1. Introduction
방대한 언어 데이터를 활용한 NLP foundation model의 등장으로, 다양한 데이터 및 task에 활용되고 있다.
본 논문은 segmentation task에서의 foundation model을 만들어, 새로운 데이터 분포에서도 프롬프트를 이용하여 segmentation을 잘 해내는 것을 목표로 한다.
Task
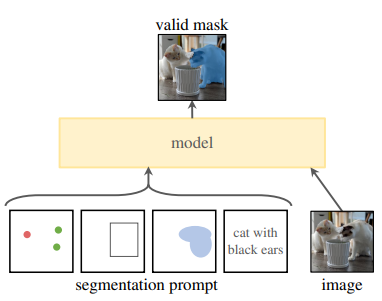
SAM의 task는 어떠한 프롬프트가 주어져도 유효한 segmentation mask를 반환하는 것이다.
Model
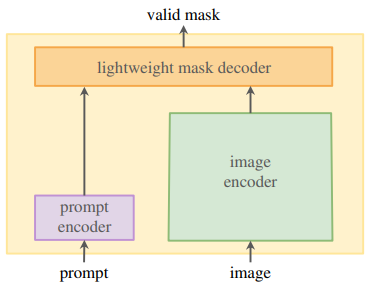
SAM은 다음의 제약조건을 만족하는 모델을 개발하는 것이 목표이다.
- 다양한 프롬프트 지원
- 실시간 segmentation mask 계산
- Ambiguity-aware
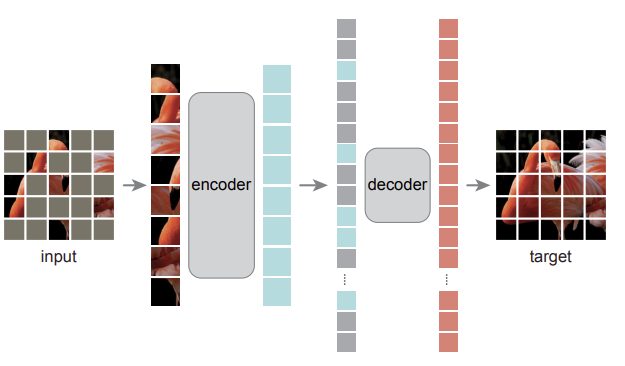
본 논문은 다음 제약조건들을 만족하는 간단한 모델을 개발했다. 모델의 구조는 위의 그림과 같다. Image encoder를 통해 image embedding을 계산하고, prompt encoder를 통해 prompt embedding을 계산하고, mask decoder에 이 두 embedding 값을 조합하여 segmentation mask를 뱉는 것이다.
Image encoder의 경우 프롬프트가 바뀔 때마다 embedding을 하는 것이 아닌, 한 번 embedding해둔 이미지를 계속 활용하는 것이다. 이렇게 연산과정을 줄여 계산시간을 줄일 수 있게 된다.
또한, ambiguity-aware하기 위해 프롬프트가 주어졌을 때 모델은 여러 개의 mask를 예측하도록 한다.
Data engine
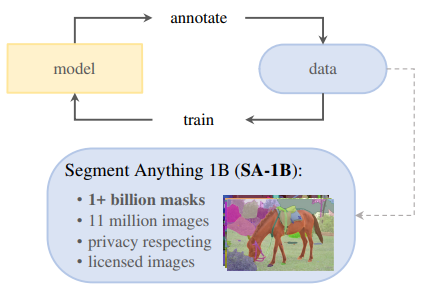
모델을 훈련하기 위해서는 대규모의 데이터셋이 필요하다. 그래야 새로운 데이터 분포에서도 strong generalization을 유지할 수 있다. 하지만 온라인에서는 그렇게 많은 segmentation 데이터셋을 찾을 수 없다. 이를 위해 본 논문은 data engine을 구축한다.
본 논문의 data engine은 assisted-manual, semi-manual, fully automatic 세 단계를 통해 데이터를 구축해나간다.
