Machine Reading Comprehension with Attention(2)
BiLSTMs + Attention models
- BiLSTMs + Attention models은 NLP에서 좋은 성능을 보여주었는데, 실제적인 QA문제에서도 좋은 성능을 보여줄까?
- 해당 문제를 확인해보기 위해 Stanford Question Answering Dataset(SQuAD)를 사용하였다.
- SQuAD는 아래와 같이 구성되어 있다. Passage : selected from wikipedia,Question : crowdsourced, Answer: must be a span in the passage.

-
SQuAD에서 좋은 성능을 보여주었지만, 분석한 결과 질문을 이해하는게 아니라, 비슷한 문장을 찾고 거기서 없는 단어를 사용하는 것처럼 보여졌다. 그래서 두가지 문제점을 제시한다.
1) questions that can be answered by span selection
2) Annotators can see the paragraph when writing questions high lexical overlap between question and paragraph -
하지만 이런한 특징은 "검색" task에서는 좋은 특징이라 볼 수 있다. 기존의 exact matching을 soft matching으로 변경해 주었다.
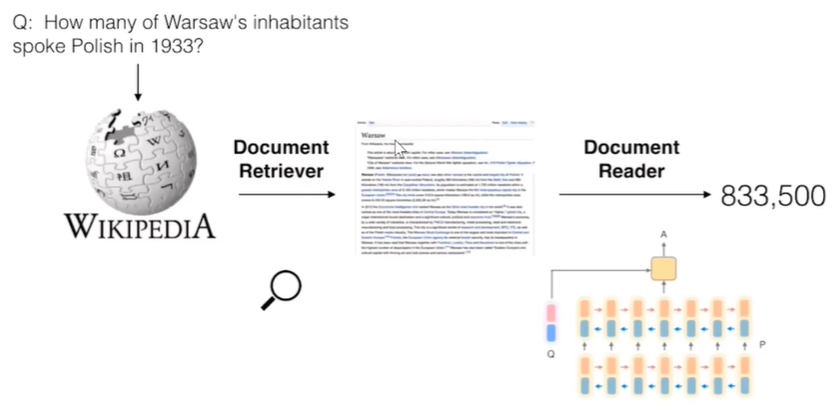
- 위 그림은 "DrQA"의 그림이다. DrQA해결하고자 하는게 Open-domain 상의 문장을 이용하여 QA 문제를 푸는 것 이였고, 기존의 phargraph 중점에서 Document Reader가 사용되었다.
Summary
-
기계독해는 하나의 NLP를 대표하는 task이고, seq2seq, transformer 등이 나타나게된 NLP에서 아주 대표적인 task이다. 즉 기계독해로부터 NLP가 성장한 것으로 생각되어진다.
-
또한, QA task를 가지고, 천하제일 무술대회처럼 경쟁을 통해 좋은 모델들이 탄생하였다.
