Attention is All You Need
- 이제는 RNN 기반 NLP 를 사용하지 않는다!
- Transformer 는 self attention 기법을 이용해 text embedding 을 진행
attention :
self attention : ->
=> 모든 단어들이 서로에게 Q, K, V 의 역할을 동시에 수행Transformer 는 내적과 가중합을 사용해 attention 값을 도출
Transformer 구조
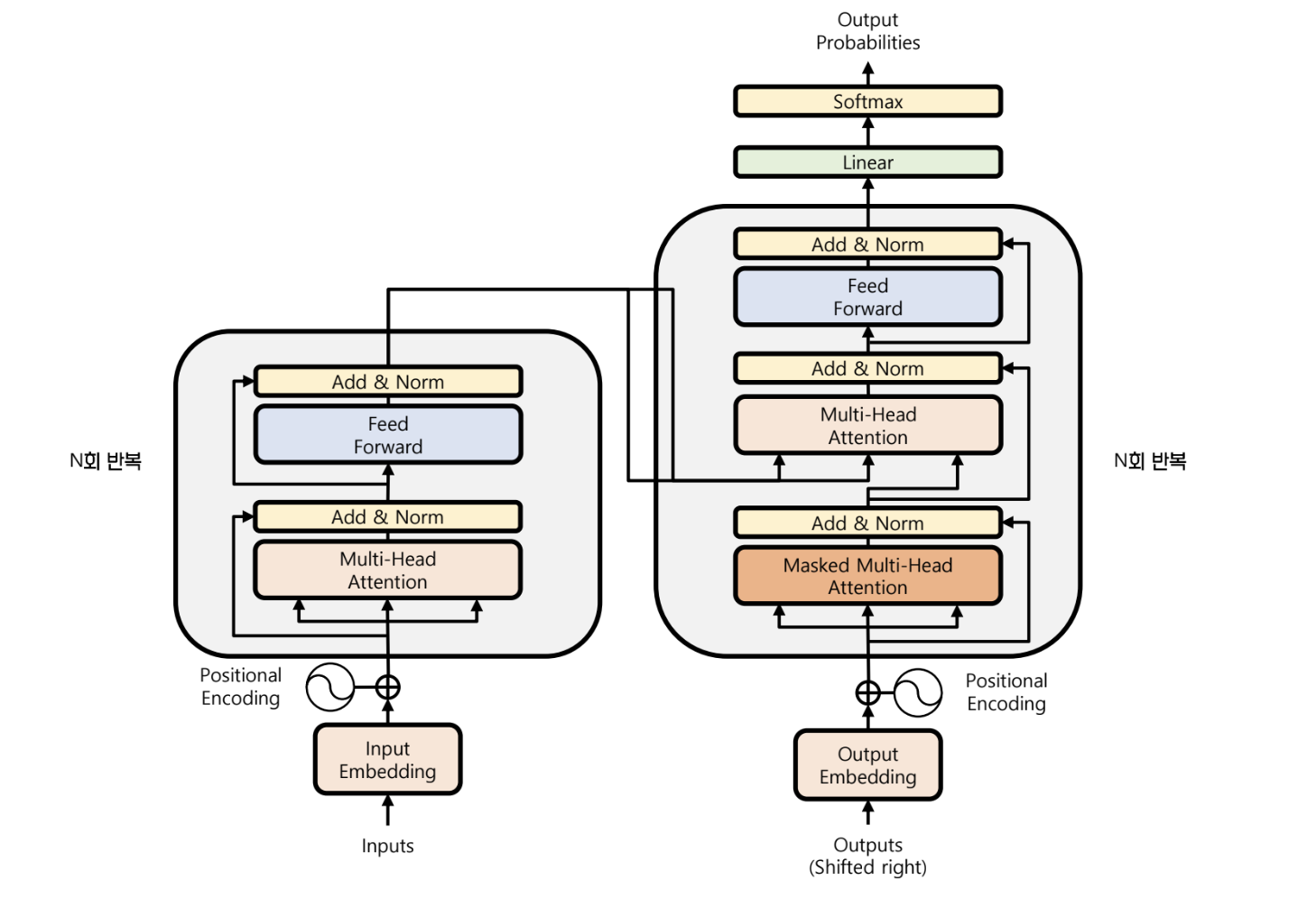
- Seq2Seq 구조를 띈다
- RNN 구조 없이 linear layer 들이 쌓여있다
입력
- input data dimension : (batch_size, timesteps, vocab_size)
- 각 단어는 one hot encoding 되어있는 상태
