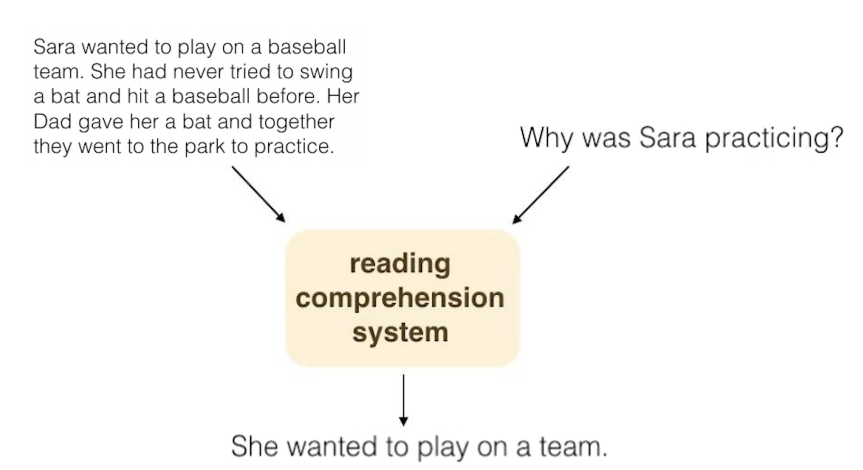
Machine Reading Comprehension(MRC)
- 앞서 우리는 NLP의 중요한 카테고리 중에 하나인 Translation에 대해 알아보았다. 이번에는 Machine Reading Comprehension(MRC)에 대해 알아 볼 것이다.
- MRC는 Machine이 사람과 유사하게 문장을 읽고 문제를 해결할 수 있도록 하는 것을 목표로 발전해왔다.
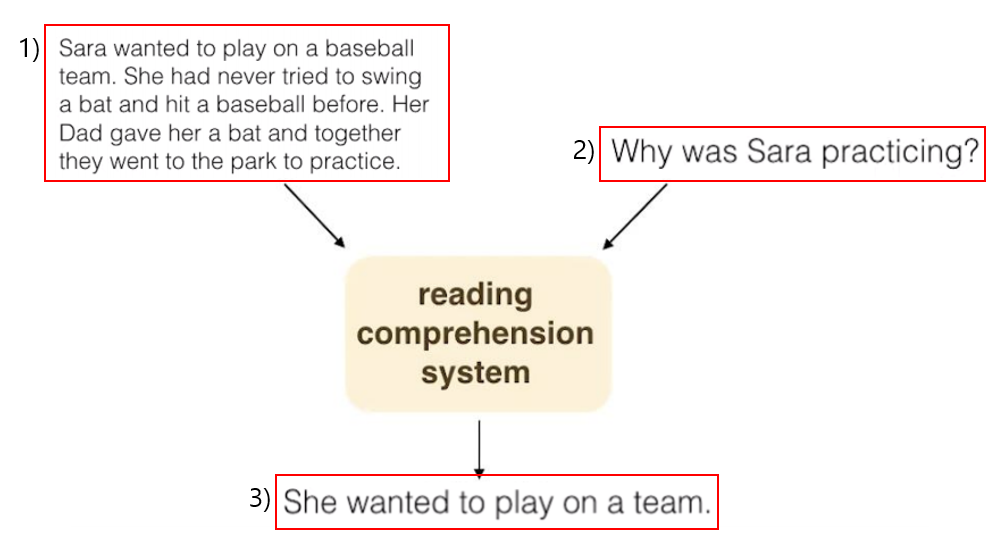
- MRC는 (1)과 같은 문장을 machine이 이해를 하고, (1)에 대한 (2)와 같은 쿼리가 들어왔을때, 알맞는 정답인 (3)을 return을 해주는 것을 목표로 한다.
