
1주차 숙제
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
df = pd.read_csv('Salary.csv')
df.head(5)
#현재 그래프에서는 2개의 데이터만 나와있음
#print(df.shape)
#데이터 크기는 (35, 2)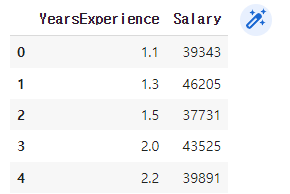
기존 csv에 있는 데이터 불러왔을때 데이터 상태 print(df.shape) 를 사용했을때 데이터의 크기는 (35, 2)가 나왔는데 35개의 데이터가 2열로 되어있다는 의미
sns.pairplot(df, x_vars=['YearsExperience'], y_vars=['Salary'], height=4)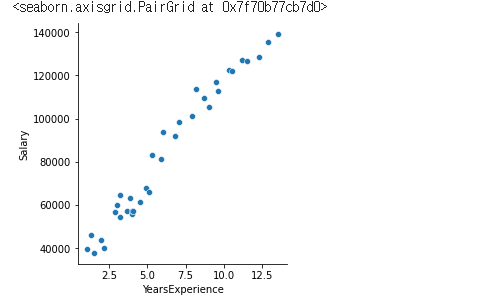
그래프에 찍어 봤을때의 데이터 모양
이후 데이터를 가공하고, 분활하여 학습을 시켜야 한다.
데이터 가공
x_data=np.array(df[['YearsExperience']], dtype=np.float32)
y_data=np.array(df[['Salary']], dtype=np.float32)
x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
print(x_data.shape)
print(y_data.shape)
데이터를 가공할때 x 데이터의 모양과 y데이터의 모양을 확인하여 모양을 일치 시켜줘야 한다.
데이터 분활
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)값이 35개중에 80프로는 데이터만 사용하고 20프로는 테스트로 설정을 해주고 random_state 랜덤으로 값을 지정해준다.
데이터 학습
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.01))
#러닝 레이트?
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)
데이터를 많이 검증할수록 데이터가 더 정확해지며 학습이 좋아진다.
y_pred = model.predict(x_val)
plt.scatter(x_val[:, 0], y_val)
plt.scatter(x_val[:, 0], y_pred, color='r')
plt.show()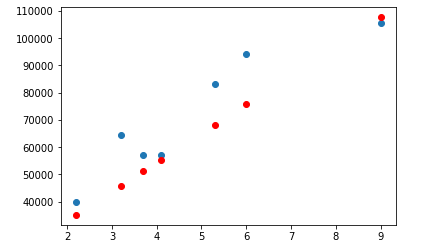
그래프로 보았을때 점과 최대한 비슷하게 그려져 있어야 더 정확하게 학습이 된것이다.
import os
os.environ['KAGGLE_USERNAME'] = 'joonpyojang' # username
os.environ['KAGGLE_KEY'] = '4c50da3eb86b3e5ddcddb419b33c5985' # key
!kaggle datasets download -d rsadiq/salary
!unzip salary.zip
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
df = pd.read_csv('Salary.csv')
x_data=np.array(df[['YearsExperience']], dtype=np.float32)
y_data=np.array(df[['Salary']], dtype=np.float32)
x_data = x_data.reshape((-1, 1))
y_data = y_data.reshape((-1, 1))
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.01))
#러닝 레이트?
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=100 # epochs 복수형으로 쓰기!
)
y_pred = model.predict(x_val)
plt.scatter(x_val[:, 0], y_val)
plt.scatter(x_val[:, 0], y_pred, color='r')
plt.show()
개발일지용 메모장