Encoder
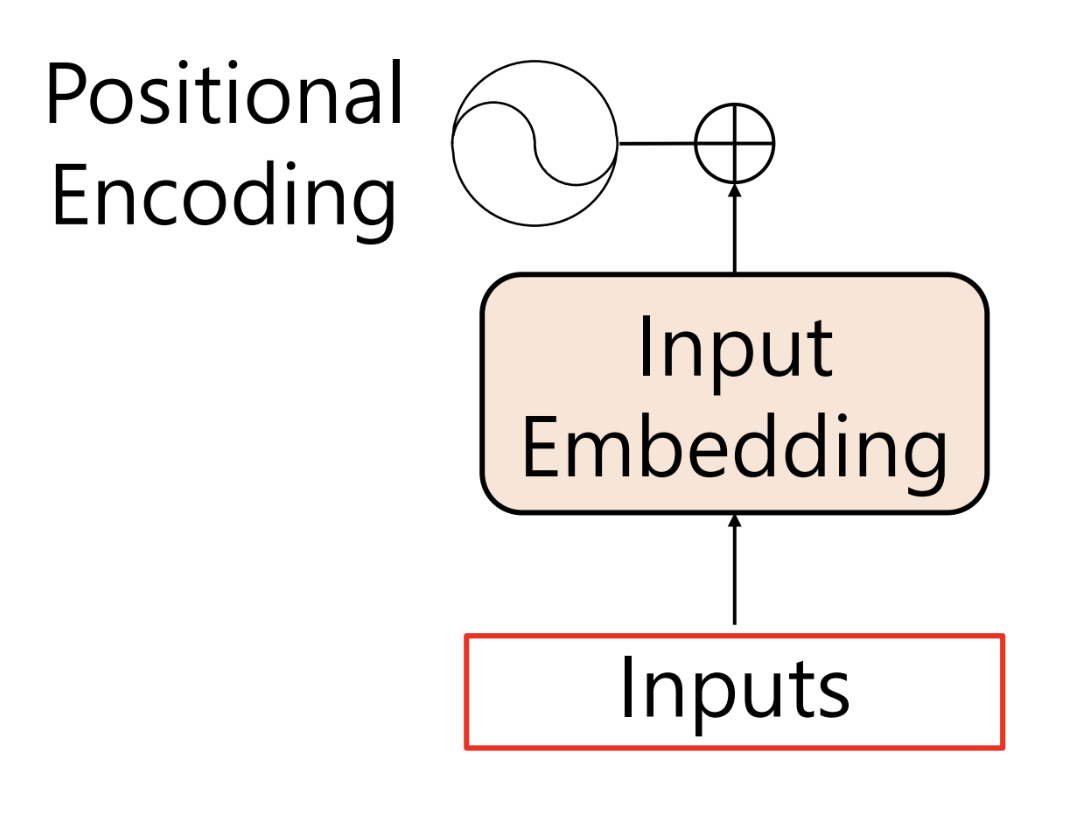
Positional Embedding
- 앞서 말했듯이, transformer 는 linear layer 로 구성
- linear layer 는 데이터의 순서를 고려하지 않는다
- transformer 는 대신 positional embedding 이라는, 단어의 순서를 학습하는 layer 를 가진다
- 단어의 위치를 ohe 하고 linear layer 를 통과 시키면 positional embedding vector 생성
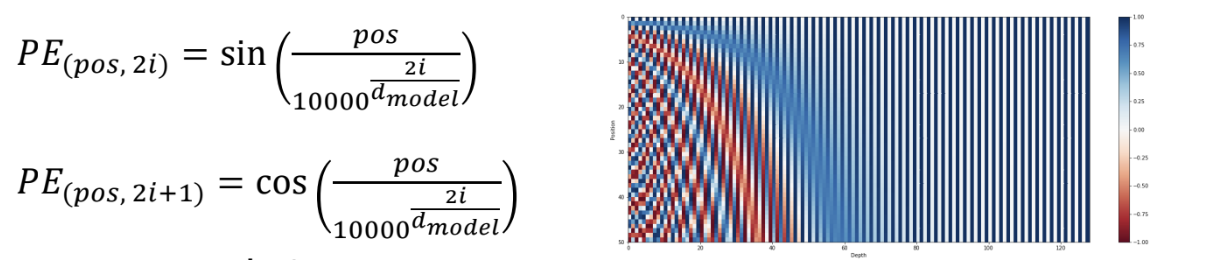
- positional encoding 은 positional embedding 의 내적 과정을 없애고 값을 더하기만 함
