Deep Learning for Natural Language
- Deep Learning은 데이터를 모델의 input으로 사용하여, 나온 output 값과 실제 정답과의 차이를 줄여가며 학습을 한다. 예를 들어 이미지가 들어왔을 때, 해당 이미지가 어떤 이미지 인지 맞추는 task를 한다고 가정해보자.
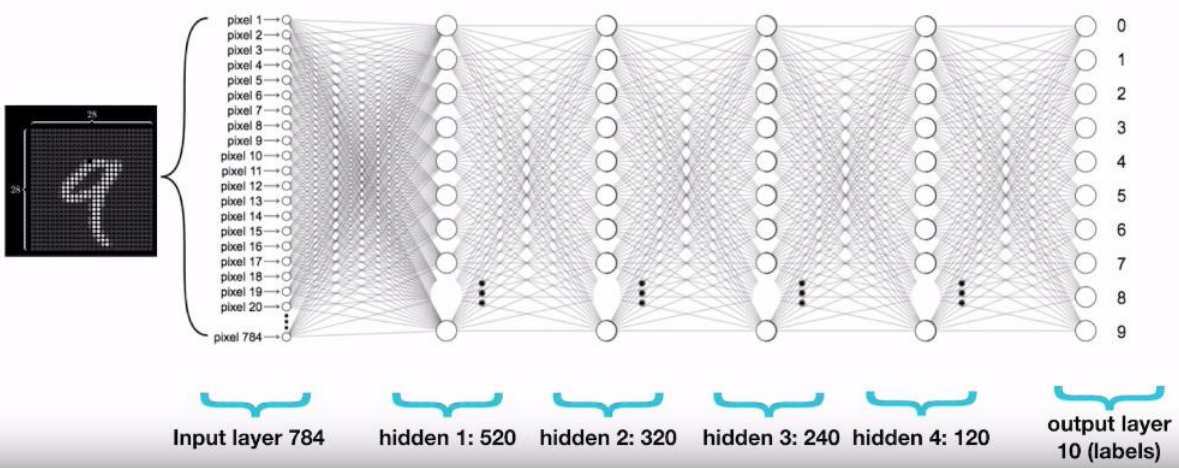
- 위 그림을 보면 해당 이미지(28x28개의 pixel)가 input으로 들어오고, 모델을 통과에 output layer에서 해당 그림이 어떤 숫자인지 맞출 수 있게된다. task의 input이 이미지일 경우는 항상 같은 사이즈(다를때는, 같게 만들어준다)이기 때문에 input layer에 28*28=784개의 뉴런이 존재하게 된다.
-
그럼 Natural Language task에서의 input layer의 뉴런이 몇개여야할까?

-
위 예시는, 'Interstellar'를 보고 감상평을 쓴 글이다. 하고 싶은 task는 해당 감상평이 영화에 대한 긍정적인 평가인가 부정적인 평가인가를 맞추는 것이다. 그럼 모델의 input으로 해당 글이 들어가야하는데, 어떻게 들어가야할까?
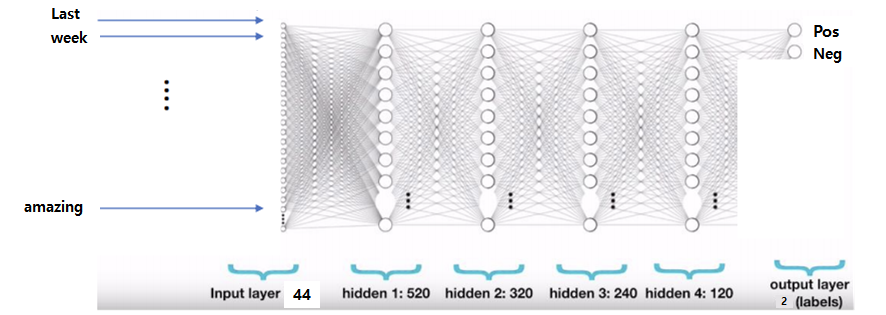
-
모든 단어들을 Input으로 받아 긍정인지 부정인지 맞춰야할까? 하지만 사람의 쓴 글은 글자의 개수가 모두 똑같지 않기 때문에, 위와같이 모든 단어들을 input으로 사용하기는 어렵다.
-
우리는 이제부터 우리가 사용하는 '자연어'를 어떻게 model의 input으로 사용할 수 있을지 알아 볼 것이다.
One-hot Vector/Encoding
- 첫번째로, 우리가 사용하는 언어는 컴퓨터가 알아 들을 수 없다. 따라서 컴퓨터가 이해할 수 있도록, one-hot vector로 변경해준다.
