
-
처음 내 key 데이터 입력
import os os.environ['KAGGLE_USERNAME'] = 'joonpyojang' # username os.environ['KAGGLE_KEY'] = '4c50da3eb86b3e5ddcddb419b33c5985' # key -
데이터 url 로 불러와 알집 풀기
!kaggle datasets download -d kandij/diabetes-dataset !unzip diabetes-dataset.zip -
사용하는 툴 import
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.optimizers import Adam, SGD #tensorflow를 가지고 논리 회귀 구현 import numpy as np import pandas as pd #데이터셋 csv 파일을 읽어줌 import matplotlib.pyplot as plt #그래프 그리기 import seaborn as sns #그래프 그리기 from sklearn.model_selection import train_test_split #traning set 과 validatation set 나눠줌 from sklearn.preprocessing import StandardScaler #전처리용 -
데이터 csv 파일 df 저장 후 확인
df = pd.read_csv('diabetes2.csv') df.head(5)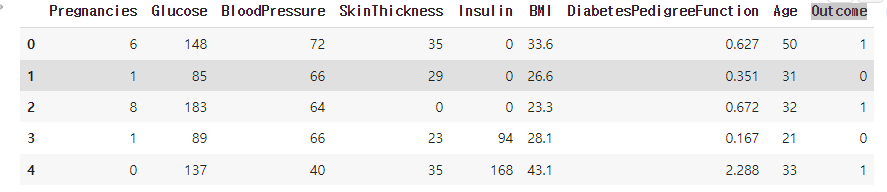
-
만약 데이터에 이름이 없을 시 이름 지정
df = pd.read_csv('train_and_test2.csv', usecols=[ 'Age', # 나이 'Fare', # 승차 요금 'Sex', # 성별 'sibsp', # 타이타닉에 탑승한 형제자매, 배우자의 수 'Parch', # 타이타니게 탑승한 부모, 자식의 수 'Pclass', # 티켓 등급 (1, 2, 3등석) 'Embarked', # 탑승국 '2urvived' # 생존 여부 (0: 사망, 1: 생존) ]) #usecols로 사용할 colum 만 따로 추출하여 저장 df.head(5) -
null 데이터 있는지 확인하고 있으면 drop
print(df.isnull().sum()) print(len(df)) df = df.dropna() #비워져 있는 데이터를 제거 print(len(df)) -
x , y 데이터 분활 및 지정
x_data = df[['BMI','DiabetesPedigreeFunction','Age']] x_data = x_data.astype(np.float32) y_data = df[['Outcome']] y_data = y_data.astype(np.float32) #32 비트 소수점으로 만들어줘야 keras에서 사용이 가능하다 #outcome 데이터가 당요병 유무이기 때문에 해당 유무로 데이터를 구분 x_data.head(5) y_data.head(5)특정 데이터만 입력할때
x_data = df.drop(columns=['Outcome'], axis=1) x_data = x_data.astype(np.float32) y_data = df[['Outcome']] y_data = y_data.astype(np.float32)x축에 Outcome 이외의 데이터 입력
-
데이터 표준화 작업
scaler = StandardScaler() #scaler 정의 x_data_scaled = scaler.fit_transform(x_data) #데이터 표준화 시켜주기 print(x_data.values[0]) print(x_data_scaled[0]) -
학습 데이터 분활
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021) print(x_train.shape, x_val.shape) print(y_train.shape, y_val.shape) -
모델 학습
model = Sequential([ Dense(1, activation='sigmoid') #actication 함수에 sigmoid를 넣어주면 sigmoid 함수를 실행한다. linear regression을 한번 하고 실행 ]) model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.01), metrics=['acc']) #이진 논리회귀에서는 binary_crossentropy을 사용한다. metrics는 loss 값만 보고 데이터가 학습이 잘되는지 확인할 수 없어 정확도를 0-1로 보여준다. model.fit( x_train, y_train, validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증 epochs=20 # epochs 복수형으로 쓰기! )다항 논리 회로일때는
sigmoid대신softmax를 사용

개발일지용 메모장