Building and Evaluating Advanced RAG - 2(완)
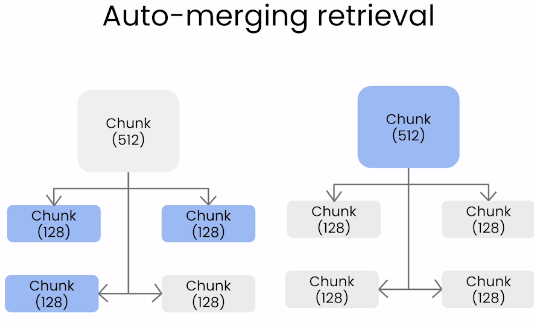
Auto-merging
- 기존 RAG는 Retrieve시 많은 chunks를 살펴보는데, 이때 chunking이 잘 되지 않았다면 살펴보는 횟수도 많아지고, 중복된 맥락을 볼 가능성이 높아진다. 이를 방지하기 위해 hierachical을 사용한다.

- Auto-merging 기법은 HierarchicalNodeParser를 사용하여 문서를 계층화하여 사용한다.
- 계층화된 관계성을 살펴보며 일정Threshold를 넘어서면, 즉 현재 처리하는 노드의 자식노드의 수가 전체 자식 노드수에서 threshold보다 높다면 이를 하나의 맥락으로 판단한다. 따라서 child node를 parent노드와 합치면서 context사이즈를 늘려 보강해준다.
Step by step
Setup
- HierarchicalNodeParser를 이용해 hirechical하게 node를 생성한다.
- chunk size는 설정 가능. 여기서 2048, 512, 128을 사용
from llama_index import SimpleDirectoryReader
from llama_index import Document
from llama_index.node_parser import HierarchicalNodeParser
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
document = Document(text="\n\n".join([doc.text for doc in documents]))
# create the hierarchical node parser w/ default settings
node_parser = HierarchicalNodeParser.from_defaults(
chunk_sizes=[2048, 512, 128]
)
nodes = node_parser.get_nodes_from_documents([document])- get_leaf_nodes 함수를 사용하여 leaf node를 탐색할 수 있다.
from llama_index.node_parser import get_leaf_nodes
leaf_nodes = get_leaf_nodes(nodes)
print(leaf_nodes[30].text)But this became less important as numerical linear algebra libraries matured.
Deep learning is still an emerging technology, so when you train a neural network and the
optimization algorithm struggles to converge, understanding the math behind gradient
descent, momentum, and the Adam optimization algorithm will help you make better decisions.
Similarly, if your neural network does something funny — say, it makes bad predictions on
images of a certain resolution, but not others — understanding the math behind neural network
architectures puts you in a better position to figure out what to do.
Of course, I also encourage learning driven by curiosity.- 다음과 같은 방법으로 leaf node와 parent node의 관계를 볼 수 있다.
nodes_by_id = {node.node_id: node for node in nodes}
parent_node = nodes_by_id[leaf_nodes[30].parent_node.node_id]
print(parent_node.text)PAGE 12Should You
Learn Math to
Get a Job in AI? CHAPTER 3
LEARNING
PAGE 13Should you Learn Math to Get a Job in AI? CHAPTER 3
Is math a foundational skill for AI? It’s always nice to know more math! But there’s so much to
learn that, realistically, it’s necessary to prioritize. Here’s how you might go about strengthening
your math background.
To figure out what’s important to know, I find it useful to ask what you need to know to make
the decisions required for the work you want to do. At DeepLearning.AI, we frequently ask,
“What does someone need to know to accomplish their goals?” The goal might be building a
machine learning model, architecting a system, or passing a job interview.
Understanding the math behind algorithms you use is often helpful, since it enables you to
debug them. But the depth of knowledge that’s useful changes over time. As machine learning
techniques mature and become more reliable and turnkey, they require less debugging, and a
shallower understanding of the math involved may be sufficient to make them work.
For instance, in an earlier era of machine learning, linear algebra libraries for solving linear
systems of equations (for linear regression) were immature. I had to understand how these
libraries worked so I could choose among different libraries and avoid numerical roundoff
pitfalls. But this became less important as numerical linear algebra libraries matured.
Deep learning is still an emerging technology, so when you train a neural network and the
optimization algorithm struggles to converge, understanding the math behind gradient
descent, momentum, and the Adam optimization algorithm will help you make better decisions.
Similarly, if your neural network does something funny — say, it makes bad predictions on
images of a certain resolution, but not others — understanding the math behind neural network
architectures puts you in a better position to figure out what to do.
