Deep pre-trained language models
ELMO
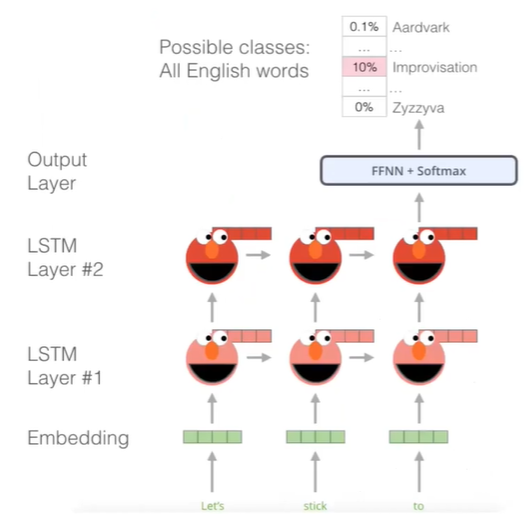
- BiLSTM기반의 Contextualized Word Embedding을 사용한다. 즉 Context에 기반하여 단어를 embedding 해준다.
- 학습은 앞 단어들을 이용하여 어떤 단어가 나올지 예측하여 word embedding을 학습시켜준다.
- 사실 Bi-Directional한 것은 실사용 모델에서는 유용하지 않지만, "학습을 위한 학습" , Pre-trained에서는 유용하게 쓰인다.
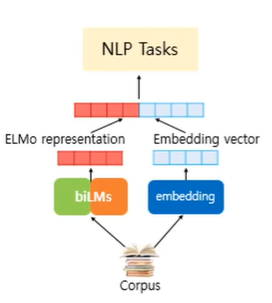
- ELMO와 같은 word-embedding pre-trained 모델은 Glove, char-cnn과 같은 embedding 후에 사용해주고, 이후 NLP task를 수행해준다.
- ELMO와 같이 pre-trained 모델들이 좋은 성과를 보여주면서, Transformer-based의 모델들이 생겨났다. Transformer에서 언급한 것과 같이 대표적으로 BERT와 GPT가 있다.
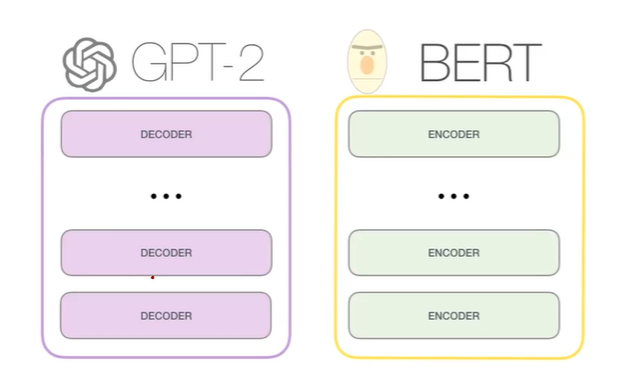
GPT
- GPT는 Transformer network의 Decoder를 이용한 모델이다.
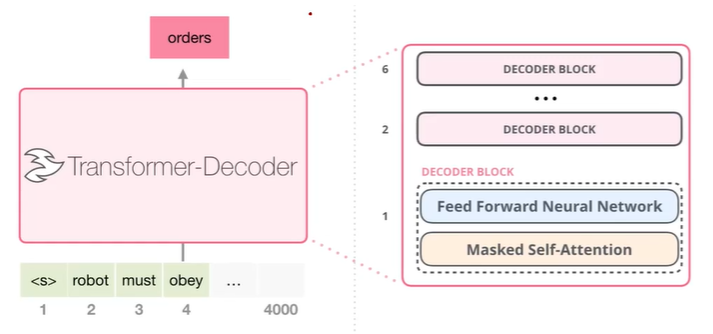
- 위 이미지는 GPT는 매우 쉽게 표현한 이미지이다. 우리는 여기서 Masked Self-Attention이 기존의 Transformer model과 다른 것을 알 수 있다.
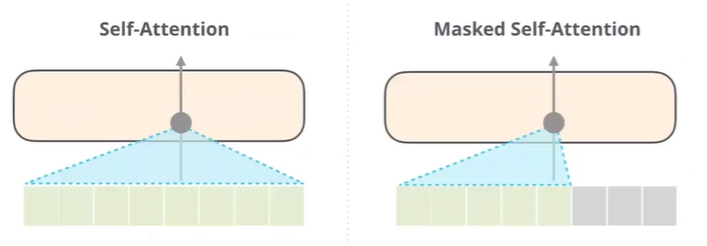
- Masked Self-Attention은 기존의 NLP에서 당연한 것이다. 전체를 고려하지 않고, 앞 단어만을 이용한다.
