추천 엔진 정의
-
사용자: 서비스를 사용하는 사람
-
아이템: 서비스에서 판매하는 물품
-> 보통 서비스가 성장하면 사용자/아이템의 수도 같이 성장함
-> 하지만 아이템 수가 커지면서 아이템 디스커버리 문제가 대두됨 -
추천 엔진의 정의
- 사용자가 관심있어 할만한 아이템을 제공해주는 자동화된 시스템(키워드는 관심과 자동화)
- 비지니스 장기적인 목표를 개선하기 위해 사용자에게 알맞은 아이템을 자동으로 보여주는 시스템(키워드는 장기적인 목표와 자동화)
-
추천 엔진이 필요한 이유
- 조금의 노력으로 사용자가 관심있어 할 만한 아이템을 찾아주는 방법임(자동화!)
- 회사 관점에서는 추천 엔진을 기반으로 다양한 기능 추가 가능(관련 상품 추천으로 쉽게 확장 가능)
- 아이템의 수가 많아서 원하는 것을 찾기 쉽지 않은 경우(검색을 위한 수고를 덜어줌)
- 추천을 통해 신상품 등의 마케팅이 가능해짐(새로 나온 아이템들은 노출 자체가 어려운데 추천을 통해 기회를 줄 수 있음)
- 인기 아이템 뿐만 아니라 롱 테일의 다양한 아이템의 노출이 가능(추천 방식에 따라 다르지만 개인화가 잘 되면 이게 가능해짐)
-
추천은 결국 매칭 문제
- 사용자에게는 맞는 아이템을 매칭해주기(아이템은 서비스에 따라 달라지며 아이템이 다른 사용자가 될 수도 있음)
- 어떤 아이템을 추천할 것인가?
- 추천 UI도 굉장히 중요함(보통 추천 유닛들이 존재하며 이를 어떤 순서로 어떻게 노출하느냐가 중요)
- 사용자와 아이템에 대한 부가 정보들이 필요해짐
- 아이템 부가 정보(먼저 분류체계를 만드는 것이 필요/태그 형태로 부가정보를 유지하는 것도 아주 좋음)
- 사용자 프로파일 정보(개인정보: 성별, 연령대 / 아이템 정보: 관심 카테고리와 서브 카테고리, 태그, 클릭 혹은 구매 아이템)
- 무엇을 기준으로 추천을 할 것인가(클릭? 매출? 소비? 평점?)
추천 엔진 예제
- 아마존 관련 상품 추천(사용자: 멤버 / 아이템: 상품)
- 넷플릭스 영화/드라마 추천(사용자: 멤버 / 아이템: 영화, 드라마)
- 구글 검색어 자동완성(유저: 검색자 / 아이템: 검색어)
- 링크드인 혹은 페이스북 친구 추천(유저: 멤버 / 아이템: 멤버)
- 스포티파이 혹은 판도라 노래/플레이리스트 추천(유저: 멤버 / 아이템: 노래, 플레이리스트)
- 헬스케어 도메인의 위험 점수 계산(유저: 의사, 간호사 / 아이템: 환자)
: 어느 환자가 더 위험한지 예측하여 치료시 우선순위를 주기 위함, 환자별로 발병 확률과 발병시 임팩트를 계산하여 곱하는 형태 - 유데미 강좌 추천(유저: 멤버 / 아이템: 강좌)
=> 위 추천 엔진들의 공통점
- 격자 형태 UI 사용
- 다양한 종류의 추천 유닛들이 존재
추천 엔진 알고리즘 종류
-
컨텐츠 기반 (아이템 기반)
: 개인화된 추천이 아니며 비슷한 아이템을 기반으로 추천이 이뤄짐
: 아이템 간의 유사도를 측정하여 추천
: 구현이 상대적으로 간단함 -
협업 필터링(평점 기준)
: 기본적으로 다른 사용자들의 정보를 이용하여 내 취향을 예측하는 방식
: 크게 사용자 기반과 아이템 기반 두 종류가 존재
-> 사용자 기반: 나와 비슷한 평점 패턴을 보이는 사람들을 찾아서 그 사람들이 높게 평가한 아이템 추천
-> 아이템 기반: 평점의 패턴이 비슷한 아이템들을 찾아서 그걸 추천하는 방식 -
사용자 행동 기반
: 아이템 클릭 혹은 구매 혹은 소비 등의 정보를 기반으로 한 추천
: 모델링을 통해 사용자와 아이템 페어에 대한 클릭 확률 등의 점수 계산이 가능
: 크게 두 종류가 존재(1. 사용자 행동 기반 간단한 추천 유닛 구성 / 2. 사용자 행동을 예측하는 추천(클릭 혹은 구매) ) -
많은 경우 위의 알고리즘들을 하이브리드 형태로 사용
-
협업 필터링
-
사용자 기반 협업 필터링: 나와 비슷한 평점 패턴을 보이는 사람들을 찾아서 그 사람들이 높게 평가한 아이템 추천
-
아이템 기반 협업 필터링: 아이템들간의 유사도를 비교하는 것으로 시작 / 사용자 기반 협업 필터링과 비교해 더 안정적이며 좋은 성능을 보인다.(아이템의 수가 보통 작기에 사용자에 비해 평점의 수가 평균적으로 더 많고 계산량이 작음)
-
유사도 측정 방법: 두 개의 비교대상을 N차원 좌표로 표현 / 보통 코사인 유사도 혹은 피어슨 유사도 사용
-
협업 필터링 문제점
- Cold start 문제(사용자: 아직 평점을 준 아이템이 없는 경우 / 아이템: 아직 평점을 준 사용자가 없는 경우)
- 리뷰 정보의 부족: 리뷰를 했다는 자체도 사실은 관심?
