Pandas
Pandas는 수식으로 계산할 수 있고 시각화도 할 수 있는 데이터 분석 도구이다. Excel로는 힘든 대용량의 데이터 분석이 가능하다.
https://pandas.pydata.org/
https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf
https://10_minutes_to_pandas
1. 필요한 라이브러리 불러오기
import pandas as pd : pandas 불러오기
import numpy as np : 수치계산을 위한 numpy 불러오기
import seaborn as sns : 시각화를 위한 seaborn 불러오기
import matplotlib.pyplot as plt : 데이터 시각화 라이브러리 불러오기
-
한글 폰트를 사용할 때 minus font 가 깨지는 경우를 방지하기 위해
plt.rc('axes', unicode_minus=False)를 사용한다. -
jupyter notebook 구버전에서 그래프가 노트북 안에 보이지 않는 경우에
%matplotlib inline을 사용하면 그래프가 보인다. -
from IPython.dispaly import set_matplotlib_formats set_matplotlib_formats('retina')를 사용하면 폰트를 선명하게 볼 수 있다.
2. 데이터 형태
DataFrame : 2차원 구조를 가졌고, 표형태로 표현된다.
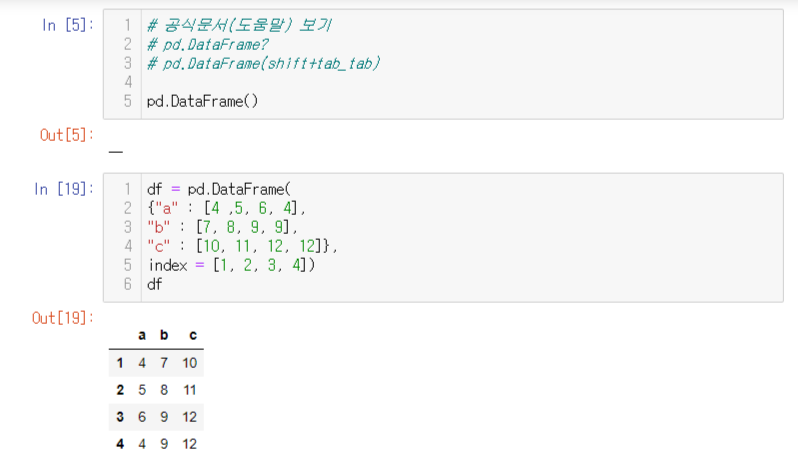
Series : 1차원 구조를 가졌고, series 형태에 [[ ]] 2개를 붙이면 DataFrame 형태로 출력된다.
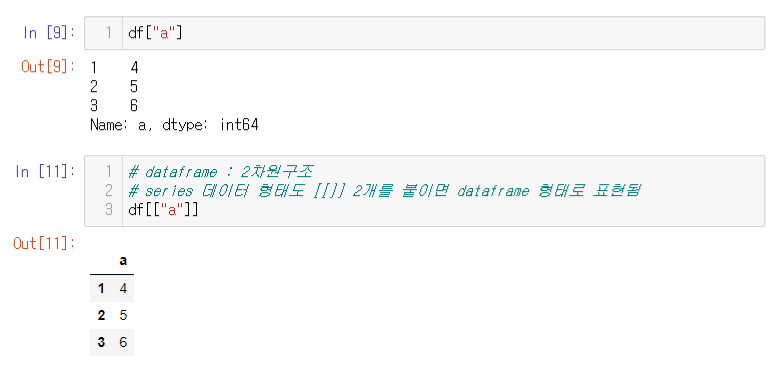
3. Subset(일부 값만 불러오기)
-
두 개 이상의 값을 불러 올때는 DataFrame 형태로 불러와야 한다.
df["a","b"]series 형태로 불러올 경우 키값 오류가 발생
df[["a", "b"]]dataframe 형태로 불러와야 함 -
데이터 미리보기
head()앞에서부터 5개의 데이터 미리보기
tail()뒤에서부터 5개의 데이터 미리보기
sample()랜덤으로 1개의 데이터 미리보기
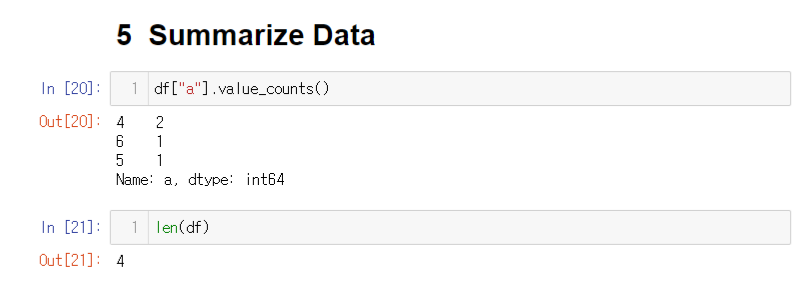
4. Summarize Data
value_counts() 는 카테고리 형태의 빈도수를 구하는 방법이다.
(normalize=True) 옵션을 사용하면 빈도수의 비율을 구할 수 있다.
.info() 데이터의 타입, 컬럼명, 메모리 사용량 등 요약정보 보여준다.
.columns 데이터의 컬럼명만 출력된다.
.types 데이터의 타입만 출력된다.
.describe() 수치형 데이터의 기초 통계값 요약해서 보여준다.
.unique() 중복 제거한 값 보여준다.
.nunique() 중복 제거한 값의 갯수 세어주기.
5. 결측치
df.isnull() 결측치 여부 boolean 타입으로 보여준다.
df.isnull().sum() 결측치 개수 구하기
reset_index() 데이터 프레임으로 만들기
6. Reshaping
drop() : 삭제
sort_values() : 정렬
df["a"].sort_values(): a 컬럼을 기준으로 정렬
df.sort_values("a"): dataframe 전체에서 a 값을 기준으로 정렬
df.sort_values("a", ascending=False): 역순으로 정렬
df.sort_values(by="a", ascending=False): a 값을 기준으로 역순 정렬
7. Group Data, pivot_table
df.groupby(["a"])["b"].mean() : a 컬럼값을 groupby 하여 b의 컬럼값의 평균 구하기
pd.pivot_table(df, index="a") : pivot_table 이용하여 평균값 구하기
8. Plotting(데이터 시각화하기)
df.plot() : 꺾은선 그래프
df.plot.bar() : 막대 그래프
df.plot.density() : 밀도함수 그리기