Of course, I also encourage learning driven by curiosity. If something interests you, go ahead
and learn it regardless of how useful it might turn out to be! Maybe this will lead to a creative
spark or technical breakthrough.How much math do you need to know to be a machine learning engineer?- 128 chunks로 나누었기 때문에 4개의 leaf node로 이루어져 있는 것을 볼 수 있다.
Building the index
from llama_index.llms import OpenAI
from llama_index import ServiceContext
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
auto_merging_context = ServiceContext.from_defaults(
llm=llm,
embed_model="local:BAAI/bge-small-en-v1.5",
node_parser=node_parser,
)from llama_index import VectorStoreIndex, StorageContext
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
automerging_index = VectorStoreIndex(
leaf_nodes, storage_context=storage_context, service_context=auto_merging_context
)
automerging_index.storage_context.persist(persist_dir="./merging_index")- 위와 같은 식으로 leaf node로 이루어진 Index를 선언해준다.
# This block of code is optional to check
# if an index file exist, then it will load it
# if not, it will rebuild it
import os
from llama_index import VectorStoreIndex, StorageContext, load_index_from_storage
from llama_index import load_index_from_storage
if not os.path.exists("./merging_index"):
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
automerging_index = VectorStoreIndex(
leaf_nodes,
storage_context=storage_context,
service_context=auto_merging_context
)
automerging_index.storage_context.persist(persist_dir="./merging_index")
else:
automerging_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir="./merging_index"),
service_context=auto_merging_context
)- 처음에는 index를 생성하고 index가 존재한다면 저장된 index를 불러오도록 설정해준다.
Retriever & Query engine
- 마지막으로 retriever를 설정해주고 query engine을 만들어준다.
- 만약 다수의 children node가 주어진 parent node에 대하여 retrieved되었으면, parent node로 대체된다.
- merging이 잘 일어나도록 leaf node에 대하여 top-k를 크게 설정해준다.
- leaf node가 128의 작은 크기를 가지므로, token 사용을 줄이기 위해 merge 후에 reranker를 붙여준다.
- 예를 들어 top 12를 찾고 merge가 일어나 10개로 줄었다면, top 6만 찾도록 reranker의 n을 설정해준다.
- rerank에 설정한 n이 많아 보일 수 있지만 base chunk size가 128로 작고 parent가 512인 것을 감안하여 크게 잡아도 괜찮다고 한다.
from llama_index.indices.postprocessor import SentenceTransformerRerank
from llama_index.retrievers import AutoMergingRetriever
from llama_index.query_engine import RetrieverQueryEngine
automerging_retriever = automerging_index.as_retriever(
similarity_top_k=12
)
retriever = AutoMergingRetriever(
automerging_retriever,
automerging_index.storage_context,
verbose=True
)
rerank = SentenceTransformerRerank(top_n=6, model="BAAI/bge-reranker-base")
auto_merging_engine = RetrieverQueryEngine.from_args(
automerging_retriever, node_postprocessors=[rerank]
)from llama_index.response.notebook_utils import display_response
auto_merging_response = auto_merging_engine.query(
"What is the importance of networking in AI?"
)
display_response(auto_merging_response)Final Response: Networking is important in AI because it allows individuals to build a strong professional network and community.
This network can provide valuable information, help with career advancement, and offer support and advice when needed.
By connecting with others in the AI community, individuals can also increase their visibility and recognition for their expertise.
Additionally, networking can lead to referrals for potential job opportunities.
