
MongoDB Basic
NoSQL의 데이테 베이스를 말한다 = MongoDB
- 이 외에도 NoSQL은 넓은 범위에서 사용하는 언어이다.
NoSQL에서는 SQL과 다르게 데이터를 행과 열이 아닌 체계적인 방식으로 저장을 하게 된다.
- 데이터를 도큐먼트의 형태로 저장을 하게 된다.
MongoDB데이터베이스는 NoSQL도큐먼트 데이터 베이스 이다.
NoSQL을 사용할떄
- 비구조적인 대용량의 데이터를 저장하는 경우
- 자유롭게 데이터를 저장할수 있기 때문에 정형화 되어있지 않는 데이터를 저장할떄 효과적이다.
- 클라우드 컴퓨팅 및 저장공간을 최대한 활용하는 경우
- 쉽게 분리 할 수 있기 떄문에 저장 공간을 효율적으로 활용 가능하다.
- 시스템이 커지면서 DB를 증설해야 한다면 SQL같은 경우에는 수직적으로 확장한다.
- 하지만 수직적으로 확장을 하게 되면 관리가 어렵다는 단점이 있다.
- 반면에 NoSQL은 수평적 확장이기 떄문에 이론상으로는 무한대로 서버를 분산시켜 DB를 증설할 수 있다.
- 빠르게 서비스를 구축하고 데이터 구조를 자주 업데이트 하는 경우
- 스키마를 미리 준비할 필요가 없기 때문에 빠르게 개발할떄 유용하다.
Atlas Cloud
- MongoDB에서는 아틀라스(Atlas)로 클라우드에 데이터베이스를 설정한다.
- GUI와 CLI로 데이터를 이용할수가 있다.
아틀라스 사용자는 클러스트를 배포할수도 있으며 클러스트는 그룹화된 서버에 데이터를 저장한다.
또한 이 서버는 레플리카 세트로 구성되어 있으며 레플리카 세트는 동일한 데이터를 저장하는 몇개의 연결된 MongoDB인스턴스 모음이다.
인스턴스 : 특정 소프트웨어를 실행하는 로컬, 클라우드의 단일 머신
즉 크기순으로 정리하면
클러스트 > 레플리카 세트 > 인스턴스 모음
이렇게 정리가 된다.
레플리카 세트는 데이터의 사본을 저장하는 인스턴스의 모음이다.
- 인스턴스 중 하나에 문제가 발생하더라도 데이터는 유지되며 나머지 레플리카 세트의 인스턴스에 저장된 데이터로 작업을 한다.
Document
도큐먼트는 필드-값형태로 데이터를 저장하고 구성을 한다.
필드: 데이터의 고유한 식별자값: 식별자와 관련된 데이터
이러한 도큐먼트의 모음을 컬렉션이라고 한다.
일반적으로 도큐먼트 간의 공통 필드가 있으며
데이터베이스 당 많은 컬렉션이 있고, 컬렉션당 많은 도큐먼트가 있을수 있다.
JSON vs. BSON
shell을 이용하여 도큐먼트를 사용할때에는 JSON형식으로 출력이 된다.
- 즉 작성하기 위해서는 JSON형식을 따라야 한다.
- 기본적인 예시

보통 JSON형태를 많이 사용하기 때문에 데이터 저장하기에 좋은 방법이지만 단점도 존재한다.
- 읽기 쉽지만 파싱이 느리고 메모리 사용이 비효율적이다.
- 기본 데이터 타입만을 지원하기 때문에 사용 할 수 있는 데이터 타입에 제약이 있다.
이러한 문제점을 해결하기 위해 BSON이 등장하게 되었다.
- 컴퓨터의 언어에 가까운 이진법에 기반을 둔 표현법
- JSON의 단점을 모두 커버하게 된다.
하지만 JSON을 주로 활용을 하기 때문에
MongoDB에서는 JSON으로 작성된 데이터를 내부에서는 BSON으로 저장,사용 하게 된다.
