목차
- 허프만 코딩이란?
- 접두부
- 인코딩 과정
- 디코딩 과정
1. 허프만 코딩이란?
데이터 문자의 등장 비도수에 따라서 다른 길이의 부호화를 사용하는 알고리즘 입니다.
2. 접두부
허프만 코딩은 각 문자에 부여된 이진 코드가 접두부가 되지 않도록 합니다.
여기서 의미하는 접두부에 대해 설명하겠습니다.
A -> 101
B -> 100
으로 인코딩 되었을 경우 A와 B의 접두부는 '10'이 됩니다.
여기서 C를 '10'으로 인코딩 한다면 다음과 같은 문제가 발생합니다.
101 == A or C + ?
인코딩된 코드 101... 을 디코딩 했을 시에 이 코드가 A를 인코딩한 것인지 아니면 C와 다른 문자를 인코딩한 것인지 알 수 없습니다.
허프만 코딩을 사용하면 각 문자에 부여된 코드는 다른 문자에 부여된 코드에 접두부가 되지 않기 때문에 이러한 문제가 발생하지 않습니다.
3. 인코딩 과정
인코딩할 문자 = ABCACDDDDDC
위 문자를 인코딩하면서 설명하도록 하겠습니다.
압서 설명드렸듯이 각 문자의 등장 빈도수를 측정합니다.

여기서 측정한 빈도수를 우선순위로 하여 정렬합니다.

가장 작은 빈도수를 가진 2가지 문자를 같은 부모 노드를 가진 서브트리로 만듭니다.
부모 노드에는 자식 노드의 빈도수의 합을 저장합니다.
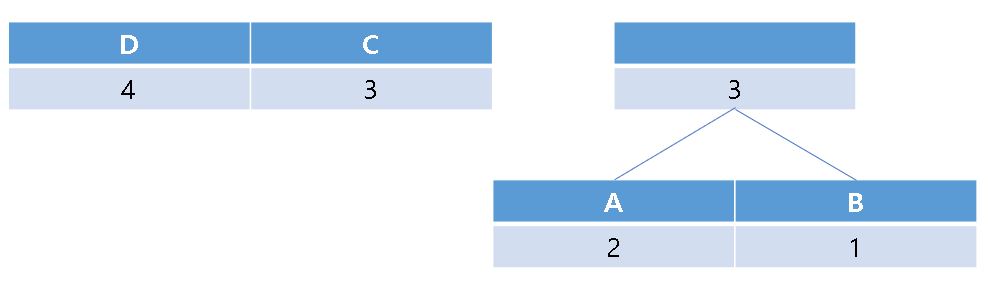
위 과정을 하나의 트리가 남을 때까지 반복합니다.
이후 아래와 같은 트리가 만들어 집니다.
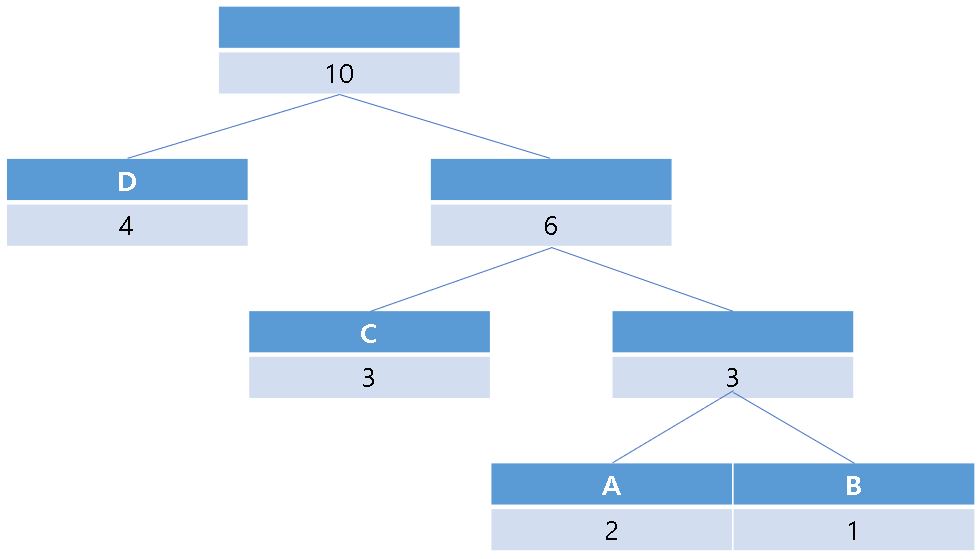
이후 root에서부터 왼쪽의 자식 노드에는 '0'을 오른쪽의 자식 노드에는 '1'을 부여하는 방식으로 각 문자를 인코딩해 줍니다.

