이번 시리즈에서는 AWS의 대표적인 NoSQL 데이터베이스인 DynamoDB의 작동방식에 대해서 이해한 바를 공유하려고 합니다. DynamoDB를 이해하려면 NoSQL이 무엇인지 알아야합니다.
NoSQL 데이터베이스란?🧐
NoSQL이 무엇의 약자인지는 많은 의견들이 있었지만, 현재는 Not Only SQL 로 설명하는 것이 다수를 차지하고 있습니다. "SQL만을 사용하지 않는 데이터베이스 관리 시스템" 을 의미하는 말로, 특정 데이터 모델에 대해 특정 목적에 맞추어 구축되는 데이터베이스로서 유연한 스키마를 갖추고 있는 것이 가장 큰 특징입니다.
특징을 간략히 정리하면 아래와 같습니다.
- 디스크 가격보다 컴퓨팅 파워에 포커싱
- 비결정적 스키마
- 인스턴스화된 보기
- 비정규화/계층적
- 대규모 OLTP에 최적화
NoSQL 데이터베이스를 사용해야 하는 이유
RDBMS와 NoSQL 중 어느 것을 사용해야하는지에 대한 논쟁을 하려는 것이 아닙니다.
응용 프로그램마다 요구 사항이 다르며 한 사용 사례에 대한 최선의 기술 선택은 다른 사용 사례에 대한 최상의 선택과 다를 수 있습니다. 따라서 예측 가능한 미래에 관계형 데이터베이스는 다양한 비관계형 데이터 저장소와 함께 계속 사용될 것으로 보입니다.
NoSQL 데이터베이스는 낮은 지연 시간의 애플리케이션을 포함한 수많은 데이터 액세스 패턴에 맞도록 설계되었습니다. 아래에 NoSQL 데이터베이스의 특징들을 간략하게 정리하였습니다.
- 유연성
일반적으로 유연한 스키마 를 제공하여 보다 빠르고 반복적인 개발을 가능하게 해줍니다. 이같은 유연한 데이터 모델은 반정형 및 비정형 데이터에 이상적으로 만들어 줍니다. - 확장성
일반적으로 고가의 강력한 서버를 추가하는 대신 분산형 하드웨어 클러스터를 이용해 확장 하도록 설계되었습니다. 일부 클라우드 제공자들은 완전관리형 서비스로서 이런 운영 작업을 보이지 않게 처리합니다. - 고성능
특정 데이터 모델 및 액세스 패턴에 대해 최적화 되어 관계형 데이터베이스를 통해 유사한 기능을 충족하려 할 때보다 뛰어난 성능을 얻게 해줍니다. - 고기능성
각 데이터 모델에 맞춰 특별히 구축된 뛰어난 기능의 API와 데이터 유형을 제공합니다.
NoSQL 데이터베이스의 유형
- Key-value ✅
- Document
- Graph
- In-memory
- Search