History of MRC
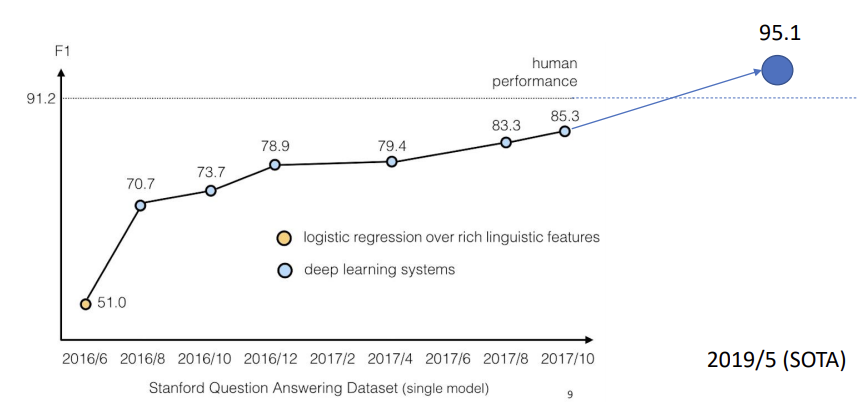
- MRC는 Deep Learning이 나오기 전에도 많은 시도가 되어왔다. 하지만 2015년 이후부터, CNN/Daily Mail, SQuAD 등 100k 이상의 데이터를 가지고 있는 거대 데이터셋이 등장하고, End-to-end의 neural network를 MRC에 활용하기 시작하였다.
- 이후 MRC에서의 Deep Learning의 효과를 알게 되었고, 아래와 같이 급격한 성장을 보여주었다.
DeepMind/Stanford Attentive Reader
-
초기 MRC를 Deep Learning으로 푼 대표적인 두 모델은 DeepMind와 Standford의 Attentive Reader이다.
-
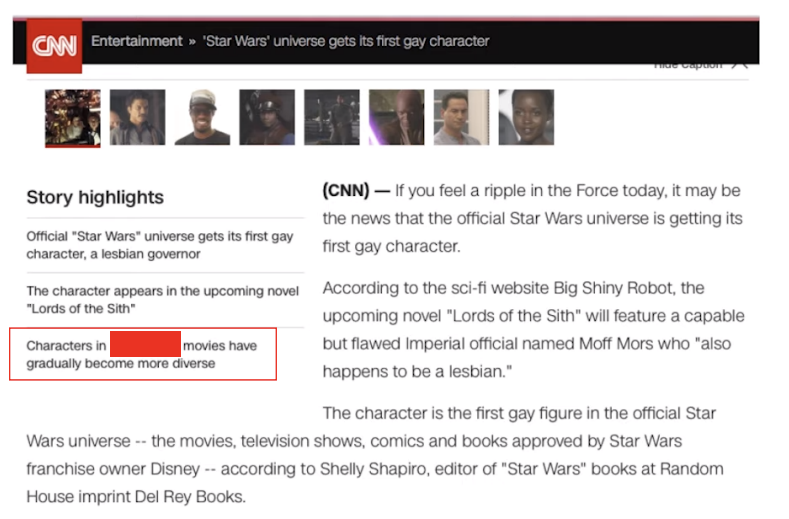
해당 두 모델을 살펴보자. 우선, 해결하려고하는 데이터를 살펴보자. 데이터셋은 CNN/Daily Mail Datasets이다.
-
위와 같이 CNN 기사의 본문을 학습시키고, 위 빨간 박스안의 빈칸을 채워두고 해당 빈칸에 대한 정답을 맞추는 것이 MRC task이다. 좀 더 자세히 봐보자.

-
Question안에 @placeholder에 들어갈 알맞은 단어를 passage안에서 찾아 Answer로 return해준다.
