M3T : three-dimensional Medical image classifier using Multi-plane and Multi-slice Transformer
Computer Vision
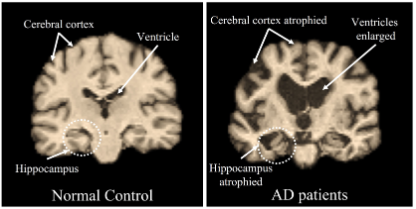
0. Abstract
본 논문은 2D CNN (Convolutional Neural Network), 3D CNN, Transformer를 조합하여, 3D MRI 이미지를 통해 알츠하이머 증상 (Alzheimer Disease, AD)를 분류해내는 모델을 제안한다.
제안된 모델은 이전 3D image 분류기들과 비교한 결과 가장 좋은 성능을 보이면서, 3D로 구성된 medical image를 위한 CNN, Transformer의 조합이 타당하다는 것을 증명한다.
1. Introduction
CNN은 classification, detection, segmentation, 등 다양한 컴퓨터 비전 task에서 중요한 역할을 수행했다. 나아가 CNN기반 모델은 X-ray, MRI, CT, 초음파, 등의 2D부터 3D까지 다양한 차원으로 구성된 medical image에 대해서도 적용되어 왔다.
이 수많은 modality들 중에서, 특히 3D medical image를 분석하기 위해 2D 및 3D CNN이 사용되었다. 하지만 각 네트워크의 장단점은 명확히 구분된다.
2D CNN은 대규모의 2D 자연 이미지로 학습된 사전 학습 모델을 사용한다는 이점이 있지만, 3D 이미지의 문맥을 이해하기는 힘들다.
3D CNN은 이와는 다르게 3D 이미지의 문맥을 잘 이해할 수 있다. 하지만, 많은 수의 파라미터와 방대한 양의 계산을 요구하므로 네트워크를 깊게 쌓는 것은 불가능하다.
최근에는 Transformer 네트워크가 제안되면서 자연어처리와 컴퓨터비전 분야 모두에 널리 사용되고 있다.
CNN은 수용 영역 (receptive field)의 한계로 인해 데이터의 global한 부분만 보는데, Transformer는 넓은 수용 영역을 가지고 있어서 네트워크가 깊어질 수록 수용 영역 또한 넓어지게 된다. 하지만 학습 데이터셋이 충분하지 않다면 CNN보다 정확도가 떨어진다는 단점이 있다.
3D medical image의 경우 다른 domain의 데이터셋에 비해 많이 부족하므로 이러한 단점을 고려하지 않을 수가 없다.
이러한 두 네트워크의 장점을 모두 가져갈 수 있도록 조합된 hybrid network가 많이 연구되었지만, 모두 2D 이미지를 위한 2D CNN과 Transformer를 조합하였다.
본 논문은 3D 이미지를 위해 2D CNN, 3D CNN, Transformer 모두를 조합한 네트워크를 소개한다.
왜 이 3개의 네트워크가 AD를 분류하는데 필요할까?
- AD 환자에게 생기는 대뇌피질 (cerebral cortex) 위축은 뇌에 전반적으로 분포하므로, 수용 영역이 넓은 Transformer가 필요하다.
- 뇌실 (ventricle) 영역과 해마 (hippocampus) 영역의 수축은 뇌의 local한 영역에서 발생하므로 CNN이 필요하다.
- MRI 이미지는 3차원으로 구성되어 있고, slice 단위가 아닌 volume 전체를 사용하기 위해 3D CNN이 필요하다.
2. Methods
모델의 전반적인 구조는 아래와 같다.