<즉 우리는 그냥 JSON으로 작성을 하면 된다!>
Importing & Exporting
다 알다시피 데이터를 가져오는 방법이다.
- 우리가 알아 볼 것은 데이터 형식(JSON, BSON)에 따라 달라지는 명령어에 대해서 알아볼 것이다.
앞서 말했듯이 MongoDB에서는 두가지 형식으로 데이터를 저장하게 된다.
- 그래서 조건에 따라 가져오거나 내보낼 떄 사용 가능한 명령어가 각각 존재한다.
크게 두가지로 나누어 진다.
JSON
- 데이터를 가져오기 ->
mongoimport- 데이터를 내보내기 ->
mongoexport
BSON
- 데이터를 가져오기 ->
mongorestore- 데이터를 내보내기 ->
mongodump
앞서 적혀 있는 것처럼 두가지 명령어가 있다.
이를 사용하기 위해서는 `Atlas Cluster URI`가 필요하다.
해당 URI는 일반 웹의 형식과 같고 usename, password, cluster주소 로 이루어져 있다.
mongoexport를 하는 경우에는 반드시 정확하게 작성을 해주어야 한다.
- 형식

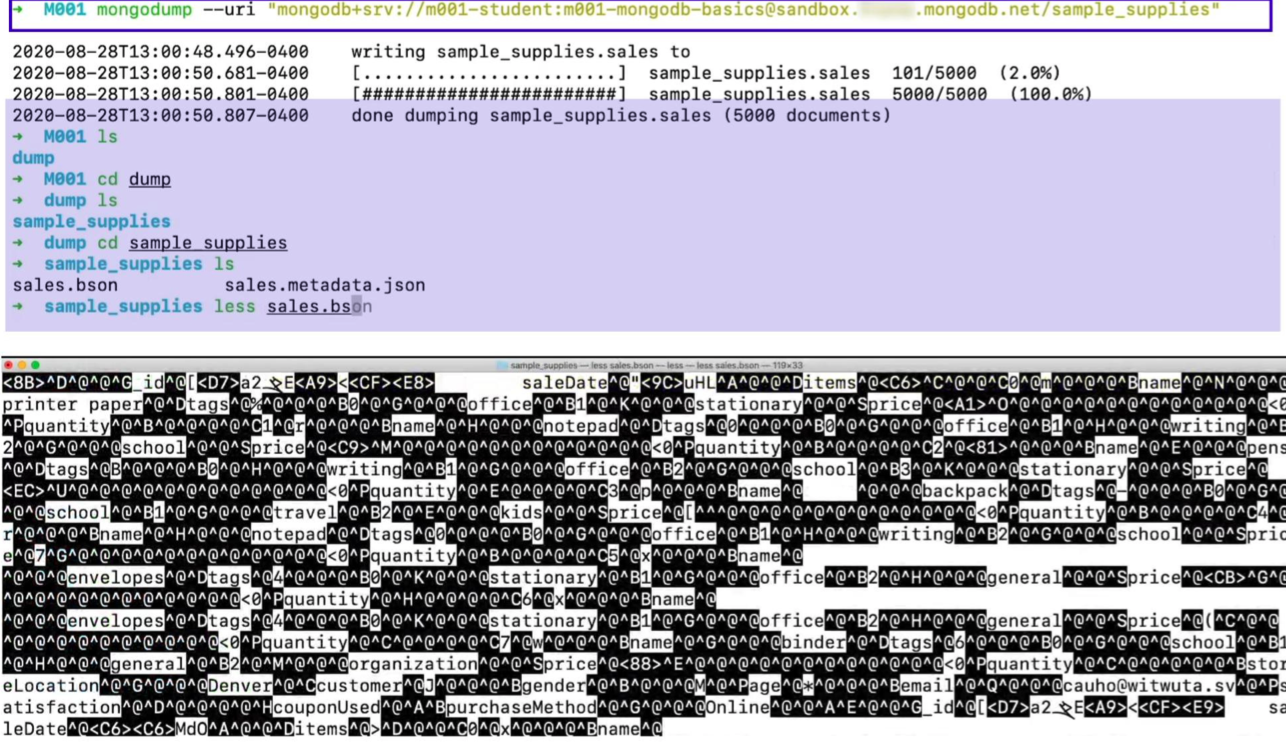
mongodump를 이용하여 sample_supplies라는 데이터 베이스를 내보내는 것이다.
