GDG 프로젝트 트랙5기 실습 1주차
TensorFlow와 데이터셋으로 시작하는 텍스트 전처리 심화 분석
안녕하세요! 딥러닝 모델 학습의 핵심 단계 중 하나인 텍스트 데이터 전처리 과정을 상세히 살펴보는 시간을 갖겠습니다. 특히, TensorFlow 라이브러리를 활용하여 네이버 영화 리뷰 데이터를 준비하는 과정을 단계별로 분석해 보겠습니다.
1. 필수 라이브러리 임포트 및 환경 설정
가장 먼저, 실습을 위한 기본 환경을 준비합니다.
- TensorFlow는 딥러닝 모델을 구축하고 학습하는 데 사용됩니다.
- NumPy와 Pandas는 데이터 조작 및 배열 처리를 위해 사용되는 핵심 라이브러리입니다.
import tensorflow as tf
import numpy as np
import pandas as pd
print("TensorFlow version:", tf.__version__)현재 사용 중인 TensorFlow 버전을 확인하는 것은 실습 환경의 안정성을 점검하는 첫 단계입니다.
2. NSMC 데이터셋 다운로드 및 텍스트 로드
딥러닝 모델 학습을 위한 데이터셋으로 네이버 영화 리뷰 감성 분석 (NSMC) 데이터를 사용합니다.
path_to_train_file = tf.keras.utils.get_file(
'train.txt',
'<https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt>'
)
path_to_test_file = tf.keras.utils.get_file(
'test.txt',
'https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt'TensorFlow의 keras.utils.get_file 함수를 사용하여 GitHub에 저장된 데이터를 자동으로 다운로드합니다. 이 방식은 Colab과 같은 환경에서 데이터를 쉽게 불러올 수 있게 해줍니다.
다운로드한 파일은 바이너리 모드('rb')로 읽어온 뒤, 한국어가 깨지지 않도록 UTF-8 인코딩으로 디코딩하여 실제 텍스트로 변환합니다.
train_text = open(path_to_train_file, 'rb').read().decode(encoding='utf-8')
test_text = open(path_to_test_file, 'rb').read().decode(encoding='utf-8')
print('Length of train text: {} characters'.format(len(train_text)))
print('Length of test text: {} characters'.format(len(test_text)))
print(train_text[:300])
# ... (출력 결과)
Length of train text: 6937271 characters
Length of test text: 2318260 characters
id document label
9976970 아 더빙.. 진짜 짜증나네요 목소리 0
3819312 흠...포스터보고 초딩영화줄....오버연기조차 가볍지 않구나 1
10265843 너무재밓었다그래서보는것을추천한다 0
9045019 교도소 이야기구먼 ..솔직히 재미는 없다..평점 조정 0
6483659 사이몬페그의 익살스런 연기가 돋보였던 영화!스파이더맨에서 늙어보이기만 했던 커스틴 던스트가 너무나도 이뻐보였다 1
5403919 막 걸음마 뗀 3세부터 초등학교 1학년생인 8살용영화.ㅋㅋㅋ...별반개도 아까움. 0
7797314 원작의텍스트 데이터를 확인해 보면, 각 행이 id, document(리뷰 문장), label(감성 라벨)의 탭(\t)으로 구분된 형태임을 알 수 있습니다.
3. 정답 라벨(Y) 및 리뷰 문장(X) 분리
로드된 전체 텍스트에서 모델의 **입력(X)**인 리뷰 문장과 **정답(Y)**인 감성 라벨을 분리합니다.
3.1. 정답 라벨(Y) 만들기
감성 라벨은 탭으로 구분된 세 번째 항목([2])에 위치하며, 0은 부정 리뷰, 1은 긍정 리뷰를 나타냅니다.
train_Y = np.array([
[int(row.split('\t')[2])] # 세 번째 항목을 정수형으로 변환
for row in train_text.split('\n')[1:]
if row.count('\t') > 0
])
test_Y = np.array([
[int(row.split('\t')[2])]
for row in test_text.split('\n')[1:]
if row.count('\t') > 0
print("train_Y shape:", train_Y.shape)
print("test_Y shape:", test_Y.shape)
print("train_Y sample:", train_Y[:5])
# (출력 결과)
train_Y shape: (150000, 1)
test_Y shape: (50000, 1)
train_Y sample: [[0]
train_Y sample: [[0], [1], [0], [0], [1]]이렇게 분리된 train_Y와 test_Y는 모델이 예측할 최종 타깃(Target) 데이터가 됩니다.
