Vector DB란?
- AI가 발달하면서 닿지 않는 분야가 없다. 그러면서 새로운 challenge들도 생기고 있는데, 특히 LLM, generative AI, semantic search를 쓰는 어플리케이션에서 특히 효율적인 데이터처리가 중요해졌다.
- 이러한 어플리케이션들은 vector embeddings에 의존하는데, vector embeddings란 복잡한 태스크를 수행할 때 long-term메모리를 유지하고 이해하기위해 AI에 중요한 semantic한 정보를 포함하고 있는 데이터의 표현이다.
- Embeddings는 LLM같은 AI모델에서 만들어지고 많은 attributes 또는 features를 포함하는데, 이 때문에 representation을 다루기 힘들다. AI와 머신러닝의 관점에서 이러한 features는 패턴, 관계, 내포하는 구조를 이해하는 데 중요한 데이터의 다른 차원들을 나타낸다.
- 그러므로 이러한 데이터 타입을 구체적으로 다루는데 특화된 데이터베이스가 필요하다. Pinecone 같은 Vector DB들은 이러한 임베딩을 위한 쿼링능력을 갖춘 임베딩에 최적화된 저장공간이라는 요구사항을 만족시킨다. Vector DB들은 standalone vector index(기존에 사용하던 방법론인듯)에는 없는 데이터베이스의 기능과 기존의 scalar-based DB에는 없는 vector embedding을 다루는데 특화된 기능을 가졌다.
- 기존 scalar-based DB는 이러한 복잡성과 스케일에 따라가지 못해 벡터 임베딩을 다루는데 문제가 있었고, 이는 실시간 분석을 수행하고 인사이트를 내기에는 어렵게 했다. 이를 다루기 위해 나온것이 vector DB이고, 이러한 데이터들을 처리하고 최대한 활용하는 데 필요한 성능, scalability, flexibility를 제공하도록 설계되었다.
- Vector DB를 가지고 우리의 AI에 semantic information이라던가, long-term memory라던가 같은 advanced feature를 추가할 수 있다.
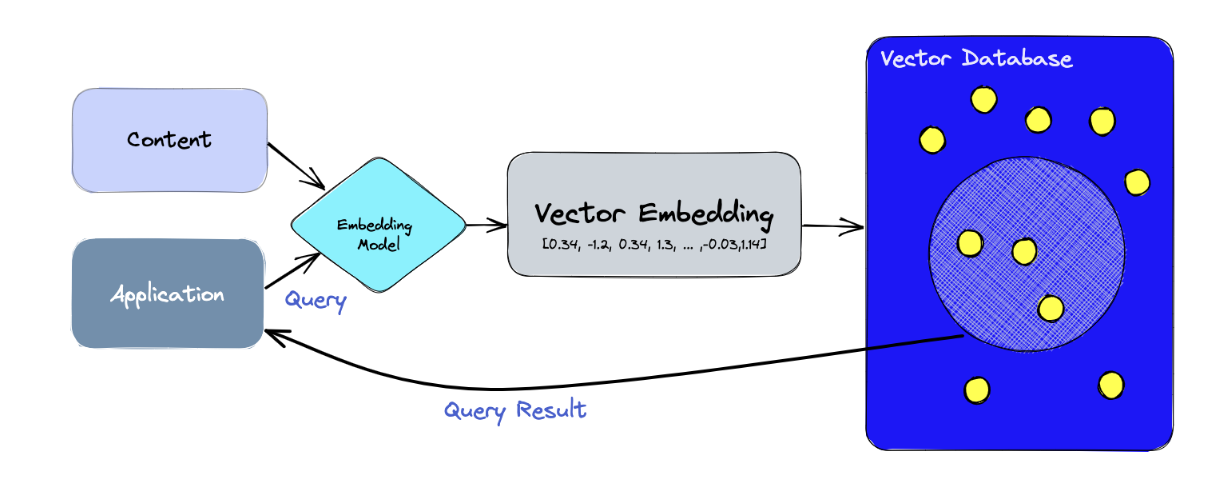
- 단계별로 알아보면:
- 먼저, 임베딩 모델을 사용하여 인덱싱할 콘텐츠에 대한 벡터 임베딩을 생성한다.
