1. Introduction
Segment Anything Model (SAM)은 이미지에 대해 프롬프트를 기반으로 segmentation을 할 수 있는 foundation model이다.

하지만 이미지는 현실 세계의 정적인 snapshot일 뿐이다. AR/VR, 로보틱스, 자율주행, 비디오 편집, 등의 중요한 어플리케이션은 이미지 레벨을 넘어 비디오 레벨에 대한 분할을 요구한다.
이 문제를 해결하기 위해 이미지와 동영상 모두에서 영상 분할이 가능한 universal segmentation system이 필요하다.
SAM2는 이러한 이미지 분할 task를 비디오 도메인에서 가능하도록 한 모델을 제안한다. 모델의 입력으로는 비디오의 아무 프레임에 대해 프롬프트를 입력하고, 출력으로 하나의 이미지, 혹은 비디오의 모든 프레임에 대한 segmentation mask를 뱉는다.
이미지에서 동영상 level로 가면서 많은 도전과제가 생긴다. 우선, 동영상 내에서 분할해야 하는 객체의 모션이 계속 바뀌고, 형태가 바뀌고, 어떤 프레임에서는 안 보일 수도 있고, 조명의 변화로 인해 픽셀 값에도 큰 변화가 생길 수도 있다. 또한, 이미지가 한 개의 프레임으로 된 동영상이라면, 동영상은 이미지에 비해 처리해야 할 프레임의 갯수가 훨씬 많아지게 된다.
2.Task : promptable visual segmentation (PVS)
PVS task는 비디오의 어떤 프레임에 대해서도 모델에 프롬프트를 입력하여 영상을 분할 할 수 있도록 해준다.
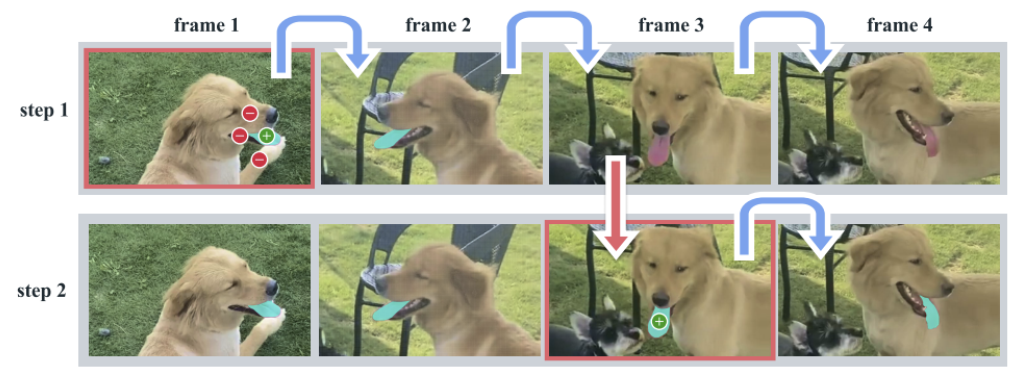
특정 프레임에 프롬프트를 줬을 때, 모델은 바로 해당 프레임에 유효한 segmentation mask를 출력한다. 이 출력된 prompt를 비디오 전체에 프롬프트로 줘서 모든 프레임에 대해 segmentation mask를 출력하게 되고, 만약 어떤 프레임에서 분할해야 할 객체를 놓친다면 여기서 우리는 다시 프롬프트를 줘서 모든 프레임에 대해 객체를 분할 할 수 있게 된다.