- 값을 더할 때는 주기함수 (논문에서는 sin, cos) 를 적용함
- 주기가 겹치지 않게 하기 위해 2개의 주기함수 사용
Self Attention
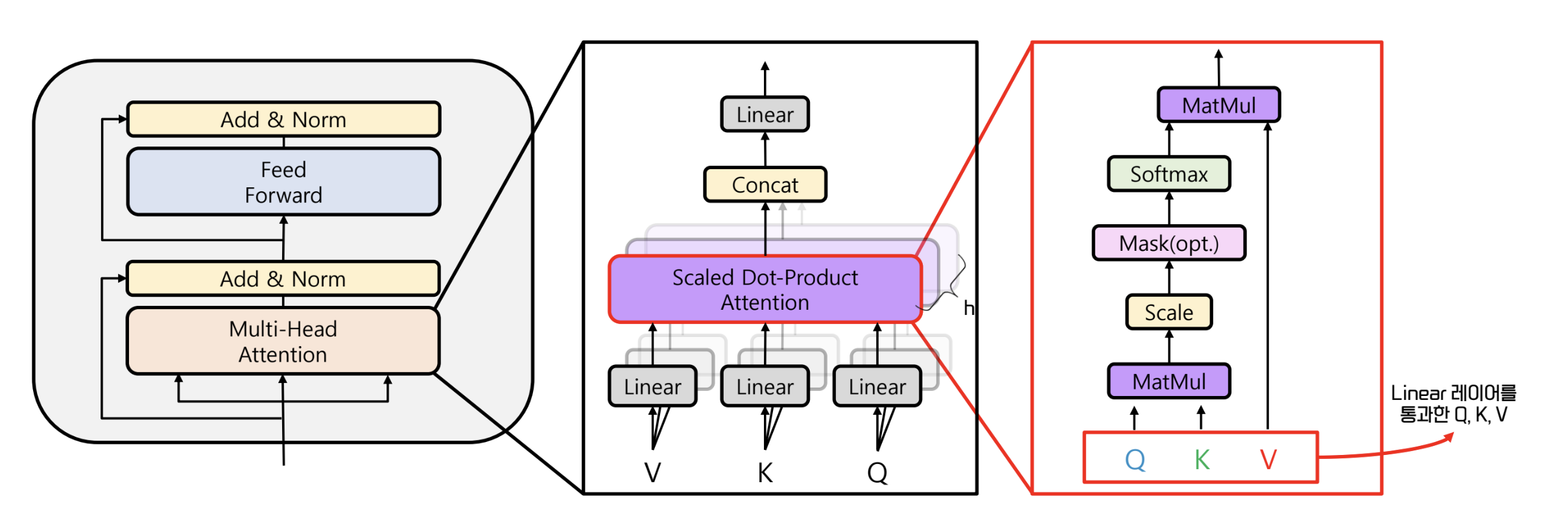
- 문장 내의 단어들 사이의 관계성, 유사도에 대한 학습을 진행하는 layer
- 위의 관계를 통해 어떤 단어에 주목 (attention) 해야 하는지 학습
- 단어 간 관계를 학습하기 위해 내적을 사용하는데, 이는 model parameter가 사용되는 연산은 아니다
- 따라서 내적 할 단어의 embedding vector 를 선형변환하는 linear layer 를 둔다
- 이 linear layer 가 학습의 대상이 된다
- Q, K, V 는 embedding layer 에서 나온 벡터로 시작한다.