- 업데이트 시점: 사용자나 아이템이 추가될 때마다 다시 계산을 해주어야 함
- 확장성 이슈: 사용자와 아이템의 수가 늘어나면서 행렬 계산이 오래 걸리게 됨 -> spark과 같은 인프라가 이런 이유로 인해 필요함.
- 협업 필터링의 많은 문제들이 추천의 일반적인 문제이기도 함
-
협업 필터링 구현 방법
- 메모리 기반
: 사용자 간 혹은 아이템간 유사도를 미리 계산
: 구현과 이해가 상대적으로 쉽지만 스케일하지 않음(평점 데이터의 부족) - 모델 기반
: 보통 SVD을 사용해서 구현됨
: 평점을 포함한 다른 사용자 행동을 예측하는 방식으로 진화하고 있기도 함
- 메모리 기반
-
-
지도학습 방식의 추천 엔진
- 어떤 기준으로 추천을 하느냐가 가장 중요
- 크게 두 종류의 힌트를 사용(명시적 힌트: 리뷰 점수 혹은 좋아요 / 암시적 힌트: 클릭, 구매, 소비)
-
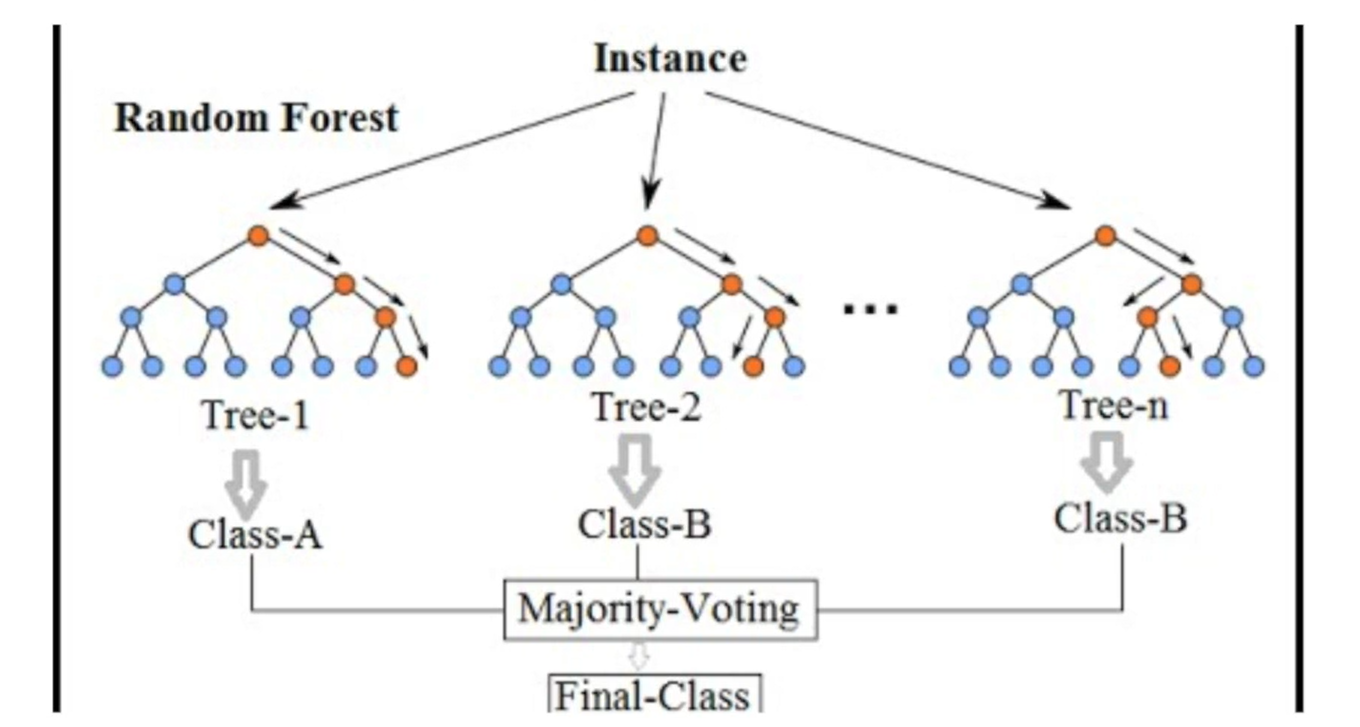
앙상블과 랜덤 포레스트
- 다수의 분류기를 사용해서 예측하는 방식
- 성능은 좋지만 훈련과 예측시간이 오래 걸린다는 단점 존재
 (앙상블과 랜덤 포레스트)
(앙상블과 랜덤 포레스트)
-
추천엔진의 발전 역사
- 2001년 아마존이 아이템 기반 협업 필터링 논문 발표
- 2006~2009년 넷플릭스 프라이즈(SVD를 이용한 사용자의 아이템 평점 예측 알고리즘 탄생/ 앙상블 알고리즘이 보편화됨)
- 딥러닝의 일종이라 할 수 있는 RBM이 단일 모델로는 최고의 성능을 보여줌. 딥러닝의 추천에서의 사용가능성을 보임.
