
Feature Reduction
- 데이터의 차원(Feature)를 줄이는 과정을 의미
- 데이터셋에는 여러개의 특성이 포함될 수 있는데,
모든 특성이 유용하거나 필요하지는 않다. - 따라서, 불필요한 특성을 제거하거나, 여러 특성을 결합하여 새로운 특성을 생성하는 식으로 수행한다.
Feature Selection VS Feature Reduction
| Feature Selection | 비교 사항 | Feature Reduction |
|---|---|---|
|
특성 중에서 가장 중요한 것만 선택하는 과정. 선택되지 않은 특성들은 완전히 제거 |
정의 |
특성 일부를 제거하거나, 여러 특성을 결합하여 새로운 특성을 생성하는 과정 |
|
1) 원본 데이터 특성 유지 2) 해석이 쉬워질 수 있음 |
특징 |
1) 원본 데이터 특성이 직접적으로 쓰이지 않음 2) 해석이 어려울 수 있음 |
Feature Reduction의 방법들
- PCA
- LDA
- T-SNE
- AutoEncoder etc..
Python Library
from sklearn.decomposition import PCA # PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA # LDA
from sklearn.manifold import TSNE # T-SNE1. Principal Component Analysis - PCA
선형 차원 축소 기법- 데이터의 분산이 최대가 되는 방향으로 데이터를 투영하여, 데이터의 차원을 축소하는 기법
- 원본 데이터의 정보 손실을 최소화하면서 차원을 축소
2. Linear Discriminant Analysis - LDA
분류 문제에 적합- 클래스 간 분산은 최대, 클래스 내 분산은 최소로 만드는 방향으로 데이터를 투영
- 각 클래스를 잘 구분할 수 있는 특성을 생성하는 것이 목표
- 방식
- 클래스 내 분산 행렬과 클래스간 분산 행렬을 계산
- 두 행렬의 고유값과 고유 벡터를 계산
- 고유값이 큰 순서로 K개의 고유벡터를 선택
- 선택된 고유벡터로 데이터를 투영하여 차원을 축소
3. t-Distributed Stochastic Neighbor Embedding (t-SNE)
- 고차원 데이터 구조를 저차원에서 유지하려는
비선형 차원 축소 기법- 원본 고차원 공간에서의 데이터 포인트 간의 유사도와 저차원 공간에서의 데이터 포인트 간의 유사도를 비슷하게 만들려고 함
- 방식
1) 고차원에서 두 데이터 포인트와 유사도를 가우스 분포를 이용해 계산
2) 저차원에서 두 데이터 포인트간의 유사도를 t-분포를 이용해 계산
3) 1)과 2)에서 구한 계산식의 차이가 최소가 되도록 데이터 포인트를 조정
4. AutoEncoder - 얘는 딥러닝
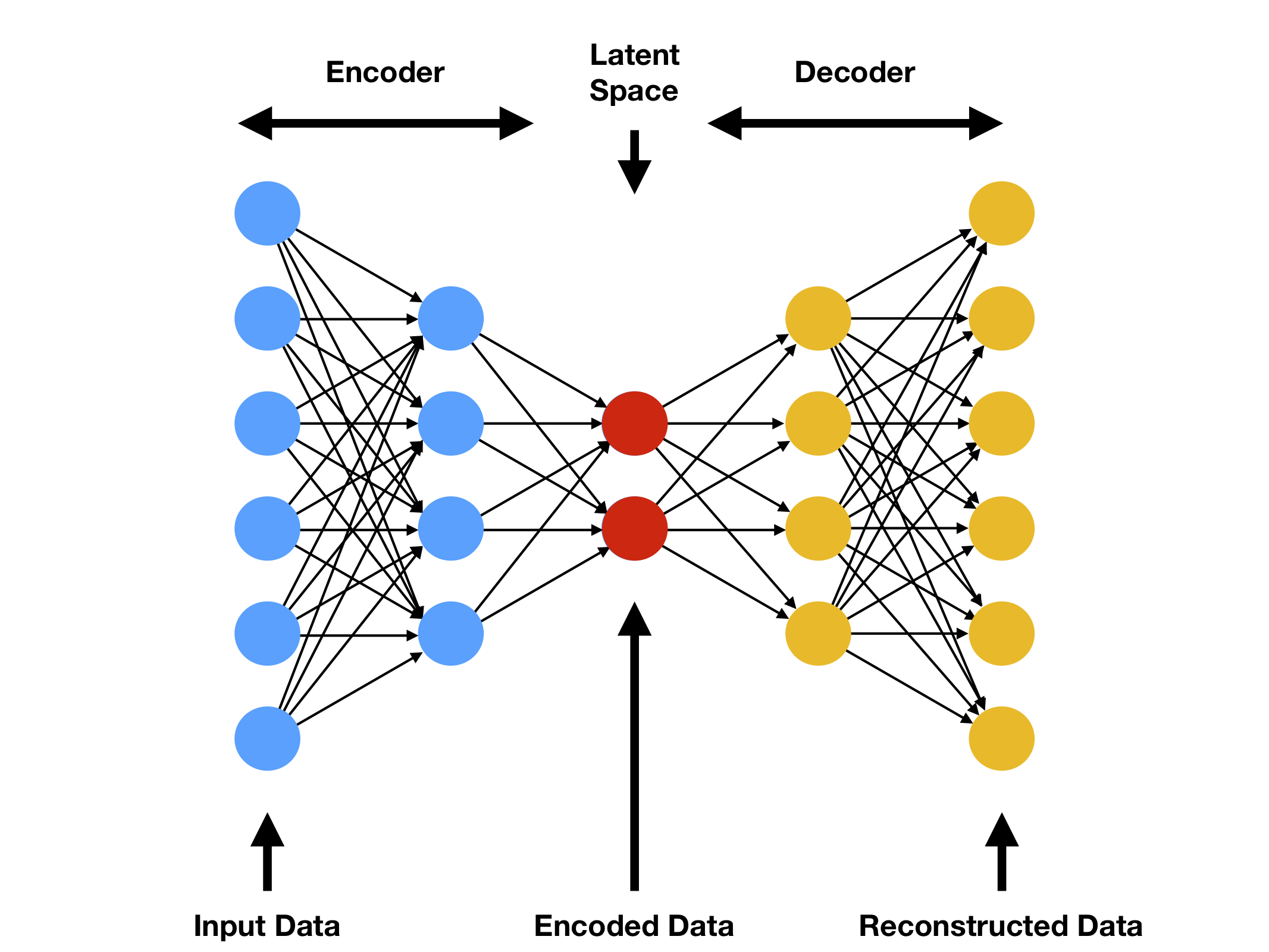
- 딥러닝 기반의 비지도 학습 모델
- 입력 데이터를 압축된 표현으로 인코딩 후 다시 디코딩하여 원래 입력데이터를 복원하는 메커니즘
- Latent Space는 Input data의 Importance Feature를 압축한 곳
- 장점으로는 앞에 나왔던 방법과는 달리 비선형 관계를 포착할 수 있으며, 대용량 데이터에서 효과적이다.

please bbbbbbbbb 😂