수행
BART
- encoder 와 decoder 를 모두 사용하여 사전 학습을 진행
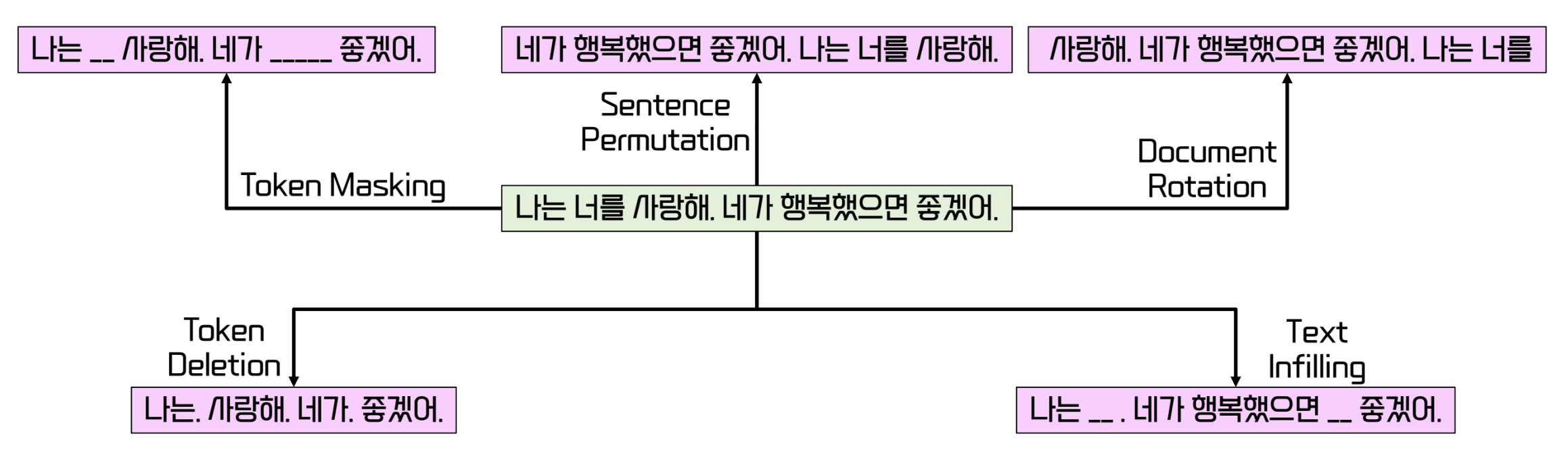
- BERT 처럼 입력 문장에 노이즈 추가
- encoder 로 부터 정보를 받아 decoder 에서 auto regressive 하게 문장을 복원
- encoder 와 decoder 를 모두 사용해서 등장한 장점들:
- mask 이외의 유연한 노이즈 추가 가능
- 하나 이상, 심지어 0개의 단어를 mask 에 적용 가능
- attention 을 통한 추론 수행 가능
Pretraining
- train 과의 차이점?
- pretrain : 대규모 데이터에서 일반적인 패턴과 지식을 학습하는 과정
- train : 사전 학습된 모델을 특정 작업에 맞게 가중치를 조정하는 과정

인하대학교 컴퓨터공학과