- 벡터 임베딩은 임베딩이 생성된 원래 내용을 일부 참조하여 DB에 삽입된다.
- 어플리케이션이 쿼리를 날리 때, 임베딩에 대한 쿼리문을 생성하는 데 동일한 임베딩 모델을 사용하고, 생성된 임베딩(쿼리문)을 DB에서 유사한 벡터임베딩(임베딩된 찾고자 하는 콘텐츠)를 쿼리하는데 사용한다. 그러면 원본 콘텐츠와 관련된 임베딩이 나오게 된다
Vector index와 Vector DB의 차이점
- FAISS(Facebook AI Similarity Search)같은 standalone vector indices는 vector embeddings에 대한 search, retrieval을 확연하게 개선시킬 수 있지만, 데이터베이스적 기능이 없다. 그와 반면 Vector DB에는 이러한 단점을 보완하기 위한 목적으로 만들어짐:
- Data management: 원래 DB 기능인 Insert, Delete, Update기능 제공함. FAISS같은 standalone vector index에는 없음
- Metadata storage and filtering: 각 vector entry에 연관되어 있는 메타데이터 저장 가능. 유저는 더 정제된 결과를 위해 이를 활용 가능하다.
- Scalability: 서비스 분산 확장 용이
- Real-time updates: 리얼타임 업뎃 지원
- Backups and collections
- Ecosystem integration
- Data security and access control
- 요약해서, Vector DB를 사용하시라
Vector DB 작동 방식
- 기존의 DB에는 string, number 등등 scalar data들을 행과 열에 저장했다. 반면 vector DB는 vector 기반으로 작동하기 때문에 optimize 되는 방식과 queried 되는 방식이 스칼라 기반과는 많이 다르다.
- Vector DB에는 similarity metric을 도입하여 우리의 쿼리와 가장 유사한 벡터를 찾는다.
- Vector DB는 ANN(Approximate Nearest Neighbor) search와 다양한 알고리즘들과 함께 조합되어 사용된다. 이런 알고리즘들은 hashing, quantization, graph-based search를 통해 검색을 최적화한다.
- 이러한 알고리즘들은 queried vector의 이웃들의 빠르고 정확한 retrieval을 제공하는 파이프라인에 들어간다. Vector DB 자체가 approximate한 결과를 제공하기 때문에 정확도와 스피드는 우리가 고려해야 할 trade-off 관계에 있다(쿼링이 느릴수록 결과가 더 정확할것). 하지만 좋은 DB는 둘다 빠르겠죠?
- Vector DB의 common pipeline:

- Indexing: Vector DB는 PQ, LSH, HNSW 같은 알고리즘들을 사용하여 벡터들을 인덱싱한다(밑에서 알아볼거임). 이 단계에서 벡터들을 더 빠른 탐색을 가능하게 하는 자료구조로 매핑한다.
- Querying: Vector DB에서는 인덱싱된 쿼리 벡터를 데이터셋의 인덱싱된 벡터와 비교하여 가장 가까운 이웃을 찾는다(이 인덱스에 사용된 similarity metric을 활용해서)
- Post Processing: 경우에 따라, Vector DB는 데이터셋에서 가장 가까운 이웃을 찾은후에 후처리를 한다. 이 단계를 거치면 다른 similarity measure를 사용하여 re-ranking을 할 수 있게 된다.
→ 각각의 알고리즘을 좀더 자세히 알아보자
Algorithms
- Vector Index를 만드는 데는 여러 알고리즘들이 기능할 수 있다. 그것들의 공통의 목표는 빨리 왔다갔다 할 수 있는 자료구조를 만듦으로써 빠른 Querying을 가능하게 하는 것이다. 이들은 Query process를 최적화하기 위해 공통적으로 원본 벡터의 표현을 압축된 형태로 바꿀 것이다.
- 그러나 Pinecone에서는 이런 복잡한 것들과 알고리즘의 선택에 대해 알아서 신경 안쓰고 너가 AI에 하고싶은거 다하게 해준다. 그래서 써라라고 하네여
- 다음으로는 다양한 vector embedding을 다루는 유니크한 방법론들에 대해 다뤄보자. 이를 통해 정보에 입각한 결정을 내릴 수 있으며, 파인콘에서 어떻게 매끄러운 서비스를 제공하려고 노력하는지 알 수 있ㄷ다.
