Building and Evaluating Advanced RAG - 1
- RAG를 통해 context 정보를 더해줌으로써, LLM의 response 생성에 대해 좀더 좋은 response가 생성이 가능해졌다.
- 하지만 RAG를 한 것이 좋은지 나쁜지 어떻게 평가할 수 있을까?
- 또한 좀더 나은 RAG 방법론에는 어떤 것이 있을까?
- 이에 대한 방법을 TruEra의 TruLens라는 오픈소스 프로젝트에서 제공하고 있다.
- 전체 과정 github 레포지토리
RAG Triad
- RAG에 대한 metric으로 RAG Triad라는 세가지 metric을 제시한다.

Anaswer Relevance
- Output Response가 user query와 얼마나 relevant한지 LLM의 CoT(Chain of Thoughts)로 판단한다.
- User query와 response 사이의 QuestionStatementRelevance를 계산하여 평가
Context Relevance
- Context(retrieved chunks)가 query에 얼마나 relevant한지 LLM의 CoT(Chain of Thoughts)로 판단한다.
- User query와 각각의 context사이의 QuestionStatementRelevance를 계산하여 평균을 계산하여 평가
Groundedness
- Output response가 context(retrieved chunks)에 얼마나 기반하는지에 LLM의 CoT(Chain of Thoughts)로 response와 context의 information overlap에 대하여 평가.
- Retrieval step에서 충분히 많은 관련된 context를 찾지 못한다면 context에 드러난 정보들을 기반으로 답변하는 것이 아닌 pre-trained information을 사용하게 된다. 이는 Groundedness를 떨어뜨린다.
- Groundedness 코드 부분
- 이 3개의 점수가 높을 수록 좋은 RAG 방법으로 생각할 수 있다.
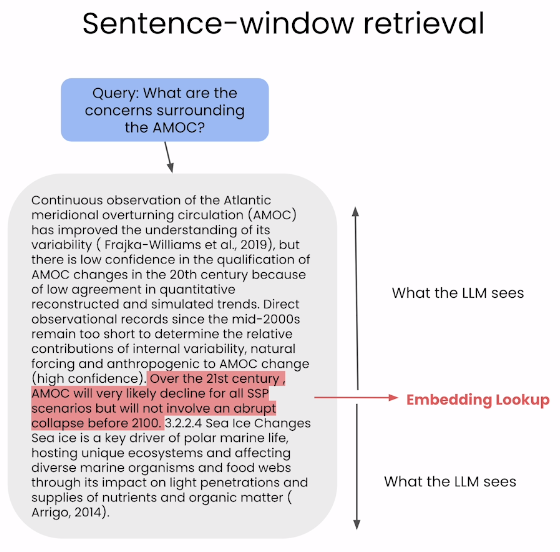
Sentence-window Retrieval
- 더 나은 RAG를 위해 Retrieval pipeline을 발전시킨 두가지 방법이 있다.
- Sentence-window Retrieval과 Auto-merging retrieval이 있는데 이번 게시물에서는 Sentece-window Retrieval에 대해 다뤄보겠다.

- 기존 RAG pipeline은 embedding과 생성에 같은 text chunk를 사용했다.
- Embedding-based retrieval은 작은 text chunk에서 잘 작동한다. 하지만 LLM이 더 좋은 응답을 생성하기 위해서는 더 많은 context와 큰 chunks가 필요하다.
- Sentence-window retrieval에서는 decouple하여 한 단계를 더 거쳐서 사용한다.

- Retrieved chunks에 대해 full-surrounding context로 대체해준다!!

- 이로 인해 LLM에게 더 확장된 context를 제공할 수 있게 된다.
Step by step
1. Sentence-window parsing
from llama_index import SimpleDirectoryReader
from llama_index import Document
from llama_index.node_parser import SentenceWindowNodeParser
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
# 앤드류응 교수님의 책
document = Document(text="\n\n".join([doc.text for doc in documents]))
# create the sentence window node parser w/ default settings
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)text = " How was your day? I was the best. What are you going to do? I will read a book. Im not busy. Take your time, please. I really don’t know what to say. I’m sorry. Did you clean this place? It’s really clean."
nodes = node_parser.get_nodes_from_documents([Document(text=text)])
print([x.text for x in nodes])[' How was your day? ', 'I was the best. ', 'What are you going to do? ', 'I will read a book. ', 'Im not busy. ', 'Take your time, please. ', 'I really don’t know what to say. ', 'I’m sorry. ', 'Did you clean this place? ', 'It’s really clean.']- SentenceWindowNodeParser 는 Document를 모두 문장단위로 쪼갠 후에, 각 문장에 surrounding context로 augment해준다.
print(nodes[0].text)
print(nodes[4].text)How was your day?
Im not busy.- .metadata[’window’]를 확인해보면
print(nodes[0].metadata["window"])
print(nodes[4].metadata["window"])How was your day? I was the best. What are you going to do?
