Pruning 정의
Pruning은 모델의 크기나 복잡성을 줄이기 위해 불필요한 구성 요소를 제거하는 기법으로 Unstructured pruning, Semi-structured pruning, Structured pruning으로 나눌 수 있다.
- Structured pruning
- 뉴런, 어텐션 헤드, 레이어와 같은 요소를 특정 규칙에 따라 제거하여 전체 구조를 유지.
- 중요한 구성요소를 제거할 경우 성능저하를 초래.
- Unstrctured와 비교해 구조를 유지하므로 추론 가속화와 같은 부분에서 이점. - Unstructured pruning
- 각각의 파라미터를 제거하여 불규칙한 sparse structure를 유지.
- 모델의 성능 유지하기 좋지만 구조가 불규칙적이게 되므로 추론 가속화와 같은 부분에서 최적화가 필요. - Semi-structured pruning : Structured와 Unstructured를 적절히 활용해 파라미터를 세밀하게 제거함과 동시에 구조적 정규화를 유지
LLM-Pruner
LLM-Pruner는 Structured pruning중에서도 loss나 gradient를 통해 중요한 unit을 평가하는 Loss-based Pruning에 속하는 기법이다.
LLM-Pruner는 gradient 정보를 기반으로 제거할 결합구조를 선별한다.
Introduction
LLM의 거대한 규모로 인해 이를 해결하기 위해 knowledge distillation, quantization, model pruning 등의 방법들이 제안 되었다. 하지만 주로 특정 도메인, task를 수행하기 위해서 압축하는 방식들로 LLM의 다양한 task 능력들을 저하시켜 특정 task에만 적합하게 만든다.
하지만 LLM의 크기를 줄이면서 특정 task에만 종속되지 않게 하기 위해서는 아래와 같이 2가지가 문제가 된다.
- 대량의 학습 데이터 셋
- 크기 압축 후 학습에 필요한 긴 시간
위와 같은 문제를 해결하기 위해 LLM-Pruner라는 접근 방식을 도입했다. 이 방식은 학습 데이터에 의존성을 줄이고 후속 학습 시간을 단축하여 기존 모델에 최소한의 영향을 미치는 것이 중점이다.
LLM-Pruner의 장점은 아래 4가지 입니다.
- 압축된 모델이 multi-task의 능력을 유지
- 50,000개의 학습 데이터 셋만으로 압축 가능
- 소요시간이 총 3시간 이내
- 자동으로 structured pruning 가능한 프레임워크
Methods
LLM-Pruner는 Discovery, Estimation, Recover의 3가지 단계로 구성
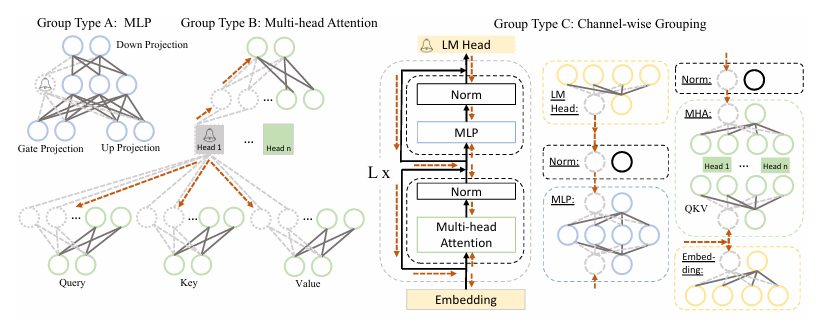
1. Discovery Stage
이 단계에서는 상호 의존적인 구조 그룹을 식별한다.
임의의 뉴런을 초기 트리거로 선정하고 종속된 뉴런들을 활성화해 새로 활성화된 뉴런이 더 이상 발견되지 않을 때까지 계속해, pruning을 위한 그룹을 구성한다.
- Group Type A
MLP(Multi-Layer Perceptron)의 뉴런들의 그룹 - Group Type B
Multi-head Attention(Q, K, V) 뉴런들의 그룹 - Group Type C
MLP, Norm, Embedding 등의 channel 단위로 구성된 그룹
2. Estimation Stage
이 단계에서는 그룹의 중요도를 평가한다.
서로 종속된 뉴런들로 구성된 그룹에서 특정 뉴런들만 pruning하게 되면 파라미터 사이즈가 증가하게 되고 중간 표현이 불일치하게 된다. 그래서 중요도가 낮은 그룹을 prunging하기 위해 그룹 자체의 중요도를 평가한다.