-
학습 방법은 다음과 같다. 1) Encoder the question, 2) Encode the passage, 3) Model the interaction between passage and question, 4) Infer teh answer
-
1) Encoder the question
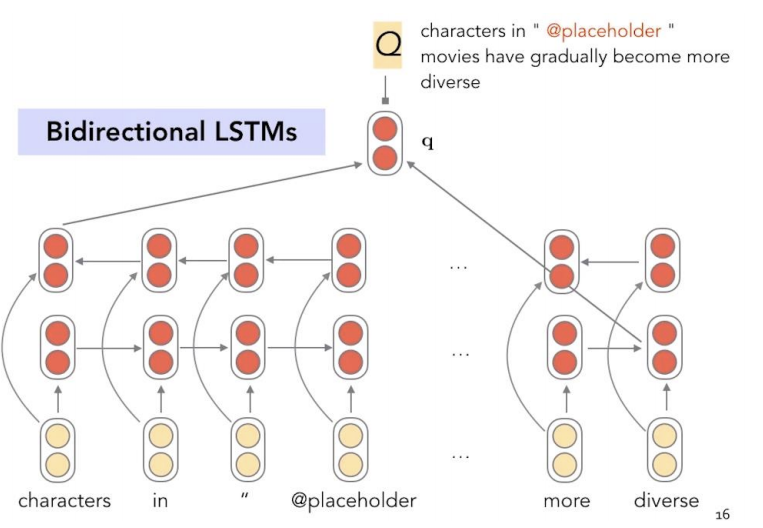
- 처음으로 question을 encoding시켜준다. 해당 문장은 앞서 알아봤던, Bidirectional LSTMS을 이용하여 encoding 시켜주어 question의 특징이 들어있는 q vector를 생성해준다.
-
2) Encoder the passage
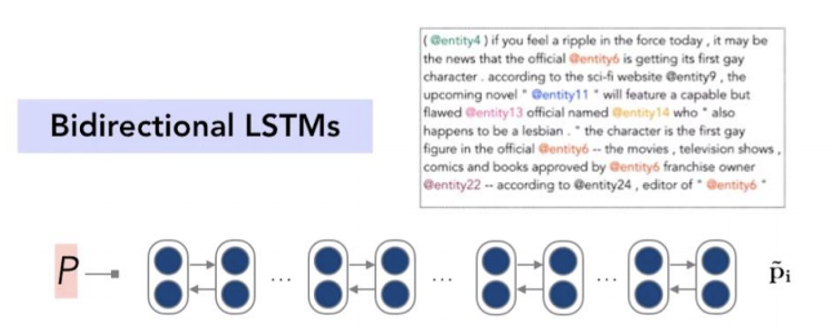
- Passage 역시 Bidirectional LSTM을 이용하여 Encoding 시켜준다. 하지만 앞선 question encoding과의 차이점은, question encoding에서는 question을 대표하는 하나의 vector q로 표현해주었지만, passage의 경우는 단어 하나하나를 주변의 단어들을 이용하여 encoding한 것이다. 따라서 output이 p_i 로 표현된다.
-
3) Model the interaction between passage and question
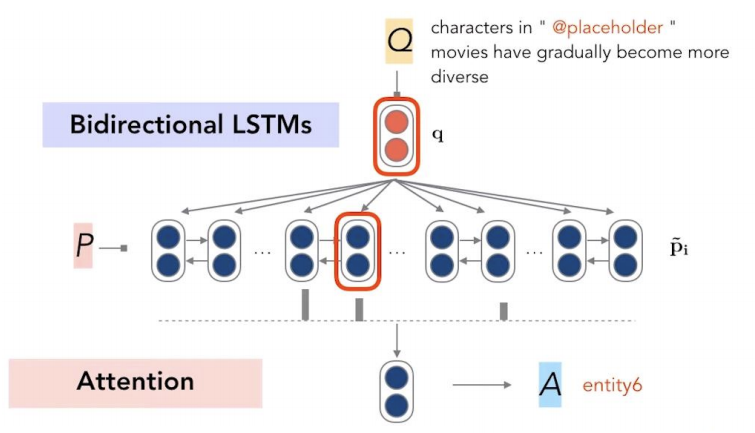
- 앞서 생성한 question vector인 q와 passage vector p_i를 같이 이용하여 Attention vector를 만들어준 후, 해당 Attention을 p_i에 곱해주어 가장 큰 값을 갖는 vector를 정답으로 채택한다.
- 이 부분에서 DeepMind와 Stanford Attentive Reader의 차이점이 확인 할 수 있다.