- 2010년 딥러닝이 컨텐츠 기반 음악 추천에 사용되기 시작
- 2016년 딥러닝을 기반으로 한 추천히 활기를 띄기 시작
- 오토 인코더 기반으로 복잡한 행렬 계산을 단순화하는 방식이 하나
유데미 추천 살펴보기
- 문제 정의: 학생들에게 관심있을 만한 강의를 먼저 보여주는 것
- 추천 UI
- 격자 기반의 UI
- 다양한 추천 유닛들이 존재(몇 개의 유닛을 어느 순서로 보여줄지 결정: 유닛 선택과 랭킹 / 페이지 생성 시간과 사용자 만족도는 반비례, 즉 너무 많은 유닛은 역효과)
- 온라인 강의 메타 데이터
- 분류 체계, 태그
- 강사에게 태그와 분류 체계 선택하게 하기, 클릭 키워드 분석
-
다양한 행동 기반 추천
- 클릭, 구매, 소비 등등
-
기본 아이디어
- 하이브리드 방식 추천: 협업 필터링, 사용자 행동 기반 추천, 머신러닝 모델기반 추천
- 사용자별로 등록 확률을 기준으로 2천개의 탑 강의 목록 생성(배치로 시작했다가 실시간 계산으로 변경)
- 홈페이지에서의 추천은 조금 더 복잡(개인화되어 있음 / 유닛 후보 생성, 유닛 후보 랭킹)
- 특정 강의 세부 페이지에서 추천은 아이템 중심
1. student also bought(아이템 기반 협업 필터링)
2. Frequently bought together(별도의 co-occurrence 행렬 계산)
3. 각 유닛에서의 강의 랭킹은 개인별 등록 확률로 결정인기도 기반 추천 유닛 개발
- Cold start 이슈가 존재하지 않음
- 인기도의 기준(평점? 매출? 최다 판매?)