- 확인해보면 BSON형식으로 내보내져 있다.
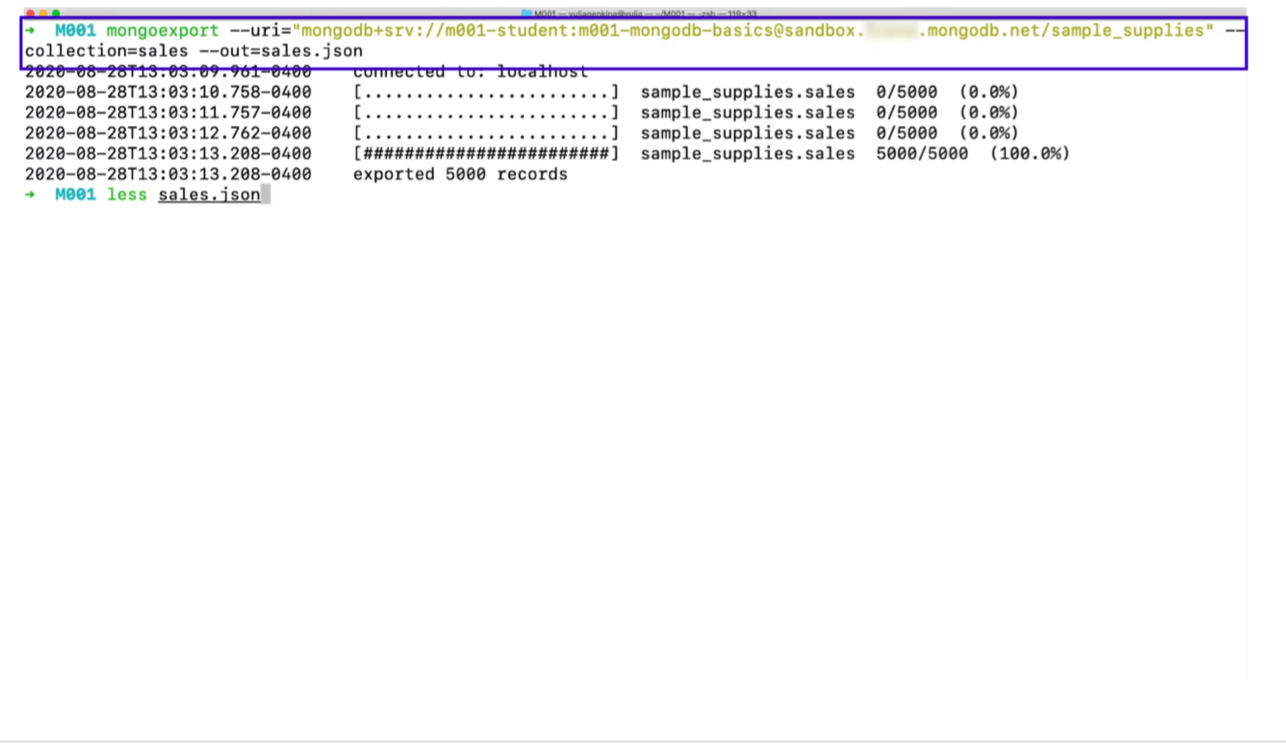
다음은 JSON형태로 내보낸 방법이다.
- 마찬가지로 확인하게 된다면 JSON형식으로 나가있다.
우리가 사용하는 데이터 형식은 JSON인데 BSON으로 내보내야 하는 이유는 뭘까??
- ??
가져오기
- 형식

마찬가지로 형식을 지켜서 내보내기 할떄와 같이 입력을 해주면 된다.