3. Model
3.1. Model architecture overview
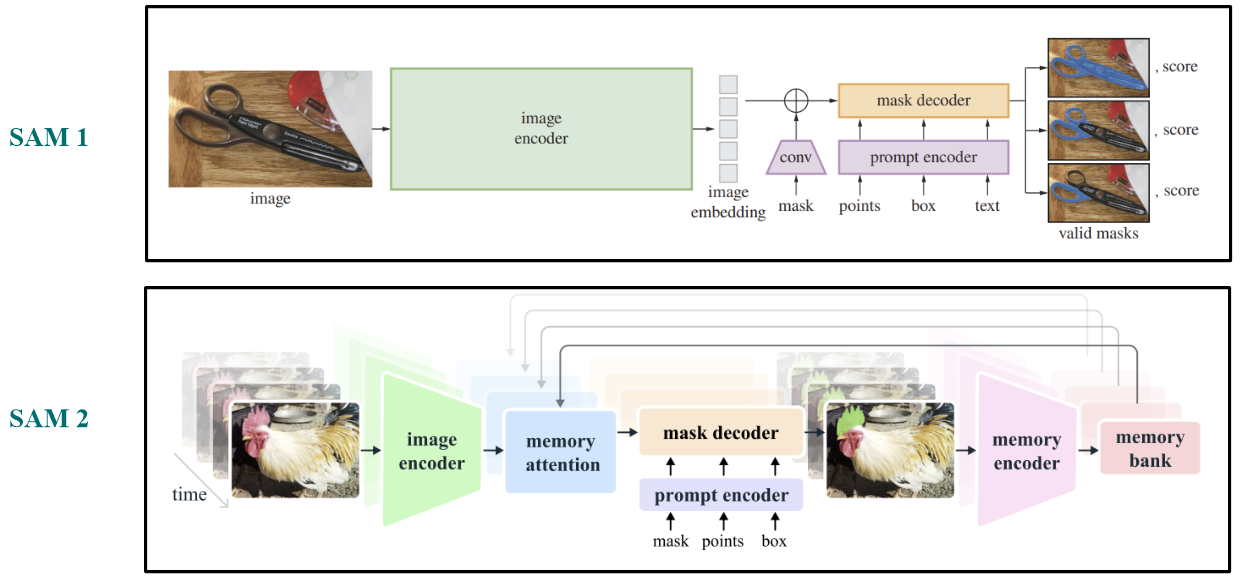
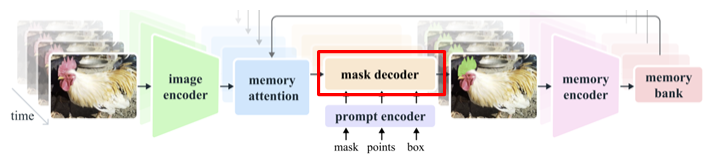
모델의 전반적인 그림이다. 기존의 SAM1 모델과의 차이가 있다면 memory 부분이 생긴 것이다.
각 파트 별로 자세히 들어가보자.
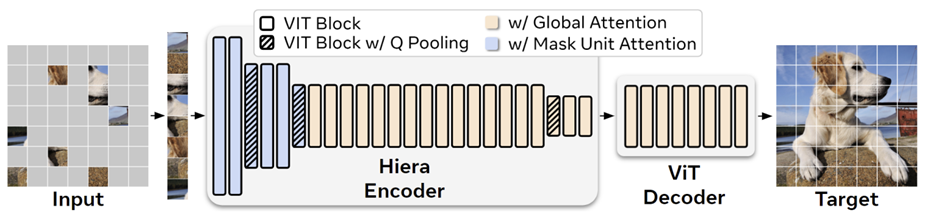
3.2. Image encoder
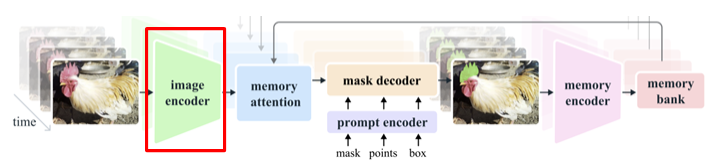
SAM2는 이미지 encoder로 MAE task를 통해 pre-train된 Hiera encoder를 사용한다.
MAE는 Masked AutoEncoder로, 이미지 내 일부 패치를 masking한 후 encoder와 decoder를 통과시켜 이미지를 복원하는 task이다.
Hiera는 ICML 2023에 소개된 논문으로, SAM1에서는 MAE pre-trained ViT 모델을 사용했다면, Hiera는 기존의 ViT보다 계층적인 구조로 encoder를 만들어서 고차원의 정보와 저차원의 정보를 모두 반영하여 좀 더 이미지의 feature를 더 잘 반영할 수 있도록 제안된 모델이다.