- 사용자 정보에 따라 확장 가능(서울 지역 인기 아이템 추천)
- 단 개인화되어 있지는 않음 (어느 정도는 가능)
- 아이템의 분류 체계 정보 존재 여부에 따라 쉽게 확장 가능(특정 카테고리에서의 인기 아이템 추천, 분류체계를 갖는 것이 여러모로 유리)
- 인기도를 다른 기준으로 바꿔 다양한 추천 유닛 생성 가능
- 기타 Cold Start 이슈가 없는 추천 유닛(현재 사용자들이 구매한 아이템, 현재 사용자들이 보고 있는 아이템)
유사도 측정
-
다양한 유사도 측정 알고리즘
: 벡터들 간의 유사도를 판단하는 방법
: 추천 알고리즘에서는, 두 점 사이의 거리를 계산하는 것 보다는 두 벡터의 방향성을 보는 것이 더 좋음-
코사인 유사도: N차원 공간에 있는 두 개의 벡터간의 각도(원점에서)를 보고 유사도를 판단하는 기준
-> from sklearn.metrics.pairwise import cosine_similarity
 (코사인 유사도)
(코사인 유사도) -
피어슨 유사도: 먼저 벡터 A와 B의 값들을 보정, 그 이후 계산은 코사인 유사도와 동일. 이를 중앙 코사인 유사도 혹은 보정된 코사인 유사도라 부르기도 함
- 피어슨 유사도의 장점: 모든 벡터가 원점을 중심으로 이동되고 벡터간의 비교가 더 쉬워짐
-
-
텍스트를 행령(벡터)로 표현하는 방법
: 텍스트 문서를 행렬로 표현하는 방법은 여러가지가 존재
1. 원핫 인코딩 + Bag of Words (카운트): 단어의 수를 카운트 해서 표현
- 먼저 stopword를 제외 ( the, is, in, we, can, see)
- 그 뒤 단어수 계산 -> 총 5개 sky, blue, sun, bright, shining
- 단어별로 차원을 배정: sky(1), blue(2), sun(3), bright(4), shining(5)
- CountVectorizer: Bag of Words 카운팅 방식을 구현한 모듈. 벡터로 표현이 되면 문서들간의 유사도 측정이 가능.
-> from sklearn.feature_extraction.text import CountVectorizer
