논문의 흐름에 따라서 코드를 구현하고 있는데, 기존의 NeRF 보다 좀 더 직관적으로 이해할 수 있을 것 같아서 공유해본다.
https://github.com/jjun9288/3D_Vision/tree/main/NeRF
0. Abstract
NeRF (Neural Radiance Field)는 복잡한 scene에 대한 새로운 시점에서의 이미지를 렌더링하는 task (novel view synthesis)를 수행한다. 모델에 5차원의 좌표 정보 (ray의 방향 정보 () 와 ray의 위의 3차원 좌표 ()) 가 입력되면, 출력된 color와 density를 통해 volume rendering을 거쳐 이미지를 구성하게 된다. 본 논문은 효과적인 모델 최적화를 통해 새로운 시점에 대한 현실적인 이미지를 렌더링하는 방법을 소개한다.
1. Introduction
Novel view synthesis를 위한 학습 방법은 다음과 같다.
- 카메라에서 scene으로 향하는 ray 위의 3차원 점 샘플링.
- 샘플링된 점과 ray의 방향을 모델에 입력하여 color ()와 density 출력
- Volume rendering을 통해 ray 위의 각 점의 color와 density를 누적하여 픽셀 값 결정
- 예측된 픽셀 값과 실제 픽셀 값과의 차이를 이용하여 loss 값 계산
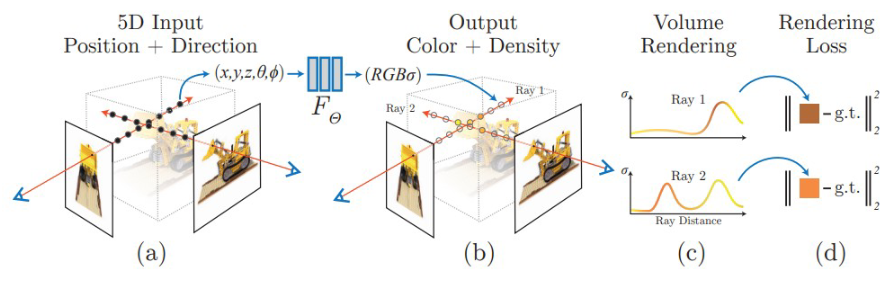
이 과정은 미분이 가능하므로 gradient descent 기법을 통해 실제 이미지와 rendering된 이미지 간의 차이를 최소화하도록 모델을 학습할 수 있다.
하지만, 이렇게 간단한 구현으로는 몇 가지의 문제점이 있다.
- 복잡한 scene을 나타낸다면 고화질로 나타내기에 모델이 수렴하지않는다.
- 카메라 ray마다의 비효율적인 샘플링을 수행하게 된다.
이러한 이슈를 해결하기 위해 본 논문은
- Positional encoding을 도입하여 모델이 고화질의 이미지를 나타낼 수 있도록 한다.
- Hierarchical sampling을 통해 최종 렌더링에 기여하는 점을 샘플링한다.
2. Neural Radiance Field Scene Representation
본 논문은 scene을 연속적으로 표현하기 위해 ray 위의 좌표 와 ray의 방향 를 입력했을 때 color 와 density 를 얻을 수 있도록 MLP 네트워크의 가중치 를 최적화한다.
또한, 단일 view에서 뿐만아니라 다양한 view에서 일관되기 위해 는 에 대해서만 계산하고, 는 와 모두에 대해 계산하도록 한다. 이를 만족하기 위해 는 먼저 positional encoding 된 를 입력으로 받아 8개의 fully-connected layer로 구성된 네트워크에 통과 (다섯번째 layer에서 skip connection을 통해 입력값 한 번 더 입력) 시켜서 와 256차원의 feature vector를 얻고, 이 feature vector를 와 합쳐서 한 개의 fully-connected layer를 통과시켜 를 얻도록 한다.
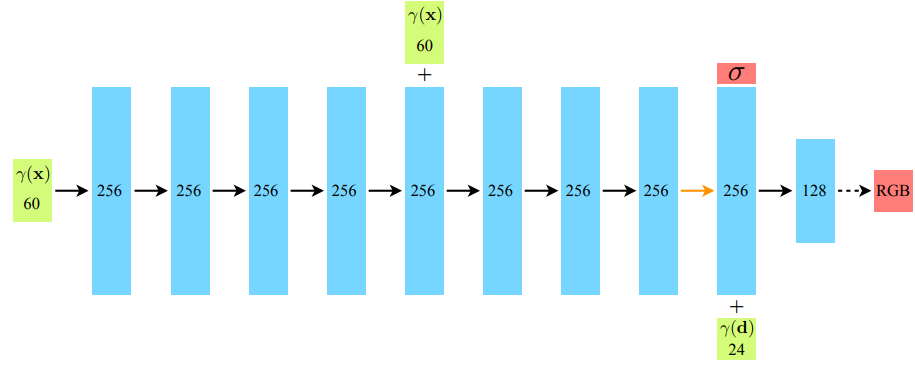
옆에 있는 숫자는 positional encoding에서 다루겠다.
3. Volume Rendering with Radiance Fields
하나의 ray 에서 샘플링된 좌표 들과 해당 ray의 방향 를 통해 얻은 density 들과와 color 들이 있을 때, volume rendering을 통해 픽셀의 최종 색 을 정할 수 있다.
여기서 와 는 위에서 이야기했듯 모델을 통해 얻은 출력이고, 는 ray의 시작과 끝, 는 누적 투과율 (accumulated transmittance)를 나타낸다. 투과도가 필요한 이유는 ray가 scene을 향해 뻗어나가다가 물체에 부딪혔을 때, 물체 내부의 점은 필요성이 떨어지므로 이를 표현하기 위해 추가한 것이다. 즉, ray가 부딪히기 전인 까지의 정보를 누적하여 색을 결정하는데 사용한다.
위 식은 구적법을 이용하여 수치적으로 근사화하기 위해 strtified sampling을 이용하여 구간을 N개의 균등한 구간으로 나눈 후, 각 구간에서 하나의 sample을 random하게 샘플링하여 모델에 입력할 를 얻는다.