Building a community and networking within it can help individuals stay connected, learn from others, and foster collaboration and innovation in the field of AI.Putting it all together
import os
from llama_index import (
ServiceContext,
StorageContext,
VectorStoreIndex,
load_index_from_storage,
)
from llama_index.node_parser import HierarchicalNodeParser
from llama_index.node_parser import get_leaf_nodes
from llama_index import StorageContext, load_index_from_storage
from llama_index.retrievers import AutoMergingRetriever
from llama_index.indices.postprocessor import SentenceTransformerRerank
from llama_index.query_engine import RetrieverQueryEngine
def build_automerging_index(
documents,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="merging_index",
chunk_sizes=None,
):
chunk_sizes = chunk_sizes or [2048, 512, 128]
node_parser = HierarchicalNodeParser.from_defaults(chunk_sizes=chunk_sizes)
nodes = node_parser.get_nodes_from_documents(documents)
leaf_nodes = get_leaf_nodes(nodes)
merging_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
)
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
if not os.path.exists(save_dir):
automerging_index = VectorStoreIndex(
leaf_nodes, storage_context=storage_context, service_context=merging_context
)
automerging_index.storage_context.persist(persist_dir=save_dir)
else:
automerging_index = load_index_from_storage(
StorageContext.from_defaults(persist_dir=save_dir),
service_context=merging_context,
)
return automerging_index
def get_automerging_query_engine(
automerging_index,
similarity_top_k=12,
rerank_top_n=6,
):
base_retriever = automerging_index.as_retriever(similarity_top_k=similarity_top_k)
retriever = AutoMergingRetriever(
base_retriever, automerging_index.storage_context, verbose=True
)
rerank = SentenceTransformerRerank(
top_n=rerank_top_n, model="BAAI/bge-reranker-base"
)
auto_merging_engine = RetrieverQueryEngine.from_args(
retriever, node_postprocessors=[rerank]
)
return auto_merging_enginefrom llama_index.llms import OpenAI
index = build_automerging_index(
[document],
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.1),
save_dir="./merging_index",
)query_engine = get_automerging_query_engine(index, similarity_top_k=6)Evaluation
- 실험 결과 - app0: level2, app1: level3로 설정한 쿼리엔진
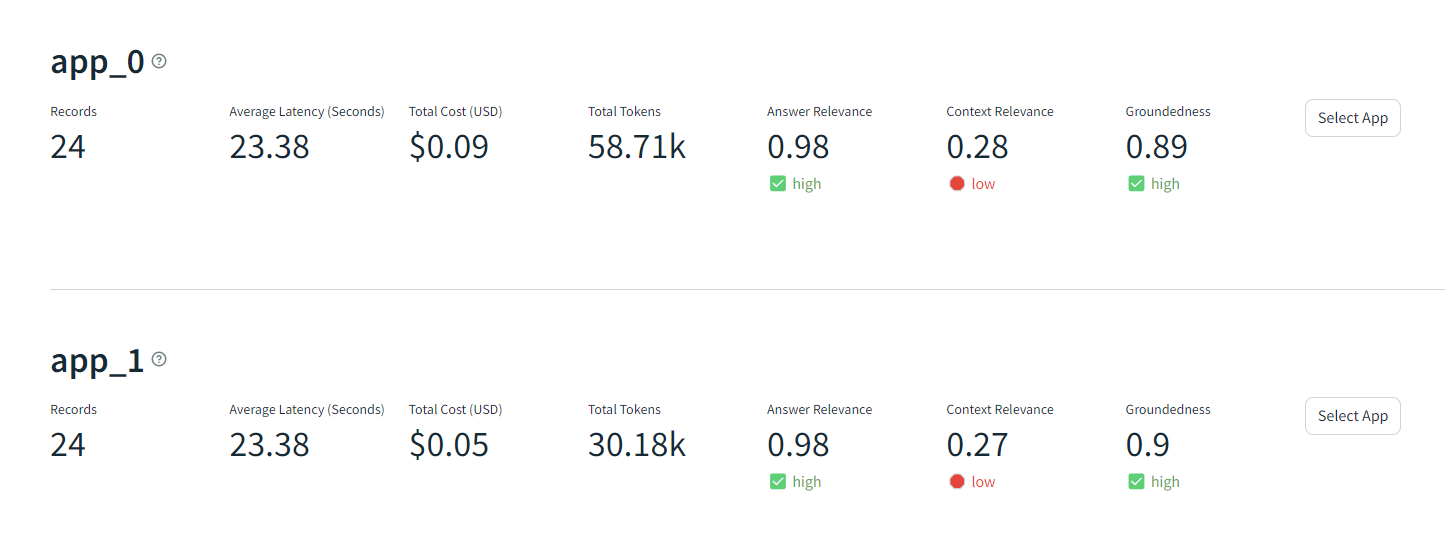
- 3 layer로 했을 때 2 layer 보다 context relevance는 조금 줄어들었지만 groundedness는 증가, 토큰사용은 반으로 줄었다.
- Sentence window 기법과 비교했을 때 Groundedness는 조금 높지만 Context Relevance측면에서 성능이 현저하게 떨어졌다.
Evaluate and Iterate
- Hierarchical structure(ex. level 또는 children 개수 등)와 chunk size를 다르게 하면서 실험해봐야 한다.
- 문서의 형태(ex. 계약서, 송장 등)를 고려하여 어떤 형태의 RAG가 최적인지 고려해봐야한다.
- 앞서 살펴봤던 Sentece window 기법과 비교해볼 필요가 있다.
Reference

라이브데이터 Developer