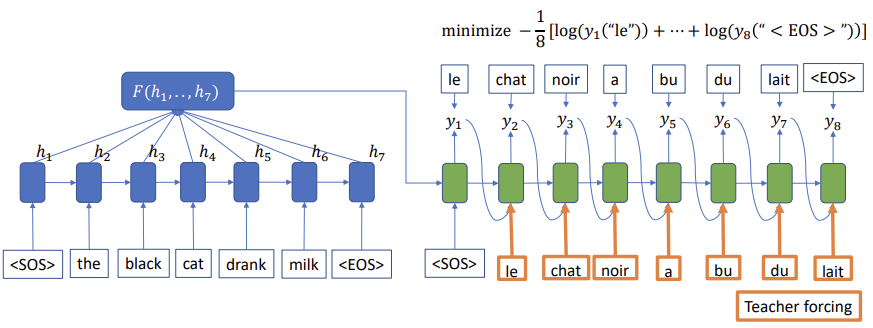
Sequence to Sequence Model
- 우리는 RNN의 Many to One, Many to Many, One to Many와 같은 활용법부터해서 LSTM, GRU와 같은 다양한 모델까지 알아보았다.
- 이제는 우리는 NLP분야에서의 꽃이라고 할 수 있는, Translation 문제를 RNN을 이용하여 풀어보려고한다.
- 우선, Translation의 input과 output은 Sequence는 다르다는 것을 알 수 있다. 예를 들면 'The black cat drank milk'는 sequence가 5이다. 이 문장을 프랑스어로 translation하게되면, ' le chat noir a bu du lait'로 sequence가 7이다. 따라서 이렇게 input과 output의 sequence가 다른 형태를 다루기 위해 Sequence to Sequence이 나타났다.
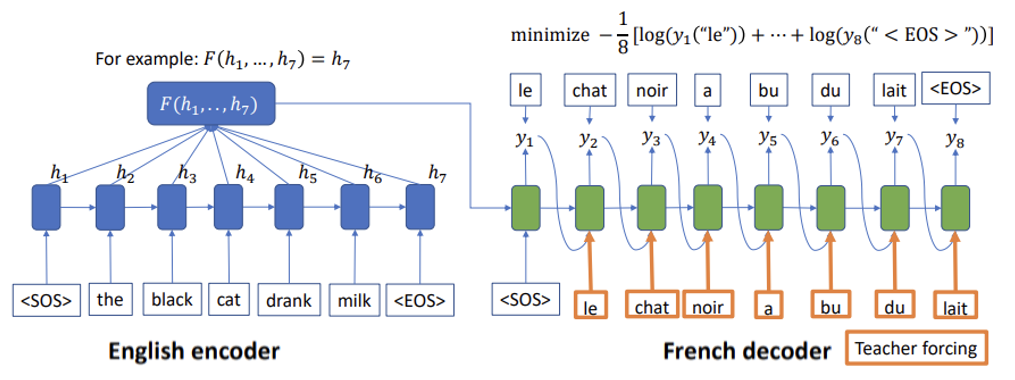
- English encoder에서는 input으로 들어오는 단어 ['the', 'black', 'cat', 'drank', 'milk'] 가 RNN모델을 통해 생겨나는 hidden vector[h1, h2, h3, h4,...,h7]을 만들어준다.
- 이후 French decoder는 input data를 품고있는, hidden vector를 hidden vector로 받고, french인 ['le', 'chat', 'nori', 'a', 'bu', 'du', 'lait']를 input으로 받고, 다음에 어떤 단어가 들어갈지 예측한다.
- 이러한 학습을 통해 우리는 이제 input과 output의 sequence가 다른 데이터에 대해서도 학습할 수 있다.
- 하지만 우리는 여기서 문제점을 발견할 수 있다. 첫번째로, Decoder의 time step에서 같은 종류의 encoder embedding을 사용한다는 것이다. 즉, cat을 뜻하는 chat과 milk를 뜻하는 lait가 모두 같은 input embedding으로부터 생성된다는 것이다. 또한 encoder의 embedding이 모든 정보를 소유하고 있어야한다는 것이다.
- 이러한 문제점을 우리는 Attention을 통해 해결할 수 있다.
Attention
- Attention은 여러 hidden vector가 존재할때, 중요하다고 생각하는 vector에 대해 가중치를 주는 것이다.