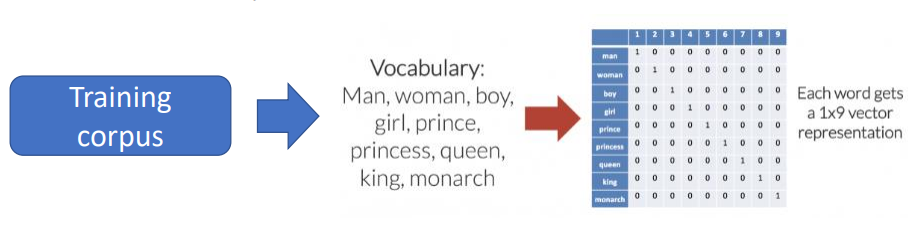
- 해당 그림은 학습하고자 하는 단어의 뭉치(Training corpus)를 컴퓨터가 이해할 수 있도록 변경해준것이다. 총 9개의 단어를 학습하는데 사용하고 싶다면, 각각의 단어가 하나의 특징을 가지도록 오른쪽과 같이 만들어줘야한다.(ex. man=[1,0,0,0,0,0,0,0,0], boy=[0,0,1,0,0,0,0,0,0])
- 다음과 같이 만들어주면 두가지 효과가 있다. input size를 전체 단어의 개수로 fixed된 neural network를 구성할 수 있다. 두번째로, 각각의 단어가 의미하는 바가 다 다르다.

- 아까 인터스텔라로 예를 들면 input layer의 neuron 개수는 해당 문장의 unique한 단어 개수가 될 것 이다.
-
하지만 one-hot vector로 모두 변경해주면 문제가 생긴다. 아래 표에서도 볼 수 있듯이, 대부분의 숫자가 0이고, unique한 단어 개수만큼 dimension이 커지기 때문에, memory 사용양과 computation time이 증가하게 된다. 이건 매우 unefficient하다.
-
그렇다면 이렇게 고차원인 데이터를 줄이는 방법은 없을까?라고 생각해 볼 수 있다.
-
이러한 생각은 Mainfold Hypothesis에 의해 가능하다고 생각되어진다. Mainfold Hypothesis란, 고차원 데이터라 할지라도 해당 정보를 잘 가지고 있는 저차원의 mainfold가 존재한다는 것이다. 이것을 잘 활용한 모델이 'Autoencoder'이다.
- 'Autoencoder'은 다음기회에...
Word Embedding: Word2Vec
-
위에서 단어를 one-hot vector로 만들어 사용해주면 생기는 문제점들에 대해 알아 보았고, 차원을 감소를 통해 더 좋은 단어 embedding을 만들려고한다. 이것이 word embedding이다.
-
Word2Vec은 Word Embedding을 대표하는 embedding 방법이다. Word2Vec은 비슷한 단어는 비슷한 문맥에서 나온다는 Distributional Hypothesis를 가정하고 사용되었다.

-
위 그림과 같이, 뉴스에서 President ~ said yesterday와 같은 문맥에서 ~은 아주 유사하다는 것을 이용한다. 해당 ~에 나오는 단어 Moon, Trump와 Jinping은 모두 한 국가의 원수를 뜻한다. 이런식으로 학습하는 방식을 Word2Vec에서 CBOW 방식이라고한다.
Word2Vec(CBOW) : Continuous Bag of Words
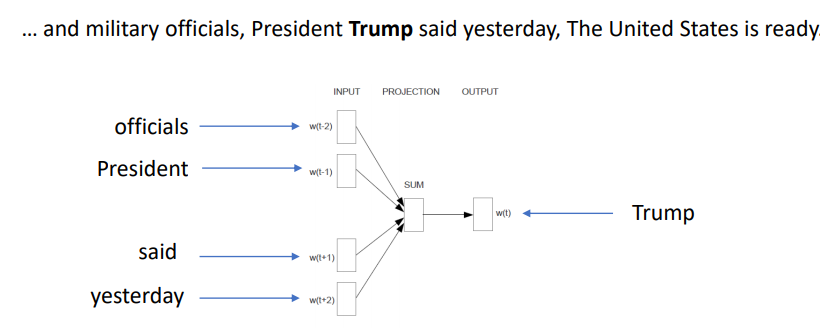
-
위 그림과 같이 해당 문장이 있으면, 앞뒤 단어(officials, president, sai, yesterday)를 input으로 사용하여 중간 글자인 Trump를 학습시키는 것이다. 있는 위에서 언급한 ~이라는 단어가 같은 문맥에서 나온다는 것을 이용한 것이다.
-
좀 더 자세히 살펴보자. Input으로는 우리가 앞서 알아보았던, one-hot vector가 들어간다.(ex, officials=[0,1,...0], President=[0,0,....,1,0]) 그럼 해당 one-hot vector들이 Leanable matrix, 즉 차원을 축소시켜주는 matrix와 곱해져, 새로운 vector를 생성해준다. 그림으로 하면 아래와 같다.
