인공지능/머신러닝 기본 개념 정리
인공지능 및 머신러닝 분야의 기본 개념들을 블로그 글로 정리했습니다.
1. 기본 파이썬 라이브러리 개념
머신러닝과 데이터 분석에서 필수적으로 사용되는 세 가지 핵심 파이썬 라이브러리입니다.
- Numpy (Numerical Python)
- 개념: 대규모 다차원 배열을 효율적으로 처리할 수 있도록 돕는 라이브러리입니다.
- 역할: 고성능 수치 계산을 지원하며, 텐서플로우와 같은 다른 라이브러리에서도 기본적인 데이터 구조로 사용됩니다.
- Pandas
- 개념: 데이터 조작 및 분석을 위한 라이브러리로, DataFrame이라는 강력한 자료구조를 제공합니다.
- 역할: 데이터를 읽고, 정렬하고, 필터링하며, 통계적인 분석을 수행하는 등 데이터 전처리 및 분석 과정에서 광범위하게 사용됩니다.
- TensorFlow
- 개념: 구글에서 개발한 오픈 소스 머신러닝 및 딥러닝 라이브러리입니다.
- 역할: 대규모 수치 계산과 신경망 모델 구축, 훈련, 배포 등을 위한 강력한 도구를 제공합니다.
2. Keras와 TensorFlow의 역할 관계
- Keras란?
- 개념: 텐서플로우 위에서 실행되는 고수준 API입니다. 빠르고 쉽게 신경망 모델을 구축할 수 있도록 설계되었습니다.
- 특징: 사용자 친화적이고 모듈화되어 있으며, 신속한 프로토타이핑을 가능하게 합니다.
- TensorFlow와 Keras의 관계
- Keras는 원래 별도의 프로젝트였으나, 현재는 TensorFlow의 공식 고수준 API로 통합되었습니다.
- 역할: Keras는 사용자가 직관적으로 모델을 정의할 수 있게 도와주는 '인터페이스/뼈대' 역할을 하고, TensorFlow는 Keras가 정의한 모델을 실제로 계산하고 실행하는 '백엔드 엔진' 역할을 수행합니다.
3. 훈련 데이터(Train)와 테스트 데이터(Test)
머신러닝 모델을 개발할 때 데이터를 두 가지 용도로 분리하여 사용합니다.
- 훈련 데이터 (Train Data)
- 개념: 머신러닝 모델이 학습하는 데 사용되는 데이터셋입니다.
- 역할: 모델이 데이터의 패턴과 특징을 파악하고 가중치를 조정하여 예측 능력을 키우는 데 사용됩니다.
- 테스트 데이터 (Test Data)
- 개념: 모델의 성능을 평가하는 데 사용되는 데이터셋입니다.
- 역할: 모델이 한 번도 보지 못한 새로운 데이터에 대해 얼마나 잘 일반화(Generalize)하는지 측정하여 최종적인 성능을 검증하는 데 사용됩니다.
4. 과적합(Overfitting)과 데이터 관계
- 과적합(Overfitting)이란?
- 개념: 모델이 훈련 데이터에 너무 완벽하게 맞춰져서, 훈련 데이터에서는 매우 높은 성능을 보이지만, 실제 테스트 데이터나 새로운 데이터에서는 성능이 급격히 떨어지는 현상입니다.
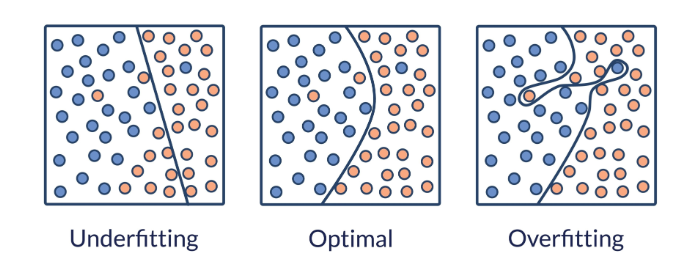
* **문제 발생:** 모델이 데이터의 **본질적인 패턴**이 아닌, 훈련 데이터에만 존재하는 **노이즈(Noise)**나 **우연한 특성**까지 암기해버리기 때문에 발생합니다. 훈련 데이터와 테스트 데이터의 관계에서 모델의 **일반화 능력**이 부족하다는 심각한 문제를 야기합니다.5. 지도학습(Supervised Learning)의 개념과 구조
- 개념: 학습할 때 **입력(문제)**과 그에 대응하는 **정답(레이블)**을 함께 제공받아 학습하는 방식입니다. 마치 선생님(Supervisor)이 정답을 알려주면서 가르치는 것과 같습니다.