2. 원핫 인코딩 + Bag of Words (TF-IDF): 단어의 값을 TF-IDF 알고리즘으로 계산된 값으로 표현
- TF-IDF
:위의 카운트 방식은 자주 나오는 단어가 높은 가중치를 갖게 된다.
: TF-IDF의 기본적인 아이디어 -> 한 문서에서 중요한 단어를 카운트가 아닌 '문서군 전체'를 보고 판단하자
: 어떤 단어가 한 문서에서 자주 나오면 중요하지만 이 단어가 다른 문서들에서는 자주 나오지 않는다면 더 중요
- 카운트 기반 Bag of Words랑 동일한데, 카운트 대신에 TF-IDF 점수를 사용(TF-IDF = TF(t,d)*IDF(t))
-> TF(t,d): 단어 t의 문서 d에서 카운트
-> IDF(t): 역문서 비율. 단어 t가 전체 문서들 중(총 N개) 몇 개의 문서에서 나타났는지 비율을 역으로 한 값)
-> DF는 단어가 나온 문서의 수를 말한다.
- TfIdfVectorizer: 문서를 벡터로 바꾸는 방법. CountVectorizer와 사용법이 거의 같다.
->from sklearn.feature_extraction.text import TfidfVectorizer
-> 기본적으로 L2 normalization 을 함.


+ L2 normalization: 벡터를 단위 벡터로 만듦(길이가 1인 벡터로 만드는 것)
+ L1 normalization과 L2 normalization의 차이는?
TF-IDF 문제점
- 정확하게 동일한 단어가 나와야 유사도 계산이 이루어짐 (동의어 처리가 안됨)
- 단어의 수가 늘어나고 아이템의 수가 늘어나면 계산이 오래 걸림
- 결국 '워드 임베딩'을 사용하는 것이 더 좋음(아니면 LSA와 같은 차원 축소 방식 사용)
- 추천 엔진 아키텍처
- 추천엔진의 기본적인 구조(전체 추천 페이지 레벨)
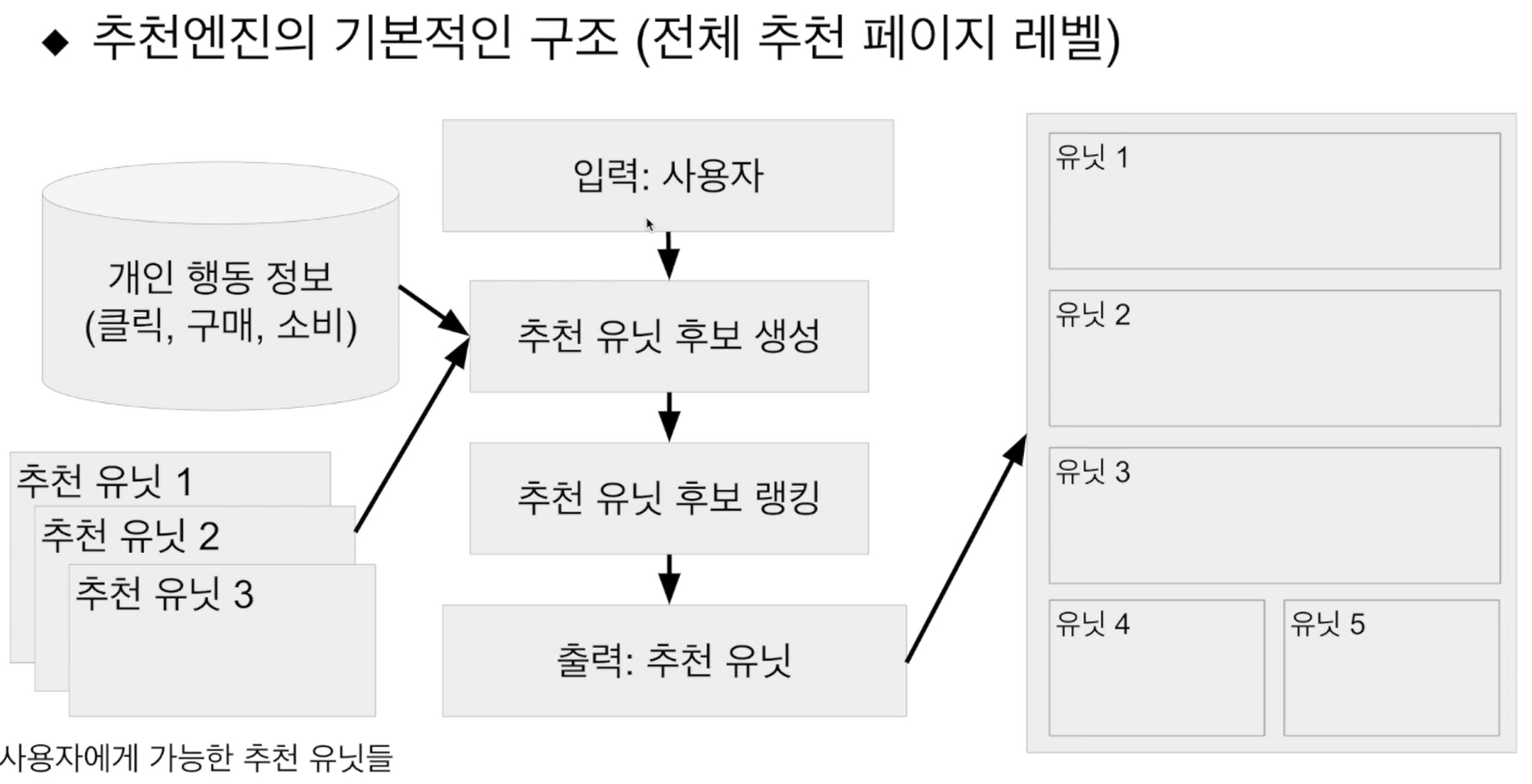
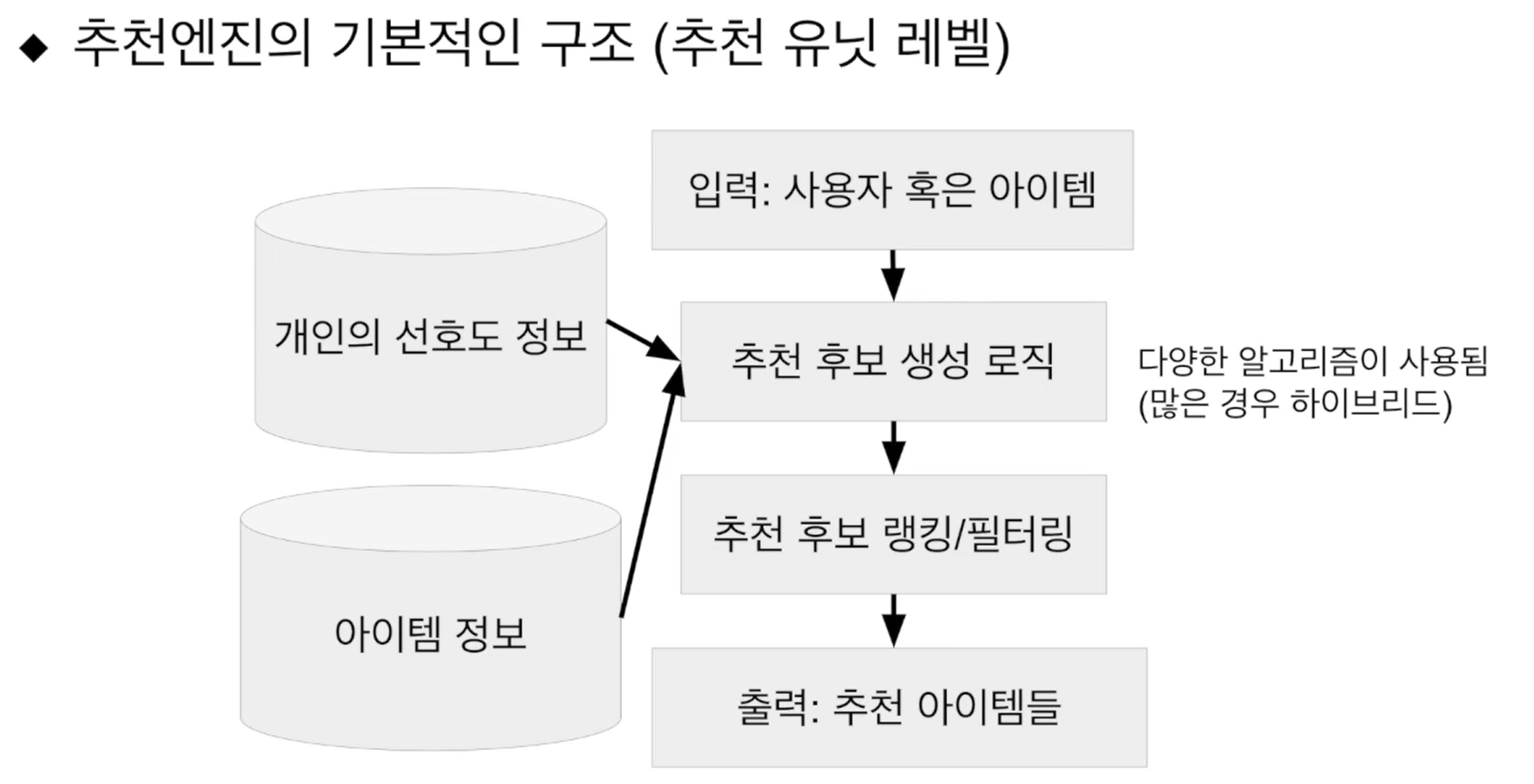
- 추천엔진의 기본적인 구조(전체 추천 페이지 레벨)
