
데이터베이스 설계는 데이터를 효율적으로 저장하고 관리하기 위한 중요한 단계이다. 그 중에서도 ERD(개체-관계 다이어그램)를 릴레이션 스키마로 변환하는 과정은 논리적 설계의 핵심이다.
이 과정은 데이터 구조를 명확히 하고, 중복을 최소화하며, 데이터의 일관성을 유지하는 데 필수적이다.
ERD를 릴레이션으로 변환하는 7단계 과정을 자세히 살펴보자.
1단계
1단계 - 정규 개체 타입과 단일 값 속성
첫 번째 단계는 정규 개체 타입을 릴레이션으로 변환하는 것이다.
정규 개체는 고유한 식별자를 가지며, 각 속성은 단일 값으로 구성된다.
이 단계에서는 개체를 하나의 테이블로 변환하고, 개체의 모든 속성을 테이블의 열로 표현한다. 각 행은 개체의 인스턴스를 나타내며, 기본 키는 개체의 고유한 식별자로 설정한다.
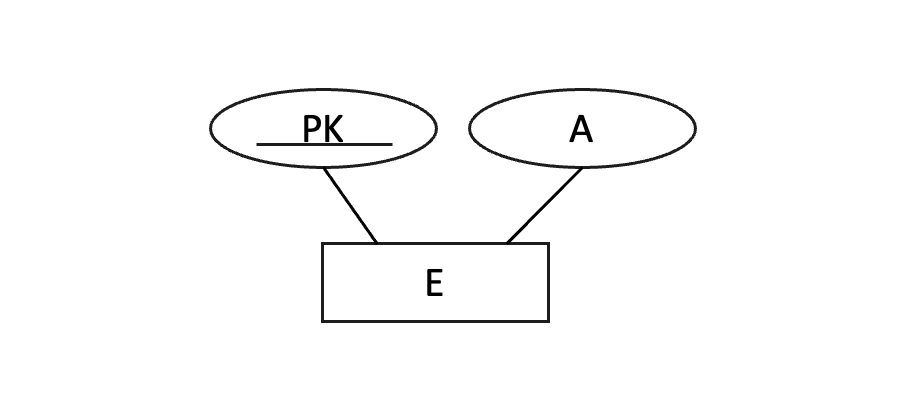
→ E(PK, A)
2단계
2단계 - 약한 개체 타입과 단일 값 속성
두 번째 단계는 약한 개체 타입을 릴레이션으로 변환하는 것이다.
약한 개체는 독립적으로 존재할 수 없으며, 정규 개체에 의존한다.
이 단계에서는 약한 개체 타입을 독립적인 테이블로 변환하되, 이를 참조하는 정규 개체의 기본 키를 포함한다. 약한 개체의 기본 키는 이 외래 키와 약한 개체의 고유 속성을 조합하여 생성한다.
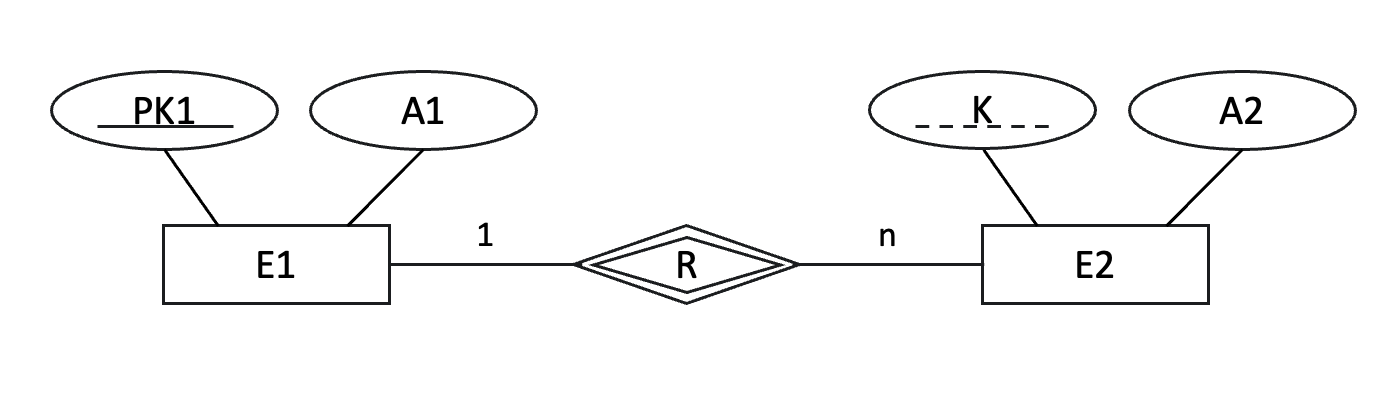
→ E1(PK1, A1), E2(PK1, K, A2)
3단계
3단계 - 2진 1:1 관계 타입
세 번째 단계는 1:1 관계를 다루는 것이다.
