목차
- 트라이란?
- 트라이 예시
- 장점과 단점
1. 트라이란?
문자열에 저장하고 탐색하는데 특화된 트리 구조의 일종입니다.
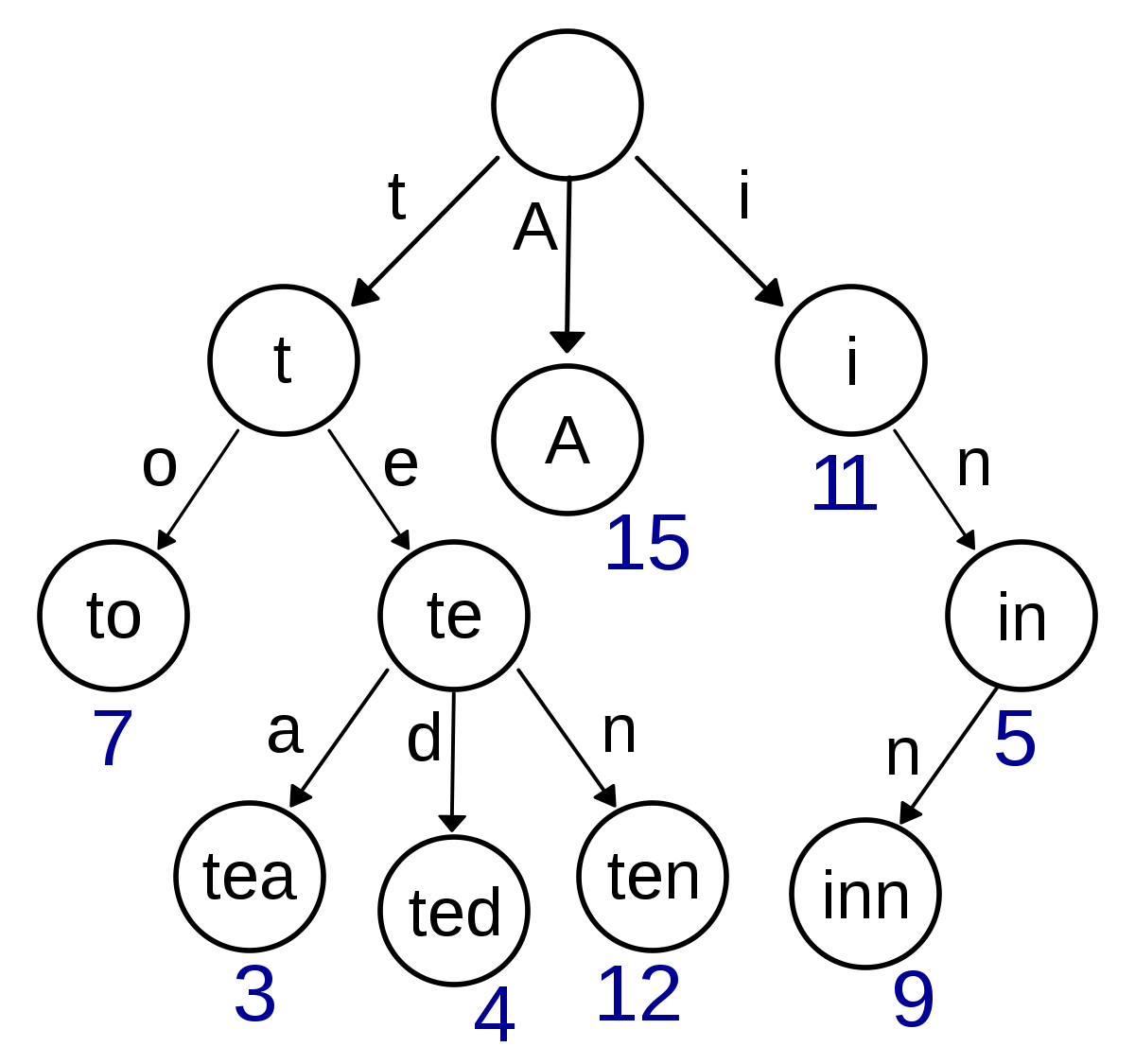
위 예시처럼 각 노드에는 생성된 문자열과 끝을 나타내는 변수를 추가해서 저장된 단어의 끝을 구분할 수 있습니다.
