1. Introduction
SAM (Segment Anything Model)과 같이 특정 task에 맞춰진 모델에서 광범위한 task를 수행할 수 있는 foundation 모델 개발로 패러다임이 전환됐다. SAM은 이미지 분할 task에서 놀라운 결과를 보였지만, 의료 도메인은 자연 도메인과 격차가 있다보니 의료 도메인에 적용 시 아쉬운 성능을 보였다. 이러한 한계를 극복하기 위해 MedSAM, SAM-Med와 같이 SAM을 의료 영상으로 fine-tuning한 연구들이 나왔지만, 여전히 한계가 존재한다.
- 위 모델들은 2D 영상 분할을 위해 디자인된 아키텍쳐다.
- 3D 영상 분할을 위해 SAM을 확장했지만, 임상 워크플로우에서 요구되는 3D 영상 분할에는 여전히 부족하다.
- 지금까지 나온 모델들에 대한 대규모 검증이 부족하다.
본 연구는 이러한 한계점을 극복하기 위해 다양한 영상 모달리티, 병변, 장기들의 정보를 담고 있는 데이터셋을 구축하고, 3D 영상 분할 foundation 모델인 MedSAM2를 제안한다.
2. Methods
MedSAM2는 SAM2 모델을 그대로 가지고 와서 의료 도메인에 fine-tuning한 형태라고 볼 수 있다. 모델의 전반적인 구조는 이전에 정리해둔 SAM2 내용을 참고하고 (https://velog.io/@jjun_8177/SAM2-Segment-Anything-in-Images-and-Videos-%EC%A7%84%ED%96%89-%EC%A4%91), SAM2에 어떻게 의료 영상을 입력하여 학습하는지에 대해 더 살펴보겠다.
2.1. Image pre-processing
영상 전처리는 nnU-Net, Segment anything in medical images 논문에서 소개한 내용을 따른다.
- 이미지 강도 조정
- CT : Hounsfield unit ( brain, abdomen, bone, lung, mediastinum )
- MRI / PET : cut-off with lower-bound and upper-bound in 0.5% and 99.5%
- 이미지 normalization 및 resampling
- 'npy' 파일로 저장
- CT, MRI, PET 영상 모두 NifTi 파일로 처리 후 numpy array로 저장
- Data loading을 빠르게 할 수 있고, 서로 다른 데이터 포맷을 통일할 수 있다
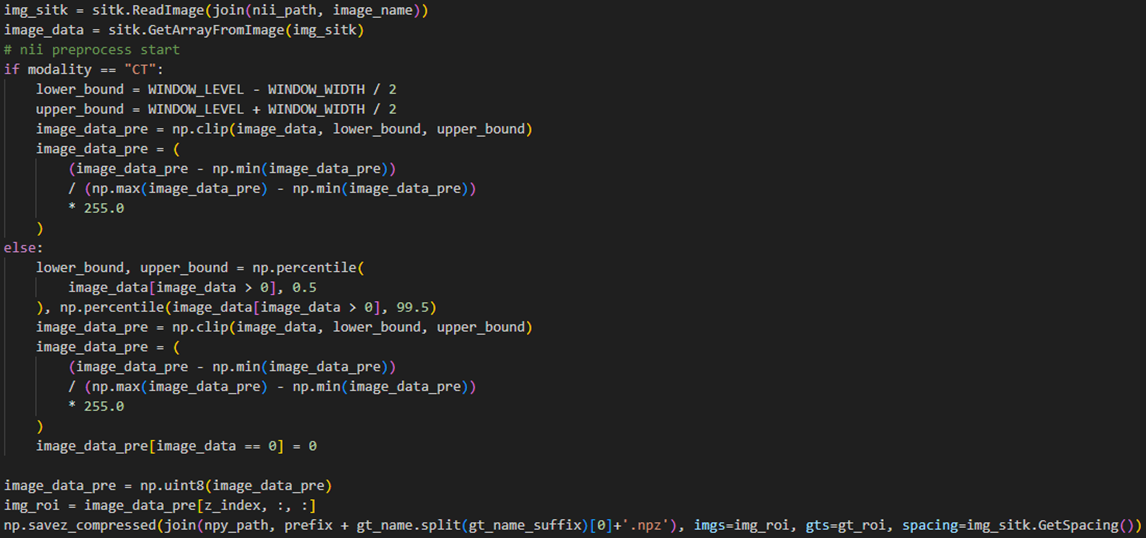
전처리 코드는 다음과 같다. 영상 모달리티에 따라 이미지 강도 조정 및 min-max normalization을 적용하는 것을 볼 수 있다.