1:1 관계는 두 개체가 서로 1:1로 대응하는 관계를 말한다.
이 단계에서는 두 개체 중 하나에 다른 개체의 기본 키를 외래 키로 추가하거나, 별도의 테이블을 만들어 두 개의 기본 키를 조합한 복합 키로 사용한다. 선택은 관계의 선택적 여부와 양쪽의 참여 여부에 따라 달라진다.
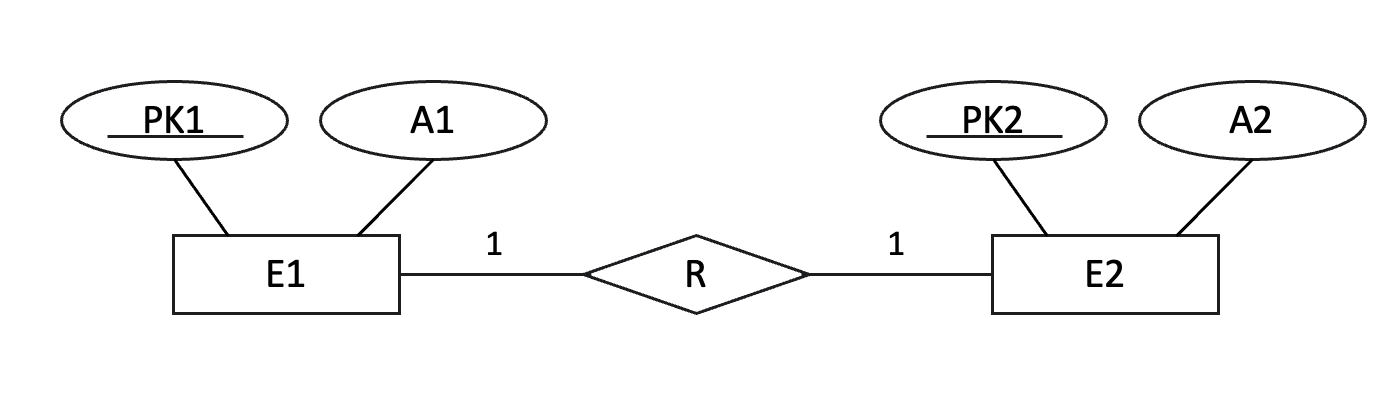
→ E1(PK1, A1), E2(PK2, A2, FK1)
→ E1(PK1, A1, FK2), E2(PK2, A2,)
→ E1(PK1, A1), E2(PK2, A2), R(FK1, FK2)
→ E1E2(PK1, A1, PK2, A2)
4단계
4단계 - 정규 2진 1:N 관계 타입
네 번째 단계에서는 1:N관계를 변환한다.
관계는 한 개체가 다른 여러 개체와 관계를 맺을 수 있는 경우이다.
이 경우, '1' 측 개체의 기본 키를 'N' 측 개체의 테이블에 외래 키로 추가한다. 이 외래 키는 두 테이블 간의 관계를 유지하는 역할을 한다.