- 이에 linear transformation 을 거친 결과도 Q, K, V 라고 칭한다
- RNN 기반 attention 에서는 였다.
- Q : dec / K, V : enc
- 하지만, transformer 에서는 각각이 linear transformation 을 거쳤기 때문에
- 모두 다르기 때문에 각자의 역할을 하도록 학습을 시키게 된다
- Q : 질문 / K : 질문에 대한 답 / V : 내적 결과의 의미 학습
- Q 와 K 의 내적은 다음과 같다. 는 linear layer 의 차원이다
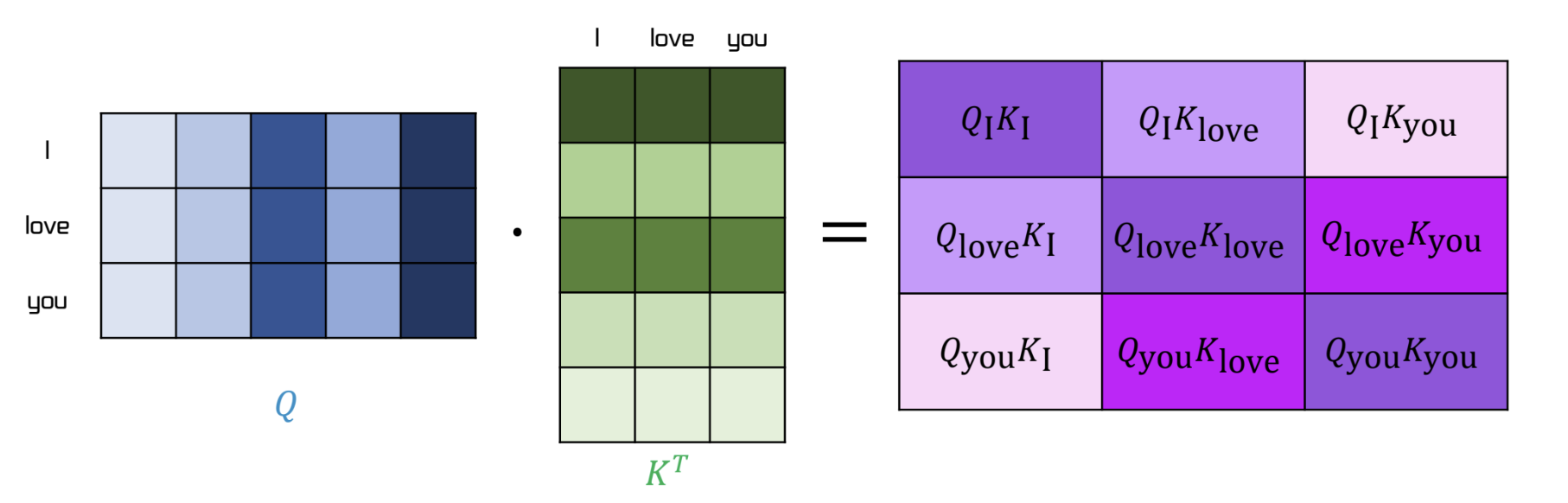
- 의 결과는 scaler 에서 로 나누어진다.