Random Projection
- Random projection의 기본 아이디어는 고차원의 벡터를 Random Projection Matrix를 이용해 저차원 공간으로 투영하는 것이다
- 랜덤한 숫자로된 matrix를 만든 후에 내적, target dimension으로 낮춰줌. 즉 생성한 매트릭스와 내적하여 생긴 projected matrix는 원본 벡터보다 차원은 작지만 유사성은 유지하고 있다.
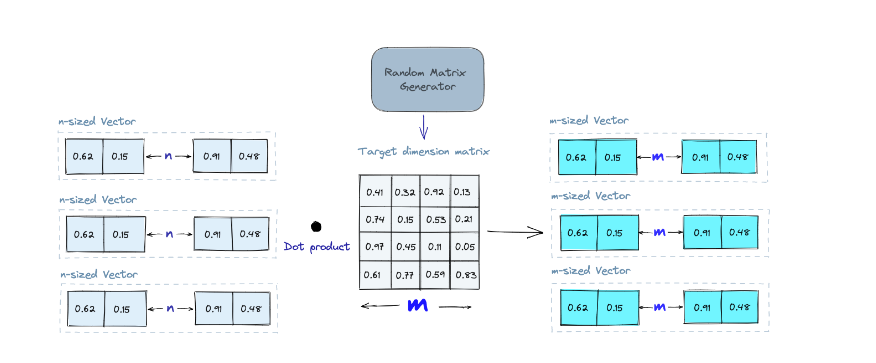
- Query작업을 할 때도 같은 projection matrix를 사용하여 query를 저차원 공간으로 투영시켜준다. 그후에 투영된 쿼리 벡터와 투영된 벡터들을 비교하여 DB내의 가장 가까운 데이터를 찾는다. 저차원으로 매핑된 데이터라 고차원의 전체 데이터보다 당연히 탐색 속도 빠름
- 하지만 random projection은 가장 단순하게 생각할 수 있는 방법인 만큼 approximate한 방법이란걸 명심해야 하고, projected vector의 퀄리티는 projection matrix의 성질에 의존할 수 밖에 없다. 일반적으로 projection matrix가 더욱 랜덤할 수록 projection의 퀄리티는 높아지지만, 특히 큰 데이터셋에 대한 완전히 랜덤한 행렬을 만드는 것은 비용이 많이 든다.
- 더 알아보기
Product Quantization
- 또다른 방법인 Product Qunatization(PQ)는 고차원 벡터(임베딩된 벡터같은)에 저적용하는 매우 lossy한 압축 기법이다.
- 원본 벡터를 chunk 들로 자른 뒤, 각각의 chunk에 대한 representative code를 만들어 각 chunk에 대한 representation을 간단하게 한다. 그리고 나서 모든 chunks를 합친다 - similarity operation에 중요한 정보를 잃지 않고.
- 이는 splitting, training, encoding, querying으로 나눌 수 있다.