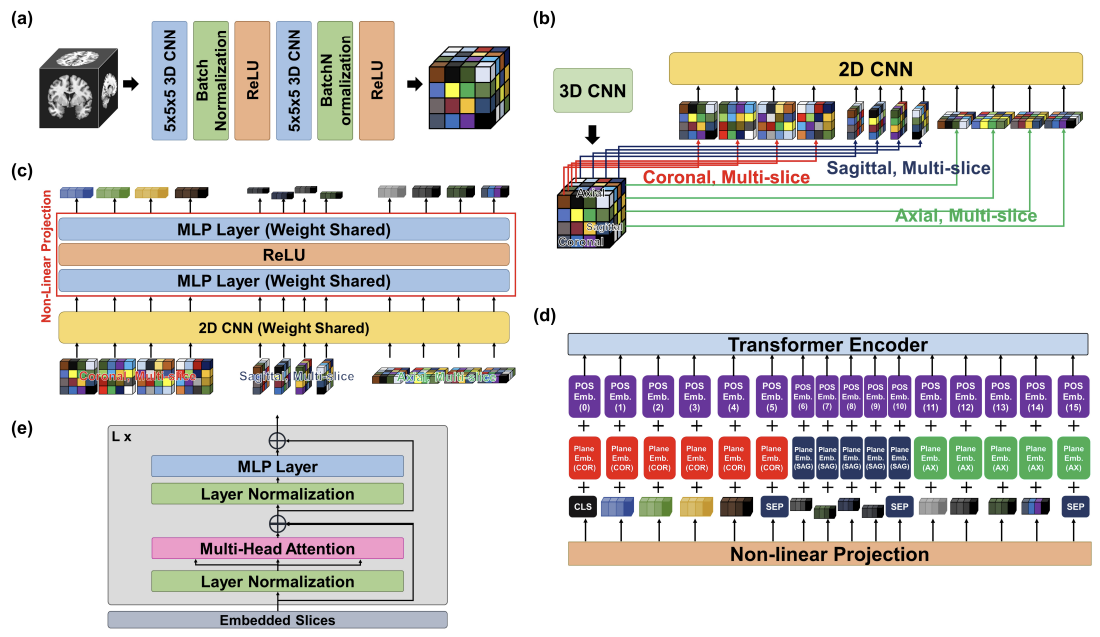
2.1. 3D Convolutional Neural Network Block
우선 입력으로 이미지의 depth , width , height 가 동일한 MRI 이미지를 받는다. 그 후 feature를 얻기 위해 2개의 3D CNN layer와 Batch Normalization, ReLU function으로 구성된 layer를 통과한다.
2.2. Extraction of Multi-plane, Multi-slice Images
보통 CT나 MRI 촬영을 진행할 때, 3개의 view에 대해 필요로 하는 view로 촬영을 진행한다. View의 종류로는 axial, sagittal, coronal view가 있다.
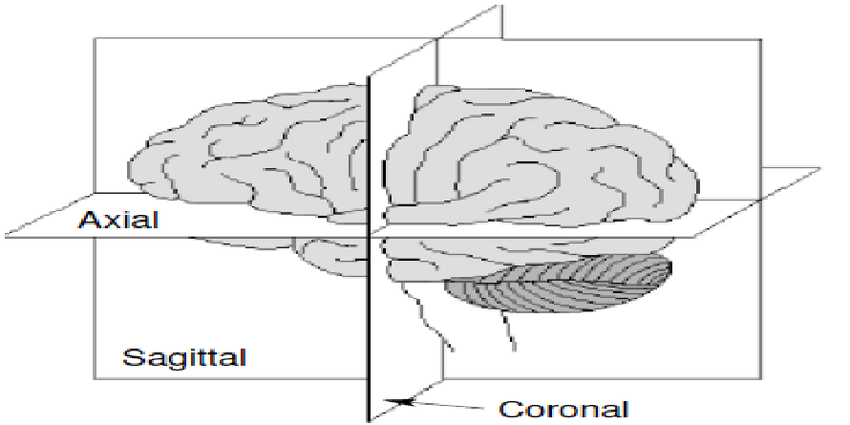
3D CNN block을 통해 얻은 3D feature map에 대해 3개의 view에 대한 feature extractor를 통해 feature를 추출한다.
2.3. 2D Convolutional Neural Network Block
추출된 feature들은 weight를 공유하는 2D CNN layer를 통과한 후, 두 개의 MLP layer와 ReLU function으로 구성된 layer를 통과해서 차원의 벡터로 투영된다. 본 논문은 를 256으로 설정한다. 또한 2D CNN block으로 ImageNet으로 pre-train이 되어있는 ResNet50을 사용한다고 한다.
2.4. Position and Plane Embedding Block
Non-linear projection layer를 통해 position token과 plane embedding token을 각 image token에 더해준다. 또한 classfication token인 와, BERT의 sep token과 비슷한 도 추가한다.
2.4. Transformer Block
위의 embedding 과정을 거친 image token들은 Multi-head Self Attention (MSA), Layer Normalization, MLP block으로 구성된 개의 Transformer layer를 통과한다. 본 논문은 를 8로 설정한다. 각 layer를 통과할 때마다 image token의 차원인 는 유지된다. 마지막으로, MLP head인 를 기반으로 알츠하이머 증상 여부를 분류한다.
3. Experiments
3.1. Implementation details
Preprocessing
다양한 기관에서 받은 MRI 이미지들을 정규화 및 표준화하기 위해, 동일한 전처리 작업을 모든 데이터셋에 적용한다.
