목적
- Qwen 2.5, EXAONE-3.5, Llama3.1 등 7~8B 모델들의 한국어 성능을 평가하기 위한 목적으로 리뷰하게 되었다.
- 번역이나 요약 등 몇가지 task를 한국어로 지시하는 경우 중국어, 영어, 특수기호 등이 부적절하게 섞여서 출력되는 현상들이 있어 찾아보게된 벤치마크이다.
Language Confusion의 정의
- 사용자가 원하는 언어로 일관성있게 생성하지 못하는 오류를 Language Confusion이라고 정의

- Full-respone Confusion
전체 답변이 부적절한 언어로 생성된 오류 - Line-level Confusion
문장별로 다른 언어로 생성된 오류 - Word-level Confusion
한 단어 또는 구문이 다른 언어로 생성된 오류
테스트 설정
- mono-lingual
입력으로 들어온 언어와 LLM이 생성한 언어가 같은지 평가 - cross-lingual
특정 언어로 생성하라고 지시한 사항을 잘 따르는지 평가
ex) "Please reply in Korean"
측정 기준
- Line-level Detection
line 단위로 응답을 나누고 fastText로 유저가 요청한 언어가 맞는지 확인 - Word-level Detection
- non-Latin 언어의 경우 단어 수준 언어 혼동이 영어에서 주로 발생되므로 대상 언어에서 주로 사용되지 않는 영문 단어가 발생하는 것을 탐지
(아랍어, 힌디어, 일본어, 한국어, 러시아어, 중국어) - Latin 언어의 경우 단어 수준의 언어 혼동이 거의 발생하지 않으므로 해당 언어의 유니코드 범위를 벗어나는 문자가 포함되는 것을 탐지
(독일어, 영어, 스페인어)
측정 지표
Line-level pass rate(LPR)
- Line-level 에러가 발생하지 않은 응답 문장의 비율을 구하는 수식
Word-level pass rate(WPR)
- 모든 단어가 원하는 언어로 작성된 응답 비율을 구하는 수식
- Line-level 에러와 Word-level 에러가 중복될 수 있기에 line-level 에러가 있는 문장을 제외하고 계산
Language confusion pass rate(LCPR)
- LPR과 WPR로 조화 평균을 구함
분석결과
프롬프트 길이에 따른 차이
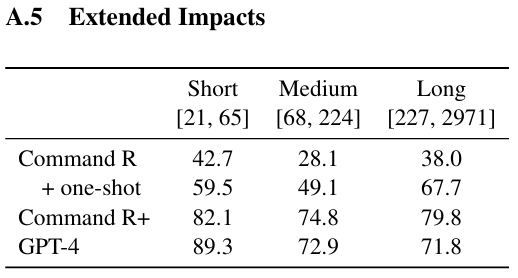
- 프롬프트를 short, medium, Long의 길이 차이로 나누어 테스트해 보았지만 명확한 패턴을 발견하지 못했다. 길이보다는 복잡성에 의해 더 높은 language confusion이 발생되는 것으로 봄.
지시사항 위치에 따른 차이
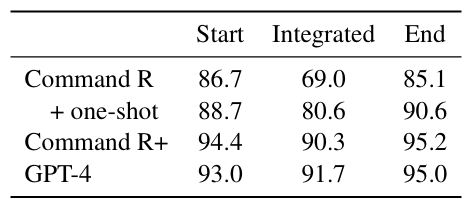
- 번역 지시 사항을 프롬프트 시작, 끝, 통합으로 구분해 테스트해 보았을때 지시사항이 독립적으로 구분된 시작과 끝 위치에서 혼동이 덜 발생함.
양자화로 인한 영향
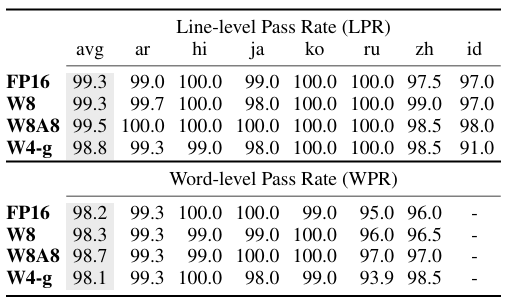
- Command R+ 모델 기준으로 FP16, W8, W8A8은 성능저하가 크지 않지만 W4의 경우 두드러짐.