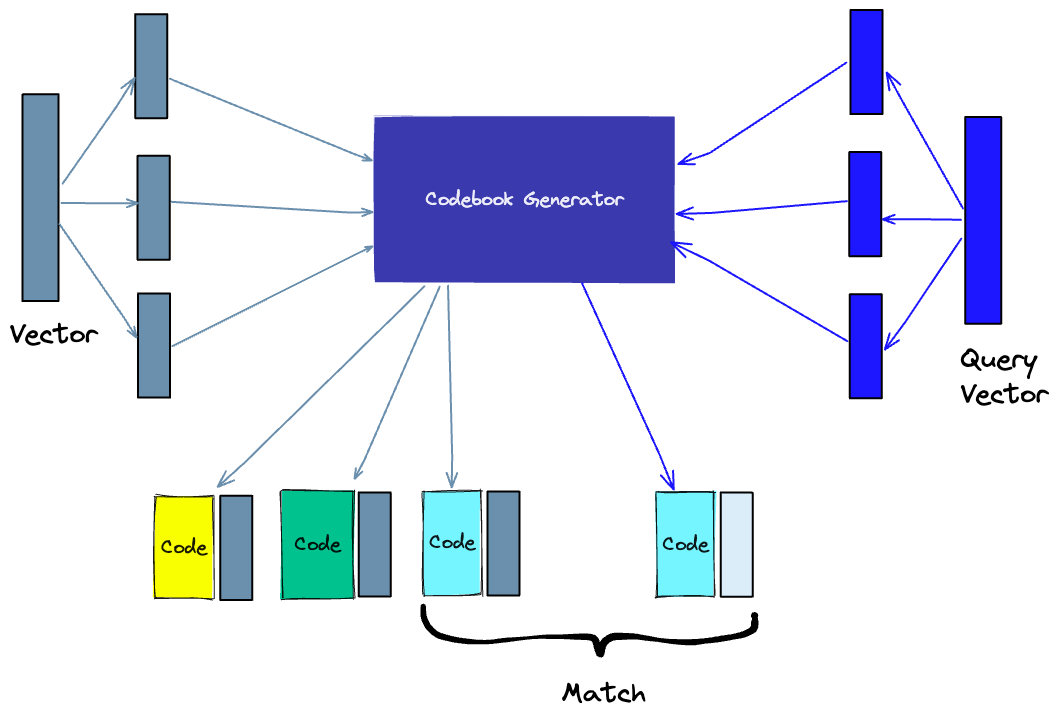
- Splitting - 벡터를 segments(chunks)로 나눔
- Training - 각 segment에 대한 “codebook”을 만든다. 쉽게 말해 하나의 벡터로 할당될 수 있는 잠재적인 “code”들의 pool을 만드는 알고리즘이라고 생각하면 된다. 예를들면, k-means로 벡터의 segments에 대한 군집화를 수행해서 나온 분류를 가지고 codebook을 만든다. K-means에 사용한 값 만큼의 개수의 segment codebook을 얻게 되는 것이다.
- Encoding - 특정 code를 각 segment로 할당한다. 예를들면, Training단계를 거친 후에는 codebook에서 각 vector segment에 가장 가까운 값을 찾는다. 찾은 이 PQ code는 codebook에 있는 값에 상응하는 identifier가 된다. PQ code는 사용하고 싶은 만큼 사용할 수 있다. 즉, 각 segment를 나타내기 위해 codebook에서 여러개의 값을 선택할 수 있다.
- Querying - Query를 할때, 똑같이 Query vector를 sub-vectors로 나누고 같은 codebook을 이용해 quatize한다. 그리고나서, 인덱싱된 코드를 가지고 query vector에 가장 가까운 vector를 찾는다.
- Codebook의 representative vector의 개수는 representation의 정확도와 계산 비용의 trade-off이다.
- 더 알아보기
Locality-sensitive hashing
- 줄여서 LSH는 approximate NN search의 맥락에서 인덱싱하는 기술이다. 속도에 최적화되있으면서 동시에 approximate하고 non-exhaustive한 결과를 제공한다.
- LSH는 다음과 같이 유사한 벡터를 hashing함수집합을 사용하여 buckets에 매핑한다.
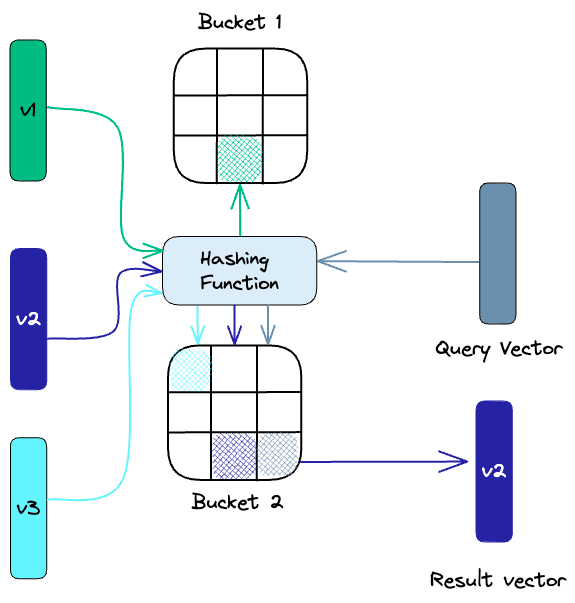
- 주어진 query vector에 대한 nn을 찾기위해 유사 벡터를 해시 테이블로 만드는데 사용한것과 같은 해싱 함수를 사용한다. 마찬가지로 특정 해시 테이블로 해싱된 쿼리벡터와 같은 해시테이블의다른 벡터들을 비교해서 가장 가까운 match를 찾는다. 이 방법도 고차원 공간에서의 전체데이터보다 해시테이블에서 찾으니까 훨씬 빠르다.