전처리된 영상, 정답 마스크, 영상의 기하학적 정보를 npz 형태로 최종 저장하여 데이터셋으로 구축된다.
2.2. Network architecture
네트워크 구조는 이전의 SAM2와 동일하다. CT, MRI, PET는 모두 3차원 영상인데, 이 중 axial view 기준 하나의 slice를 image encoder에 태워서 frame embedding을 얻고, 프롬프트인 bounding box를 prompt encoder에 태워 prompt embedding을 얻어 mask decoder에 이 두 embeddings 간의 attention 연산을 수행하여 예측 마스크를 얻게 된다. 현재 slice를 기준으로 이전 slice 및 이후 slice도 같은 방법을 수행하지만, 여기서 현재 slice를 통해 얻은 예측 마스크로 memory attention을 수행하여 conditioned frame embedding을 얻은 후 수행하게 된다.
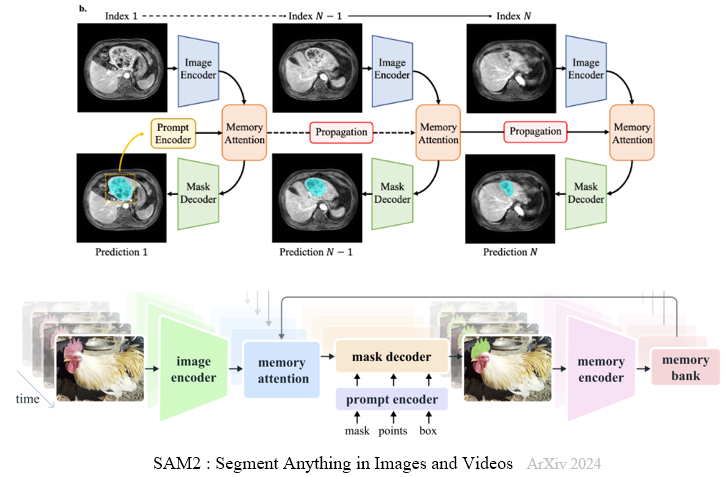
첫 번째 figure는 MedSAM2에서, 두 번째 figure는 SAM2에서 가져온 figure이다. 네트워크 구조가 동일하다는 것을 보이기 위해 이렇게 준비해봤다.
Fine-tuning은 네트워크의 모든 부분을 수행하게 된다. 네트워크의 모든 부분이 아닌 일부분, 예를 들어 prompt encoder와 mask decoder만 fine-tuning을 하면 더 좋은 결과를 보일 수도 있지 않을까 의문이 들 수 있지만, Segment Anything in Microscopy라는 논문에서 네트워크의 모든 부분을 fine-tuning 했을 때 제일 좋은 성능을 보인다고 입증하여 MedSAM2도 위와 같이 진행한다.
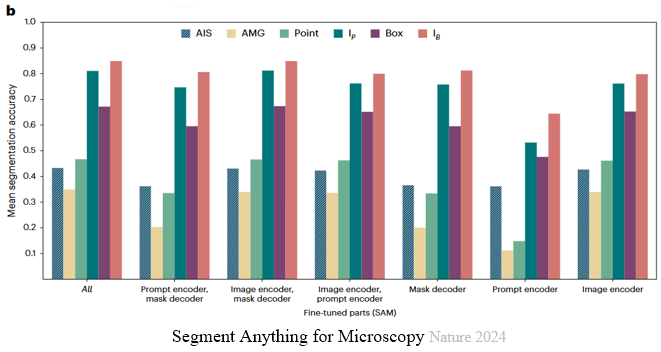
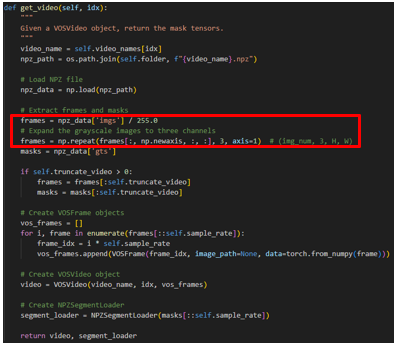
Image encoder가 받는 입력 이미지의 크기가 이전의 SAM2와는 차이가 있다. SAM2는 인 이미지를 입력받지만, CT, MRI, PET 영상의 각 slice는 여서, MedSAM2는 인 이미지를 입력받도록 수정됐다.