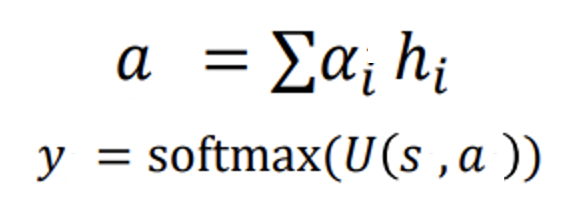
- 위 식을 보면 Attention에 대해 더 잘 알 수 있다. alpha는 trainiable parameter로 hidden vector(h) 중 중요한 hidden vector를 뽑아 줄 수 있다. 그렇게 뽑힌 hidden vector a는 해당 state(s)에 같이 사용될 수 있다.
- 예를 들면, 고양이를 뜻하는 [chat]을 예측할 때, 모든 hidden vector를 사용하는 것이 아니라, 모든 hidden vector중 cat에 가중치를 주어, chat을 학습 할 수 있도록 해준다.
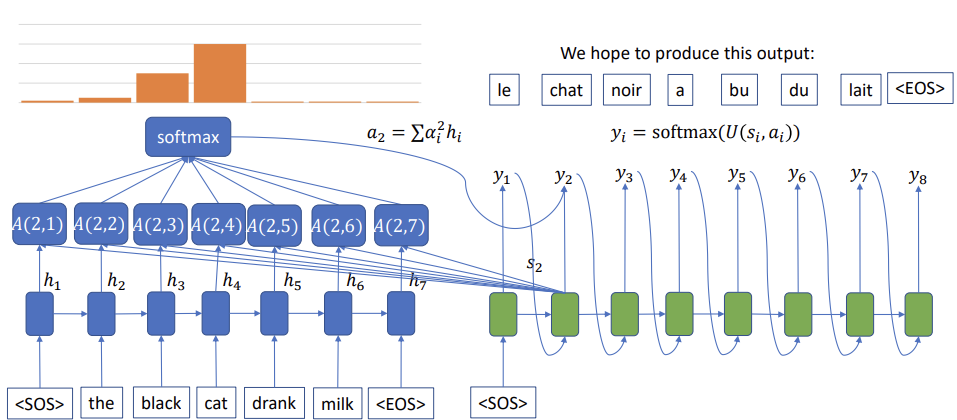
- 위 그림을 통해 더욱 명확히 알 수 있다. chat을 예측하기 위해, hidden vector들의 softmax값들 중 chat과 같은 의미를 가진 cat의 확률이 가장 높은 것을 확인 할 수있다.
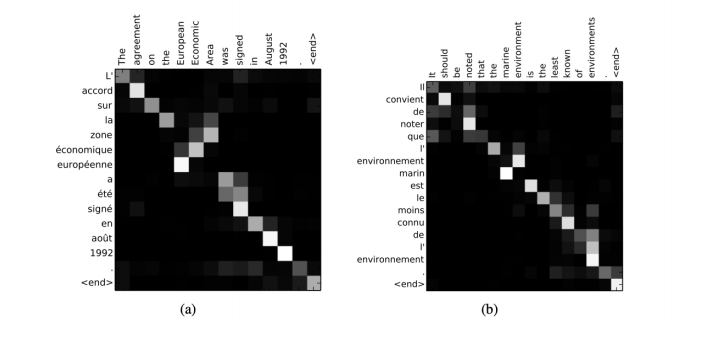
- 실제로 단어에 대한 attention의 가중치를 확인해보면, 같은 뜻을 가진 [August, aout], [Economic, economique] 등 높은 값을 갖는것을 확인할 수 있다.(색이 밝을수록 값이 큰것)
- Attention의 종류로는 Global과 Local Attention이 존재한다.
- Global Attention은 앞서 했던 것과 같이, 모든 hidden vector를 고려하여, 중요한 hidden vector를 뽑는것이다. 하지만, Sequence가 커지면, Computation이 매우 커지게 되고, 정말 중요하지 않는 hidden vector까지 고려하기 때문에, noise가 끼게된다.
- 위와 같이 Global Attention의 문제점으로 나온것이, Local Attention이다. 모든 hidden vector를 고려하는 것이 아니라, 유사한 위치에 있는 hidden vector만을 고려하는 것으로, image에서 Fully connected network와 CNN과의 차이점을 생각하면 좀 더 이해하기 쉬울 것이다.
