- 협업 필터링
- 메모리 기반과 모델 기반으로 나뉜다.
- 모델 기반에는 클러스터링 기법, 행렬 축소 기법, 딥러닝 기법이 있다.
- 행렬 축소 기법 중 하나에는 SVD(특잇값 분해)가 있다.
- SVD
- SVD는 동의어나 다의어로부터 오는 문제를 해결하기 위해 정보 검색 분야에 널리 사용되고 있다.
- 추천분야에서 SVD는 거대한 행렬을 축소시킬 수 있고, 축소된 행렬에서 확연히 줄어든 계산량으로 사용자 또는 아이템 간의 유사도를 구할 수 있게 해준다. 그래서 계산량도 줄이고, 정확도는 기본적인 협업 필터링보다 낫다.
- 하지만 해석에 있어서 그 요소들을 설명하기 까다로워진다는 단점이 있다.
- RMSE
-
오차의 합을 구할 때는 각 오차를 제곱한 값들을 더한다(오차에 음수가 껴있을 수도 있으므로)

-
오차의 합의 평균(평균제곱오차, MSE)를 구할 때는 오차의 합을 전체 갯수로 나눈다.
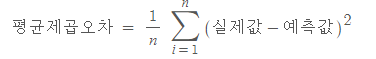
-
평균제곱오차를 최소로 하는 선을 찾는 것이 선형회귀에서의 미션이다. 하지만, 간혹 오차합의 값이 굉장히 크게 나오는 경우, 평균제곱오차도 너무 커지게 된다. 이 경우, 연산 속도가 느려질 수 있다는 단점이 있다. 그래서 우리는 저 값에 루트를 씌운다. 그것이 바로 RSME. 평균제곱근오차이다.
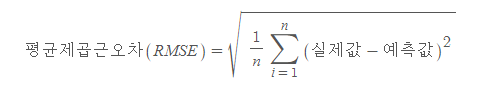
- MAE
-
Mean Absolute Error. 즉, 평균절대오차.
-
이는 모든 절대 오차(Error)의 평균이다. 여기서 오차란 알고리즘이 예측한 값과 실제 정답과의 차이를 의미한다. 그러므로 알고리즘이 정답을 잘 맞힐수록 MSE 값은 작다. 따라서, MAE가 작을 수록 알고리즘의 성능이 좋다고 할 수 있다.
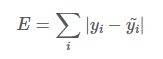
-
MAE는 손실 함수가 오차와 비례하여 일정하게 증가한다.
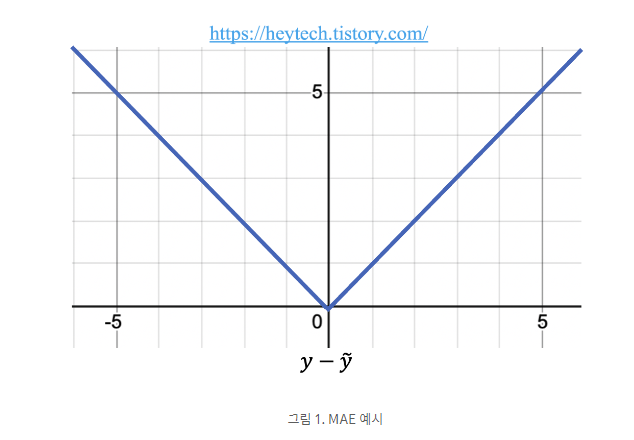
-
Outlier(이상치)에 강건하다. 즉, 오차가 유난히 큰 값은 Outlier로서 간주하여 해당 값을 무시하고 학습한다. (반면 평균제곱오차, 즉 MSE는 Outlier에 민감하다)
-
MAE는 회귀 문제에 자주 활용된다.
- 추가
1. 그리드 서치
-
정의: 모델의 성능을 가장 높게 하는 최적의 하이퍼파라미터를 찾는 방법. 하이퍼파라미터 후보들을 하나씩 입력해 모델의 성능이 가장 좋게 만드는 값을 찾는다.
-
sklearn.model_selection.GridSearchCV
-> 시도해볼 하이퍼파라미터들을 지정하면 모든 조합에 대해 교차검증 후 제일 좋은 성능을 내는 하이퍼파라미터 조합을 찾아준다. -
함수들
· fit(X, y): 학습
· predict(X): 분류-추론한 class, 회귀-추론한 값
· predict_proba(X): 분류문제에서 class별 확률을 반환

-
시도할 하이퍼파라미터와 값들이 너무 많아지면 많은 시간이 소모됨
2. 랜덤 서치
-
정의: 그리드 서치와 동일한 방식으로 사용하지만, 모든 조합을 다 시도하지 않고 각 반복마다 임의의 값을 대입해 지정한 횟수만큼 평가
-
sklearn.model_selection.RandomizedSearchCV
-
함수들
· estimator: 모델객체 지정
· param_distributions: 하이퍼파라미터 목록을 dictionary로 전달 ('파라미터명': [파라미터 값 list] 형식)
· n_iter: 파라미터 검색 횟수
· scoring: 평가 지표
· refit: best parameter를 정할 때 사용하는 평가지표로, scoring에 여러 평가지표를 설정한 경우 설정한다.
· cv: 교차검증 시 fold 개수
· n_jobs: 사용할 CPU 코어 개수 (None: 1 (기본값), -1: 모든 코어 다 사용)
· fit(X, y): 학습
· predict(X): 분류-추론한 class, 회귀-추론한 값을 반환한다. (제일 좋은 성능을 낸 모델)
· predict_proba(X): 분류 문제에서 class별 확률을 반환한다. (제일 좋은 성능을 낸 모델)
https://heytech.tistory.com/379
https://cori.tistory.com/167
(cori.tistory.com 도 과제시 참고할 것)
https://data-science-hi.tistory.com/82
(data-science-hi.tistory 블로그는 과제시에도 참고할 수 있을 듯 하다.)