- 구조
- (입력 특성, Feature): 모델이 예측하기 위해 사용하는 데이터입니다. (예: 이메일의 내용)
- (출력 레이블, Label/Target): 에 대응하는 정답입니다. (예: 스팸/정상)
- 역할: 모델은 입력 를 받아 정답 를 가장 잘 예측하는 규칙을 학습하게 됩니다.
6. 지도학습과 비지도 학습의 차이점
| 구분 | 지도학습 (Supervised Learning) | 비지도 학습 (Unsupervised Learning) |
|---|---|---|
| 정답 (레이블 ) 유무 | 있음 (입력 와 정답 쌍을 제공) | 없음 (오직 입력 만 제공) |
| 목표 | 입력에 대한 정답을 예측하는 규칙을 학습 (분류, 회귀) | 데이터 내의 숨겨진 구조나 패턴을 파악하고 그룹화 (군집, 차원 축소) |
| 대표 예시 | 이미지 분류, 가격 예측, 스팸 메일 감지 | 고객 세분화(Clustering), 데이터 시각화 |
7. TextVectorization의 개념과 전처리 (Preprocessing)
- 전처리 (Preprocessing)의 개념
- 개념: 머신러닝 모델이 데이터를 효율적으로 학습하고 높은 성능을 낼 수 있도록, 입력 데이터를 가공하고 정제하는 모든 과정을 통틀어 말합니다.
- 역할: 데이터의 품질을 높이고, 모델이 이해할 수 있는 형식으로 변환하며, 불필요한 노이즈를 제거합니다.
- TextVectorization의 개념
- 개념: 텍스트 데이터를 모델이 처리할 수 있는 숫자(벡터) 형태로 변환하는 전처리 계층입니다.
- 역할: 주어진 텍스트 데이터의 단어(토큰)를 분석하고, 고유한 정수 인덱스로 매핑하여 최종적으로 텐서(Tensor) 형태로 변환합니다.
8. 벡터화(Vectorization)가 필요한 이유
- 컴퓨터는 텍스트를 이해하지 못함: 머신러닝 모델은 본질적으로 수학적 연산을 수행합니다. 따라서 '고양이', '사과'와 같은 자연어 텍스트나 이미지를 그대로 처리할 수 없고, 숫자 형태로 변환해야만 계산이 가능합니다.
- 벡터화의 역할: 텍스트나 이미지를 수치형 벡터 또는 행렬로 변환하여 모델이 학습하고 연산할 수 있도록 만들어주는 필수적인 과정입니다.
9. 패딩(Padding)의 역할
- 배경: 텍스트 데이터는 문장마다 단어의 개수(길이)가 모두 다릅니다. 하지만 딥러닝 모델은 입력 데이터의 길이가 동일해야 효율적으로 처리하고 배치(Batch) 단위로 묶을 수 있습니다.
- 패딩의 역할: 서로 다른 길이를 가진 데이터들을 가장 긴 데이터의 길이에 맞춰 부족한 부분에 특정 값(주로 0)을 채워 넣어 길이를 통일시키는 작업입니다. 이를 통해 데이터를 효율적으로 처리할 수 있는 정형화된 형태로 만듭니다.
10. 또 다른 대표적인 파이썬 라이브러리인 Matplotlib
- 개념: 파이썬에서 가장 널리 사용되는 데이터 시각화 라이브러리입니다.