의료 영상은 흑백 이미지이다 보니 1-channel이고, 자연 영상은 컬러 이미지이다 보니 3-channel로 구성된다. MedSAM2는 SAM2의 image encoder를 그대로 사용하므로 해당 영상을 그대로 image encoder에 태우면 사이즈가 맞지 않으므로 에러가 날 것이다. 그래서 저자는 흑백 이미지를 복사하여 나머지 두 개의 channel에 붙임으로서 3-channel로 구성하는 방식을 사용한다.
Memory attention 모듈은 SAM2와 마찬가지로 4개의 transformer 블록으로 구성되어 있고,
bounding box를 프롬프트로 받으므로 SAM 및 SAM2에서와 마찬가지로 bbox의 좌상단, 우하단 좌표를 임베딩하여 mask decoder에 입력하게 된다.
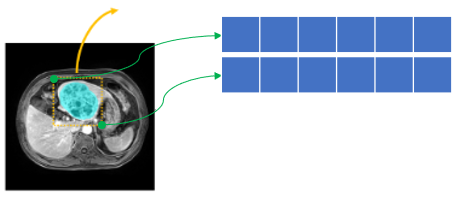
최종적으로 이미지 embedding과 프롬프트 embedding을 mask decoder에 태워 예측 마스크를 획득한다.
2.3. Training protocol
모델은 자연 영상으로 pre-train된 SAM2.1-Tiny 모델을 가져와서 fine-tuning한다. Fine-tuning 된 모델은 이미 feature를 뽑는데 특화되어 있을 것이므로 이렇게 진행한다. Fine-tuning 전략은 image encoder는 learning rate를 낮춰서 feature를 뽑는 능력을 유지할 수 있도록 하고, 나머지 모듈은 learning rate를 높여서 의료 도메인에 특화될 수 있도록 한다.