3.2. 리뷰 문장(X) 분리 및 정제
모델의 입력 데이터인 리뷰 문장(document)은 탭으로 구분된 두 번째 항목([1])입니다. 이 문장들을 분리하고 정제하여 train_text_X로 만듭니다.
# (출력 예시)
[['아', '더빙', '진짜', '짜증나네요', '목소리'], ['흠', '포스터보고', '초딩영화줄', ...]]분리된 문장들은 이후 TextVectorization 레이어의 입력으로 사용됩니다.
4. 텍스트 정수 인코딩 (TextVectorization)
딥러닝 모델은 텍스트를 직접 처리할 수 없으므로, 모든 문장을 고정된 길이의 숫자 시퀀스로 변환해야 합니다. 이를 위해 TensorFlow의 강력한 TextVectorization 레이어를 사용합니다.
| 설정 변수 | 값 | 역할 |
|---|---|---|
VOCAB_SIZE | 2000 | 단어 사전 크기: 빈도가 높은 상위 2000개의 단어만 학습에 사용 |
MAX_LEN | 25 | 최대 문장 길이: 모든 문장의 길이를 25로 통일 (패딩/자르기 기준) |
vectorize_layer = tf.keras.layers.TextVectorization(
standardize='lower_and_strip_punctuation', # 소문자 변환 + 구두점 제거
split='whitespace', # 띄어쓰기 기준 토큰화
max_tokens=VOCAB_SIZE, # 단어 사전 크기 제한
output_mode='int', # 결과를 정수 인덱스로 변환
output_sequence_length=MAX_LEN # 자동 패딩/자르기
)
vectorize_layer.adapt(train_text_X) # 훈련 데이터로 단어 빈도 및 사전 학습
train_X = vectorize_layer(train_text_X)adapt() 메서드를 통해 훈련 데이터의 단어 빈도를 학습하고, 이를 바탕으로 단어 사전을 구축합니다. vectorize_layer(train_text_X)를 실행하면, 각 문장의 단어가 정수 인덱스로 바뀌고, 길이가 25로 통일된 tf.Tensor가 생성됩니다. 짧은 문장은 0으로 채워집니다(패딩).
print(train_X[:5])
# (출력 결과)
tf.Tensor(
[[ 23 902 5 1 1097 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0]
[ 586 1 1 1 1 1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0]
[ 1 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0]
[ 1 1 68 345 28 33 1 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0]
[ 1 1 102 1 2 1 1 844 1 1 570 1 0 0
0 0 0 0 0 0 0 0 0 0 0]], shape=(5, 25), dtype=int64)5. 문장 길이 분포 시각화 및 검증
MAX_LEN을 25로 설정한 것이 적절한지 검증하기 위해 문장 길이의 분포를 시각화합니다.
import matplotlib.pyplot as plt
# ... 길이 계산 및 정렬 코드 생략
plt.plot(sentence_len)
plt.show() #
print(sum([int(l <= 25) for l in sentence_len]))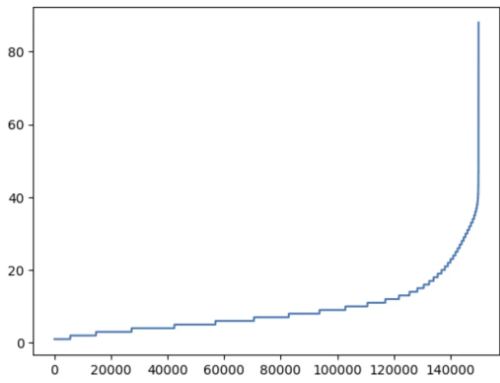
문장 길이를 오름차순으로 정렬하여 시각화한 결과, 그래프를 통해 대부분의 문장(거의 90% 이상)이 단어 25개 이하임을 명확히 확인할 수 있습니다. 이로써 MAX_LEN = 25 설정이 데이터의 손실을 최소화하면서도 효율적인 모델 학습을 가능하게 하는 합리적인 기준임을 검증할 수 있습니다.
이 모든 전처리 과정을 거쳐, 복잡한 텍스트 데이터는 딥러닝 모델이 곧바로 학습할 수 있는 깨끗하고 정형화된 숫자 배열 형태로 완벽하게 변환되었습니다!