NoSQL 데이터베이스의 유형은 위와 같이 크게 5가지로 나뉘고, 오늘 알아볼 DynamoDB는 key-value 형식에 해당합니다.
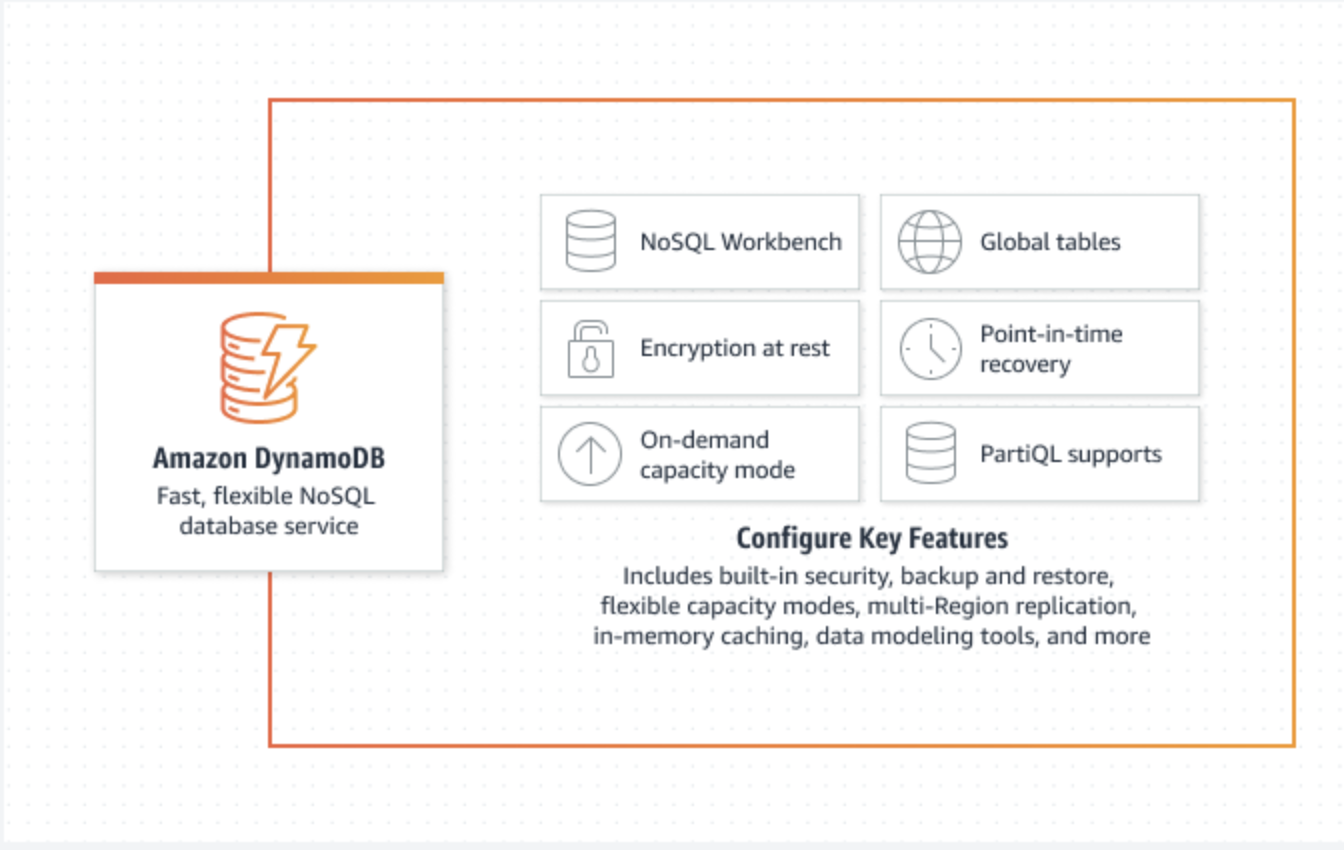
Amazon DynamoDB 😎
모든 규모에서 10밀리초 미만의 성능을 제공하는 빠르고 유연한 NoSQL 데이터베이스 서비스
aws 공식 사이트에서 DynamoDB를 위와 같이 소개하고 있습니다.
기존 RDBMS에서도 아래와 같이 대규모 데이터 처리가 가능합니다.
- RDS read replica
- Sharding
다만 DynamoDB와 비교해서 몇가지 뚜렷한 단점이 있습니다.
replica가 늘어나면 bin-log 복제에서 write node에 부하를 주고 sharding을 잘못하면 데이터가 한 쪽으로 몰릴 수 있습니다.
주요 특징
-
fully managed
- aws가 해당 리소스를 사용자 대신 관리해준다는 의미로, db 관리 포인트가 거의 없을 수 있습니다. (대신 키 설계를 어떻게 하는지가 매우 중요!)
-
mission-critical OLTP
- OLTP에 특화된 데이터베이스입니다.
- 다운타임 또는 성능 저하 없이 테이블의 처리 능력을 확장 또는 축소할 수 있습니다.
-
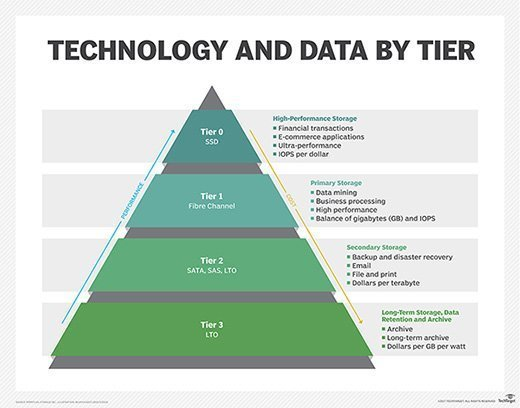
Tier 0 Service
일반적으로 계층 수가 적을 수록 비용은 높아지고 해당 계층에서 데이터를 검색하는 데 걸리는 시간은 줄어듭니다.
- 실제로 aws의 대부분의 서비스에는 dynamoDB가 base로 사용된다고 합니다.
-
multi-region replication
- 모든 데이터가 ssd에 저장되고 aws 리전의 여러 가용 영역에 걸쳐 자동 복제되기 때문에 확실한 고가용성과 데이터 내구성을 제공합니다.
-
partition
- data는 partition별로 쪼개집니다.
- partition별로 저장할 때는 hash function 적용하여 랜덤으로 분류됩니다.
- partition은 늘어날 수 있지만, 한번 늘어난 partition은 줄어들지 않습니다.
- data는 partition별로 쪼개집니다.
이번 장에서는 NoSQL에 대한 이해 및 dynamoDB에 개요에 대해 간략하게 정리하였습니다. 다음 글에서는 작동방식 및 주요기능에 대하여 이어서 정리 하겠습니다😎