- 역할: 데이터를 다양한 형식의 2D 그래프나 플롯 (꺾은선 그래프, 막대 그래프, 산점도, 히스토그램 등)으로 표현하여 데이터의 경향, 분포, 관계 등을 쉽게 파악할 수 있도록 돕습니다. 데이터 분석 결과를 보고하거나, 모델의 훈련 과정(손실, 정확도)을 시각적으로 모니터링할 때 필수적으로 사용됩니다.
AI 학습을 마치며: 배우고 느낀 점
이번에 머신러닝의 기본 개념들을 정리하면서 AI 공부의 재미와 어려움을 동시에 느꼈어요. 학생의 입장에서 핵심적인 느낀 점들을 정리해 봅니다.
- 기본 라이브러리의 중요성: '집 짓는 도구'를 익히다
처음엔 Numpy, Pandas, TensorFlow 같은 라이브러리들이 그냥 어려운 이름의 도구로만 느껴졌습니다. 하지만 정리해보니 이들이 곧 AI 모델을 구축하고 데이터를 분석하는 '기초 공사 도구'라는 것을 깨달았습니다.
Numpy로 데이터의 기본 뼈대(다차원 배열)를 세우고,
Pandas로 데이터를 보기 좋게 다듬고(전처리),
TensorFlow로 복잡한 계산을 수행하는 셈입니다.
이 도구들에 익숙해지는 것이 AI 모델을 만드는 첫걸음이라는 것을 확실히 느꼈습니다.
-
Keras: '진입 장벽'을 낮춰준 설계자
TensorFlow가 복잡한 '엔진'이라면, Keras는 이 엔진을 쉽게 다룰 수 있게 해주는 '운전대와 계기판' 같다는 느낌을 받았습니다. 고수준 API 덕분에 신경망을 Sequential 모델로 층층이 쌓아 올리는 과정이 훨씬 직관적이고 빠르게 느껴졌습니다. Keras 덕분에 딥러닝이라는 거대한 분야에 대한 진입 장벽이 크게 낮아졌다고 생각합니다. -
가장 중요했던 개념: '일반화'와 과적합 (Overfitting)
이번 학습에서 가장 깊이 와닿고 중요하다고 느낀 개념은 훈련 데이터(Train)와 테스트 데이터(Test)의 구분, 그리고 이로 인해 발생하는 과적합(Overfitting) 문제였습니다.
모델을 만드는 목적은 훈련 데이터를 '암기'하는 것이 아니라, 새로운 데이터에 대해서도 잘 작동하는 '일반화 능력'을 갖추는 것임을 알게 되었습니다.
과적합은 모델이 훈련 데이터를 너무 잘 따라가서 오히려 독이 되는 현상이라는 것을 명확히 이해했습니다. 이는 단순히 코드를 잘 짜는 것 이상의 데이터 철학이 필요한 부분이라고 느꼈습니다.
-
지도학습과 비지도 학습: AI의 두 가지 시선
지도학습이 '정답(Label)이 있는 문제집'을 푸는 것이라면, 비지도 학습은 '정답 없이 스스로 숨겨진 패턴을 찾는 것'이라는 차이점을 명확히 구분할 수 있게 되었습니다. 문제를 해결하고자 하는 목표에 따라 어떤 학습 방식을 선택해야 할지 기준이 잡혀서 좋았습니다. -
전처리의 중요성: 벡터화와 패딩
TextVectorization, 벡터화, 패딩 같은 전처리 개념을 정리하면서 'Garbage In, Garbage Out'이라는 말이 얼마나 중요한지 깨달았습니다.
벡터화는 컴퓨터가 텍스트를 연산할 수 있게 언어를 숫자 언어로 번역하는 과정이며,
패딩은 모델이 일괄적으로 데이터를 처리할 수 있도록 데이터의 형태를 통일하는 역할입니다.
아무리 좋은 모델을 사용해도, 데이터가 모델이 이해할 수 있는 형태로 잘 다듬어져 있지 않으면 의미가 없다는 사실을 느꼈습니다.