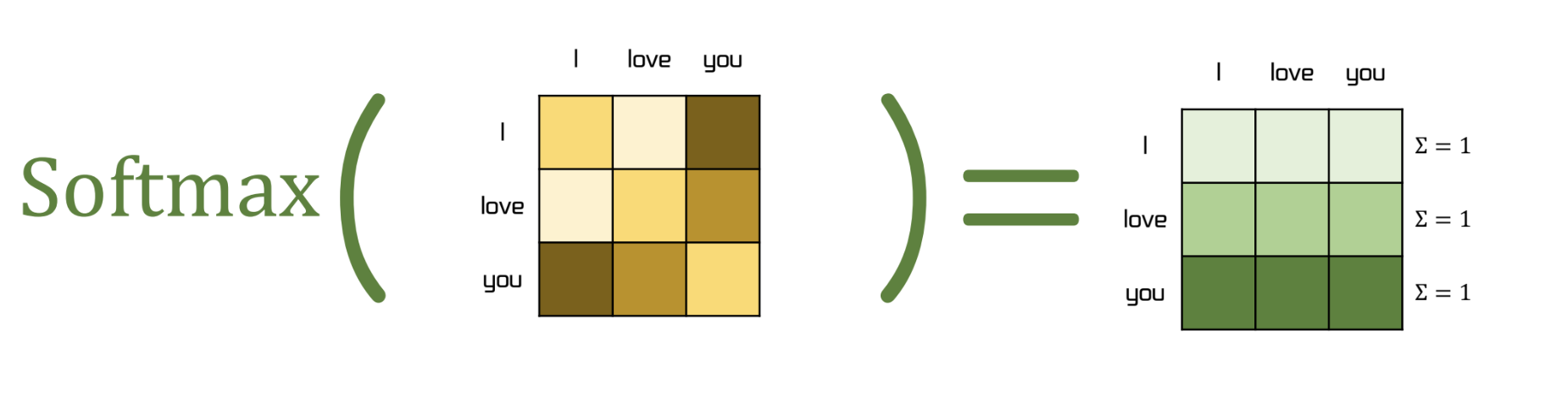
- 이후 softmax 가 수행되고, 이 결과를 energy 라고 한다. 이 때, softmax 는 dim=1 로 수행
Multi Head Attention (Encoder)
- 단어에 대한 가중치를 다각도로 보기 위함
- CNN 의 channel 과 유사한 개념
- 이를 위해 정보의 소실을 어느정도 감수하고 로 차원을 축소했다
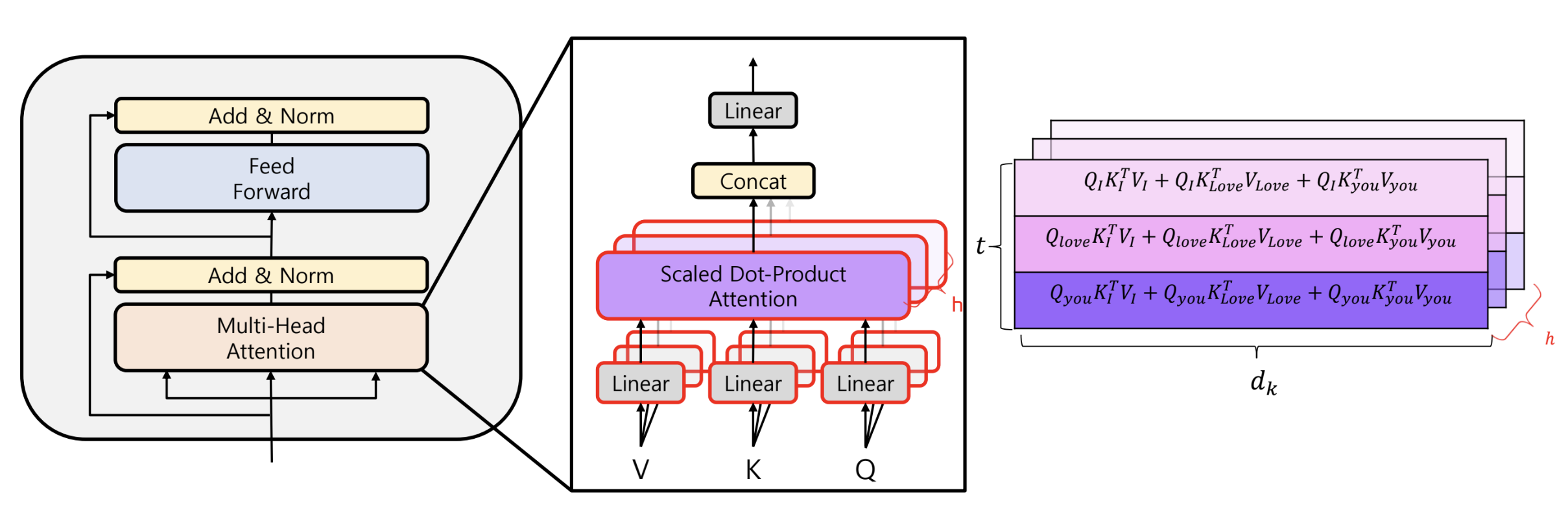
- 각 head 는 각 단어들에 대한 attention 을 별도로 분석
- 이후 concat 에 의해 각 head 의 분석을 종합