3. Segment Anything Model
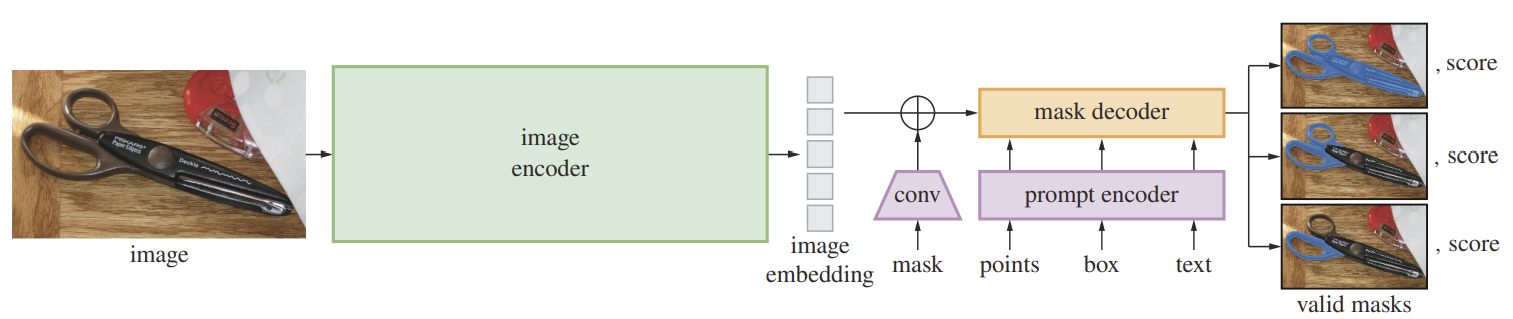
3.1. Image encoder
입력 이미지는 encoder를 통해 차원의 vector로 mapping한다. Encoder는 'Masked Autoencoders Are Scalable Vision Learners'에서 소개한 MAE pre-trained ViT를 사용한다.
Encoder를 통해 출력된 image embedding은 이 된다.
3.2. Prompt encoder
Prompt의 종류는 sparse, dense가 있고, sparse에는 points, boxes, texts가, dense에는 masks가 있다. Prompt encoder를 통해 모든 입력 prompt는 256차원으로 mapping된다.
- Point : 지정된 point의 좌표에 positional encoding을 한 결과와 points의 위치가 피사체 / 뒷배경 중 어디에 속하는 지 나타내는 학습된 embeddings가 합쳐져 256차원으로 mapping
- Box : 좌상단, 우하단 좌표에 positional encoding을 한 결과와 좌상단, 우하단을 나타내는 학습된 embeddings가 합쳐져 256차원으로 mapping
- Mask : 입력 mask를 배의 해상도로 바꿔 { convolution}, { convolution} 연산을 수행하여 총 4배의 추가 downsampling을 진해한다. 그 후 { convolution} 연산을 통해 최종 256차원으로 mapping
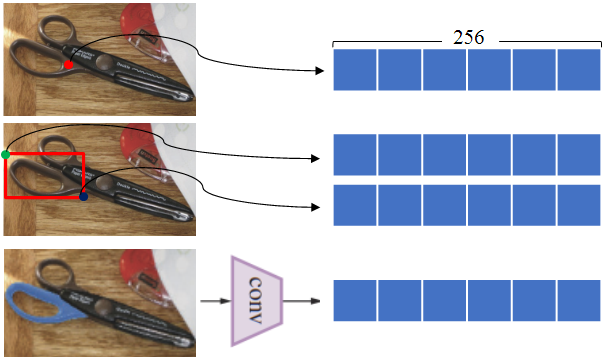
- Text : CLIP(Learning Transferable Visual Models from Natural Language Supervision)에서 소개된 text encoder를 통해 256차원으로 mapping
3.3. Mask decoder
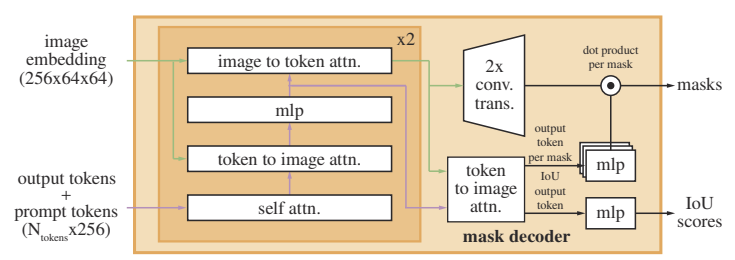
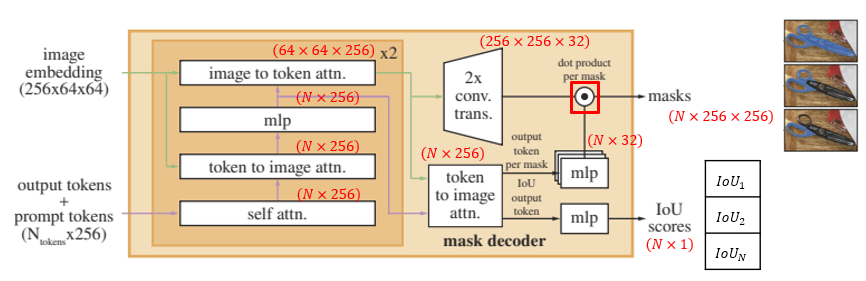
Image embeddings와 token embeddings를 통해 segmentation map을 출력하게 되는데, 과정은 다음과 같다. 위 그림에서 output tokens는 target object에 대해 출력할 mask의 수, prompt tokens는 prompt encoder를 통해 embedding된 prompt이다. 이 둘을 합쳐서 'tokens'라 한다.