- 더 알아보기
Hierarchical Navigable Small World
- HNSW는 hierachical하고, 트리한 구조를 만드는데 이 구조에서 트리의 각 노드는 벡터의 세트를 나타낸다. 에지는 벡터들 간의 similarity를 나타낸다.
- 각각 작은 숫자의 벡터를 가진 노드셋을 만드는 것으로 시작하는데 이는 랜덤으로 하거나 k-means를 써서 수행하는데, 이때는 각 클러스터가 노드가 된다.
- 그리고 나서 각 노드의 벡터들을 보고 유사도가 높은 쪽으로 edge를 그린다.
- 이 그래프를 사용해서 쿼리벡터와 가장 가까운 벡터를 가진 노드를 방문하는 것으로 HNSW 인덱스를 사용해 querying할 수 있다.
Similarity Measures
- 앞서 논의한 알고리즘을 바탕으로, Vector DB에서 Similarity Measures의 역할에 대해 이해할 필요가 있다. 이 measure들은 VDB가 주어진 쿼리에 가장 관련있는 결과를 어떻게 비교하고 찾는지에 대한 기초가 된다.
- Similarity measures는 벡터 공간에서 두 벡터가 얼마나 유사한지 판단하는 수학적 방법이다. Similarity measures는 VDB에서 저장된 벡터들을 비교하고 주어진 쿼리벡터와 가장 유사한 벡터를 찾는데 사용된다.
- 여러가지 measure가 사용될 수 있는데:
- Cosine Similarity: 두벡터간의 각도를 측정. -1부터 1, 1은 동일한 벡터, 0은 othogonal, -1은 diametrically opposed.
- Euclidean distance: 벡터공간에서 두 벡터 사이의 직선거리. 0부터 무한대의 범위이고, 0은 동일한벡터, 값이 커질수록 덜 유사한 벡터
- Dot product: 두 벡터의 magnitude와 두 벡터 사이각의 코사인의 곱을 측정함. 마이너스 무한대부터 무한대의 범위이고 양수이면 같은방향, 0이면 직교, 마이너스면 반대방향을 나타냄
- Similarity measure의 선택에 따라 VDB에서 얻는 결과가 달라질 것이다. 그리고 각 measure마다 장단점이 있음에 유의해야하고, 상황과 요구사항에 따라 적절하게 사용하는것이 중요하다.
- 더 알아보기
Filtering
-
DB에 저장된 모든 벡터도 메타데이터를 포함하고 있다. 유사 벡터를 쿼리하는 능력 뿐만아니라, VDB에서는 메타데이터 쿼리에 기반해서 결과를 필터링 할 수 있다. 이를 위해서 VDB에서는 vector index, metadata index 두가지를 유지한다. 그런다음 벡터 탐색 자체의 전후에 메타데이터 필터링이 가능하지만, 두경우 모두 각각의 이유로 query process의 느려짐을 초래한다는 단점이 있다.