협업 필터링 소개
-
기본적으로 다른 사용자들의 정보를 이용하여 내 취향을 예측하는 방식
-
크게 세 종류가 존재
1. 사용자 기반(나와 비슷한 평점 패턴을 보이는 사람들을 찾아서 그 사람들이 높게 평가한 아이템 추천)
2. 아이템 기반(평점의 패턴이 비슷한 아이템들을 찾아서 그걸 추천하는 방식)
3. 예측 모델 기반(평점을 예측하는 머신러닝 모델을 만드는 것) -
구현하는 방식에는 크게 두 종류가 존재
1. 메모리 기반- 코사인 유사도나 피어슨 상관계수 유사도를 사용해 비슷한 사용자 혹은 아이템을 찾음 -> 평점의 예측 없이 유사도 기반으로 추천할 아이템을 결정하는 방식
- 평점을 예측할 때는 가중치를 사용한 평균을 사용
- 이해하기 쉽고 설명하기 쉽지만 스케일하기 힘듬(평점 데이터의 부족)
- 보통 Top-N(혹은 nDCG) 방식으로 평가(사용자가 좋아한 아이템을 일부 남겨두었다가 추천 리스트에 포함되어 있는지 보는 방식. 추천 순서를 고려해 평가하면 nDCG)
2. 모델 기반 - 머신 러닝을 사용해 평점을 예측(PCA, SVD, 딥러닝 등등/ 딥러닝의 경우에는 오토인코더를 사용하여 차원을 축소)
- 행렬의 차원을 줄임으로써 평점 데이터의 부족 문제를 해결
- 하지만 어떻게 동작하는지 설명하기 힘듦(머신 러닝이 갖는 일반적인 문제)
- 머신러닝 알고리즘들이 사용하는 일반적인 방식으로 성능 평가 가능
- 메모리 기반에서 사용하는 Top-N이나 nDCG 방식도 사용가능
3. 온라인 테스트 (A/B 테스트) - 가장 좋은 방식은 실제 사용자에게 노출시키고 성능을 평가하는 것
4. 메모리 기반 vs 모델 기반 - 메모리 기반은 유사도 함수를 기반으로 비슷한 사용자나 아이템을 검색(KNN 방식도 여기에 속한다 볼 수 있음/ 평점을 예측하는 것이 아니라 유사도 기반으로 추천)
- 모델 기반은 어떤 비용 함수를 기반으로 학습(즉 머신러닝 / SVD++를 사용하여 (딥러닝처럼) 학습 / 딥러닝에서는 오토인코더를 사용하여 사용자 아이템 행렬의 패턴을 배운다.)