- N4 algorithm : Image intensities의 불균일성 제거
- Skull stripping algorithm : Non-brain tissues 제거
- Resize (same voxel spacing & matrix size)
- Normalize (Image intensities to zero-mean unit-variance)
3.2. Comparison study results
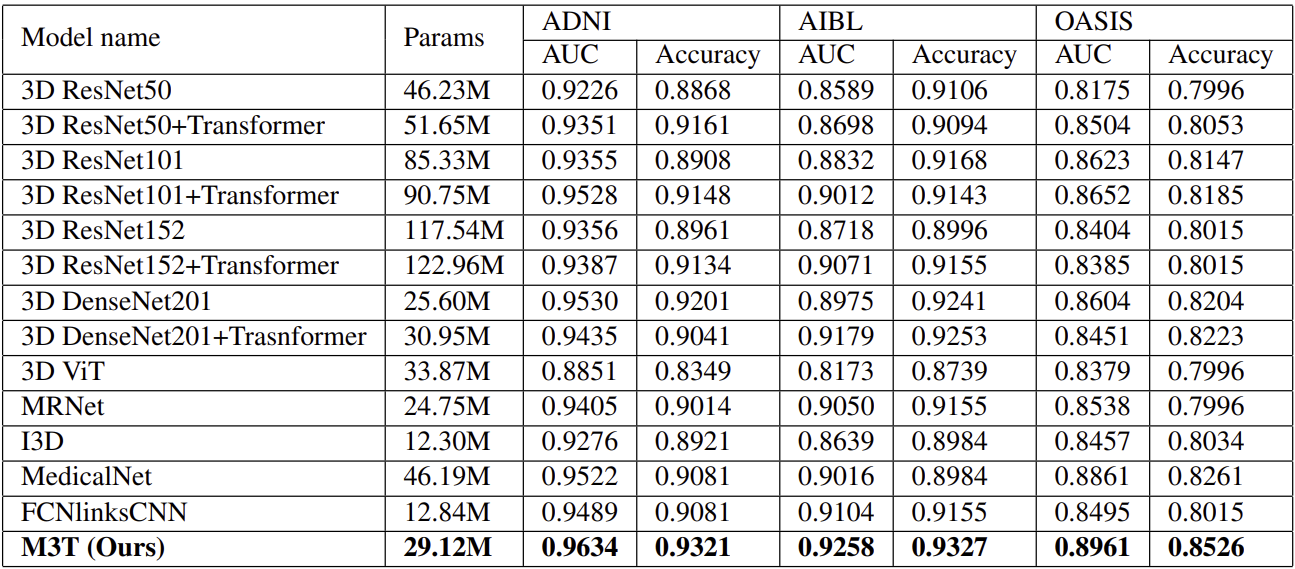
다른 연구들과 비교한 결과, 본 논문이 제안한 방법이 가장 높은 정확도를 보인다.
또한, CNN과 Transformer를 조합한 hybrid network가 3D CNN network보다 더 좋은 성능을 보인다.
Transformer 만을 사용한 network는 적은 수의 데이터에 대해 낮은 정확도를 보인다는 것 또한 알 수 있다.
3.3. Ablation study results

제안된 모델에서 각각 3D CNN, 2D CNN, Transformer block을 제거하고 실험한 결과, 모든 block을 사용한 network가 제일 높은 정확도를 보인다.
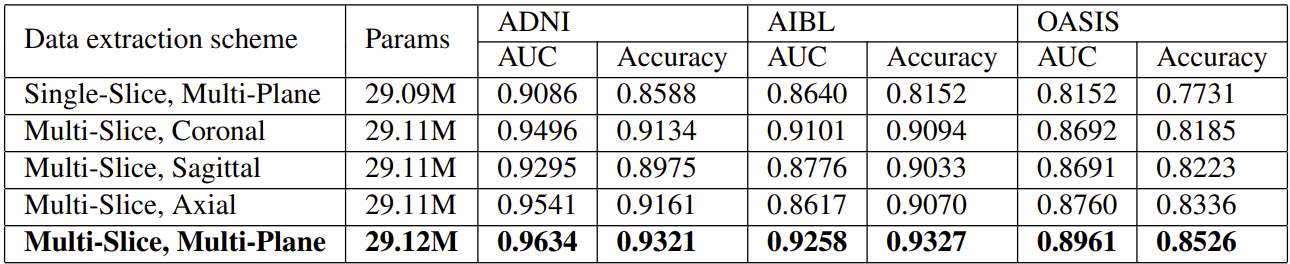
3D CNN을 통해 얻은 feature map에 대해 coronal / sagittal / axial view 에 대한 feature를 추출하는데, 모든 view에 대한 feature를 사용하는 것이 가장 높은 정확도를 보인다.