Decoder에서는 two-way attention을 통해 token/image embedding을 image/token embedding과 cross-attention을 수행하여 각각의 embedding 값을 업데이트한다. 각 layer를 통과하면서 출력되는 shape을 이해하기 위해 attention의 수식에 대해 간단한 복습을 하고 넘어가자.
★ Attention =
여기서 는 query, 는 key, 는 value이다. 만약 의 image embedding를 의 tokens과 cross-attention을 수행한다면 image embedding이 query, tokens가 key/value가 된다.
즉, attention은 상대와의 관계를 바라보기 위한 것이므로 shape에는 변함이 없다는 것을 알 수 있다.
-
Token embeddings self-attention
-
Token embeddings와 image embeddings 간의 cross-attention
-Image 정보로 token embeddings 업데이트 -
point-wise MLP로 token 업데이트
-
Image embeddings와 token embeddings 간의 cross-attention
-Prompt 정보로 image embeddings 업데이트
이 과정을 총 2회 수행한다. 그 후
-
Image embeddings에 up-convolution 연산을 2번(channel 수는 각각 64 / 32) 통과시켜 해상도는 올리고 채널은 축소
-
Token embeddings와 image embeddings 간의 cross-attention 연산을 한 번 더 수행 한 후 3-layer MLP에 통과시켜 up-convolution된 image embeddings의 채널 수와 맞춤
-
Up-convolution된 image embeddings와 token embeddings 간의 dot product를 통해 최종 mask 출력
-
업데이트된 token embeddings를 MLP layer에 통과시켜 mask 별 예측 IoU score 출력
여기서 IoU score가 가장 높은 mask를 최종 output mask로 선정한다.
4. Segment Anything Data Engine
4.1. Assisted-manual stage
첫 번째 단계에서는, 전문가들이 이미지 각 픽셀을 직접 클릭하여 피사체와 배경을 구분한다.
여기서 본인이 알거나 설명할 수 있는 객체만 라벨링 하되, 해당 객체의 이름이나 설명은 모으지 않는다.
- 공개된 데이터셋을 이용하여 SAM 모델 초기 훈련
- 새롭게 annotation된 mask를 이용하여 재훈련
- 모델 구조 진화 (image encoder ViT-B to ViT-H)
첫 번째 단계를 통해 이미지 당 평균 마스크 수는 20에서 44로 증가한다.
4.2. Semi-automatic stage
두 번째 단계에서의 목표는 모델이 모든 것을 segment할 수 있도록 mask의 다양성을 증가하는데에 있다.
이를 위해 모델이 먼저 다양한 mask를 뽑아내고 사람이 후처리를 한다.
- 모델이 신뢰도 높은 mask 자동으로 감지
- 감지된 마스크에 전문가가 추가 라벨링
두 번째 단계를 통해 이미지 당 평균 마스크 수는 44에서 72로 증가한다.
4.3. Fully automatic stage
두 개의 단계를 통해 모델을 향상시키기 충분한 데이터셋을 수집했고, 충분히 ambiguity-aware한 모델을 만들었다.
마지막 단계에서는 이 모델을 통해 다음과 같은 최종 작업을 진행한다.
- Point가 가리키는 객체의 subpart, part, whole part를 반환
- IoU (Intersection over Union) 값을 계산하여 신뢰도가 가장 높은 mask 선택
- NMS (Non Maximum Suppression)을 통해 중복 mask 제거

정말 흥미롭네요