What are you going to do? I will read a book. Im not busy. Take your time, please. I really don’t know what to say. I’m sorry.- 노드의 앞뒤로 3개의 문장을 가져오는 것을 볼 수 있다.
2. Building Index
- 다음 step은 인덱스 생성이다.
from llama_index.llms import OpenAI
from llama_index import ServiceContext
from llama_index import VectorStoreIndex
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
sentence_context = ServiceContext.from_defaults(
llm=llm,
embed_model="local:BAAI/bge-small-en-v1.5",
# embed_model="local:BAAI/bge-large-en-v1.5"
node_parser=node_parser,
)
sentence_index = VectorStoreIndex.from_documents(
[document], service_context=sentence_context
)
# 생성된 Index 저장.
sentence_index.storage_context.persist(persist_dir="./sentence_index")- 저장된 Index가 있을 경우
# This block of code is optional to check
# if an index file exist, then it will load it
# if not, it will rebuild it
import os
from llama_index import VectorStoreIndex, StorageContext, load_index_from_storage
from llama_index import load_index_from_storage
if not os.path.exists("./sentence_index"):
sentence_index = VectorStoreIndex.from_documents(
[document], service_context=sentence_context
)
sentence_index.storage_context.persist(persist_dir="./sentence_index")
else:
sentence_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir="./sentence_index"),
service_context=sentence_context
)3. Building the postprocessor
- retrieval에 쓰인 chunk (위에서는 node)를 window(더 많은 context 포함)로 교체해준다.
from llama_index.indices.postprocessor import MetadataReplacementPostProcessor
from llama_index.schema import NodeWithScore
from copy import deepcopy
postproc = MetadataReplacementPostProcessor(
target_metadata_key="window"
)- postprocessor가 어떻게 작동하는지 보자.
# 위의 sentence-window parsing 진행된 노드들
scored_nodes = [NodeWithScore(node=x, score=1.0) for x in nodes]
nodes_old = [deepcopy(n) for n in nodes]
nodes_old[4].text# 원래 문장
'Im not busy.replaced_nodes = postproc.postprocess_nodes(scored_nodes)
print(replaced_nodes[4].text)I was the best. What are you going to do? I will read a book. Im not busy. Take your time, please. I really don’t know what to say.- window 데이터로 대체되었다.
4. Adding a reranker
- 다음 step은 sentencetransformer reranker를 추가하는 것이다.
- this takes query and retrieve nodes and reorder some nodes and order relevants using a specialized model for the task
- Generally, you will make the initial similarity top-k larger and then reranker will rescore the nodes that return smaller top-n, so filter out smaller set
from llama_index.indices.postprocessor import SentenceTransformerRerank
# BAAI/bge-reranker-base
# link: https://huggingface.co/BAAI/bge-reranker-base
rerank = SentenceTransformerRerank(
top_n=2, model="BAAI/bge-reranker-base"
)- Reranker가 작동하는 예시를 보자.
from llama_index import QueryBundle
from llama_index.schema import TextNode, NodeWithScore
query = QueryBundle("I want a dog.")
# query와 관련된 text의 score를 의도적으로 바꿔놨다.
# 이럴 때(관련된 text의 score가 낮을 때)를 위해 Reranker가 필요
scored_nodes = [
NodeWithScore(node=TextNode(text="This is a cat"), score=0.6),
NodeWithScore(node=TextNode(text="This is a dog"), score=0.4),
]reranked_nodes = rerank.postprocess_nodes(
scored_nodes, query_bundle=query
)
print([(x.text, x.score) for x in reranked_nodes])[('This is a dog', 0.91827345), ('This is a cat', 0.0014040739)]- 앞서 말한것 처럼 reranker의 K , N초깃값을 크게 주는데, 이는 reranker가 fair chance로 적절한 정보를 훑을 수 있게 하기 위함이다.
- top-k=6, top-n=2 → 6개의 relevant chunks를 찾고 최종으로 2개를 찾도록 rerank한다.
sentence_window_engine = sentence_index.as_query_engine(
similarity_top_k=6, node_postprocessors=[postproc, rerank]
)Running the query engine
sentence_window_engine = sentence_index.as_query_engine(
similarity_top_k=6, node_postprocessors=[postproc, rerank]
)
window_response = sentence_window_engine.query(
"What are the keys to building a career in AI?"
)
from llama_index.response.notebook_utils import display_response
display_response(window_response)Final Response: The keys to building a career in AI are learning foundational technical skills, working on projects, and finding a job, all of which is supported by being part of a community.