MongoDB CRUD
도큐먼트의 고유의 값인 id와 새로운 도큐먼트를 추가하는 방법에 대해서 알아보자.
SQL에서 primary key가 필수인 것처런 NoSQL에서도 id값이 필수적으로 있어야 한다.
- id 필드의 값은 각 도큐먼트를 구별하는 역할을 하게 된다.
- 필드와 값이 같더라도 id값이 다르면 다른 도큐먼트로 간주한다.
- 반대로 필드와 값이 달라도 id값이 같으면 같은 도큐먼트로 인지한다.
CREATE
컬렉션을 생성, 컬렉션에 값을 넣는 것을 다룬다.
일단 기본적으로 NoSQL은 컬렉션의 생성에 제약을 두지 않는다.
- 기존에 없는 컬렉션(A)에 그냥 바로 insert하게 되면 A컬렉션이 만들어 지면서 값이 들어가게 된다.
기존에 있는 컬렉션이 값을 추가하기 위해서는 우리는 몇가지 사항을 지켜주어야 한다.
- id값이 중복되면 안된다.
- 고유한 값이기 떄문에 만약 중복되는 id값을 입력하면 오류가 발생한다.
- id값이 입력된 데이터를 집어 넣어야 한다.
- 1과 같은 이유이다.
- 작업 순서는 순차적으로 이루어진다(바꿀수도 있음)
- 말그대로 앞에서 부터 이루어 지는 것이다
- 만약 특정 컬렉션에 A,B,C를 넣게 되었을떄
- B에서 오류가 발생을 하면 A는 삽입이 이루어 지고 B,C는 삽입이 이루어 지지 않는다.
기본적인 insert문
`db.컬렉션명.insert(도큐먼트)`
-> db.zips.insert({"_id" : "1", "test":"1"})
zips라는 컬렉션에 id가 1, test가 1인 도큐먼트를 삽입한다.
READ
show dbs
- 저장된 데이터 베이스를 보는 명령어 이다.
use [dbs]
- 사용한 데이터베이스를 선택하는 명령어이다.
show collections
- 사용중인 데이터베이스에 어떤 컬렉션이 있는지 확인하는 명령어
db.컬렉션 이름.find(쿼리문)
- 해당 컬렉션에 있는 데이터 중에서 쿼리문에 해당하는 값을 찾는 것이다.
db.zips.find({"state":"NY"})

- state가 NY인 데이터만 가져 오는 것이다.
만약 조건을 두가지 주고 싶다면
db.zips.find({"state":"NY", "city" : "ALBANY"})

만약 모든 값을 보고 싶다면
db.zips.find()
하지만 이런식으로 불러오는 데이터들은
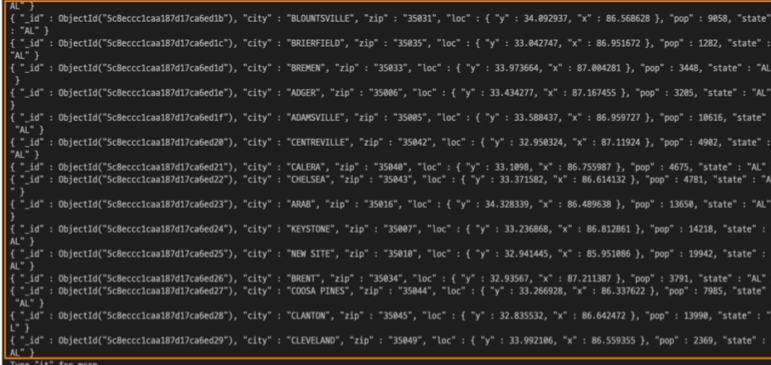
이렇게 보기 어렵다.