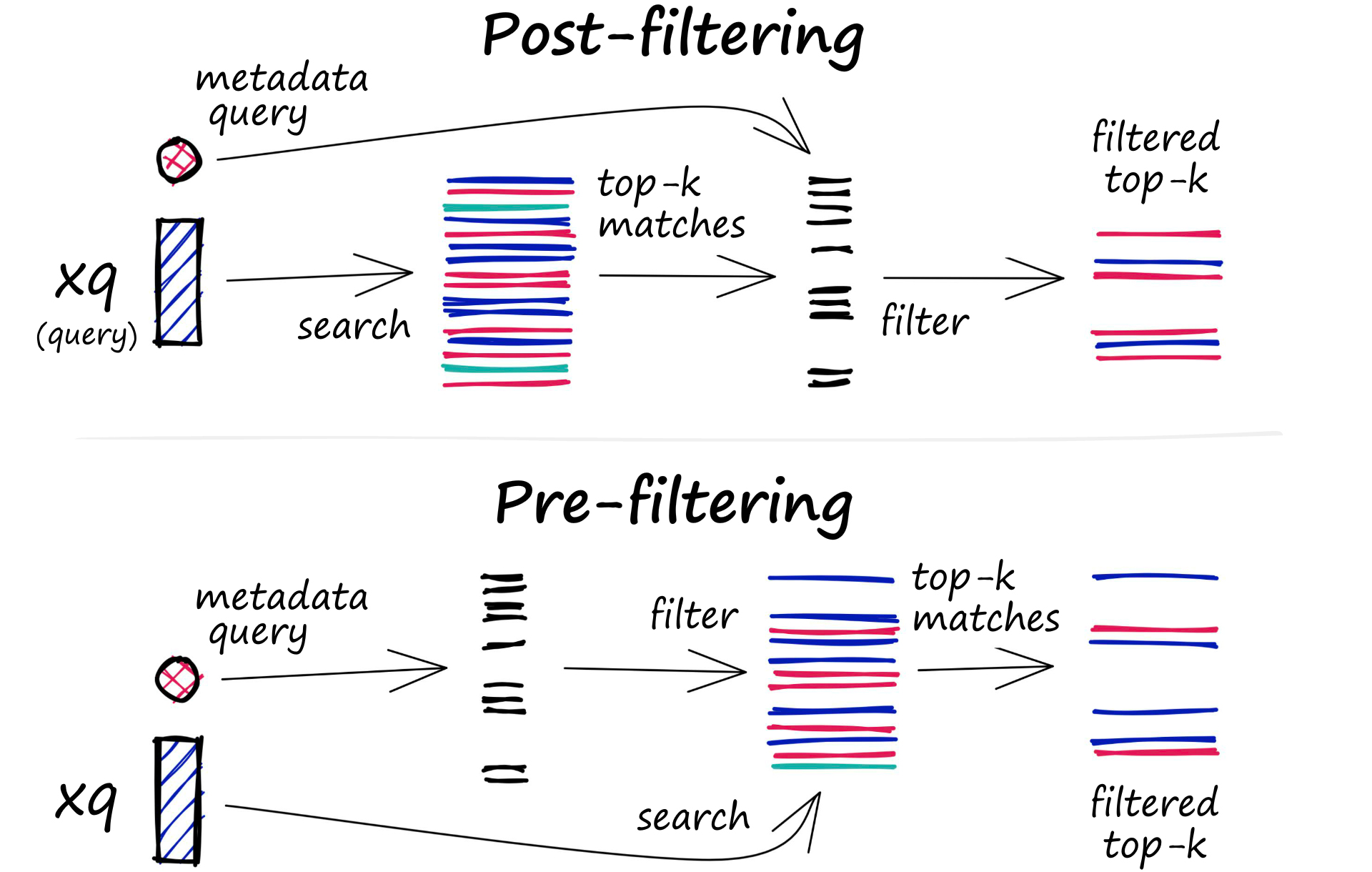
- Pre-filtering: Vector search 이전에 필터링 수행. 탐색할 공간을 줄이는 장점이 있지만, 시스템으로 하여금 관련 결과지만 metadata filter criteria에 맞지않는 결과를 무시할 수 있다. 그리고 extensive한 메타데이터 필터링은 computational overhead로 쿼리프로세스의 느려짐을 초래할 수 있다.
- Post-filtering: Vector search 이후에 필터링 수행. 모든 관련 결과를 고려할 수 있지만, 관련 없는 결과를 필터링해줘야하는 오버헤드로 쿼리프로세스가 느려질 수 있다.
-
필터링 프로세스를 최적화하기 위해서, VDB는 다양한 테크닉을 사용하는데, 메타데이터에 대한 advanced indexing 기법을 활용하거나 병렬 처리로 필터링 태스크를 빠르게하는 방법을 사용한다. VDB에서 효율적이고 적절한 쿼리 결과를 제공하기 위해서 Search 성능과 Filtering 정확도 간 trade-off를 균형잡는것이 중요하다.