- 오토인코더란, 딥러닝에서 데이터 차원을 축소하는 방식으로, 인코딩을 통해 데이터를 압축하고 디코딩을 통해 데이터를 복구한다. 인코딩을 하는 부분이 결국 차원 축소를 담당
- SurpriseLib 소개
- 협업 필터링과 관련한 다양한 기능을 제공하는 라이브러리
- KNNBasic 객체 이용해서 사용자 기반 혹은 아이템 기반 협업 필터링 구현
- SVD 혹은 SVDpp 객체를 이용해서 모델 기반 협업 필터링
- 협업 필터링 알고리즘의 성능 평가를 위한 방법 제공
- scikit-learn 사용법과 비슷
-
사용자의 유사도 측정
- 사용자들을 벡터로 표현
- 지정된 사용자와 다른 나머지 사용자들과 유사도 측정
- 사용자 대 아이템 행렬을 사용자간 유사도 행렬로 변환
-
아이템의 유사도 측정
- 주어진 아이템을 기반으로 가장 비슷한 아이템을 찾아서 추천
- i가 메인 아이템, j는 비교 대상이 되는 아이템
- 최종적으로 i와 유사도가 가장 큰 j를 추천 (N개)
- 아이템 i와 j간의 유사도 측정 -> 아이템 대 사용자 행렬을 아이템간 유사도 행렬로 변환
- 주어진 아이템을 기반으로 가장 비슷한 아이템을 찾아서 추천
=> 협업 필터링에는 사용자 기반과 아이템 기반으로 유사도를 바탕으로 추천을 하는 메모리 방식과, 평점을 예측하여 추천하는 모델 방식이 존재한다.
=> Surprise 라이브러리를 사용하여 사용자 기반과 아이템 기반 협업 필터링을 구현한다!!!
- SVD 알고리즘(SVD를 사용해서 아이템 기반 평점을 행렬 기반으로 예측할 수 있음)
- 사용자, 아이템 기반 협업 필터링의 문제점
- 확장성: 큰 행렬 계산은 여러모로 쉽지 않음(물론 아이템 기반으로 가면 계산량이 줄어듦 / 물론 Spark을 사용하면 큰 행렬 계산도 얼마든지 가능)
- 부족한 데이터(많은 사용자들이 충분한 수의 리뷰를 남기지 않음)
- 해결책
=> '모델 기반 협업 필터링' : 머신 러닝 기술을 사용해 평점을 예측. 입력은 사용자-아이템 평점 행렬- 행렬 분해 방식
- 협업 필터링 문제를 사용자-아이템 평점 행렬을 채우는 문제로 재정의(사용자 혹은 아이템을 적은 수의 차원으로 기술함으로써 문제를 간단화)
- 가장 많이 사용되는 행렬 분해 방식으로 PCA / SVD 혹은 SVD++
- PCA(Principal Component Analysis): 차원을 축소하되, 원래 의미는 최대한 그대로 간직
