🎈 Multi - DAE
👌 Multi
- 다항 분포를 이용해서 확률을 계산하기 때문에 multi라는 이름을 이용함
- loss function에서 다항 예측 함수를 사용함 !
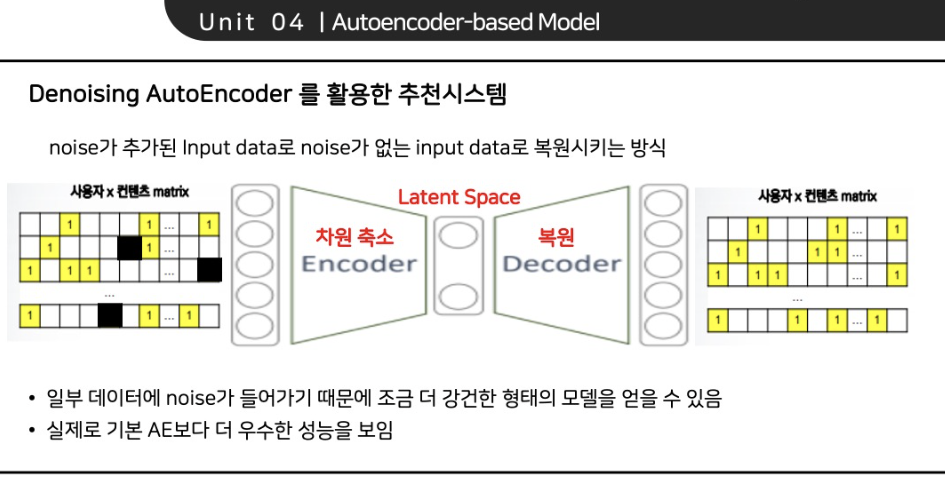
👌 DAE(Denoising Auto Encoder)
- Denoising, 즉 Input(x)에 Noise(dropout=0.5)를 줘서, 깨끗하지 못한 인풋 데이터에 대해서도 축약된 latent representation(z)를 통해서 output(x')값이 추천을 잘할 수 있는 값으로 복원될 수 있도록 하는 Auto Encoder Model
📍 Model에 대한 이해
📍 Loss Function 이해
📍 Metric 이해
✨ 가설 진행
1. Domain 이해를 바탕으로 Side-information을 Embedding 생성 및 적용
- 우선, 장르와 영화 제목이 제일 중요하다고 판단해서 Embedding을 통해 모델의 input에 적용
- numerize 함수에 라벨 인코딩 진행
- 각 유저별 시청 영화에 대해서 장르, 제목을 매핑하고 리스트를 extend하는 식으로 Batch별 장르, 제목 리스트 생성
단, 유저와 아이템간의 Batch Sparse matrix는 하나만 있어야 하기 때문에 반복문 첫 번째에만 생성
- 생성된 리스트를 배치별로 임베딩으로 적용해서 train & evaluate 적용
- 최종적으로 추천 영화 output 결과 값에 대해서 inference 진행
변경 Part (For Collaboration)
- Load Data - Dataset 구성
한계점? 영화별 장르 하나만 선택해서 하는 거라 각 영화별의 특징을 다 담지 못함 (임베딩) -> 프리트레인 파트 이용하면 더 좋아질 것 같다
- Build the model - Model 정의
- Trainig Code - Batch, Train, Eval function
- CUDA out of memory
-
Train, data, test split
-
Model
-
Train
-
Eval
- 실험 결과 및 해석
ML20m에서 80-100 그룹에서는 DAE가 성능이 더 높음
→ 이건 많은 데이터가 있을 때 오히려 VAE 접근법 (prior assumption) 이 더 성능을 낮춘다고 해석 가능함
실제로 이번 대회의 Sparsity는 약 97.5%로 데이터가 많은 것에 해당한다고 볼 수 있음 (0점대의 희소가 아니라는 점)
sequential data에 강한 BERT4Rec, SASRec보다 static data에 좀 더 강점을 보이는 auto encoder가 더 좋은 추천 결과를 보이는 게 아닌가 하는 생각이 들었다.
- 실험 분석
valid, test : 약 35%의 Recall 결과
실제 test : 약 13.84%의 Recall 결과
- 여기서 생각해볼만한 점
- 일단, 시퀀셜한 파트를 채워야 하기 때문에 성능이 당연히 떨어지는 거임
- 실제로 기존에 시청했던 데이터들이 testset에 많이는 포함되지 않은 것 같다라는 의심을 할 수 있음 (중간에 구멍에 의해서?!)
- 기본 모델이기 때문에, 대회에 맞게 더 손봐야 할 필요가 있음
K-fold
train → 정답 데이터(-무한대)
😎 Numpy
🎈 Numpy 함수 정리
- argsort : 크기 순으로 index를 뱉어냄
- np.nonzero()
>> import numpy as np >> a=np.array([1, 0, 2, 3, 0]) >> np.nonzero(a) (array([0, 2, 3]),)
- 대회 Code
# Exclude examples from training set recon_batch = recon_batch.cpu().numpy() recon_batch[data.nonzero()] = -np.inf→ 시청 이력 있는 items -무한대로 설정
- np.random.choice(a, b)
→ a에서 b개를 뽑아라!
🎈 Numpy 희소행렬을 SciPy 압축 희소 열 행렬 (Compressed sparse row matrix)로 변환
- arr 넘파이 배열 : scipy.sparse.csr_matrix(arr)
csr_mat = csr_matrix(arr)
- 값 data, '0'이 아닌 원소의 열 위치 indices, 행 위치 시작 indptr
=> csr_matrix((data, indices, indptr), shape=(5, 4))indptr = np.array([0, 2, 5, 5, 7, 8]) indices = np.array([1, 3, 1, 2, 3, 0, 3, 1]) data = np.array([1, 2, 3, 4, 5, 6, 7, 8]) csr_mat2 = csr_matrix((data, indices, indptr), shape=(5, 4))
- 값 data, '0'이 아닌 원소의 (행, 열) , 대회 Code
=> csr_matrix((data, (row, col)), shape=(5, 4))sparse.csr_matrix((np.ones_like(rows), (rows, cols)), dtype='float64', shape=(n_users, self.n_items))
- 대회에 있어서 이를 해석하자면, 해당 dataset에 있어서 각 유저별 시청 기록을 1로 설정하고, 이를 희소행렬에 대입하는 방법
- 시도해볼만 한 것
input의 앞에 아이템에 대한 임베딩 벡터를 붙여서 encoder layer에 통과시키는 것

장난감이 데이터인 사람