위 예시에는 "to, tea, ted, ten, A, i, in, inn"이 트라이에 들어있습니다.
2. 트라이 예시
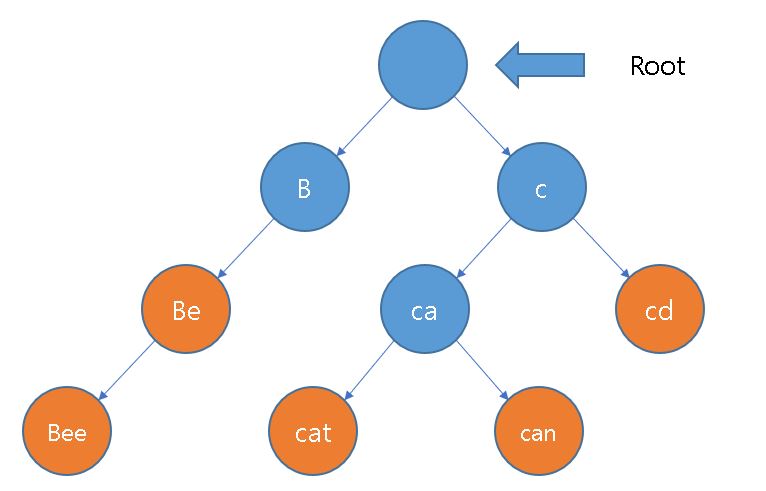
[Be, Bee, cat, can, cd]를 추가하며 생성과정을 보여드리겠습니다.
우선 문자열이 저장되있지 않은 root노드를 준비합니다.
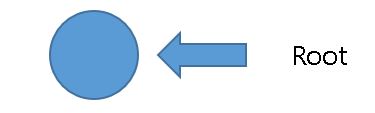
"Be"를 추가해 보도록 하겠습니다.
root의 자식 노드중 "B"가 있는지 확인합니다.
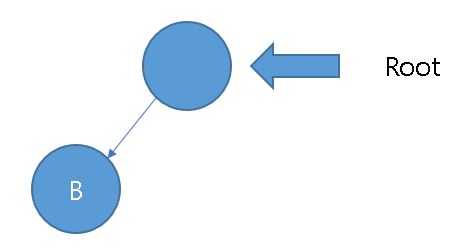
없는 것을 확인했으니 "B"를 포함한 문자를 저장한 노드를 추가합니다.
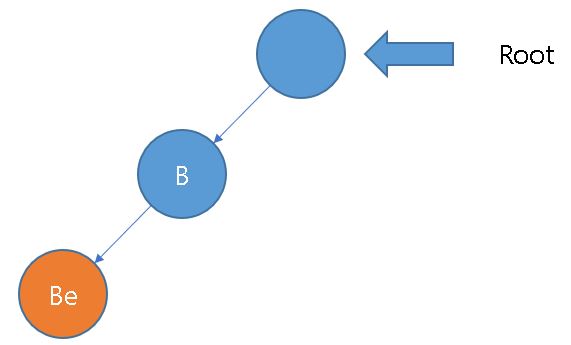
같은 순서로 "e"를 진행합니다.

한 단어가 끝이 났음으로 그 노드에 단어가 끝났음을 표시합니다.
이러한 과정을 끝까지 진행하면 아래와 같은 형태가 됩니다.
3. 장점과 단점
3-1. 장점
시간 복잡도: 문자열의 길이가 N이라고 했을 때 시간복잡도는 O(N)입니다.
Map같은 다른 자료구조를 사용할 경우 검색과 확인을 따로 진행해야 하기 때문에 시간적인 측명에서 trie는 긍정적인 면모를 보입니다.
3-2. 단점
공간 복잡도: 알파벳을 예시로 들어보겠습니다.
각각의 노드는 26개의 배열을 가지고 있어야 하며 결국 최종 메모리의 경우 (포인터의 크기 X 배열의 갯수 X 노드의 갯수)가 됩니다.

개발자 취준생 입니다.