
🎈[PROGRAMMERS] 그룹별 조건에 맞는 식당 목록 출력하기
SELECT M.MEMBER_NAME, R.REVIEW_TEXT,
DATE_FORMAT(R.REVIEW_DATE, "%Y-%m-%d") AS REVIEW_DATE
FROM REST_REVIEW R LEFT JOIN MEMBER_PROFILE M
ON R.MEMBER_ID = M.MEMBER_ID
WHERE M.MEMBER_ID = (SELECT MEMBER_ID FROM REST_REVIEW
GROUP BY MEMBER_ID
ORDER BY COUNT(*) DESC
LIMIT 1)
ORDER by REVIEW_DATE asc, REVIEW_TEXTSELECT MEMBER_ID FROM REST_REVIEW
GROUP BY MEMBER_ID - 기준으로 의미!!!
ORDER BY COUNT(*) DESC - 기준에 대한 개수를 세서 내림차순 정렬 !!!- 해석
- MEMBER ID 기준으로 (멤버 아이디별로) 각각의 로우 개수 기준으로 정렬시켜라!!! 이런 뜻
- GROUP BY만 사용할 경우 그냥 하나의 그룹으로만 묶게됩니다! 조심!!
🔥GROUP BY 사용 시 주의사항
HAVING 절에 조건을 걸 때는 SELECT문에 추출할 컬럼들에 대해서 GROUP BY를 실행하는 것임!!
🎈[HACKER RANK] 문자열 함수 문제 - CONCAT, SUBSTRING, LOWER
SELECT CONCAT(name, '(', substring(occupation, 1, 1), ')')
FROM Occupations
ORDER BY name, substring(occupation, 1, 1);
SELECT CONCAT('There are a total of ', count(occupation), ' ', LOWER(occupation), 's.')
FROM Occupations
GROUP BY occupation
ORDER BY count(occupation), occupation-
출력값
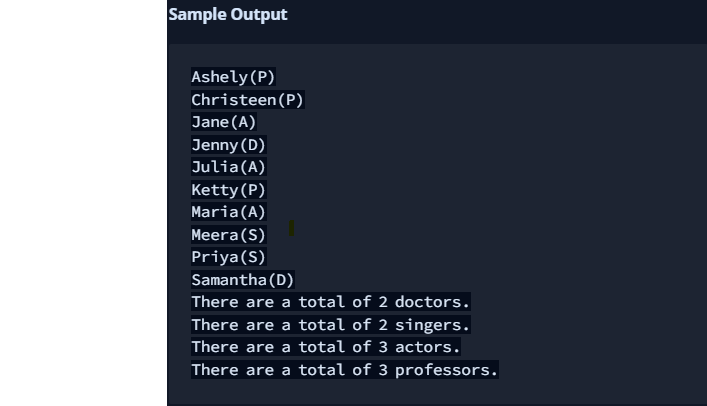
-
FEEDBACK
- PROGRAMMERS에서는 항상 출력값이 테이블 형식이라 이러한 문자열로 도출되는 형식을 어떻게 쿼리를 짜야할 지 당황했습니다
- CONCAT은 알았으나 LOWER와 SUBSTRING을 활용할 줄 몰랐고, 심지어 LOWER의 존재도 몰랐습니다..
- 위와 같이 두 파트로 나눠서 쿼리를 작성하면 결과가 저렇게 나오는지도 몰랐고 이와 같이 풀이한 경험이 없어서 당황했습니다..
🔥문자열 함수 정리
SUBSTRING
SUBSTRING(슬라이싱하고 싶은 대상, START INDEX, 크기 지정)
- 예시
ORDER BY substring(occupation, 1, 1) # OCCUPATION을 1번째 부터 1개의 크기까지 문자열을 추출해라 !LOWER, UPPER, INITCAP
LPAD, RPAD

장난감이 데이터인 사람