최종 렌더링 식은 다음과 같다.
위 식에서 는 샘플링된 두 인접한 좌표 간의 거리를 나타낸 것이다. 는 밀도, 즉 해당 점이 물체와 부딪혔는지 통과했는지를 scalar 값으로 나타낸 것이다. 수식의 각 부분을 'Depth-supervised NeRF'에서 시각화를 잘 해두어서 가져와봤다.
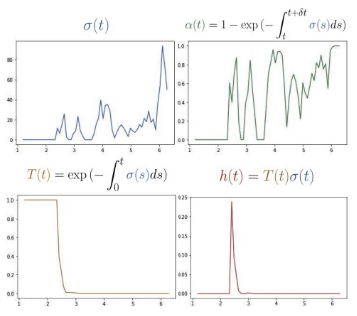
그림을 보면, 결국 누적투과율에 의해 물체와 처음 부딪히는 점이 큰 기여를 하게 되고, 이후의 점들은 죽는 것을 볼 수 있다.
모델을 통해 얻은 와 와 이 volume rendering 식을 이용하여 를 얻는다.
4. Optimizing a Neural Radiance Field
Introduction에서 이야기했듯이 이 방법만으로는 SOTA 급의 퀄리티를 내기는 힘들다. 본 논문은 두 가지의 방법을 추가하여 성능을 개선했는데, 그것은 바로 positional encoding과 hierarchical sampling이다.
4.1. Positional encoding
모델 에 와 를 바로 입력한다면 렌더링 결과가 color나 geometry가 고주파 요소, 즉 세밀한 디테일을 잘 표현하지 못한다고 한다. 이는 딥러닝이 저주파 함수를 학습하는 경향이 있어서 그렇다. 네트워크가 세밀한 디테일을 표현할 수 있도록 하기 위해 본 논문은 입력값을 더 높은 차원의 공간으로 mapping하는 positional encoding을 도입했다.
Positional encoding에 대한 자세한 설명은 'Fourier Features Let Networks Learn High Frequency Features in Low Dimensional Domains'에서 볼 수 있다.

4.2. Hierarchical volume sampling
단순히 ray 위의 점 개를 샘플링하는 것은 빈 공간이나 물체 뒤의 가려진 영역처럼 렌더링에 기여하지 않는 점들도 있으므로 비효율적이다. 본 논문은 hierarchical sampling을 통해 최종 렌더링에 기여하는 부분을 집중적으로 샘플링하여 렌더링의 효율성을 올렸다.