3.3. Memory attention
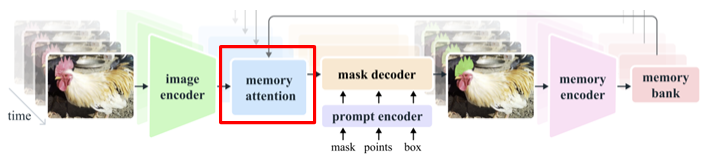
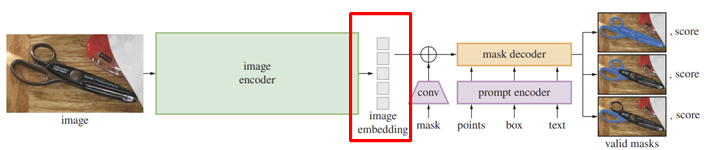
SAM1에서는 이미지 encoder를 통과해서 나온 이미지 embedding을 바로 mask decoder에 입력으로 줬다.
SAM2에서는 encoder를 통과한 이미지 embedding을 unconditioned embedding이라고 한다. 이미지 레벨에서는 해당 이미지에 대해서만 잘 분할하면 됐지만, 동영상에서는 모든 프레임들끼리 정보를 공유하는 것이 분할 작업을 더 잘 수행할 것이라 판단하여 이전 프레임 정보, 예측 결과 등의 정보를 이 embedding에 반영하여 conditined embedding을 생성한다.
그러기 위해 나중에 소개할 memory bank 정보와 이미지 embedding 간의 cross-attention 연산을 수행한다. 이 연산을 memory attention 블록에서 진행하고, memory attention을 통해 얻은 frame embedding을 mask decoder의 입력으로 넣어주게 된다.
3.4. Prompt encoder
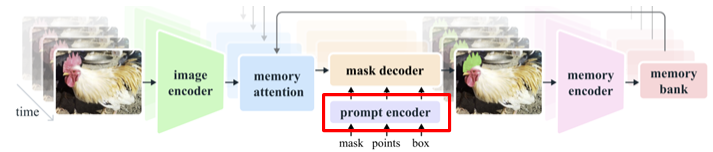
Prompt encoder는 SAM1과 동일한 encoder를 사용하므로 이전에 정리한 SAM1을 참고하자!
(https://velog.io/@jjun_8177/Segment-Anything-%EC%A7%84%ED%96%89-%EC%A4%91)
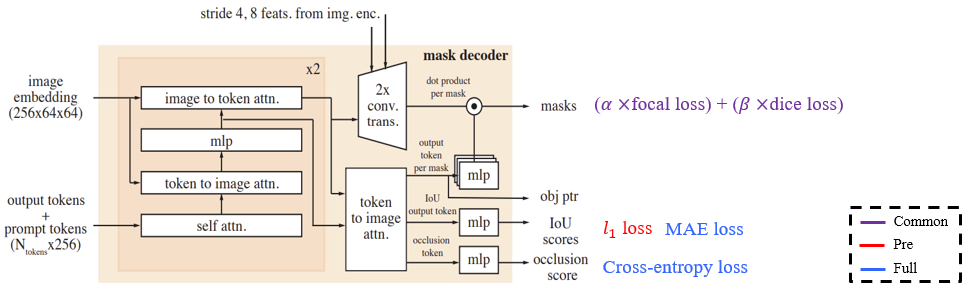
3.5. Mask decoder
Mask decoder도 SAM1을 많이 따르고 있다.