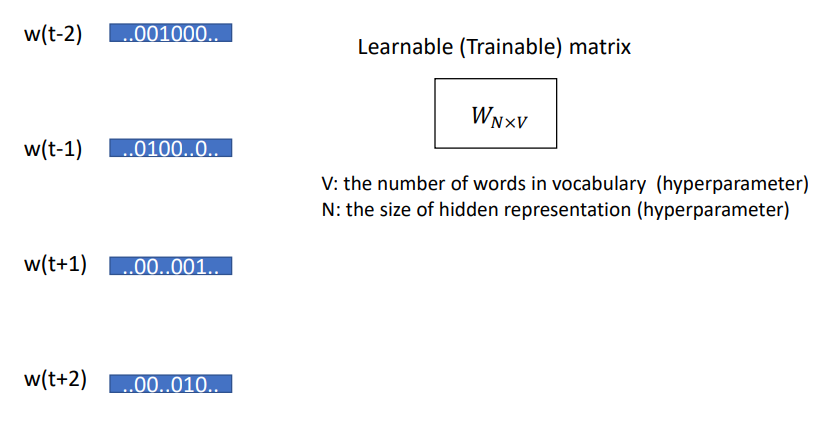
-
w(t-2), w(t-1), w(t+1), w(t+2)는 앞뒤 단어들이고, 해당 one-hot vector를 learnable matrix와 곱해준다. 물론 learnable matrix의 크기는 N(줄이고자하는 차원의크기)X V(Input vector/one-hot vector의 크기이다.
-
이번에는 Learnable matrix의 학습원리를 알아보자.
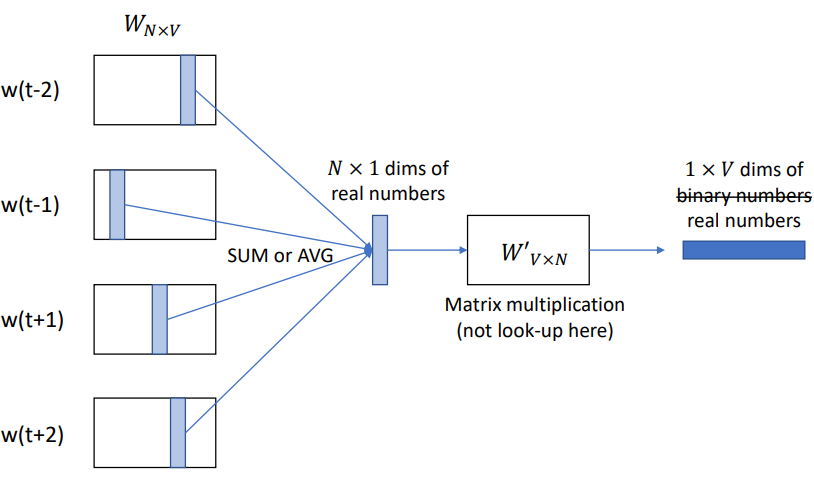
-
위와 같이, 학습하려는 앞,뒤의 단어들을 합하거나 평균낸 값을 이용해 Learnable matrix와 곱해주면 1XV 차원의 vector를 가질 수 있다.
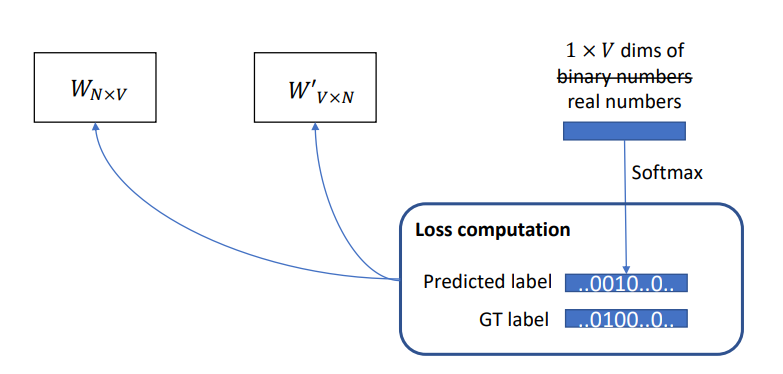
-
1XV 차원의 vector를 softmax를 통해 해당 vector가 어떤 one-hot vector였는지, 예측하게되고, 실제 one-hot vector와의 차이를 이용해 학습하게된다.
Word2Vec(Skip-gram) : Skip gram
- Word2Vec의 다른 방법으로는 Skip-gram이 있다. 해당 방식은 CBOW와 반대로, 한 단어를 input으로 받고, 주변의 단어들을 output으로 사용한다.