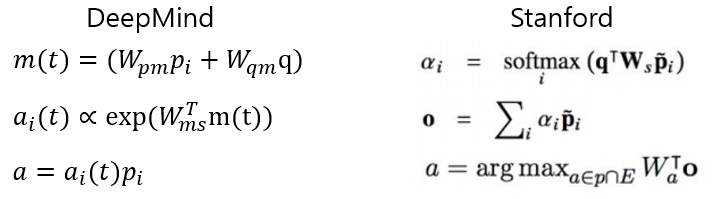
- Stanford는 query와 passage에 같은 weight matrix를 공유하였지만, DeepMind의 경우는 각각의 weight matrix를 가지고, 합쳐주는 것을 볼 수 있다. 즉 DeepMind보다 Standford의 방식이 query와 passage가 더 잘 융합된 것으로 볼 수 있다. 이는 결과를 통해서도 확인 할 수 있다.
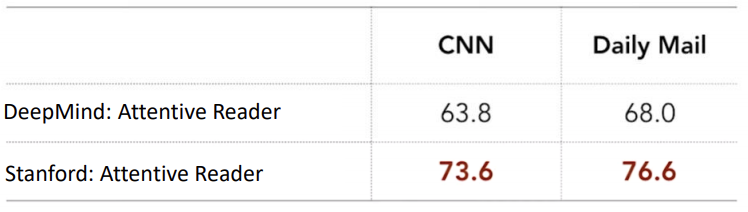
Stanford Attentive Reader(Neural Net) vs Categorical feature classifier
- 여기서는 Neural Net인 Stanford Attentive Reader와 Deep Learning 이전의 Categorical feature classifier와의 차이점을 알아볼 것이다. 우선 전체적인 결과를 통해 Stanford Attentive Reader의 성능이 더 좋은 것을 확인할 수 있다.

- 좀 더 자세히 분석해보자면, 문제를 6가지로 나눠볼 수 있다. (1) Exact match, (2) Parapharsing, (3) Partial clue, (4) Multiple sentence, (5) coreference errors, (6) Ambiguous/hard cases
- 전체 데이터셋에서 각각에 대한 비율은 다음과 같다.

- 각각의 task에 대해 Stanford Attentive Reader와 Categorical feature classifier차이를 알아보자
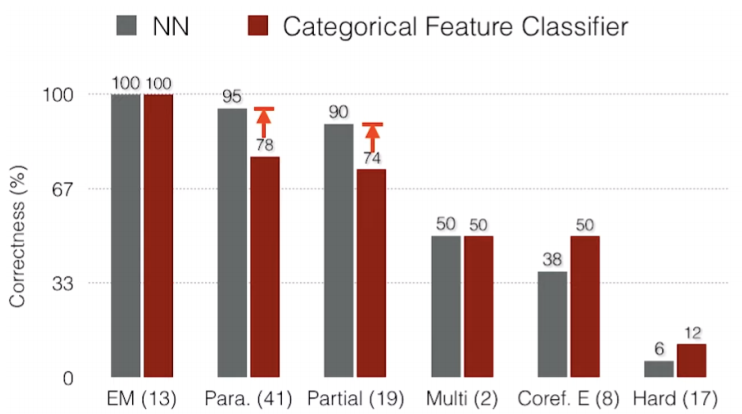
- 주변의 단어들을 고려하는 Paraphrasing과 Partial cluse에서 LSTM을 사용하는 Neural Network가 좋은 성능을 보여주는 것을 확인 할 수 있다. 또한 해당 task에 집중하는 Categorical feature classifier는 ambiguous/hard case와 Coreference errors에서 더 좋은 성능을 보여주는 것을 확인 할 수 있다.
- 즉 Neural Net을 사용하는 것이 Categorical feature classifier보다 더 general하게 성능이 좋은 것을 확인 할 수 있다.
- 여담으로 요즘은 모델을 복잡하게 만들어 모델의 성능을 좋게하는 것보다 데이터를 잘 가공하여 성능을 향상시키는 방법이 대세(?)라고한다.. 모두 지금부터 "https://analyticsindiamag.com/big-data-to-good-data-andrew-ng-urges-ml-community-to-be-more-data-centric-and-less-model-centric/" 해당 페이지를 잘 읽어보고, Andrew ng 코인을 탑승해보는 것도 좋은 기회인것같다.