- SVD(Singular Vector Decomposition): 2개 혹은 3개의 작은 행렬의 곱으로 단순화. PCA와 같은 차원 축소 알고리즘이지만 다른 방식이다.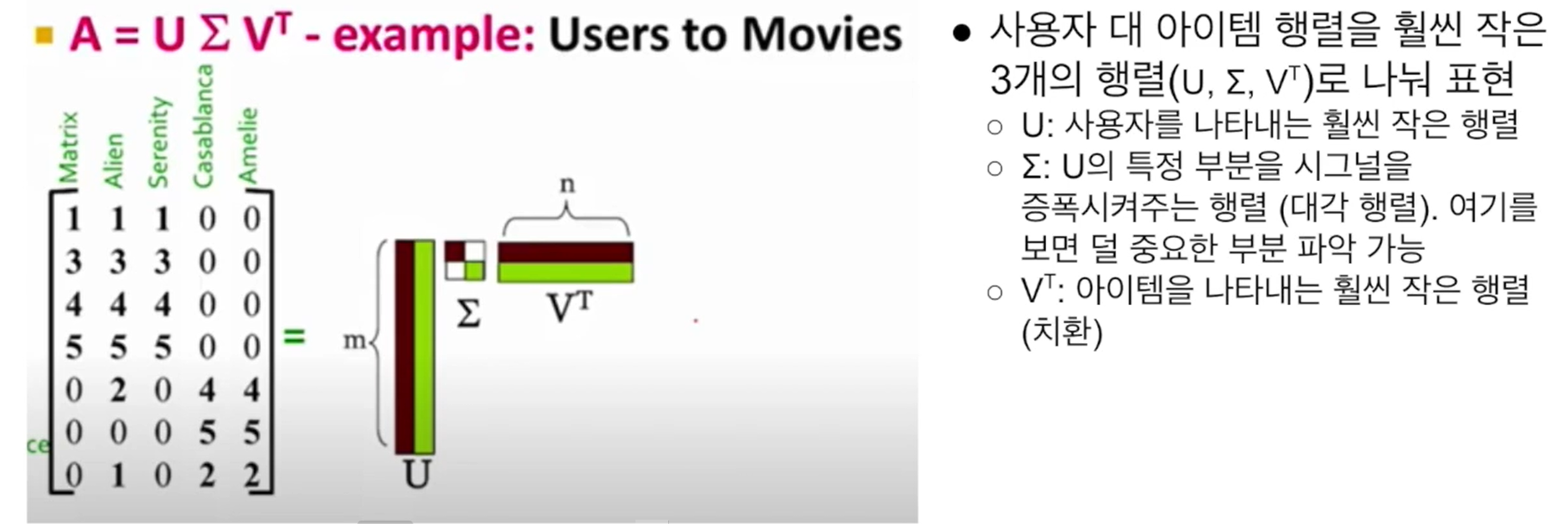 (그림: SVD)
(그림: SVD)
- SVD++
: SVD나 PCA는 완전하게 채워져 있는 행렬의 차원수를 줄이는 방식
: SVD++는 sparse 행렬이 주어졌을 때 비어있는 셀들을 채우는 방법을 배우는 알고리즘으로, 채워진 셀들의 값을 최대한 비슷하게 채우는 방식으로 학습한다(에러률을 최소화). 보통 RMSE의 값을 최소화 하는 방식으로 학습하면서 SGD 를 사용
: surprise 라이브러리를 사용하거나 사이킷런의 TruncatedSVD를 사용한다. - 딥러닝 방식
- 행렬 분해 방식
- 사용자, 아이템 기반 협업 필터링의 문제점
- 오토인코더
- 대표적인 비지도학습을 위한 딥러닝 모델
- 데이터의 숨겨진 구조를 발견하면서 노드의 수를 줄이는 것이 목표
- 입력 데이터에서 불필요한 특징들을 제거한 압축된 특징을 학습하려는 것
- 오토인코더의 출력은 입력을 재구축한 것임 {최대한 비슷하게 나오도록 학습 / 입력 데이터와 예상 출력 데이터가 동일(입력==레이블)}
- 오토인코더의 구조: 출력층의 노드 개수와 입력층의 노드 개수가 동일해야 함 / 은닉층의 노드 개수가 출력층과 입력층의 노드 개수보다 작아야 함
- 이렇게 학습된 은닉층의 출력을 입력을 대신하는 데이터로 사용(데이터의 크기 축소) (그림 참고. 그림에서 A 대신 B 사용)
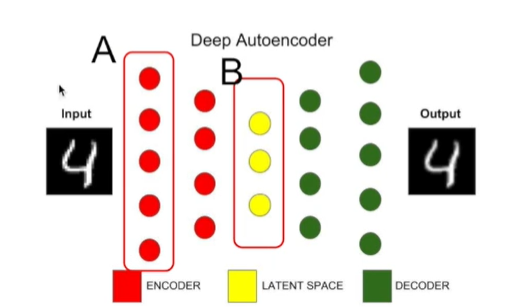
- 케라스(Keras)
- 오픈소스 딥 러닝 라이브러리(구글에서 시작)
- 다양한 프레임웍 위에서 동작하는 상위레벨 딥러닝 프레임웍(텐서플로우, MXNet 등 지원)
- TensorFlow 위에서만 동작하는 라이브러리도 있음( 'from tensorflow import keras' vs 'import keras')
- Keras API를 사용하는 세 가지 방법
1. Sequential 모델 API(가장 간단하며 가장 많이 사용됨 / 하나의 입력 데이터, 하나의 출력 데이터, 순차 레이어 스택을 지원)
2. Functional API (레고 블록 모델 / 다중 입력 데이터, 다중 출력 데이터, 임의의 그래프 구조 지원(텐서플로우와 흡사) / Sequential 모델에 비해 복잡
3. Model Subclassing(가장 Flexible 하지만 가장 복잡)