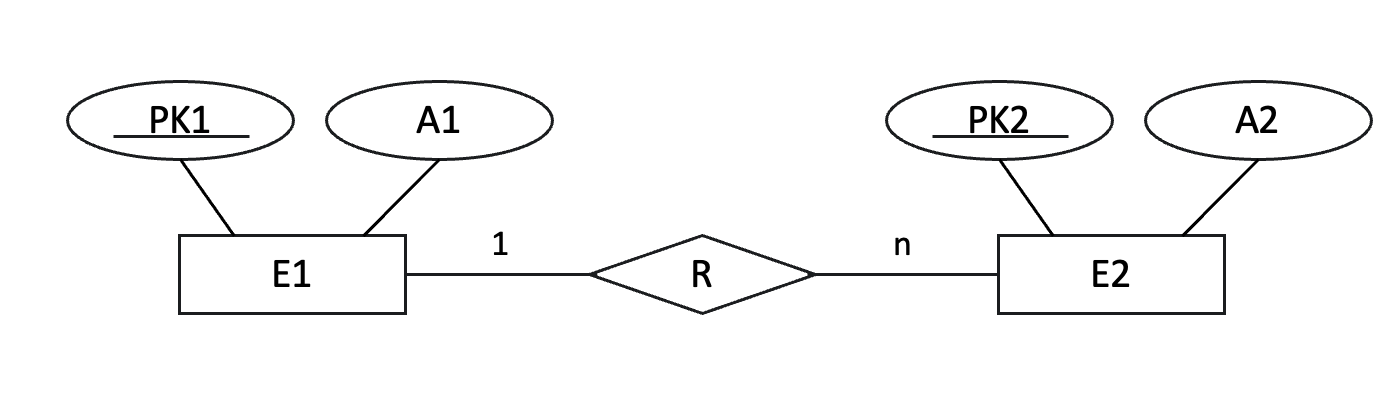
→ E1(PK1, A1), E2(PK2, A2, FK1)
→ E1(PK1, A1), E2(PK2, A2), R(FK1, FK2)
5단계
5단계 - 2진 N:M 관계 타입
다섯 번째 단계는 N:M관계를 다룬다.
관계는 양쪽 개체가 서로 다수의 관계를 맺을 수 있는 경우이다.
이 경우, N 관계를 표현하기 위해 별도의 중간 테이블을 생성하고, 양쪽 개체의 기본 키를 중간 테이블에 외래 키로 추가하여 복합 키로 사용한다. 이 중간 테이블은 두 개체 간의 모든 관계를 기록하는 역할을 한다.
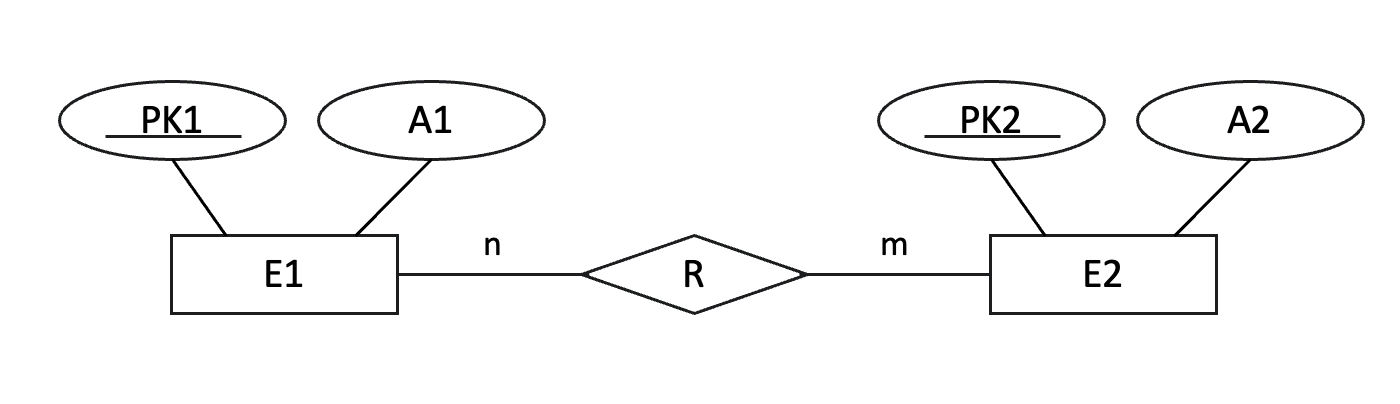
→ E1(PK1, A1), E2(PK2, A2), R(FK1, FK2)
6단계
6단계 - 3진 이상의 관계 타입
여섯 번째 단계는 3진 이상의 관계를 변환하는 것이다.