-
Vector-wise Importance
- 모델의 예측에 미치는 영향이 가장 적은 그룹을 제거하기 위해 손실의 편차를 계산
- 데이터셋 , 샘플수 N
-
Element-wise Importance
- 가중치 에 대한 중요도를 추정한다. -
Group Importance
- 와 를 통해 최종적으로 그룹의 중요도를 아래 4가지 방식 중 적절히 선정해 계산
- Summation: or
- Production: or
- Max: or
- Last-only: 그룹에서 마지막으로 실행되는 구조를 제거.(마지막 실행 구조를 그룹의 중요도로 할당)
3. Recover Stage
모델 성능 복구 과정을 빠르고 효율적으로 개선하기 위해 복구 단계에서 최적화가 필요, 이는 파라미터 수를 최소화하는 것이 중요하다. 이를 위해 pruning된 모델을 LoRA를 사용해 post-train한다. 추가 파라미터인 P와 Q는 매개변수로 표현할 수 있으므로 모델에서 추가 파라미터가 발생하지 않는다.
Experiments
LLM-Pruner를 LLaMA-7B, Vicuna-7B, ChatGLM-6B 모델로 테스트 수행.
BoolQ, PIQA, HellaSwag등의 벤치마크를 통해 zero-shot classification, common sense reasoning을 평가.
- pruning 후 튜닝 여부에 따른 성능 비교
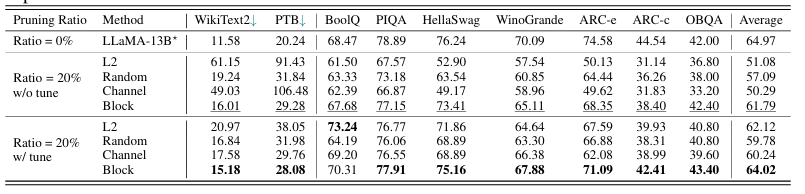
- pruning 후 recover stage를 수행한 w/ tune 상태의 모델이 튜닝하지 않은 w/o tune 상태의 모델보다 성능이 덜 감소했다.
- Block(Group Type A or Group Type B) 보다 Channel(Group Type C) 타입이 성능저하가 심했다. 이는 Transformer의 구조에서 첫 layer와 끝 layer의 경우 성능에 더 중요한 layer이지만 Channel 타입의 경우 모든 layer를 동일하게 취급하기에 첫부분, 끝부분의 layer가 pruning될 가능성이 생기기 때문이다. - pruning을 통한 모델 추론 성능 비교
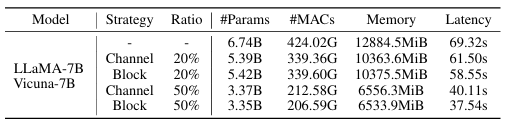
- pruning 비율에 따른 성능 비교
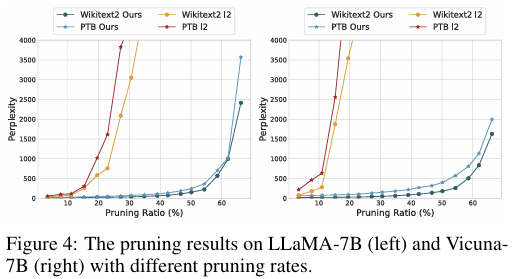
- LLM-Pruner의 경우 pruning 비율을 60%까지 높여도 유사한 perplexity 수준을 유지한다. - Estimation Stage의 Group Importance 방식에 대한 결과
- Max 전략은 문장의 일관성, 유창성에 대해서는 우수했지만 zero-shot classification 성능은 가장 낮았다.- Last-only 전략의 경우 분류 성능이 제일 우수했지만 생성품질이 떨어졌다.
- 일반적으로 성능이 우수한 Sum 전략을 최종적으로 선정했다.
Conclusion
LLM-Pruner는 학습 데이터셋에 크게 구애받지 않고 모델을 압축하는 것을 목표로 하는 방법입니다. 각 뉴런간의 종속성을 파악해 pruning을 위한 그룹을 구성하고 파라미터, 가중치 단위의 평가를 통해 제거할 그룹을 선정, 이후 모델 성능 복구를 위해 LoRA를 통한 post-training을 수행합니다.
LLaMA 모델의 파라미터를 50%의 높은 비율로 제거할시 성능이 상당히 저하되고 일관성 없는 문장을 생성하는 경우도 관찰하였다.
Reference
https://arxiv.org/pdf/2308.07633 - A Survey on Model Compression for Large Language Models
https://arxiv.org/pdf/2305.11627 - LLM-Pruner