Database Operations
- vector indexes와 다르게, VDB는 high scale production setting에서도 사용하기에 적합한 기능 집합을 가지고 있다.
- VDB operations components overview:
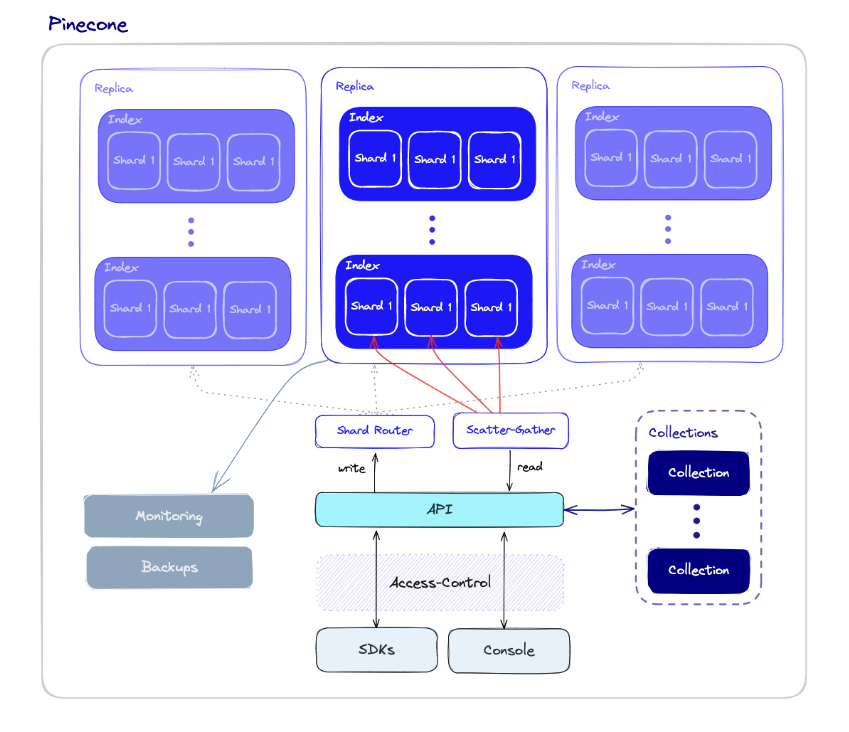
Performance and Fault tolerance
- 퍼포먼스와 Fault tolerance는 깊이 연관되어 있다. 많은 데이터를 가질 수록, 더 많은 노드가 필요하다 - 필연적으로 에러나 failure의 확률이 올라간다.
- 여느 DB와 마찬가지로 쿼리가 가능한 빨리 실행되고 몇 노드가 failure나도 정상적으로 작동하길 바란다.
- 따라서 샤딩, Replication 지원
Monitoring
- 효과적인 관리를 위해 DB 모니터링은 필수
- 자원 사용, 쿼리성능, system health 모니터링 가능
Access-control
- 데이터 보호, 법규준수, 책임및 감사, Scalability&Flexibility 측면에서 접근 통제 중요
Backups and collections
- Pincone에서는 유저가 백업하고 싶은 특정 인덱스들을 “collections”로서 저장할 수 있고, 이는 새로운 인덱스를 채우는데 사용될 수 있다.
API and SDKs
- VDB가 진가를 발휘하는 순간: 고성능의 vector search application개발을 VDB API단에서 간단하게 해준다
- API 뿐만 아니라 언어 특화된 SDK가 제공되기 때문에 인프라적 복잡성 상관없이? 유즈케이스에 더 specific한 사용이 가능하다.
Summary
- AI 필드에서 vector embedding의 폭발적인 성장은 우리의 application에서 vector embeddings와 효과적으로 상호작용하게하는 computation engine으로써 VDB를 출현시켰다.
- VDB는 목적기반으로 설계되었는데 Production 시나리오들에 따른 벡터 임베딩을 관리할 때 발생하는 문제들을 처리하는데 특화되었다. 따라서, 기존의 스칼라기반 DB와 standalone vector indexes의 장점을 아우른다.
Reference

라이브데이터 Developer