3개 이상의 개체가 참여하는 관계를 다룰 때는 관계를 나타내는 별도의 테이블을 생성하고, 참여하는 모든 개체의 기본 키를 이 테이블에 외래 키로 추가한다. 이렇게 만들어진 테이블은 관계에 참여하는 모든 개체 간의 복잡한 상호작용을 기록한다.
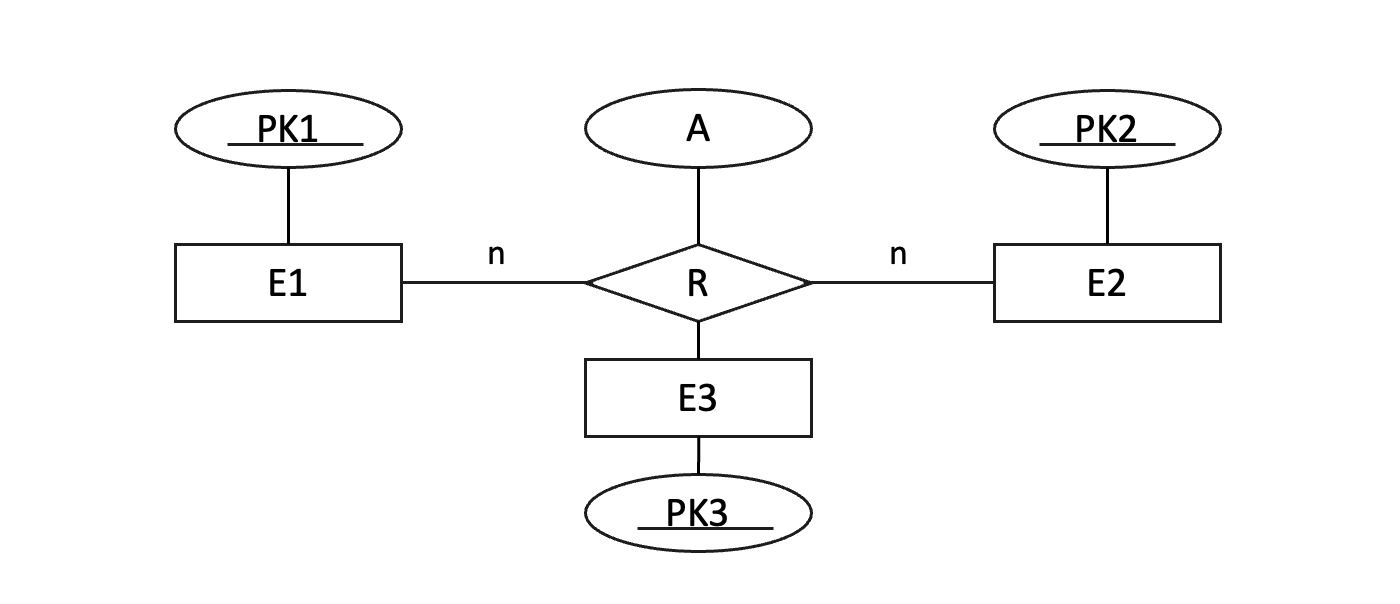
→ R(FK1, FK2, FK3, A)
7단계
7단계 - 다치 속성
마지막 단계는 다치 속성을 처리하는 것이다.
다치 속성은 하나의 개체가 여러 값을 가질 수 있는 속성을 의미한다.
이를 릴레이션으로 변환하기 위해서는, 다치 속성을 별도의 테이블로 분리하고, 원래 개체의 기본 키와 다치 속성을 이 테이블에 포함시킨다. 이 테이블은 개체의 각 속성 값에 대해 하나의 행을 가지며, 기본 키로 원래 개체의 기본 키와 다치 속성의 값을 조합하여 사용한다.

→ E(PK, A), MVA(FK, B)
참고
데이터베이스론
