4주차 WIL
1. Transformer가 RNN, LSTM과 다른점을 정리해주세요.
ransformer는 기존의 Recurrent Neural Network (RNN) 및 그 변형인 Long Short-Term Memory (LSTM)이 가졌던 근본적인 한계를 극복하기 위해 제안된 모델입니다.
| 특징 | RNN/LSTM | Transformer |
|---|---|---|
| 핵심 메커니즘 | 재귀 (Recurrence): 이전 스텝의 출력을 현재 스텝의 입력으로 사용 | Self-Attention (자기-주목): 시퀀스 전체를 한 번에 주목 |
| 병렬 처리 | 불가능/어려움: 순차적인 계산 필수 | 가능: 각 위치의 단어를 동시에 처리 |
| 장거리 의존성 | 정보 손실/취약: 거리가 멀어질수록 앞선 정보 망각 (기울기 문제) | 효율적: 거리에 관계없이 모든 단어와 직접 연결 |
| 속도 | 느림 | 빠름 |
요약: Transformer는 재귀 구조를 완전히 제거하고 Attention Is All You Need라는 철학을 구현하여, RNN/LSTM의 고질적인 문제인 병렬 처리 한계와 장거리 의존성 문제를 해결했습니다.
2. Positional Embedding에 대해서 정리해주세요.
Transformer는 재귀 구조를 없애 순서 정보를 잃어버렸습니다. 이 순서 정보를 다시 주입하기 위한 기술이 Positional Encoding입니다.
- 필요성: Attention은 모든 단어를 동시에 보기 때문에, 문장에서 "사과가 책상 위에 있다"와 "책상 위에 사과가 있다"를 구분할 수 없습니다.
- 원리: 각 단어 임베딩에 해당 단어의 위치에 따른 고유한 벡터를 더해줍니다.
- 구현: 주로 사인(sine) 및 코사인(cosine) 함수를 사용하여, 문장의 길이가 달라도 일관성 있는 상대적 위치 정보를 모델에 제공합니다.
3. Multi-Head Self-Attention, Feed Forward Network (FFN), Residual Connection, Layer Normalization 에 대해서 정리해주세요.
Transformer의 인코더와 디코더는 기본적으로 동일한 구조를 반복하며 쌓아 올린 형태입니다. 각 레이어는 다음과 같은 핵심 모듈로 구성됩니다.
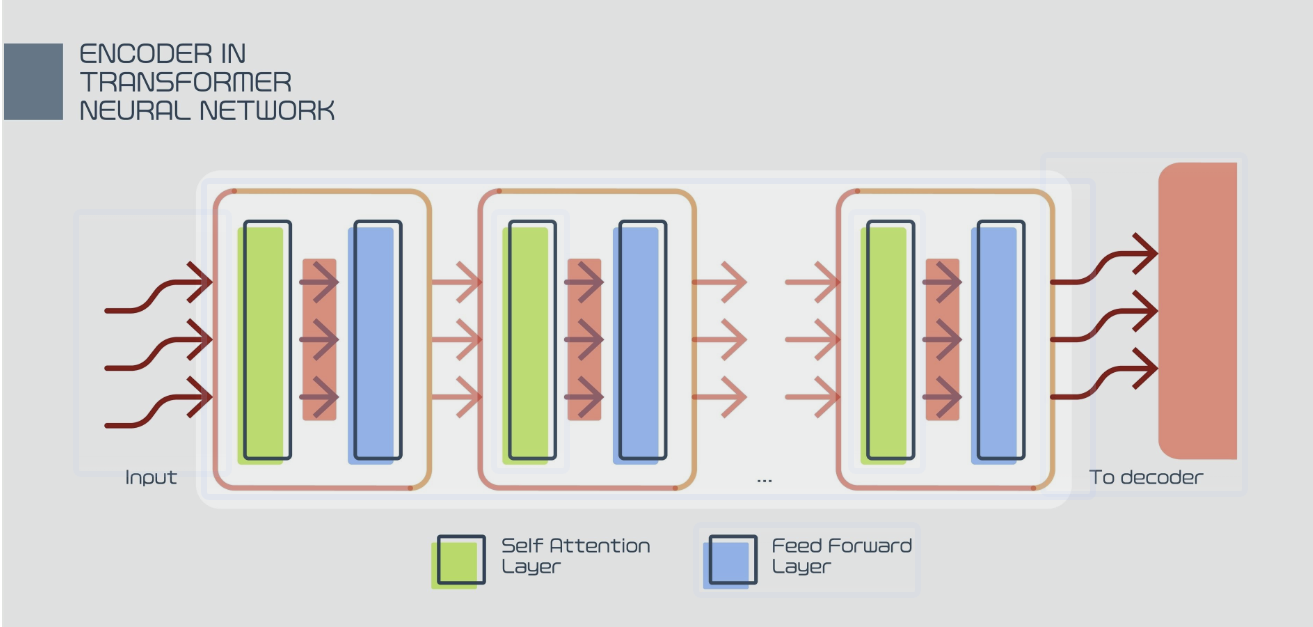
Multi-Head Self-Attention (MHSA)
시퀀스 내의 각 단어가 다른 모든 단어와의 관련성(중요도)을 계산하여 새로운 벡터를 얻는 메커니즘입니다.
- Q (Query), K (Key), V (Value): 입력 벡터 를 각각 라는 가중치 행렬로 선형 변환하여 얻습니다.
- Self-Attention 수식:
- Multi-Head의 역할: 하나의 어텐션 대신 여러 개의 어텐션(Head)을 병렬로 수행하여, 문장의 다양한 측면(문법, 의미 등)에서 관계를 동시에 포착하고 표현력을 높입니다.
Feed Forward Network (FFN)
Attention 레이어에서 나온 정보를 비선형적으로 변환하여 모델의 표현 능력을 확장합니다.
- 구조: 두 개의 선형 변환 레이어와 그 사이에 ReLU 활성화 함수로 구성된 간단한 신경망입니다.
- 특징: 시퀀스의 각 위치(단어)별로 독립적으로 동일한 FFN을 적용합니다.
Residual Connection (잔차 연결)
이전 레이어의 입력 를 그 다음 레이어의 출력에 그대로 더해주는 방식입니다.
- 목적: 레이어가 깊어질수록 발생하기 쉬운 정보 손실을 방지하고, 기울기 소실(Vanishing Gradient) 문제를 완화하여 안정적인 학습을 돕습니다.
- 수식:
Layer Normalization (레이어 정규화)
Residual Connection의 결과를 안정적으로 학습하기 위해 사용됩니다.
- 방식: 배치 내의 샘플이 아니라, 하나의 샘플(시퀀스)에 대해 임베딩 차원을 따라 평균과 분산을 계산하여 정규화합니다.

hello