이를 위해 하나의 네트워크가 아닌 coarse, fine 총 두 개의 네트워크를 최적화한다.
첫음에는 일반적인 샘플링 방식을 통해 개의 샘플을 얻은 후 모델을 통해 얻은 출력값으로 volume rendering을 수행하여 모델의 성능을 평가한다.
Coarse 네트워크의 출력값을 얻은 후, 최종 렌더링에 기여하는 영역에서 추가로 샘플링을 진행한다. 추가적인 샘플링은 를 normalize한 후 () 각 샘플 구간별로 얻은 일정한 확률 밀도 함수에서 inverse transform sampling을 통해 얻는다. 이렇게 얻은 총 개의 샘플링을 이용하여 최종 렌더링된 이미지를 얻게 된다.
4.3. Loss function
Loss function은 간단하게 렌더링된 이미지와 실제 이미지 간의 차이를 이용한다.
최종 렌더링은 fine network를 통해 얻은 값을 통해 수행되지만, coarse network를 통해 얻은 weight의 분포가 fine sampling에 사용되므로 coarse network 또한 사용하여 loss를 최소화하는 방향으로 모델을 최적화하게 된다.
5. Results
5.1. Synthetic dataset
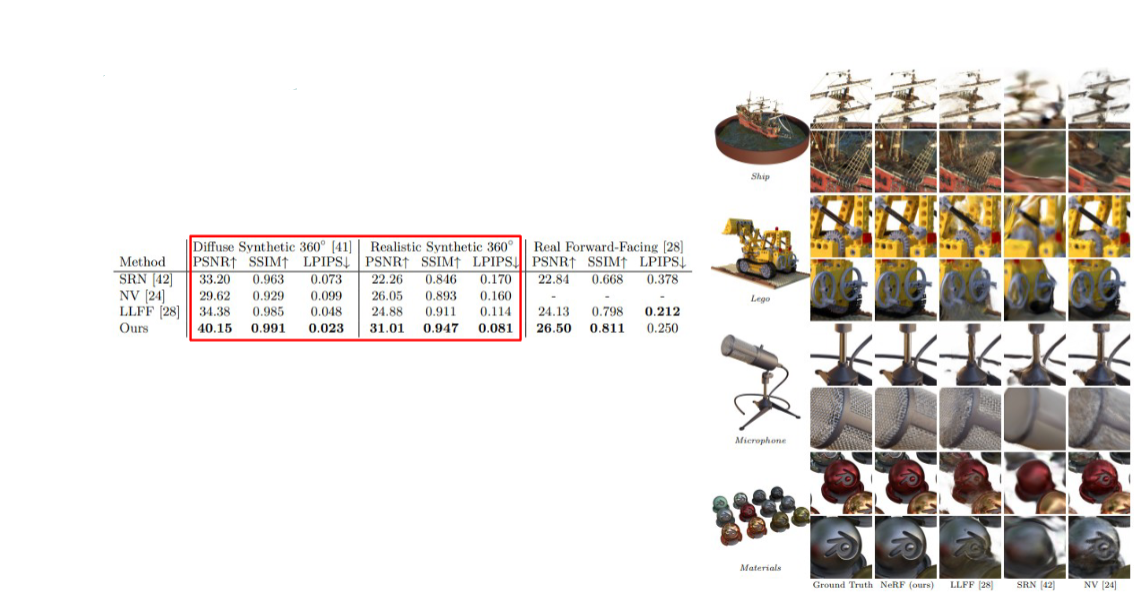
5.2. Real-world dataset
Synthetic 데이터셋은 아무래도 blender와 같은 프로그램을 통해 물체의 정확한 3차원 위치를 알 수 있고, 세상 좌표계 및 카메라 좌표계 간의 변환 관계도 정확하게 알 수 있으므로, real-world 데이터셋보다 높은 정확도를 보여준다고 생각한다.

5.3. Ablation studies

positional encoding, view direction, hierarchical sampling, 더 적은 수의 이미지, positional encoding 시 frequency band, 등 다양한 요소를 비교한 결과 모든 요소를 고려했을 때 가장 정확한 결과를 내는 것을 확인할 수 있다.

호기심을 유발하네요