그러기 떄문에 간단하게
db.zips.find().pretty()를 추가해서 적어주면
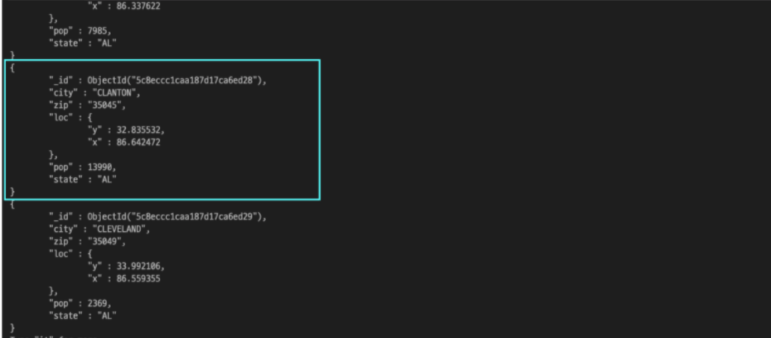
좀더 알기 쉽게 값을 가져와 준다.
만약 데이터의 수를 알고 싶다면
db.zips.find().conut()
이렇게 활용하자
만약 특수하게 저 많은 데이터중 단 한개만의 데이터를 가지고 오고 싶다면
db.zips.findOne({"_id": "~~"})
이렇게 지정한 쿼리문에 해당하는 값이 단 한개만 가져오고
만약 쿼리문을 적지않는다면 저 많은 값중 단 한개의 무작위한 데이터를 가져온다.
UPDATE
단 두가지 방법이 있다.
- updateOne
- updateMany
만약 특정 도시에서 지역에 대한 인구증가를 표현한다고 하자
전체적으로 10명정도가 증가했다고 하면 updateOne보다는 updateMany가 효율적일 것이다.
- 기본 형식이다.

우리는 update할떄 MQL연산자를 사용할 필요가 있다.
- 이 명령문은 조건에 맞는 데이터의 pop수치를 10증가 시킨다는 명령어 이다.
이런 update명령어를 실행하게 되면 두가지 결과가 출력이 된다.
- 조건을 만족하는 도큐먼트 수(city = ALPINE)
matchedCount
- 도큐먼트가 변한 도큐먼트의 수
modifiedCount
updateOne부분도 위와 동일하다.
$inc연산자는 기존에 있는 값을 유지하면서 더하기 뺴기는 해준다.
- +=, -= 와 같은 연산자이다.
하지만 만약 값을 완전히 수정해야 한다면( 12345 -> 7943)
우리는 $set연산자를 사용 하면 된다.
- 사용 하는 위치는 위에 사진과 같다.
하지만 만약 우리가 필드를 잘못 입력하면 어떻게 될까??
- 업데이트해야할 필드는
"pop"인데 만약"population"으로 입력을 하게 되면 - 그냥 단순하게
"population"이라는 필드가 하나 생겨나게 된다.
배열에 값을 업데이트 하는 방법
이러한 배열의 형태에 값을 추가 및 수정하는 법을 알아보자
- 형식이다.
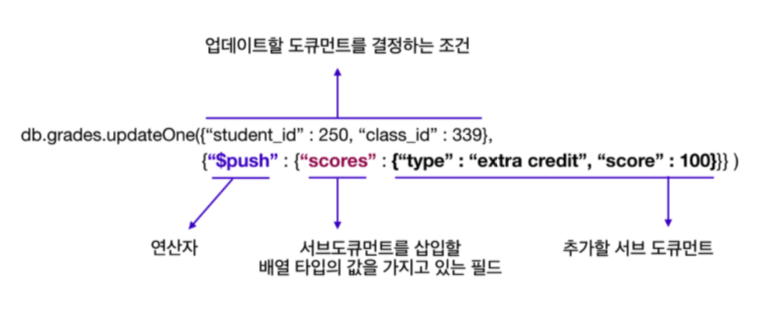
많이 어려운 점은 없다 우리는 배열안에 값을 넣는 작업이 목표이기 떄문에 $push연산자를 활용하여 값을 넣어주면 된다.
DELETE
update와 같다.
deleteOne, deleteMany이 두가지 명령어를 활용한다.
- 형태 또한 동일하다.
db.컬렉션명.drop()
- 컬렉션을 삭제하는 명령어