Batch size는 SAM2와 마찬가지로 GPU 당 8로 설정하여, SAM2에서는 동영상에서 8 프레임씩 뽑아 입력했다면 MedSAM2는 8개의 slice를 뽑아 입력하게 된다.
Loss는 focal loss와 dice loss를 선형 조합하여 사용하고, 비율은 20:1로 설정하여 focal loss에 조금 더 가중치를 준다.
3. Results
성능 평가는 다양한 모달리티, 병변, 장기들이 포함된 40 개의 segmentation task에서 진행되었다.
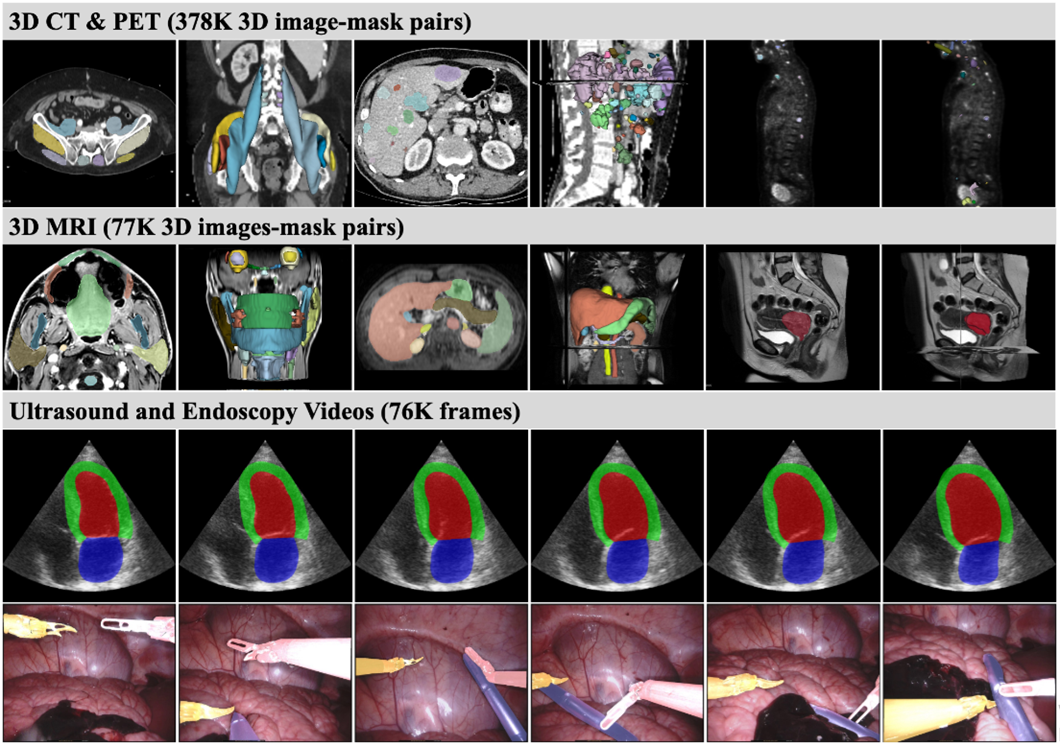
성능 비교는 SAM2.1의 tiny / small / base / large 모델, EfficientMedSAM-1 모델과 비교했다. EfficientMedSAM-1은 MedSAM2와 마찬가지로 bounding box를 입력 프롬프트로 받고, bbox segmentation foundation 모델에서 SOTA를 기록한 연구이므로 비교군으로 골랐다고 한다.
3D 이미지 성능 평가 결과는 다음과 같다.
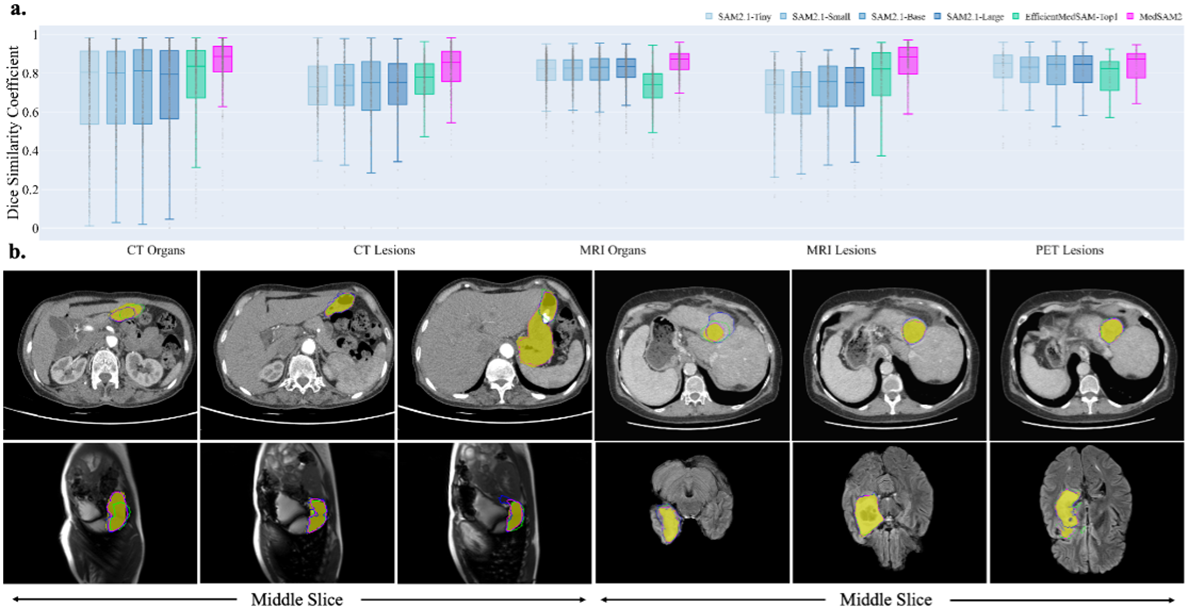
결과는 위의 표를 보면 SAM2.1의 모든 모델에서 DSC 값에 큰 차이가 없다는 것을 볼 수 있고, EfficientMedSAM-1은 특정 task에서는 SAM2.1보다 좋은 결과를 보인다. 전반적으로 MedSAM2가 다른 비교군들보다 좋은 결과를 보인다.