- 따라서, 사용법이 명확히 나뉘는데, Generation model의 경우 앞단어를 이용하여 다음 단어를 생성해내는 것이기 때문에 Masked Self-Attention을 사용하고, 나머지 문장전체를 고려하여 문제를 해결하는 task는 Self-Attention이 더 적합하다.
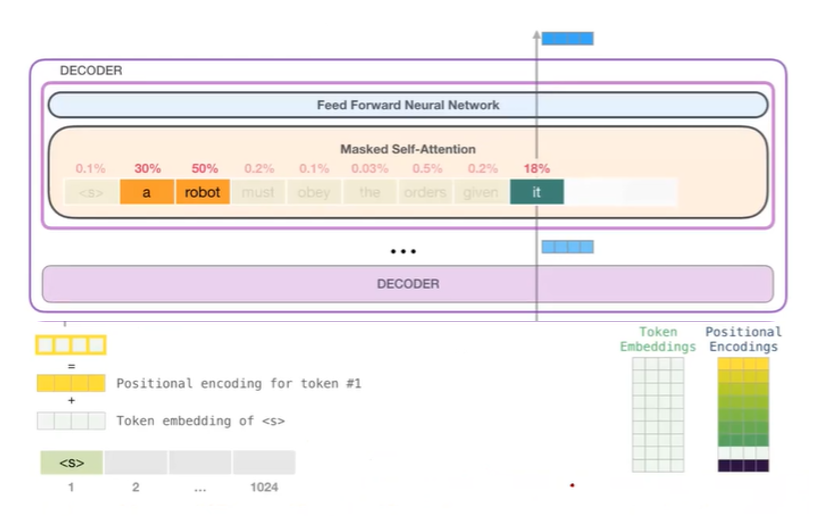
- 위는 GPT의 모델이다. 기존 Transformer과 똑같이 Positional encoding을 해주고, Masked Self-Attention을 이용해준다. 하지만, Transformer의 Encoder는 사용하지 않기 때문에 기존의 Encoding-Decoding Attention layer는 제거해주었다. 또한, Residual 은 그림에는 표현되어있지않지만, Transformer와 똑같이 적용해 주었다.
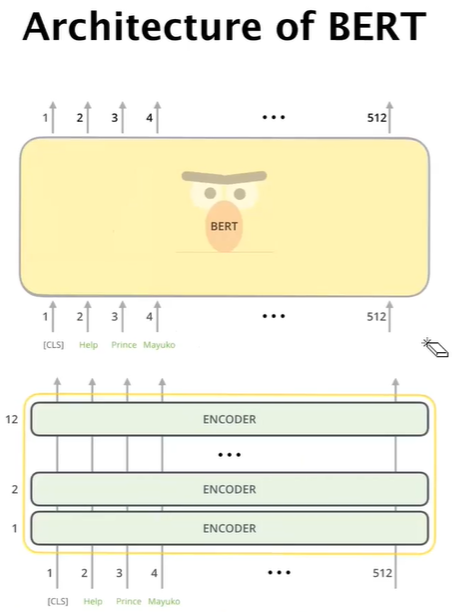
- Layer의 개수만 다르고 Transformer와 아주 유사하다.(Bert의 hidden size는 768이다)
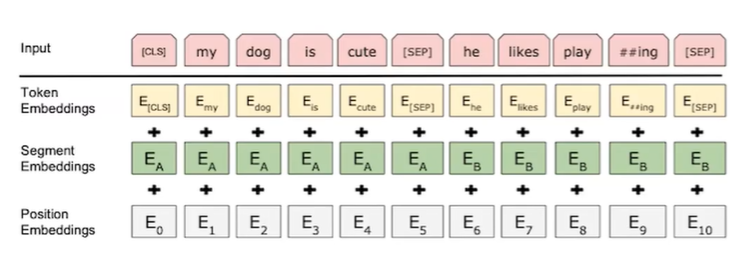
- BERT의 Encoder이다. Segment Embedding의 경우는 Positional Embedding보다 High Level로 생각하면 좋다.(ex E_A는 질문 E_B는 답)
- Position Embedding은 Encoding과 다르게 값을 그대로 쓰는 것이 아니라, 값을 살짝 바꿔주어 사용한 것이다.
Summary
- 공부를 하는데 있어서, ELMO, GPT, BERT 등과 같은 Pre-trained model의 네트워크를 정확히 다 공부할 필요는 없다. 나중에 그 내용이 필요하게 되면, 공부하는 것이 좋다.
- 결국 Pre-trained network는 down stream task를 위한 것이다. Fine-tuning 또한 좋은 성능을 보여준다.
