
Spring 강의를 듣다가 HashMap을 사용하면 동시성 문제가 생겨 ConcurrentHashMap을 사용하기를 권장해서 차이점을 찾아보았다.
1. HashMap
- HashMap은 키-값 쌍을 저장하는 데에 사용된다. 해시함수를 사용하여 키를 해싱하고, 배열 내에서 키와 값을 연결하는 방식으로 동작한다.
- key와 value에 null값을 허용한다.
import java.util.HasMap;
HashMap<K,V> variable name = new HashMap<K,V>();
Type Parameters:
K - the type of keys maintained by this map
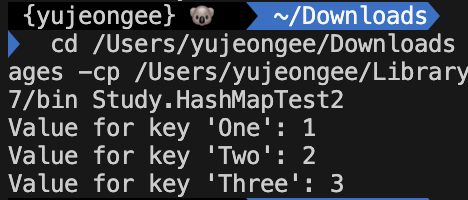
V - the type of mapped values아래의 코드처럼 각각의 다른 키를 추가한 경우에는 추가한 키-값에 대한 결과가 잘 나오기 때문에 동시성 문제를 고려할 필요가 없어 보인다.
package Study;
import java.util.HashMap;
public class HashMapTest1 {
public static void main(String[] args) {
// HashMap 생성
HashMap<String, Integer> hashMap = new HashMap<>();
// 키-값 추가
hashMap.put("One", 1);
hashMap.put("Two", 2);
hashMap.put("Three", 3);
// 값 가져오기
System.out.println("Value for key 'One': " + hashMap.get("One"));
System.out.println("Value for key 'Two': " + hashMap.get("Two"));
System.out.println("Value for key 'Three': " + hashMap.get("Three"));
}
}
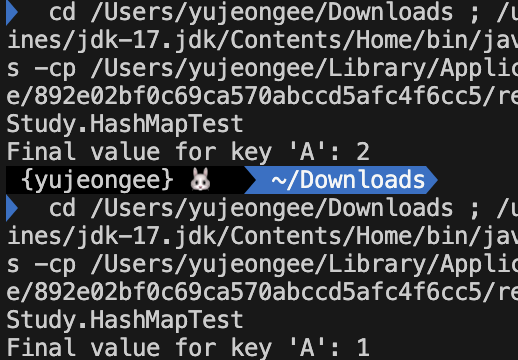
하지만, 다음의 코드처럼 같은 키에 대해 값을 추가하는 경우는 다르다. HashMap은 멀티스레드 환경에서 동시 수정에 대한 동기화가 이루어지지 않기 때문에 여러 스레드에서 동시에 수정되면, 예측 불가능한 결과가 발생한다.
package Study;
import java.util.HashMap;
public class HashMapTest2 {
public static void main(String[] args) throws InterruptedException {
// 공유되는 HashMap 객체
HashMap<String, Integer> sharedHashMap = new HashMap<>();
// 첫 번째 스레드: 키 "A"에 대한 값을 1로 설정
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
sharedHashMap.put("A", 1);
}
});
// 두 번째 스레드: 키 "A"에 대한 값을 2로 설정
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
sharedHashMap.put("A", 2);
}
});
// 두 스레드 시작
thread1.start();
thread2.start();
// 메인 스레드는 두 스레드가 종료될 때까지 대기
thread1.join();
thread2.join();
// 최종 결과 출력
System.out.println("Final value for key 'A': " + sharedHashMap.get("A"));
}
}
synchronizedMap
HashMap의 Collections.synchronizedMap(HashMap)은 모든 메서드에 대한 동기화를 제공하기 때문에 하나의 스레드가 맵을 수정하고 있을 때, 다른 스레드는 대기하게 된다.
그래서 동시성 문제를 해결할 수 있으나, 전체 맵에 대한 락(lock)을 사용하므로 성능이 영향을 받을 수 있다.
3. ConcurrentHashMap
이러한 HashMap의 안전한 버전으로 ConcurrentHashMap을 사용할 수 있다. 그리고 key와 value에 null값을 허용하지 않는다.
import java.util.concurrent.ConcurrentHashMap;
import java.util.Map;
Map<K,V> concurrentHashMap = new ConcurrentHashMap<>();ConcurrentHashMap는 내부적으로 세그먼트를 사용하여 동기화를 제공하기 때문에 부분적인 동기화를 통해 성능을 향상시킬 수 있다. 즉, 여러 스레드가 동시에 맵을 수정할 수 있다.
package Study;
import java.util.concurrent.ConcurrentHashMap;
import java.util.Map;
public class ConcurrentHashMapTest {
public static void main(String[] args) throws InterruptedException {
// ConcurrentHashMap 사용
Map<String, Integer> concurrentHashMap = new ConcurrentHashMap<>();
// 첫 번째 스레드: 키 "A"에 대한 값을 1로 설정
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
concurrentHashMap.put("A", 1);
}
});
// 두 번째 스레드: 키 "A"에 대한 값을 2로 설정
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
concurrentHashMap.put("A", 2);
}
});
// 두 스레드 시작
thread1.start();
thread2.start();
// 메인 스레드는 두 스레드가 종료될 때까지 대기
thread1.join();
thread2.join();
// 최종 결과 출력
System.out.println("Final value for key 'A': " + concurrentHashMap.get("A"));
}
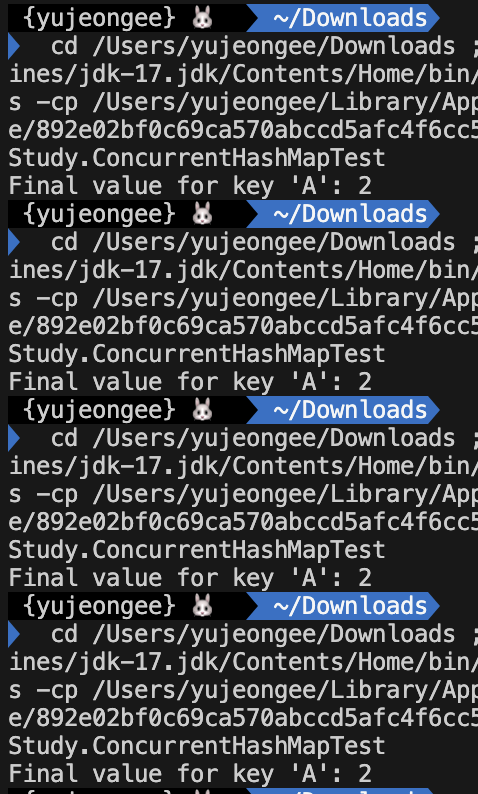
}최종 결과 다음과 같이 같은 결과를 얻을 수 있다.
정리
| HashMap | ConcurrentHashMap | |
|---|---|---|
| key와 value에 null 허용 | O | X |
| 동기화 보장(Thread-safe) | X | O |
| 추천 환경 | 싱글 스레드 | 멀티 스레드 |
참고
Class ConcurrentHashMap<K,V>
Class HashMap<K,V>
ConcurrentHashMap vs Synchronized HashMap
HashMap, HashTable, ConcurrentHashMap 내부 코드

공부 기록