다음은 비디오 성능 평가 결과이다. 두 번째 figure에서 첫 번째 영상은 초음파, 두 번째 영상은 내시경 영상이다.
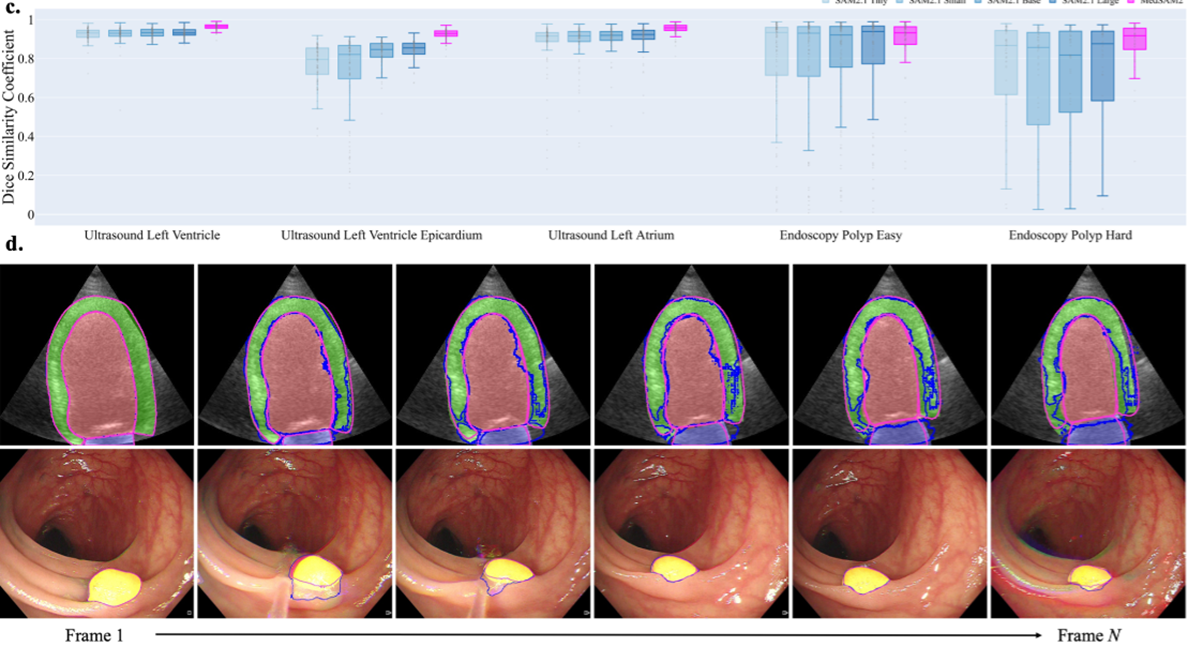
형태 변화가 까다로운 영상에서 SAM2.1 모델들은 점수가 크게 떨어지고 오차범위가 넓어지는 반면에 MedSAM2는 분할 난이도가 높은 비디오에서도 안정적인 정확도와 분포를 보인다.
- MedSAM2 enables efficient 3D lesion annotation for large 3D CT and MRI datasets
병변의 이질성, noise 및 artifact는 라벨링 작업 시간이 많이 걸리고 노동 집약적인 작업으로 만든다. MedSAM2는 human-in-the-loop 파이프라인을 구축하여 라벨링 작업 시간을 압도적으로 줄이고 대용량 의료 분할 데이터셋을 구축한다.