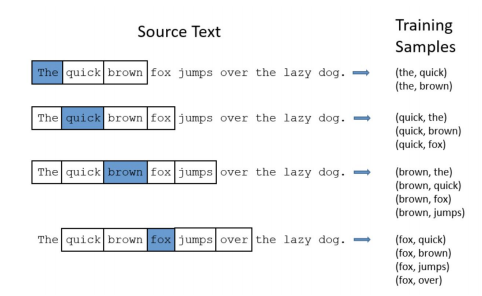
- 그림을 통해 더 쉽게 알 수 있다. 3번째를 보면 brown이라는 단어를 이용해 the를 학습하고, quick을 학습하고, fox를 학습하고, jumps를 학습한다. 학습하는 과정을 자세히 보면 다음과 같다.
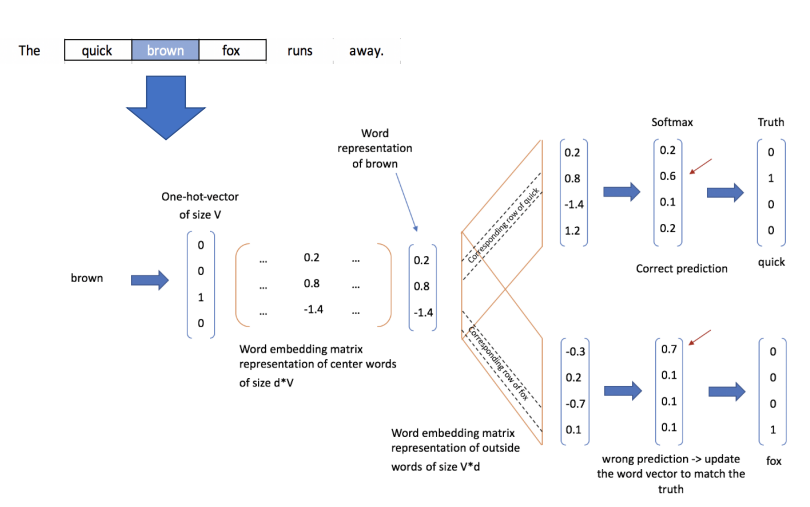
- brown이라는 one-hot vector가 input으로 들어가고, 해당 output의 softmax를 이용해 주변 단어를 학습시킨다.
Difference between CBOW and Skip-gram
- 여기서는 CBOW와 Skip-gram의 장단점을 살펴 볼 것이다.
- 우선 Skip-gram은 한 단어로 부터 여러 단어를 학습해야하기 때문에, 시간이 오래 걸린다. 하지만 이러한 특징 덕분에, 데이터 수가 적을 때 유용한다.
- 반면에 CBOW는 여러 단어가 들어오고 한 단어를 학습하기때문에, Skip-gram보다 빠른학습을 한다. 또한 성능면에서도 약간 더 높은 정확도를 가진다.
Techniques in Word2Vec
- 이미 위에 학습방법을 통해 알 수 있었을 수도 있지만, CBOW와 Skip-gram모두 학습을 위해 softmax를 사용한다. 하지만, Softmax시, 단어의 개수가 너무 많을때는, 아래 loss값을 구할때, normalization factor 계산에 많은 computing power가 소모된다.
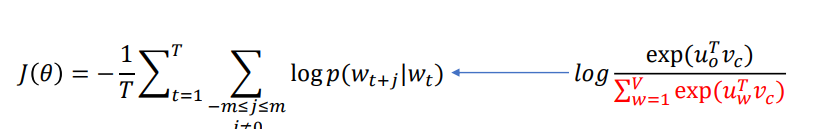
- 따라서, Word2Vec에서는 두가지 technique을 제시한다.
1) Hierarchical Softmax - 단어들을 binary tree로 만들어, 각 node에서 선택할 확률을 높이되록 하는 것이다. 따라서 단어의 수가 V가 라면 내적을 V번 했어야 했지만, 이 binary tree를 사용하면 log2(V)로 줄어든다.
2) Negative Sampling - 학습하고자 하는 단어의 앞뒤에 등장하지 않는 단어들을 5~20개 정도 뽑고, 그 단어들을 학습하고자 하는 단어와 합친 후 softmax를 구해준다. - 위에 두 technique의 목적은 결국 분모에서 모든 단어들을 고려하여 computing power가 높은것을, 더 적은 수의 단어들만 고려하여 낮춰주는 것이다.
Future Embedding
- Word2Vec이후에, 더 좋은 Word Embedding에 대한 연구가 진행되었고, GloVe, FastText, ELMO 등 좋은 기법들이 많이 생겨났다.