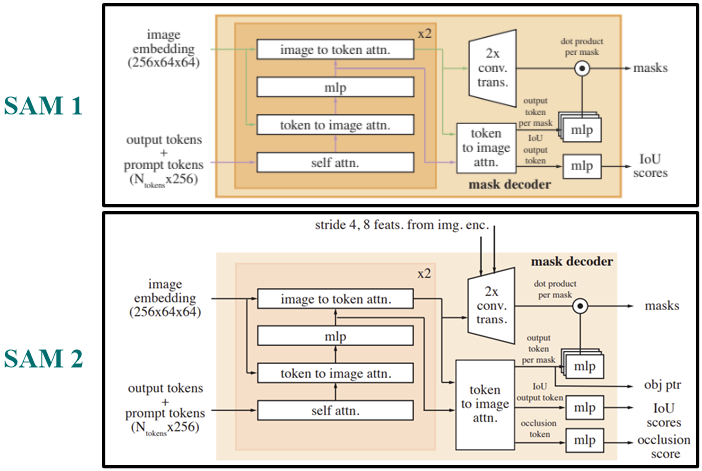
SAM1에서 Mask와 IoU score를 출력하는 과정을 아래 페이지에 상세하게 작성해뒀으니 참고하면 좋을 것 같다.
(https://velog.io/@jjun_8177/Segment-Anything-%EC%A7%84%ED%96%89-%EC%A4%91)
해당 페이지에서는 SAM1에서 소개한 mask decoder와 다른 부분만 짚어보자.
-
SAM1에서는 image to token attention 연산을 통해 image embeddings를 업데이트한 후 바로 transposed convolution 연산을 통해 해상도를 높이고 채널 수를 축소했다면, SAM2에서는 upscaling 과정에서 image encoder (unconditioned) 의 stage 1과 2, 즉 고해상도 정보를 담고 있는 feature map을 저해상도인 image embeddings에 더해준다.
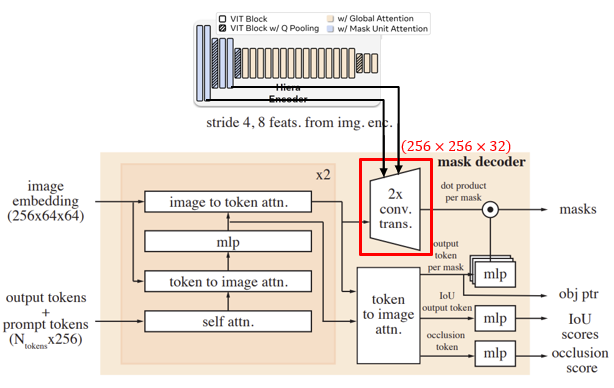
-
SAM1에서는 mask decoder의 output이 mask와 IoU score고, 후보 mask들 중 예측 IoU score가 가장 높은 mask를 최종 출력한다. 하지만 SAM2에서는 그 외에 obj ptr, occlusion score도 함께 출력한다.
-
Obj ptr는 object pointer로, 마스크를 생성해내는 "출력 토큰", 즉 분할 대상 객체의 고차원 이미 정보를 담고 있는 벡터로, 나중에 소개할 memory bank에 활용된다.
-
SAM1은 이미지 레벨을 다루고 있고, 이미지에서는 보이는 객체에 대해 단순히 분할을 할 수 있다면 동영상의 경우에는 분할 대상인 객체가 시야에서 벗어나거나 다른 객체에 가려지면서 특정 프레임에서는 사라질 수 있다. 이를 대비하여 SAM2에서는 occlusion score를 도입하여 해당 프레임에서 분할 대상인 객체가 있는지 없는지를 occlusion score를 통해 표현한다. 이는 scalar 값으로 객체가 보이면 1, 안 보이면 0으로 나타낸다.
