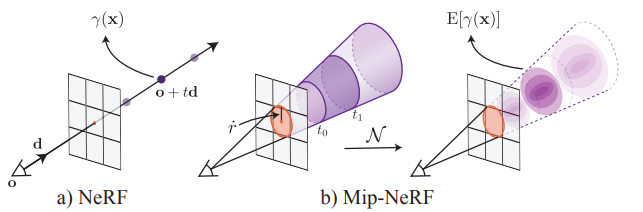
NeRF는 3D object 또는 scene을 촬영한 이미지들로 향하는 ray 위의 점을 샘플링해서 학습한 모델을 이용하여 새로운 시점에 대한 이미지를 렌더링하는 기술이다. 이 기법은 일정한 거리에서 촬영한 이미지들에 대해 좋은 렌더링 결과를 보여줬지만, 가까이에서 바라보는 시점에 대한 이미지는 흐릿한 현상이 발생했고, 거리가 먼 시점에 대한 이미지는 계단현상이 발생하는 한계를 보였다. 또한, NeRF는 fine network와 coarse network를 통해 최종 픽셀 값을 결정하게 되는데, 큰 해상도의 이미지는 ray 수도 많을 뿐더러 샘플링하는 점의 수까지 많아지다보니 모델에 입력할 query가 많아서 하나의 이미지를 렌더링하는데 오랜 시간이 걸린다는 단점이 있었다.
본 논문은 이러한 한계점을 극복하고자 새로운 방식을 제안한다.
1. Cone tracing
우선, 기존의 NeRF는 카메라에서 object나 scene의 3D point를 향해 발사되는 ray 위의 점들을 샘플링한 후 누적하여 픽셀의 최종 색을 결정했다. Mip-NeRF는 이런 얇은 광선 대신 콘(cone) 형태의 ray를 발사한 후 일정 구간으로 쪼개진 conical frustum 안의 좌표들을 사용하게 된다. t0,t1 시점 사이의 Conical frustum 안에 있는 3D 좌표들인 x는 다음과 같다.
그래서 이 conical frustum을 추후에 다룰 integrated positional encoding (IPE) 를 위해 다변수 가우시안으로 근사화한다. 이를 위해 F(x,⋅)의 평균과 공분산을 구해야 한다. conical frustum은 원형이고 대칭이므로, 이 Gaussian 분포는 광선과 평행한 방향으로의 평균 거리 μt, 광선과 평행한 방향으로의 분산 σt2, 광선과 수직인 방향으로의 분산 σr2 세 개의 값으로 설명할 수 있다.
우선 기존의 Cartesian space에 정의된 좌표 x=(x,y,z)는 광선이 퍼지는 효과를 제대로 반영하기 어려우므로, (r,t,θ) 좌표계로 변환해준다. 여기서 r은 radius로 광선의 퍼짐 정도를, t는 광선의 깊이(depth), θ는 광선의 기울기를 나타낸다. 여기서 x,y,z는 각각 rtcosθ,rtsinθ,t로 나타낼 수 있고, 이렇게 변환된 변수는 미분가능하게 해준다. 그 이유는 :
이렇게 구한 μt,σr2,σt2을 이용하면, t0와 t1이 큰 차이를 낸다면 괜찮지만, 서로 가까이 위치해있을 때 이 차이를 큰 지수 값으로 계산하게 되면 값이 0 또는 NaN을 뱉는 경우가 있으므로, t0,t1 대신 t0와 t1의 중점인 tμ=2t0+t1, t0와 t1사이의 거리의 절반인 tδ=2t0−t1 로 파라미터를 바꾸어 사용한다고 한다. 최종 변수들은 다음과 같다.
여기서 tμ는 t0와 t1의 중점이고, tδ는 t0와 t1 사이의 거리의 반을 나타낸다.
tμ=2(t0+t1)tδ=2(t0−t1)
Conical frustum 좌표계에서 정의된 가우시안 분포는 다음과 같이 world coordinate으로 변형할 수 있다.
μ=o+μtdΣ=σt2(ddT)+σr2(I−∣∣d∣∣22ddT)
여기서 μ는 평균 벡터로, 데이터의 중심을 나타내고, Σ는 공분산 행렬로, 데이터의 퍼짐 정도를 나타낸다. 이를 통해 world coordinate에서 데이터의 분포를 정확히 모델링할 수 있게 된다.
2. Integrated positional encoding (IPE)
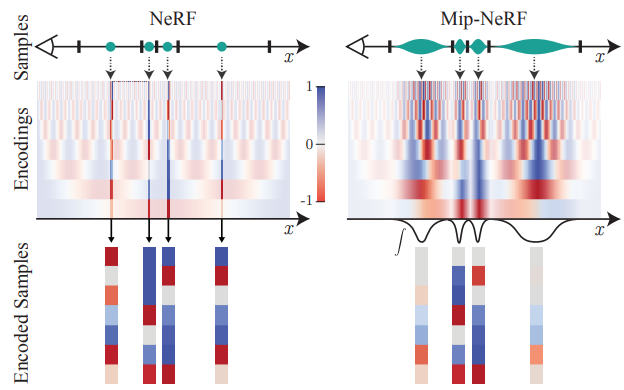
다음 그림은 1차원 공간에서 positional encoding(PE)와 integrated positional encoding(IPE)의 차이를 보여준다. NeRF는 각 ray 위에서의 점들을 샘플링하고 모든 주파수를 동일하게 인코딩한다. Aliasing이라고 불리는 계단현상은 고주파 신호가 저주파 신호로 왜곡되는 현상인데, 이는 샘플 간격에 비해 고주파 특성들이 너무 많이 표현되면서 발생하는 것이다. IPE는 주파수 구간을 통합함으로써 고주파 특성들이 구간의 크기에 비례해 감소하게 하여 anti-aliasing 효과를 얻을 수 있다.
우선 coordinate space에서의 좌표 x를 frequency space로 Fourier feature를 통해 embedding할 수 있다.
NeRF는 coarse network, fine network 두 개의 네트워크를 사용하여 최종 이미지 픽셀 값을 정하였다. 하지만, Mip-NeRF는 multi-scale representation이 가능하므로 단 하나의 네트워크만을 사용하여 이미지 픽셀 값을 결정하므로 모델 사이즈도 절반으로 줄일 수 있고, 샘플링도 더 효과적이고, 전체적인 알고리즘도 단순해진다.

정말 재밌군요!