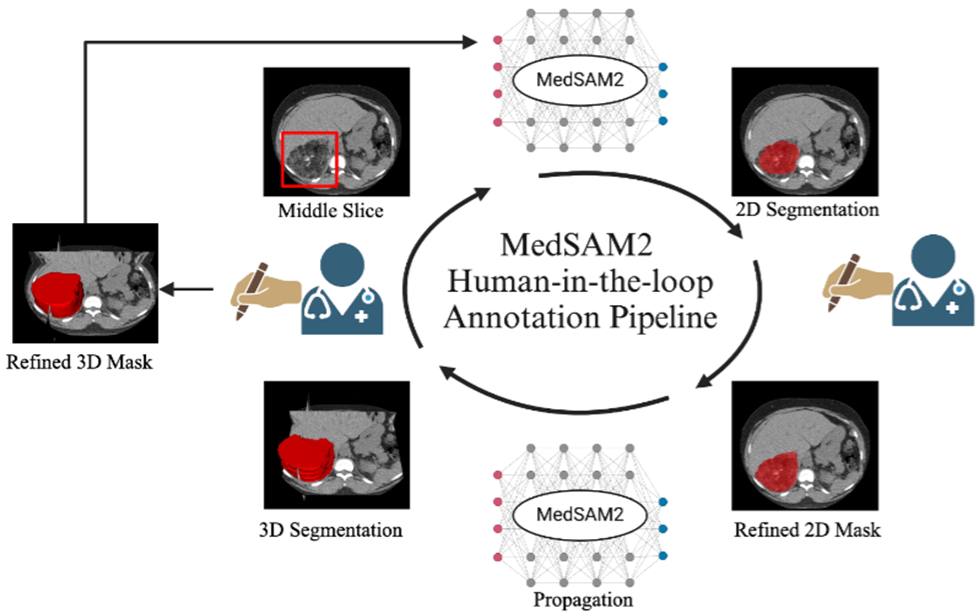
순서는 다음과 같다.
- 어노테이터가 영상의 가운데 slice 라벨링하고 싶은 영역에 bounding box를 그린다.
- SAM2.1 모델이 초기 마스크를 생성한다.
- 어노테이터가 마스크를 수정한다.
- 수정된 마스크를 기반으로 MedSAM2가 모든 slice에 예측 마스크를 생성한다.
- 어노테이터가 최종적으로 모든 slice의 마스크를 수정하여 최종 정답 마스크를 생성한다.
- 충분한 데이터가 생성되면 SAM2.1 모델 fine-tuning을 실시한다.
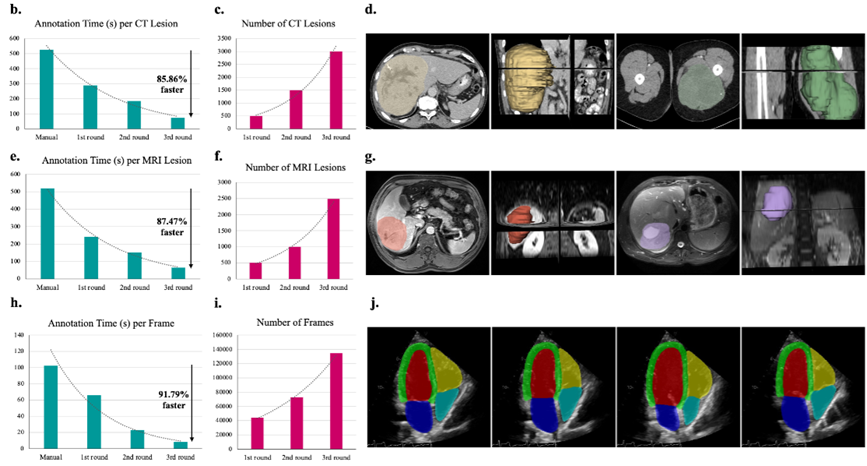
Human-in-the-loop 방식을 통해 각 round가 지날 때마다 라벨링 시간은 단축되고 라벨링하는 CT의 수는 증가하게 되면서 효율적으로 대용량의 데이터셋을 생성하게 된다.
4. Discussion
좋은 성능을 보였음에도 저자는 몇 개의 한계점을 이야기한다. 첫 번째로는 프롬프트 제한이다. 현재 MedSAM2는 bounding box를 입력 프롬프트로 받는데, 혈관과 같이 얇고 긴 장기의 경우 적합하지 않은 프롬프트다. 두 번째로는 고정된 메모리 디자인이다. SAM2와 마찬가지로 8개의 slice를 메모리 뱅크에 저장하는데, 내시경 영상 같은 경우에는 카메라가 빠르고 연속적이게 움직이므로 추적에 실패할 가능성이 올라간다.