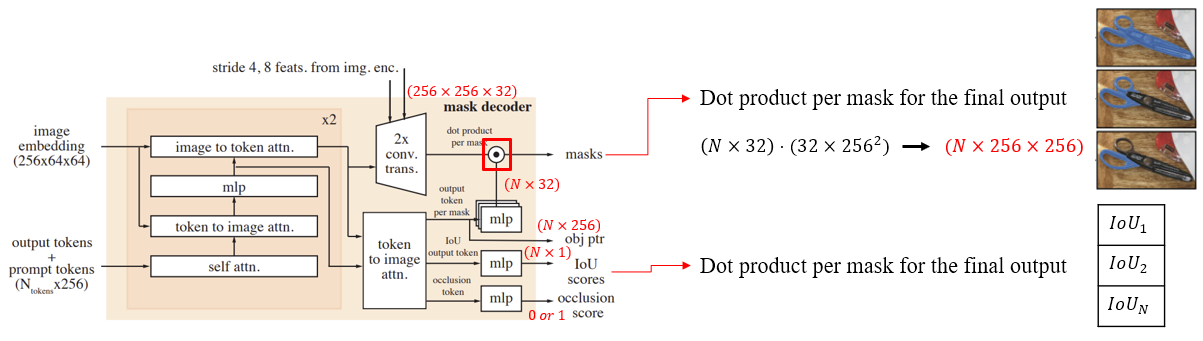
3.6. Memory encoder
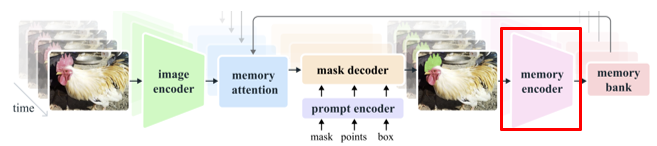
Memory는 mask decoder에서 최종 출력한 mask를 downsampling한 후, 해당 frame의 frame embedding 과 합쳐서 만들어진다. 여기서 frame embedding은 Hiera encoder를 통과하여 출력된 값이다.

3.7. Memory bank
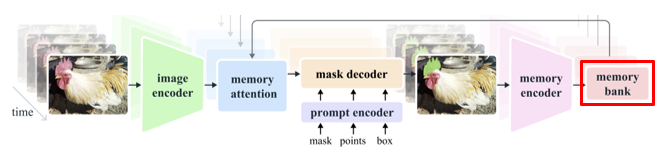
Memory bank는 말 그대로 memory 은행으로, frame마다 생성된 memory를 모아둔 공간이다.
Memory bank는 이 memory를 queue 형식으로 관리하고, 현재 시점을 기준으로 최근 개 frame의 memory와, 해당 frame들 중 prompt가 있는 개의 memory로 구성된 2 개의 queue로 관리한다.
또한 mask decoder에서 소개한 object pointer 정보도 함께 저장한 후 memory attention layer에서 모두 frame embeddings(conditioned)를 생성하는데 활용된다.
Object pointer가 실제로 모델의 성능을 올렸는지 궁금했는데 마침 ablation study에 정리가 되어있었다.
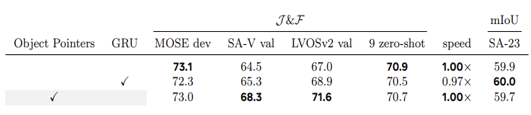
솔직히 그렇게 드라마틱한 차이가 있는가 생각이 들지만 논문에서는 SA-V val 데이터셋에서 좋은 성능을 보여 최종적으로 사용했다고 한다.
3.8. Training
Training은 pre-training, full-training, fine-tuning 3 개의 과정으로 진행된다.
3.8.1. Pre-training
Pre-training에서는 정적인 이미지만 있는 SA-1B 데이터셋을 활용하여 학습을 하고, 한 이미지 당 7번의 수정 클릭을 하여 8번의 iteration을 돌면서 학습하게 된다. 이미지만 학습하므로 memory 영역이 필요없을 것이고, loss function은 출력 mask와 정답 mask 간의 loss를 focal loss와 dice loss의 선형 조합한 loss, 예측 IoU score와 실제 IoU score 간의 loss를 합쳐서 모델을 학습하게 된다.
3.8.2. Full-training
Full-training은 이미지(SA-1B)와 비디오(SA-V) 데이터셋 모두를 활용한다. 여기서 비디오는 frame 수가 많으므로 8 개의 연속된 frame 선택 후 최대 2 개의 frame까지 수정 클릭이 가능하도록 설정하고, masklet의 수도 최대 3개로 제한한다. 동영상은 50%의 확률로 역재생하도록 하여 모델이 양방향 전파(bi-directional propagation)하여 일반화될 수 있도록 한다. Loss function은 출력 mask와 정답 mask 간의 loss를 focal loss와 dice loss의 선형 조합한 loss, 예측 IoU score와 실제 IoU score 간의 MAE loss, occlusion score는 cross-entropy loss를 합쳐서 모델을 학습한다.