앞서 설명 드렸듯이 각 문자열에 부여된 코드는 다른 코드의 접두부가 되지 않는 것을 확인할 수 있습니다.
위 인코딩된 문자를 기준으로 처음 주어줬던 문자열을 인코딩하면 아래와 같은 결과를 얻습니다.
ABCACDDDDDC => 1101111011010000010
4. 디코딩 과정
인코딩 했던 예시를 디코딩해 보겠습니다.
이론적으로는 root에서 0이 나오면 왼쪽, 1이 나오면 오른쪽으로 찾아나가 leaf 노드를 찾을 때까지 이를 반복해 주면 됩니다.
처음에는 1이니 오른쪽입니다.
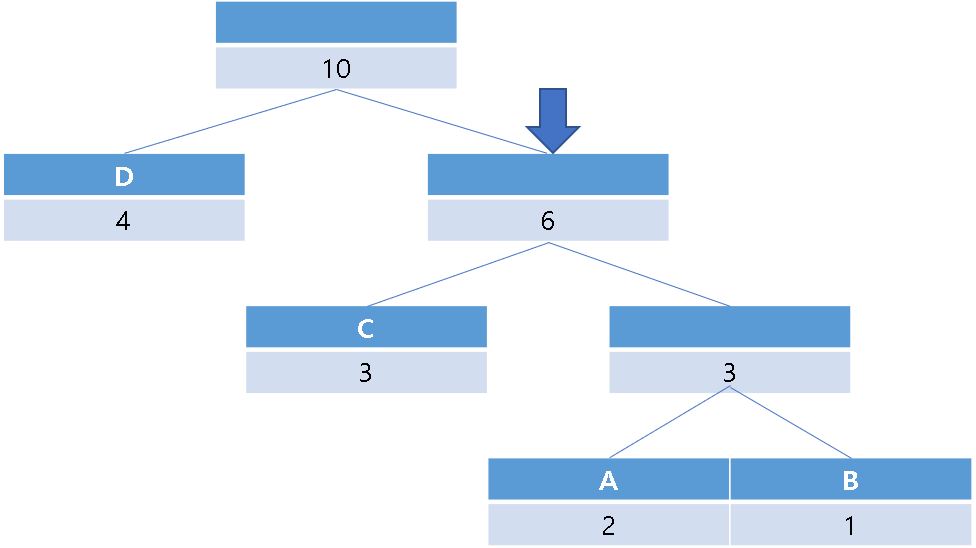
leaf 노드에 도달할 때 까지 반복할 경우 A(110)에 도달합니다.
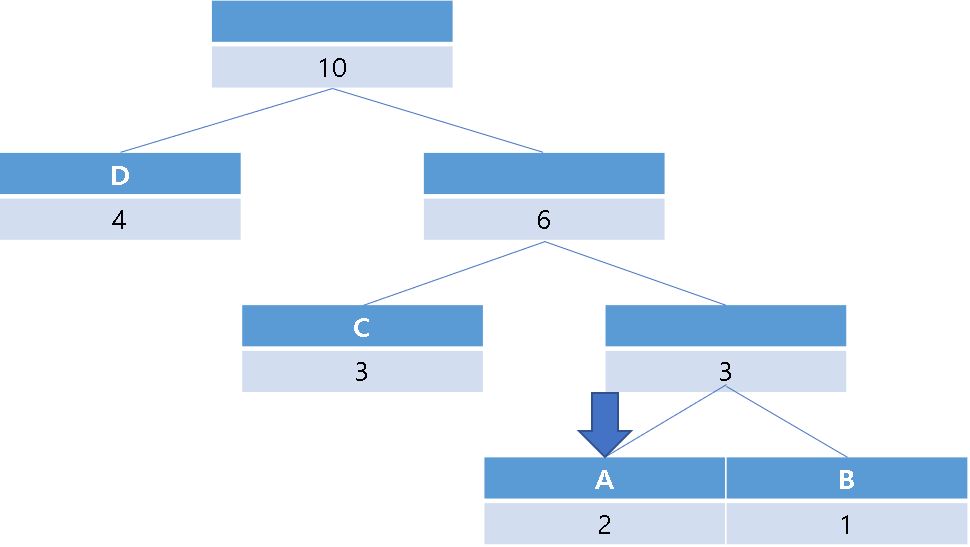
이 과정을 끝까지 반복하면 원래 문자열인 "ABCACDDDDDC"를 찾을 수 있습니다.