Putting it all together
- 이 파이프라인들을 모두 합치자.
import os
from llama_index import ServiceContext, VectorStoreIndex, StorageContext
from llama_index.node_parser import SentenceWindowNodeParser
from llama_index.indices.postprocessor import MetadataReplacementPostProcessor
from llama_index.indices.postprocessor import SentenceTransformerRerank
from llama_index import load_index_from_storage
def build_sentence_window_index(
documents,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
sentence_window_size=3,
save_dir="sentence_index",
):
# create the sentence window node parser w/ default settings
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=sentence_window_size,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
sentence_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
node_parser=node_parser,
)
if not os.path.exists(save_dir):
sentence_index = VectorStoreIndex.from_documents(
documents, service_context=sentence_context
)
sentence_index.storage_context.persist(persist_dir=save_dir)
else:
sentence_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir=save_dir),
service_context=sentence_context,
)
return sentence_index
def get_sentence_window_query_engine(
sentence_index, similarity_top_k=6, rerank_top_n=2
):
# define postprocessors
postproc = MetadataReplacementPostProcessor(target_metadata_key="window")
rerank = SentenceTransformerRerank(
top_n=rerank_top_n, model="BAAI/bge-reranker-base"
)
sentence_window_engine = sentence_index.as_query_engine(
similarity_top_k=similarity_top_k, node_postprocessors=[postproc, rerank]
)
return sentence_window_enginefrom llama_index.llms import OpenAI
index = build_sentence_window_index(
[document],
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1),
save_dir="./sentence_index",
)
query_engine = get_sentence_window_query_engine(index, similarity_top_k=6)Evaluation
-
window size를 1부터 3,5 까지 늘리면서 실험
-
각각에 대해 RAG Triad에 대해서 평가
-
Note trade-off between token usage/cost and context relevance
-
Note trade-off between window size and groundedness(context relevance에서도 간접적으로 평가)
-
retrieval step에서 충분히 많은 관련된 context를 모으지 못하면 LLM은 Completion step에서 부족한 점을 메우기 위해 context에 드러난 정보들에 기반하는것이 아닌 pre-train된 정보를 사용하게 되고 이는 groundedness를 작아지게 만든다.
-
Note relationship between context relevance and groundedness
-
위의 이유로 context relevance가 작아지면 groundedness도 작아진다.
-
Context relevance가 증가하면 어느지점까지 같이 증가하지만, context size가 너무 커지면 context relevance점수가 높더라도 groundedness가 감소하게 된다. 이는 LLM이 너무 많은 컨텍스트에 오히려 압도되어서 pre-trained knowledge를 사용하게 되기 때문이다.
Experiments
- Load different questions
- Try different sentence-window size:
- 1, 3, 5
- Check the impact of the different window size on the RAG Triad.
# 사전에 쓰여진 evaluation용 질문들
eval_questions = []
with open('generated_questions.text', 'r') as file:
for line in file:
# Remove newline character and convert to integer
item = line.strip()
eval_questions.append(item)- trulens를 이용한 evaluation
from trulens_eval import Tru
def run_evals(eval_questions, tru_recorder, query_engine):
for question in eval_questions:
with tru_recorder as recording:
response = query_engine.query(question)
from utils import get_prebuilt_trulens_recorder # 강의를 위해 사전에 정의된 helper함수
from trulens_eval import Tru
Tru().reset_database() # 초기화- k=1 인 쿼리 엔진
sentence_index_1 = build_sentence_window_index(
documents,
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1),
embed_model="local:BAAI/bge-small-en-v1.5",
sentence_window_size=1,
save_dir="sentence_index_1",
)
sentence_window_engine_1 = get_sentence_window_query_engine(
sentence_index_1
)
tru_recorder_1 = get_prebuilt_trulens_recorder(
sentence_window_engine_1,
app_id='sentence window engine 1'
)
run_evals(eval_questions, tru_recorder_1, sentence_window_engine_1)- k=3 인 쿼리 엔진
sentence_index_3 = build_sentence_window_index(
documents,
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1),
embed_model="local:BAAI/bge-small-en-v1.5",
sentence_window_size=3,
save_dir="sentence_index_3",
)
sentence_window_engine_3 = get_sentence_window_query_engine(
sentence_index_3
)
tru_recorder_3 = get_prebuilt_trulens_recorder(
sentence_window_engine_3,
app_id='sentence window engine 3'
)
run_evals(eval_questions, tru_recorder_3, sentence_window_engine_3)- k=5 인 쿼리 엔진
sentence_index_5 = build_sentence_window_index(
documents,
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1),
embed_model="local:BAAI/bge-small-en-v1.5",
sentence_window_size=5,
save_dir="sentence_index_5",
)
sentence_window_engine_5 = get_sentence_window_query_engine(
sentence_index_5
)
tru_recorder_5 = get_prebuilt_trulens_recorder(
sentence_window_engine_5,
app_id='sentence window engine 5'
)
run_evals(eval_questions, tru_recorder_5, sentence_window_engine_5)- 위와 같이 window 1,3,5에 대해서 평가 후 대시보드에서 보면,
Tru().run_dashboard()
- 11개 문장으로 평가 했을 때, Context relevance는 window=5 일때 0.77로 가장 높았고, Answer relevance는 5에서 감소했고, Groundedness는 동일했다.
Reference
https://learn.deeplearning.ai/building-evaluating-advanced-rag/lesson/4/sentence-window-retrieval