- multi head attention 이후 add & norm 은 skip-connection 과 layer normalization 진행
Decoder
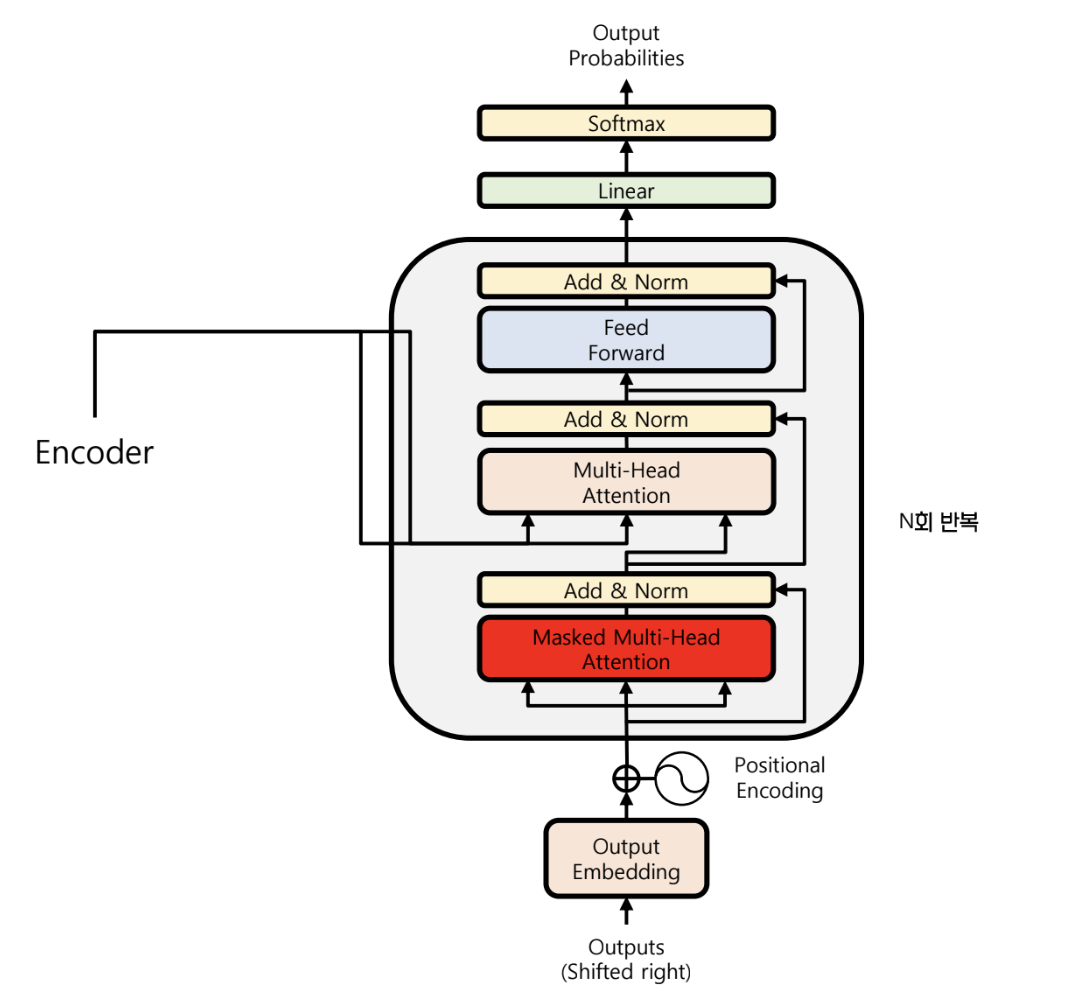
- encoder 에서 출력된 context vector 를 입력받는다
Masked Multi Head Attention
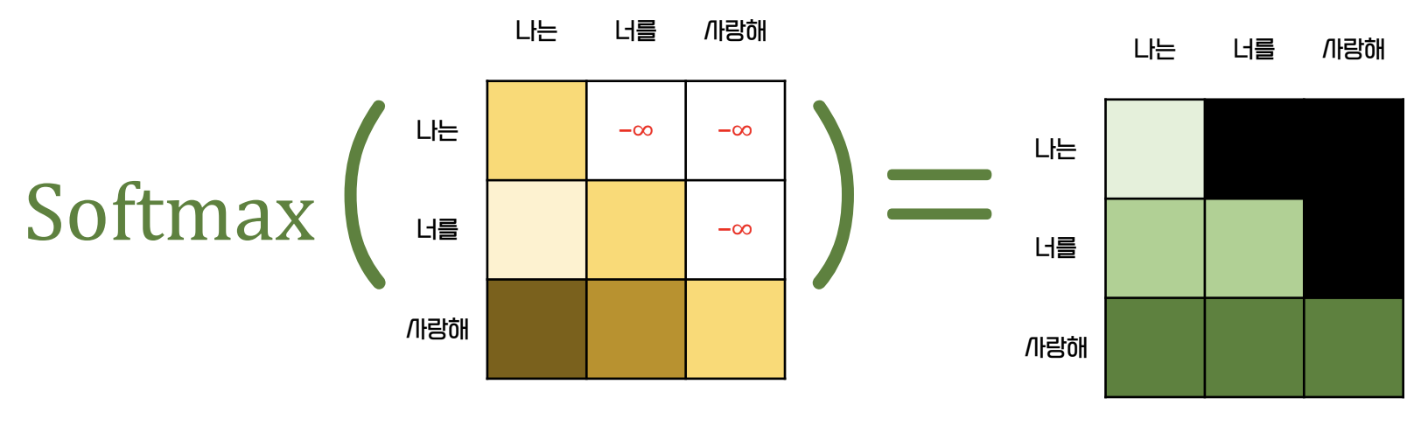
- Multi head attention 을 적용하면, 뒤에 등장할 단어들을 모두 아는 상태로 attention 이 수행됨
- 이를 방지하기 위해 decoder 에서는 masking 을 수행한다
- softmax 통과 전 뒤 쪽의 단어들을 모두 같은 매우 작은 값으로 바꿈
- energy 가 0으로 되어 뒤쪽의 단어들에 대한 attention 은 구해지지 않는다
Multi Head Attention (Decoder)
- masked multi head attention 에서는 self attention 이 일어났다.
- 여기서는 encoder 의 단어들 중 어느 단어에 집중하는지를 분석한다.
- encoder 의 context vector 를 입력 받고, 이를 K, V 로 사용한다
Inference
- RNN 계열 모델과 다르게 한번에 여러 개의 sequence 가 들어간다

- RNN 보다 훨씬 정확한 결과를 도출할 수 있다.

인하대학교 컴퓨터공학과