Instruction tuning의 영향
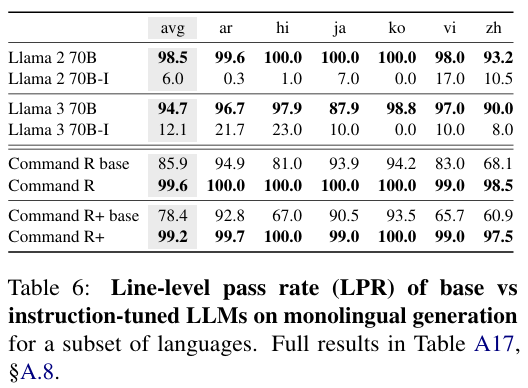
- Llama, Command R의 기본 모델, Instruction 모델을 비교 테스트.
- Command R의 경우 Instruction 모델이 언어 혼동이 덜 일어났지만, Llama 모델의 경우 Instruction 모델이 language confusion이 더 많이 발생함. 이는 Llama 모델의 지시사항 학습이 영어 위주로 학습되었기 때문으로 봄.
Language Confusion이 발생되는 원인

- 다음 토큰의 확률 분포가 평탄하거나 높은 확률의 비슷한 값을 가진 토큰이 다수가 존재할때 발생한다. 즉 비슷한 확률값을 가진 후보 토큰들이 다수가 존재해 적절한 토큰을 선정하기 어려울 때 발생한다.
Language Confusion의 해결방안
temperature, top-p 값 조정
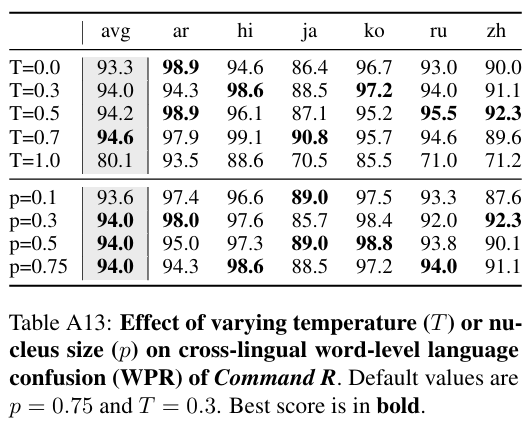
- temperature는 높일 수록 WPR 값이 낮아졌고, top-p는 0.3까지는 증가하다 일정한 값을 보였다.
Beam search decoding의 조정
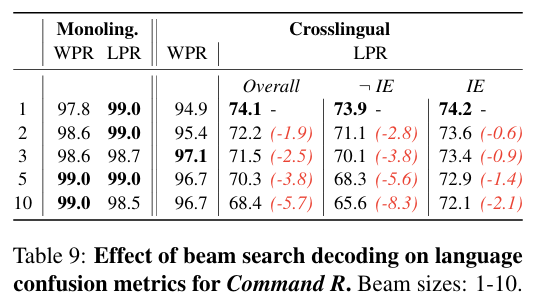
- beam 수가 증가할 수록 WPR 값은 증가.
- Mono-lingual LPR의 경우 beam 수와 거의 영향이 없음
- cross-lingual LPR의 경우 beam 수에 영향을 크게 받아 수가 증가할 수록 감소하게 됨.
Multilingual instruction tuning
- 영어로만 instruction tuning하는 경우는 mono-lingual에서 단어 수준의 혼동에 큰 악영향을 줌.
- SFT에서 10%만 다국어 데이터를 섞어서 tuning하는 경우 줄 단위의 혼동을 거의 제거할 수 있다.
- 다국어 데이터를 instruction tuning하는 경우는 cross-lingual에서 줄 단위 혼동을 더욱 발생시킬 수 있다. 이는 cross-lingual의 경우 'Reply in French' 처럼 하나의 언어로만 지시하기 때문이다.
Reference
AI의 Use Case에 관심이 많습니다.