3.8.3. Fine-tuning
Full-training에서 비디오에 대해 8 frame만 샘플링하여 모델을 학습했는데, 동영상은 일반적으로 훨씬 많은 수의 frame으로 구성되어 있을 것이다. 그래서 fine-tuning 단계에서는 보다 긴 16 frame을 샘플링하고, 비디오는 challenging한 비디오로 제한한다.
4. Data
SA-V 데이터셋은 총 5만 9백 개의 비디오, 64만 2천 6백 개의 masklet으로 구성되어있다.

데이터 획득 과정 모델과 인간이 상호작용하며 만들어지고, 총 3개의 단계로 구성되어 있다.
Phase 1 : SAM per frame
Annotator는 비디오 모든 frame에 대해 분할 대상인 객체를 SAM 모델을 이용하여 분할하고, 지우개나 브러쉬같은 편집 tool로 수정한다.
Phase 2 : SAM + SAM2 Mask
동영상의 첫 번째 frame을 SAM 모델을 이용하여 mask를 생성하고, Mask만 prompt로 받을 수 있도록 커스터마이징 된 SAM2 Mask 모델에 해당 mask를 넣어 동영상의 나머지 frame에 대해서도 segmentation을 진행한다. 다음 frame의 예측 결과를 SAM 모델을 이용해서 수정한 후 다시 SAM2 Mask 모델에 넣는 방식으로, 정확한 mask가 나올 때까지 반복한다.
Phase 3 : SAM2
Annotator는 예측 mask를 수정하기 위해 SAM2에게 수정클릭만을 prompt로 줄 수 있도록한다.
5. Experiment
5.1. Semi-supervised video object segmentation
해당 방식은 첫 번째 frame에 대해서만 입력 prompt를 주고, 나머지 frame에 대해 mask를 예측하는 방식이고, 비교 모델은 VOS 모델인 XMem++와 Cutie를 SAM과 합친 모델이다.
모든 prompt에 대해 SAM2가 가장 높은 정확도를 보인다.

5.2. Image segmentation
이미지 데이터로만 학습된 SAM1과 SAM2를 비교해봤을 때, SAM2 모델 자체에서 모델 성능이 향상된 것을 확인할 수 있고, 이미지와 동영상으로 구성된 데이터로 학습했을 때 이미지만으로 학습된 모델보다 더 좋은 성능을 보이는 것을 확인할 수 있다.

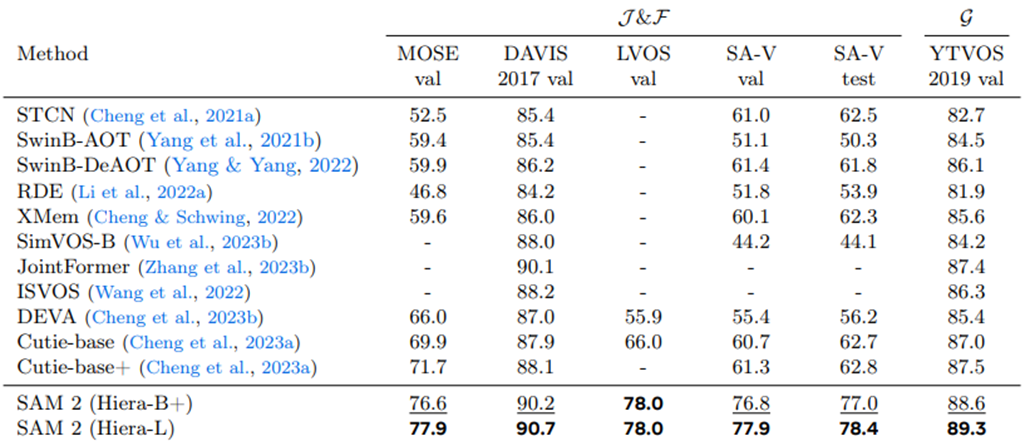
5.3. Comparison to state-of-the-art semi-supervised VOS
VOS를 수행하는 최신 method와 비교한 결과 SAM2가 가장 좋은 성능을 보이는 것을 확인할 수 있다.